本文已经或者同济子豪兄作者授权对文章进行编辑和转载
引言
随着人工智能和机器人技术的快速发展,机械臂在工业、医疗和服务业等领域的应用越来越广泛。通过结合大模型和多模态AI,机械臂能够实现更加复杂和智能化的任务,提升了人机协作的效率和效果。我们个人平时接触不太到机械臂这类的机器人产品,但是有一种小型的机械臂我们人人都可以拥有它myCobot,价格低廉的一种桌面型机械臂。
案例介绍
本文介绍同济子豪兄开源的一个名为“vlm_arm”项目,这个项目中将mycobot 机械臂与大模型和多模态AI结合,创造了一个具身智能体。该项目展示了如何利用先进的AI技术提高机械臂的自动化和智能化水平。本文的目的是通过详细介绍该案例的方法和成功,展示机械臂具身智能体的实际应用。
产品介绍
myCobot 280 Pi
myCobot 280 Pi是一款6自由度的桌面型机械臂,主要的控制核心是Raspberry Pi 4B,辅助控制核心是ESP32,同时配备了 Ubuntu Mate 20.04 操作系统和丰富的开发环境。这使得 myCobot 280 Pi 在无需外接 PC 的情况下,只需连接显示器、键盘和鼠标即可进行开发。

这款机械臂重量轻,尺寸小,具有多种软硬件交互功能,兼容多种设备接口。它支持多平台的二次开发,适用于人工智能相关学科教育、个人创意开发、商业应用探索等多种应用场景。
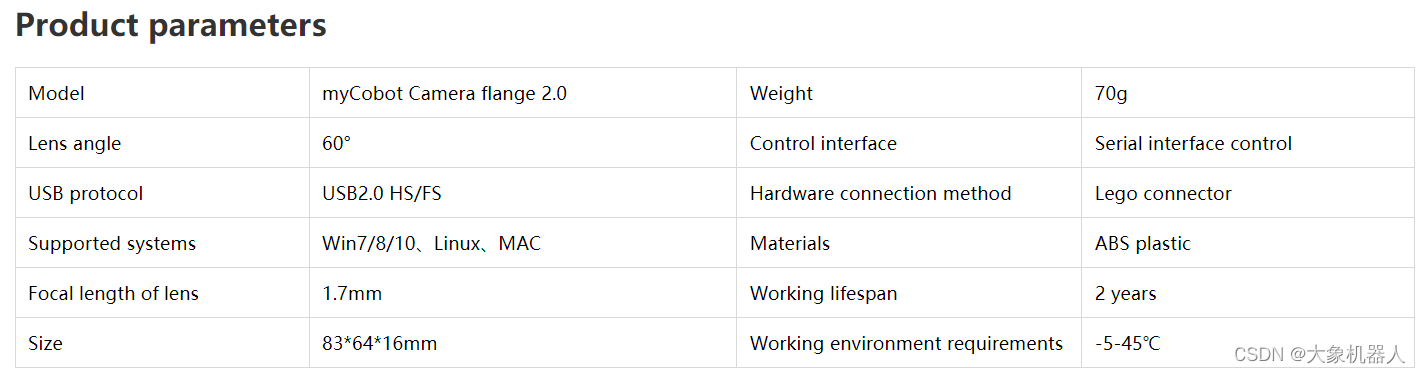
Camera Flange 2.0
在案例中使用到的摄像头,通过usb数据线跟raspberry pi链接,可以获取到图像来进行机器视觉的处理。

Suction Pump 2.0
吸泵,工资原理通过电磁阀抽空起造成压强差然后将物体吸起来。通过IO接口链接机械臂,用pymycobot 的API进行控制吸泵的开关。

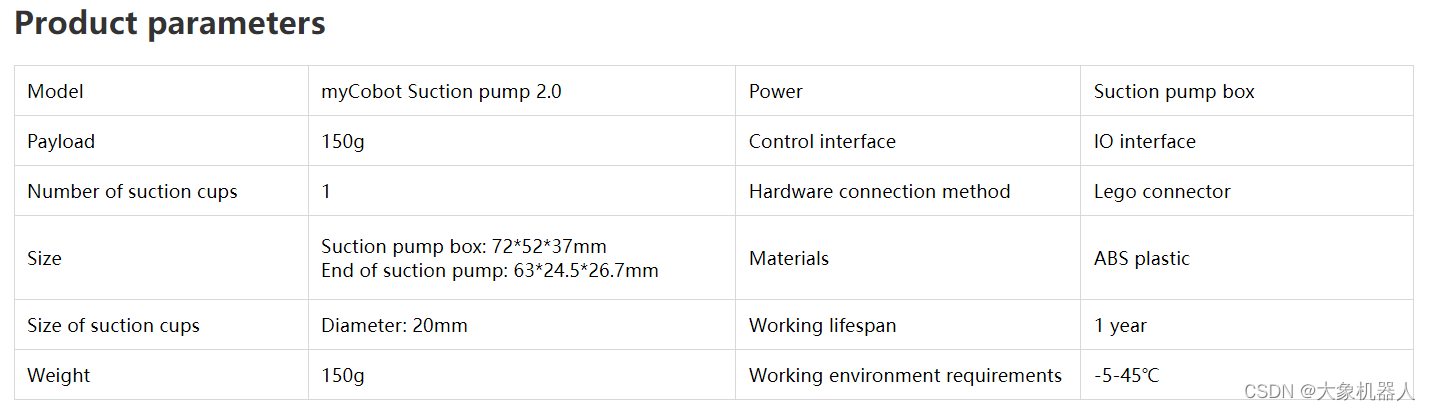
机械臂的末端都是通过LEGO连接件连接起来的,所以它们之间可以很方便的连接起来不需要额外的结构件。

技术介绍
整个的案例将在python环境中进行编译,下面讲介绍使用到的库。
pymycobot:
elephant robotics编写的对myCobot 控制的python库,可以通过坐标,角度来控制机械臂的运动,也可以控制官方适配的末端执行器例如夹爪,吸泵的运动。
Yi-Large:
Yi-large 是由中国人工智能公司 01.AI 开发的大型语言模型,拥有超过 1000 亿参数。Yi-large 使用了一种叫做“Transformer”的架构,并对其进行了改进,使其在处理语言和视觉任务时表现得更好。
Claude 3 Opus:
该模型还展示了强大的多语言处理能力和改进的视觉分析功能,能够进行图像的转录和分析。此外,Claude 3 Opus 被设计为更具责任感和安全性,减少了偏见和隐私问题,确保其输出更加可信和中立。
AppBuilder-SDK:
AppBuilder-SDK 的功能非常广泛,包含了诸如语音识别、自然语言处理、图像识别等AI能力组件 (Read the Docs) 。具体来说,它包括了短语音识别、通用文字识别、文档解析、表格抽取、地标识别、问答对挖掘等多个组件 (Read the Docs) (GitHub) 。这些功能使开发者可以构建从基础AI功能到复杂应用的各种项目,提升开发效率。
该案例中提到了很多的大语言模型,都是可以自行去测试每个大语言输出的不同的结果如何。
项目结构
介绍项目之前必须得介绍一下项目的构成,制作了一张流程图方便理解。
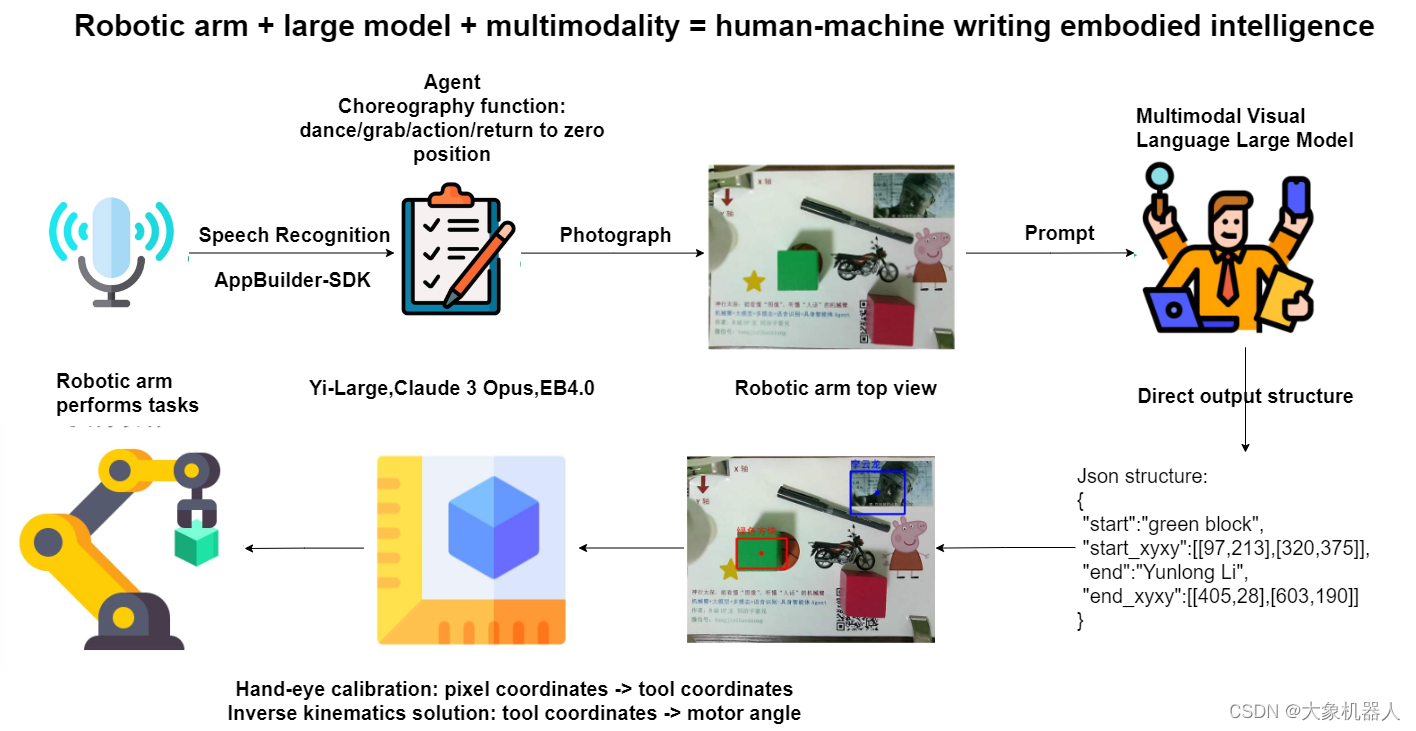
语音识别-appbuild
首先通过调用本地的电脑进行麦克风的录音制作成音频文件。
#调用麦克风录音。
def record(MIC_INDEX=0, DURATION=5):
'''
调用麦克风录音,需用arecord -l命令获取麦克风ID
DURATION,录音时长
'''
os.system('sudo arecord -D "plughw:{}" -f dat -c 1 -r 16000 -d {} temp/speech_record.wav'.format(MIC_INDEX, DURATION))
当然这种默认的录音在一些特定的环境中效果是不好的,所以要设定相关的参数保证录音的质量。
CHUNK = 1024 # 采样宽度
RATE = 16000 # 采样率
QUIET_DB = 2000 # 分贝阈值,大于则开始录音,否则结束
delay_time = 1 # 声音降至分贝阈值后,经过多长时间,自动终止录音
FORMAT = pyaudio.paInt16
CHANNELS = 1 if sys.platform == 'darwin' else 2 # 采样通道数根据参数的设定,然后开始录音,之后要对文件进行保存。
output_path = 'temp/speech_record.wav'
wf = wave.open(output_path, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames[START_TIME-2:END_TIME]))
wf.close()
print('保存录音文件', output_path)有了录音文件,电脑当然没那么智能我们需要用到appbuild-sdk来对音频文件的语音进行识别,这样LLM才能够获取我们说的话然后做出一些对应的操作。
import appbuilder
os.environ["APPBUILDER_TOKEN"] = APPBUILDER_TOKEN
asr = appbuilder.ASR() # 语音识别组件
def speech_recognition(audio_path='temp/speech_record.wav'):
# 载入wav音频文件
with wave.open(audio_path, 'rb') as wav_file:
# 获取音频文件的基本信息
num_channels = wav_file.getnchannels()
sample_width = wav_file.getsampwidth()
framerate = wav_file.getframerate()
num_frames = wav_file.getnframes()
# 获取音频数据
frames = wav_file.readframes(num_frames)
# 向API发起请求
content_data = {"audio_format": "wav", "raw_audio": frames, "rate": 16000}
message = appbuilder.Message(content_data)
speech_result = asr.run(message).content['result'][0]
return speech_resultPrompt-Agent
紧接着,我们要prompt大语言模型,提前告诉它出现某种情况应该如何进行应对。这边对调用LLM的API 就不做过多的介绍了,让我们来看看如何对LLM做预训练。
prompt: (截取部分片段,以下是做中文的翻译)
你是我的机械臂助手,机械臂内置了一些函数,请你根据我的指令,以json形式输出要运行的对应函数和你给我的回复
【以下是所有内置函数介绍】
机械臂位置归零,所有关节回到原点:back_zero()
放松机械臂,所有关节都可以自由手动拖拽活动:back_zero()
做出摇头动作:head_shake()
做出点头动作:head_nod()
做出跳舞动作:head_dance()
打开吸泵:pump_on()
关闭吸泵:pump_off()【输出json格式】
你直接输出json即可,从{开始,不要输出包含```json的开头或结尾
在'function'键中,输出函数名列表,列表中每个元素都是字符串,代表要运行的函数名称和参数。每个函数既可以单独运行,也可以和其他函数先后运行。列表元素的先后顺序,表示执行函数的先后顺序
在'response'键中,根据我的指令和你编排的动作,以第一人称输出你回复我的话,不要超过20个字,可以幽默和发散,用上歌词、台词、互联网热梗、名场面。比如李云龙的台词、甄嬛传的台词、练习时长两年半。
【以下是一些具体的例子】
我的指令:回到原点。你输出:{'function':['back_zero()'], 'response':'回家吧,回到最初的美好'}
我的指令:先回到原点,然后跳舞。你输出:{'function':['back_zero()', 'head_dance()'], 'response':'我的舞姿,练习时长两年半'}
我的指令:先回到原点,然后移动到180, -90坐标。你输出:{'function':['back_zero()', 'move_to_coords(X=180, Y=-90)'], 'response':'精准不,老子打的就是精锐'}智能视觉抓取
在这个过程中,只需要myCobot移动到俯视的一个位置,对目标进行拍摄,然后将拍摄后的照片交给视觉模型进行处理,获取到目标的参数就可以返回给机械臂做抓取运动。
调用相机进行拍摄
def check_camera():
cap = cv2.VideoCapture(0)
while(True):
ret, frame = cap.read()
# gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()讲图像交给大模型进行处理,之后得到的参数需要进一步的处理,绘制可视化的效果,最终将返回得到归一化坐标转化为实际图像中的像素坐标。
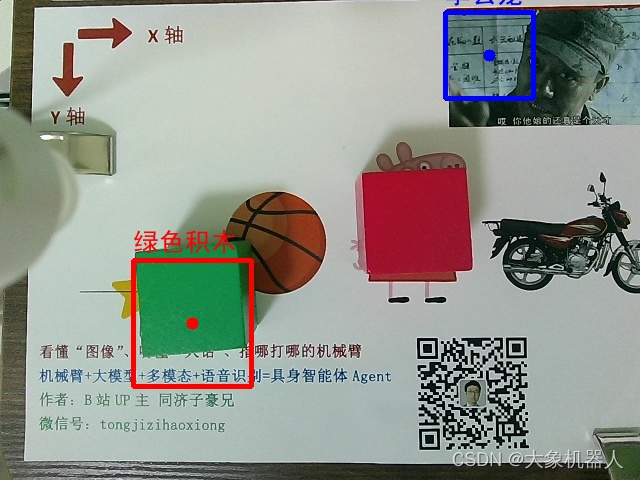
def post_processing_viz(result, img_path, check=False):
'''
视觉大模型输出结果后处理和可视化
check:是否需要人工看屏幕确认可视化成功,按键继续或退出
'''
# 后处理
img_bgr = cv2.imread(img_path)
img_h = img_bgr.shape[0]
img_w = img_bgr.shape[1]
# 缩放因子
FACTOR = 999
# 起点物体名称
START_NAME = result['start']
# 终点物体名称
END_NAME = result['end']
# 起点,左上角像素坐标
START_X_MIN = int(result['start_xyxy'][0][0] * img_w / FACTOR)
START_Y_MIN = int(result['start_xyxy'][0][1] * img_h / FACTOR)
# 起点,右下角像素坐标
START_X_MAX = int(result['start_xyxy'][1][0] * img_w / FACTOR)
START_Y_MAX = int(result['start_xyxy'][1][1] * img_h / FACTOR)
# 起点,中心点像素坐标
START_X_CENTER = int((START_X_MIN + START_X_MAX) / 2)
START_Y_CENTER = int((START_Y_MIN + START_Y_MAX) / 2)
# 终点,左上角像素坐标
END_X_MIN = int(result['end_xyxy'][0][0] * img_w / FACTOR)
END_Y_MIN = int(result['end_xyxy'][0][1] * img_h / FACTOR)
# 终点,右下角像素坐标
END_X_MAX = int(result['end_xyxy'][1][0] * img_w / FACTOR)
END_Y_MAX = int(result['end_xyxy'][1][1] * img_h / FACTOR)
# 终点,中心点像素坐标
END_X_CENTER = int((END_X_MIN + END_X_MAX) / 2)
END_Y_CENTER = int((END_Y_MIN + END_Y_MAX) / 2)
# 可视化
# 画起点物体框
img_bgr = cv2.rectangle(img_bgr, (START_X_MIN, START_Y_MIN), (START_X_MAX, START_Y_MAX), [0, 0, 255], thickness=3)
# 画起点中心点
img_bgr = cv2.circle(img_bgr, [START_X_CENTER, START_Y_CENTER], 6, [0, 0, 255], thickness=-1)
# 画终点物体框
img_bgr = cv2.rectangle(img_bgr, (END_X_MIN, END_Y_MIN), (END_X_MAX, END_Y_MAX), [255, 0, 0], thickness=3)
# 画终点中心点
img_bgr = cv2.circle(img_bgr, [END_X_CENTER, END_Y_CENTER], 6, [255, 0, 0], thickness=-1)
# 写中文物体名称
img_rgb = cv2.cvtColor(img_bgr, cv2.COLOR_BGR2RGB) # BGR 转 RGB
img_pil = Image.fromarray(img_rgb) # array 转 pil
draw = ImageDraw.Draw(img_pil)
# 写起点物体中文名称
draw.text((START_X_MIN, START_Y_MIN-32), START_NAME, font=font, fill=(255, 0, 0, 1)) # 文字坐标,中文字符串,字体,rgba颜色
# 写终点物体中文名称
draw.text((END_X_MIN, END_Y_MIN-32), END_NAME, font=font, fill=(0, 0, 255, 1)) # 文字坐标,中文字符串,字体,rgba颜色
img_bgr = cv2.cvtColor(np.array(img_pil), cv2.COLOR_RGB2BGR) # RGB转BGR
return START_X_CENTER, START_Y_CENTER, END_X_CENTER, END_Y_CENTER要用到手眼标定将图像中的像素坐标,转化为机械臂的坐标,以至于机械臂能够去执行抓取。
def eye2hand(X_im=160, Y_im=120):
# 整理两个标定点的坐标
cali_1_im = [130, 290] # 左下角,第一个标定点的像素坐标,要手动填!
cali_1_mc = [-21.8, -197.4] # 左下角,第一个标定点的机械臂坐标,要手动填!
cali_2_im = [640, 0] # 右上角,第二个标定点的像素坐标
cali_2_mc = [215, -59.1] # 右上角,第二个标定点的机械臂坐标,要手动填!
X_cali_im = [cali_1_im[0], cali_2_im[0]] # 像素坐标
X_cali_mc = [cali_1_mc[0], cali_2_mc[0]] # 机械臂坐标
Y_cali_im = [cali_2_im[1], cali_1_im[1]] # 像素坐标,先小后大
Y_cali_mc = [cali_2_mc[1], cali_1_mc[1]] # 机械臂坐标,先大后小
# X差值
X_mc = int(np.interp(X_im, X_cali_im, X_cali_mc))
# Y差值
Y_mc = int(np.interp(Y_im, Y_cali_im, Y_cali_mc))
return X_mc, Y_mc最后将全部的技术整合在一起就形成了一个完成的Agent了,就能够实现指哪打哪的功能。
https://www.youtube.com/watch?v=VlSQQJreIrI
总结
vlm_arm项目展示了将多个大模型与机械臂结合的巨大潜力,为人机协作和智能化应用提供了新的思路和方法。这一案例不仅展示了技术的创新性和实用性,也为未来类似项目的开发提供了宝贵的经验和参考。通过对项目的深入分析,我们可以看到多模型并行使用在提升系统智能化水平方面的显著效果,为机器人技术的进一步发展奠定了坚实基础。
离实现钢铁侠中的贾维斯越来越近了,未来电影中的画面终将会成为现实。