总的来说,JavaScript 逆向可以分为三大部分:寻找入口、调试分析和模拟执行。下面分别进行介绍。
一,寻找入口
一个网站加载了很多 JavaScript 文件,那么怎么从这么多 JavaScript 里面找到关键的位置,那就是一个关键问题。这就是寻找入口。
但开始寻找前,建议先做以下工作:
判断参数是否需要逆向,可不可以直接复制参数
加密参数是否由之前的请求返回
按加密字符串的特征进行尝试,也许会有意外收获
下面介绍寻找入口时常用的手段。
1.1 巧用搜索
搜索是有一定技巧的,比如加密关键词是 signature,可以搜索 signature、“signature”、signature=、signature: 、sign、URL、headers[ 等。
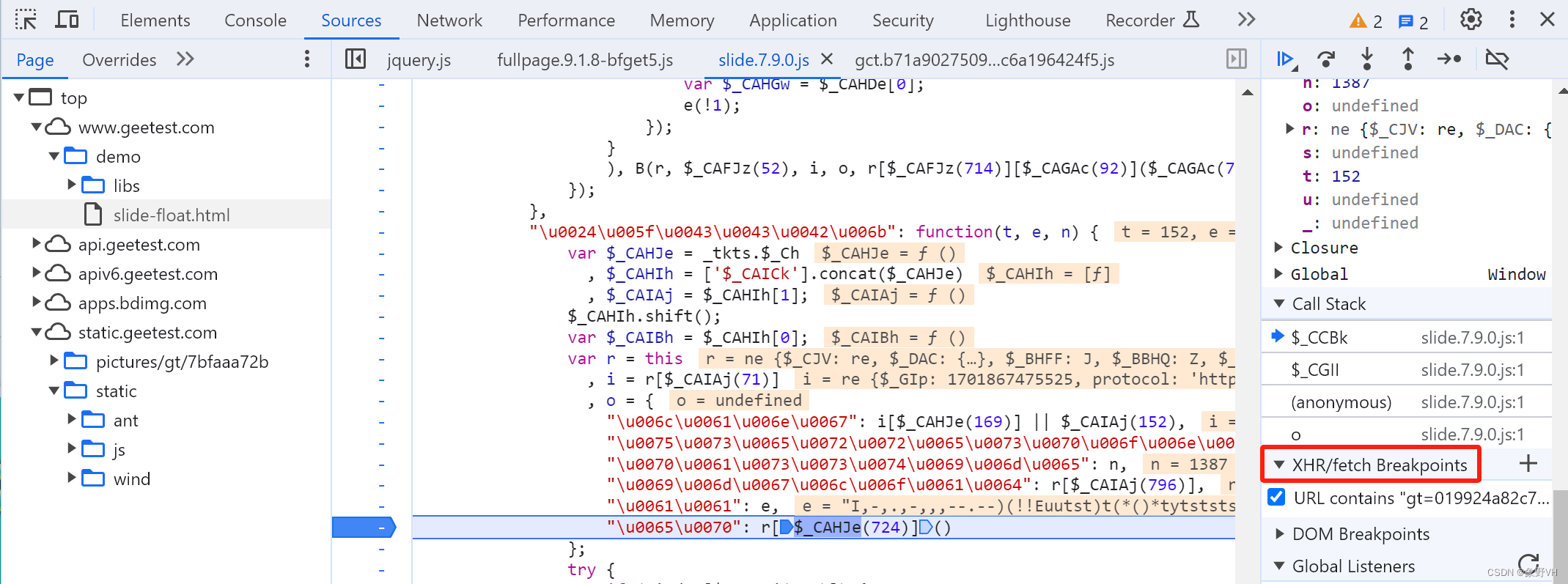
1.2 Ajax断点+调用栈
它可以在发生 Ajax 请求的时候触发断点。要设置断点,就要先观察 Ajax 请求,假设请求的 URL 为:https://spa2.scrape.center/api/movie/?limit=xxx&page=99
可以看到,URL 中包含 /api/movie ,因此可以填写 /api/movie ,当 Ajax 请求的 URL 包含填写的内容时,就会进入断点停止。
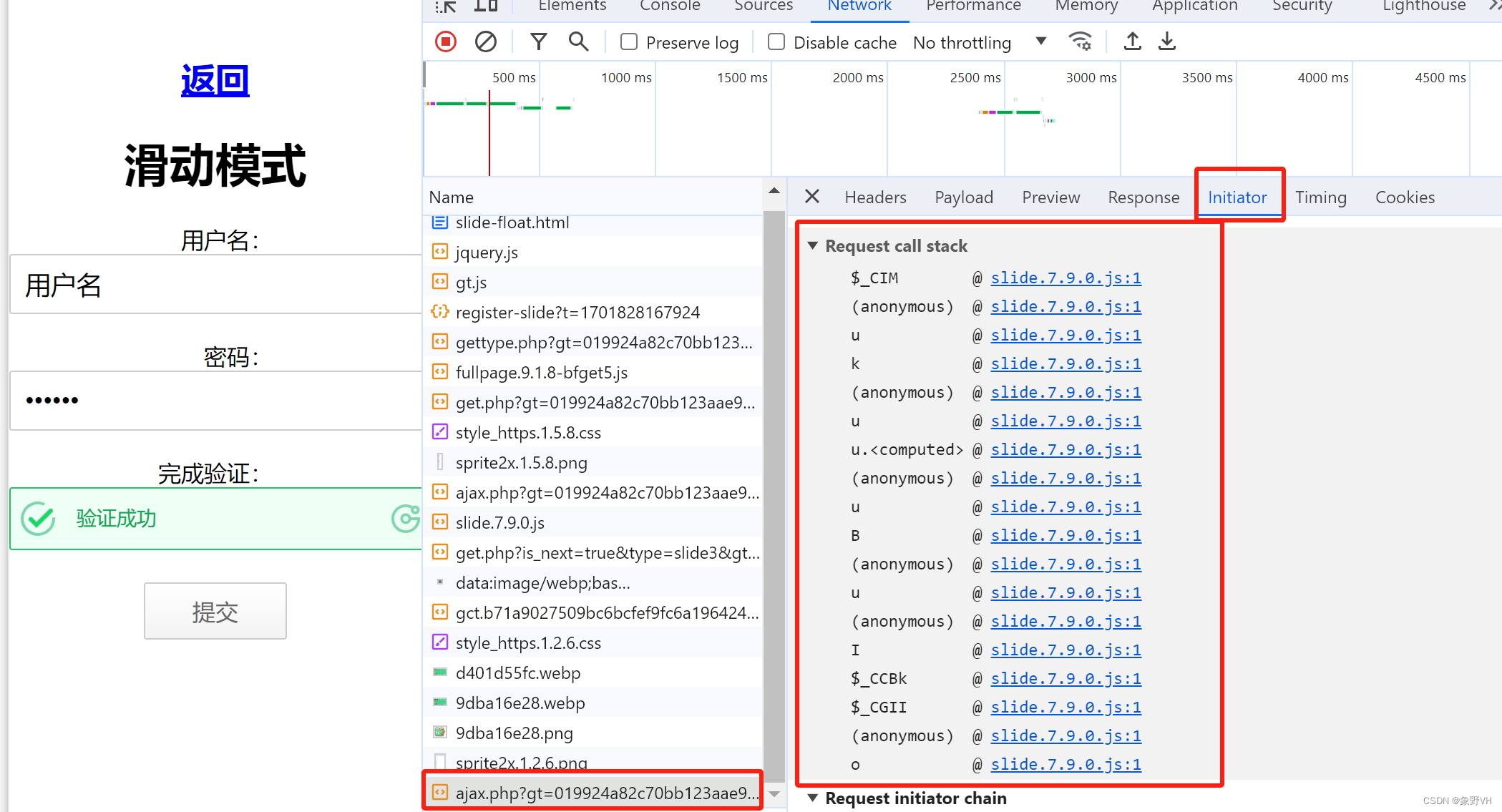
1.3 Initiator call stack
Initiator 主要是为了监听请求是怎样发起的,通过它可以快速定位到调用栈中。栈的调用顺序为从下到上。
1.4 事件监听+调用栈
有的时候找不到参数位置,但是知道它的触发条件,此时可以使用事件监听器进行断点。然后结合调用栈进行定位。
1.5 Hook 关键方法
Hook 技术又叫钩子技术,指在程序运行的过程中,对其中的某个方法进行重写,在原先的方法前后加入我们自定义的代码。相当于在系统没有调用该函数之前,钩子程序就先捕获该消息,得到控制权,这时钩子函数既可以加工处理该函数的执行行为,也可以强制结束消息的传递。
要对 JavaScript 代码进行 Hook 操作,就需要额外在页面中执行一些有关 Hook 逻辑的自定义代码,这里推荐一个浏览器插件,叫做 Tampermonkey,中文叫 油猴,利用它,可以在浏览器加载页面时自动执行某些 JavaScript 脚本。由于执行的是 JavaScript ,所以我们几乎可以在网页中完成任何我们想实现的效果,如自动爬虫、自动修改页面、自动响应事件等。
下面以 https://login1.scrape.center/ 网址为例,进行 base64 方法的 hook,以下为油猴中的脚本:
// ==UserScript==
// @name HookBase64
// @namespace https://login1.scrape.center/
// @version 0.1
// @description Hook Base64 encode function
// @author Vahan
// @match https://login1.scrape.center/
// @icon data:image/gif;base64,R0lGODlhAQABAAAAACH5BAEKAAEALAAAAAABAAEAAAICTAEAOw==
// @grant none
// ==/UserScript==
(function() {
'use strict';
function hook(object, attr){
var func = object[attr]
object[attr] = function(){
console.log('hooked',object,attr)
var ret = func.apply(object,arguments)
debugger
return ret
}
}
hook(window,'btoa')
})();
如果观察出一些门道,可以多使用这种方法来尝试,如 Hook encode 方法,decode 方法,stringify 方法,log 方法,alert 方法等。
二,调试分析
找到入口之后,我们需要搞清楚里面的逻辑是怎样的、里面调用了多少加密算法,经过了多少变量赋值和转换等,以便后面进行模拟调用或者逻辑改写。在这个过程中,我们主要借助浏览器的调试工具进行断点调试分析,或者借助于一些反混淆工具进行代码的反混淆等。
以下总结了一些调试分析时有用的技巧:
扣代码:扣代码时,同级目录的代码要扣全;
调试按钮:用的最多是逐行调试:
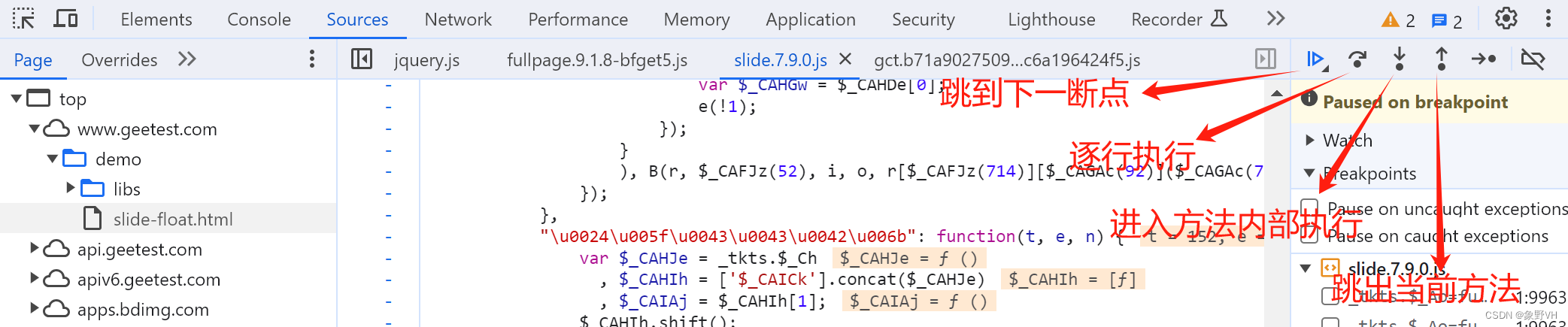
调用栈:可以看到 $_CCBk 的上一步是 $_CGII ,再上一步是 (anonymous)

改写 JavaScript 文件:
我们知道,一个网页里面的 JavaScript 是从对应服务器上下载下来并在浏览器执行的。有时,可能想要在调试的过程中对 JavaScript 做一些更改,比如说有以下需求:
- 发现 JavaScript 文件中包含很多阻扰调试的代码或者无效代码、干扰代码,想要将其删除
- 调试到某处,想要加一行 console.log 输出一些内容,以便观察某个变量或方法在页面加载过程中的调用情况。在某些情况下,这种方法比打断点调试更方便
- 调试过程遇到某个局部变量或方法,想要把它赋值给 window 对象以便全局可以访问或调用
- 在调试的时候,得到的某个变量中可能包含一些关键的结果,想要加一些逻辑将这些结果转发到对应的目标服务器
浏览器中的 Sources 面板的 Overrides 功能可以支持实现。在 Overrides 上选定一个本地的文件夹,用于保存需要更改的 JavaScript 文件。更改后保存,可以发现在选定的文件夹下生成了新的 JavaScript 文件,它用于在浏览器加载该 JavaScript 文件时进行替换。
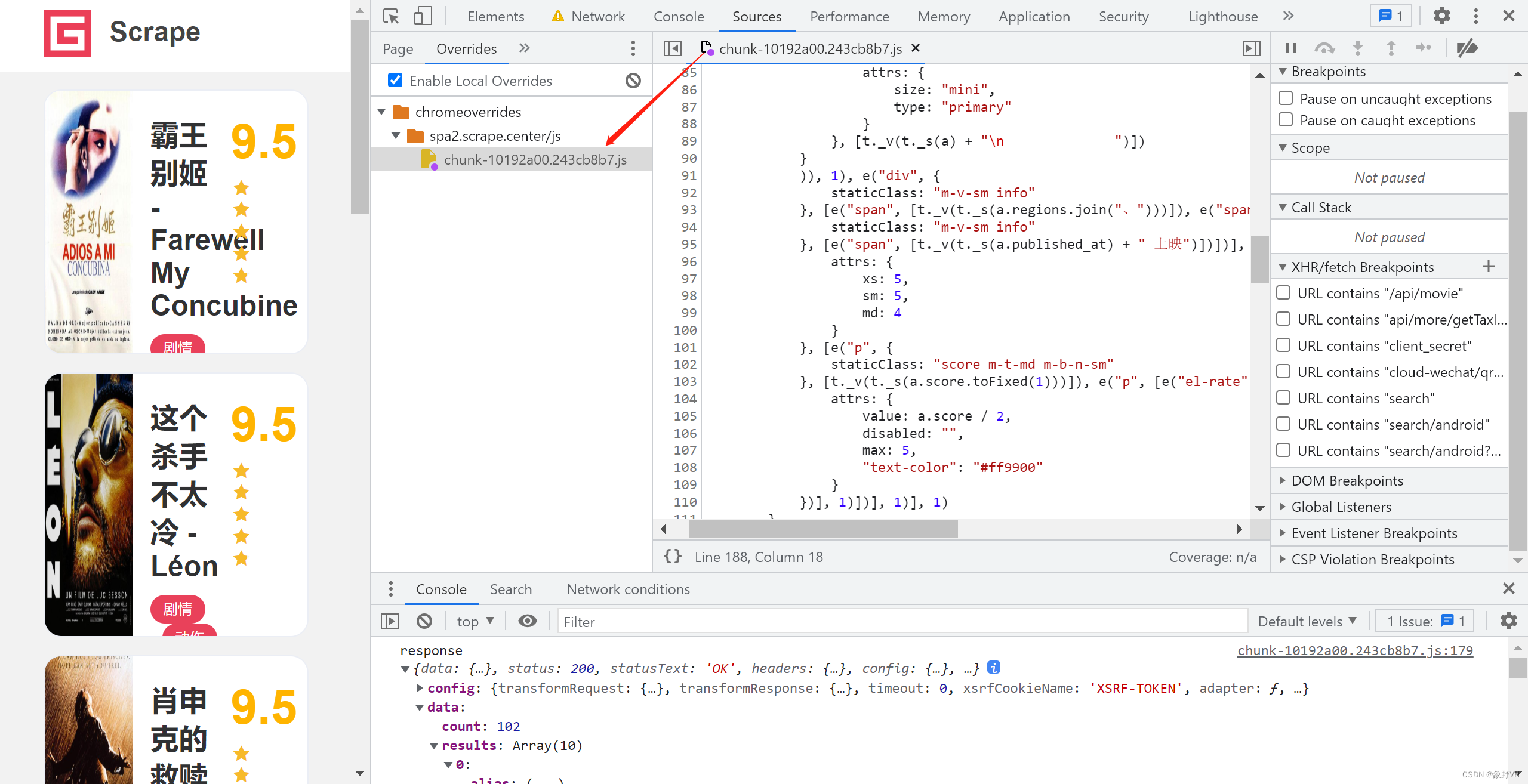
注意:若使用其他网站调试时生成的本地文件夹,则对于这个网页来说可能不能成功保存 JavaScript 文件,需要新创建一个文件夹。
三,模拟执行
搞清楚整个逻辑后,就需要对整个加密过程进行逻辑复写或者模拟执行,以把整个加密流程模拟出来。
3.1 Python 改写或模拟执行
如果整体逻辑不复杂的话,可以尝试用 python 把整个加密流程实现一遍。
如果整体逻辑较复杂,可以使用 python 来模拟调用 JavaScript 的执行。这种方法需要抠出加密代码及需要的运行环境(可能需要补浏览器环境)。
# pip install PyExecJS
# 前提是已经安装nodejs,相当于通过python来调用nodejs执行js文件
import execjs
#1.实例化一个node对象
node = execjs.get()
#2.js源文件编译
ctx = node.compile(open('./wechat.js',encoding='utf-8').read())
#3.执行js函数,wechat.js 文件中有 getpwd() 函数
funcName = 'getpwd("{}")'.format('123456')
pwd = ctx.eval(funcName)
print(pwd)
3.2 Nodejs 模拟执行 + API
与 python 调用几乎一样,都是将算法代码与调用代码抠出来放在一个 js 文件中,但 nodejs 调用的兼容性更好,需要修改调整的地方较 python 调用少,只是为了让 python 代码能使用,还需要通过 express 暴露成 HTTP 服务,从而实现跨语言的调用。
有了方式一,这种方式作用不大。
3.3 浏览器模拟执行
在算法难以实现时,可以使用 playwright 改写 js 文件,然后进行调用。这种方法只需定位到算法的位置,然后将加密函数挂到全局 window ,当作黑盒调用即可。
安装 playwright :
pip3 install playwright
playwright install

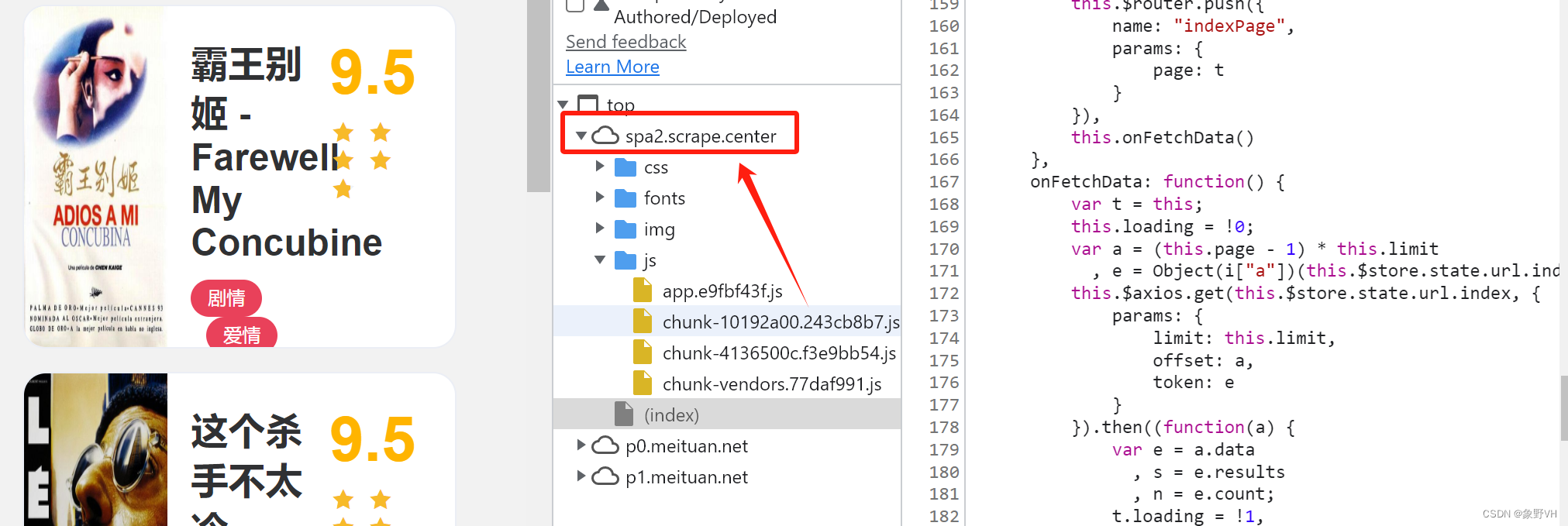
案例:https://spa2.scrape.center/
想要获取电影数据,就需要分析出 token 的加密逻辑:
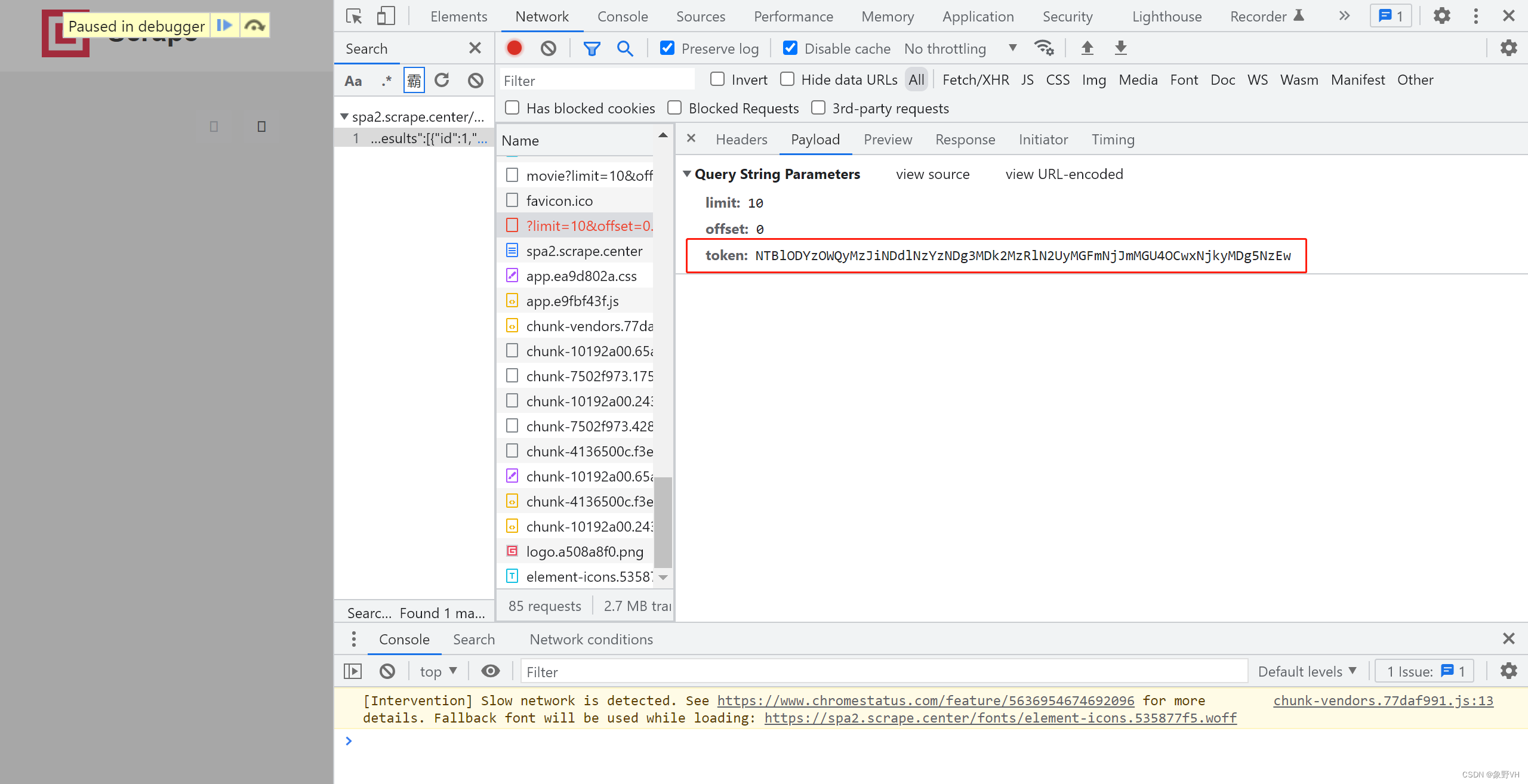
使用 XHR 断点,定位到核心加密算法的位置如下:
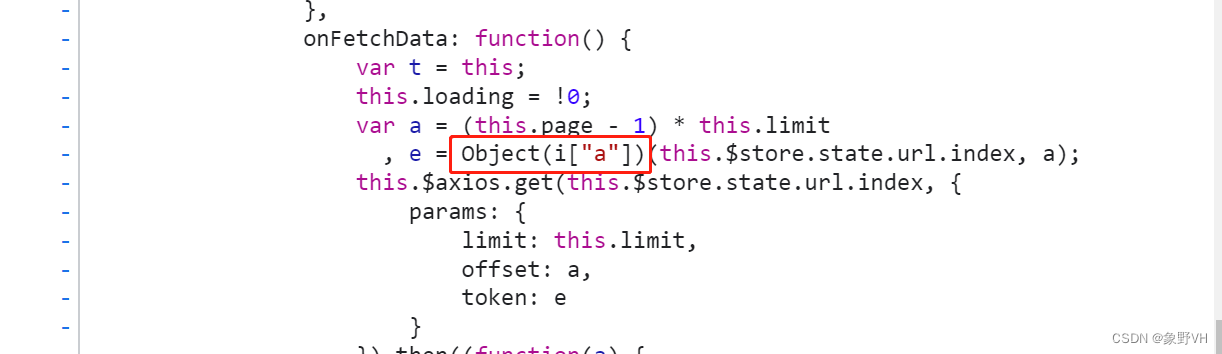
将修改后的整个 js 文件保存到本地,命名为 chunk.js:
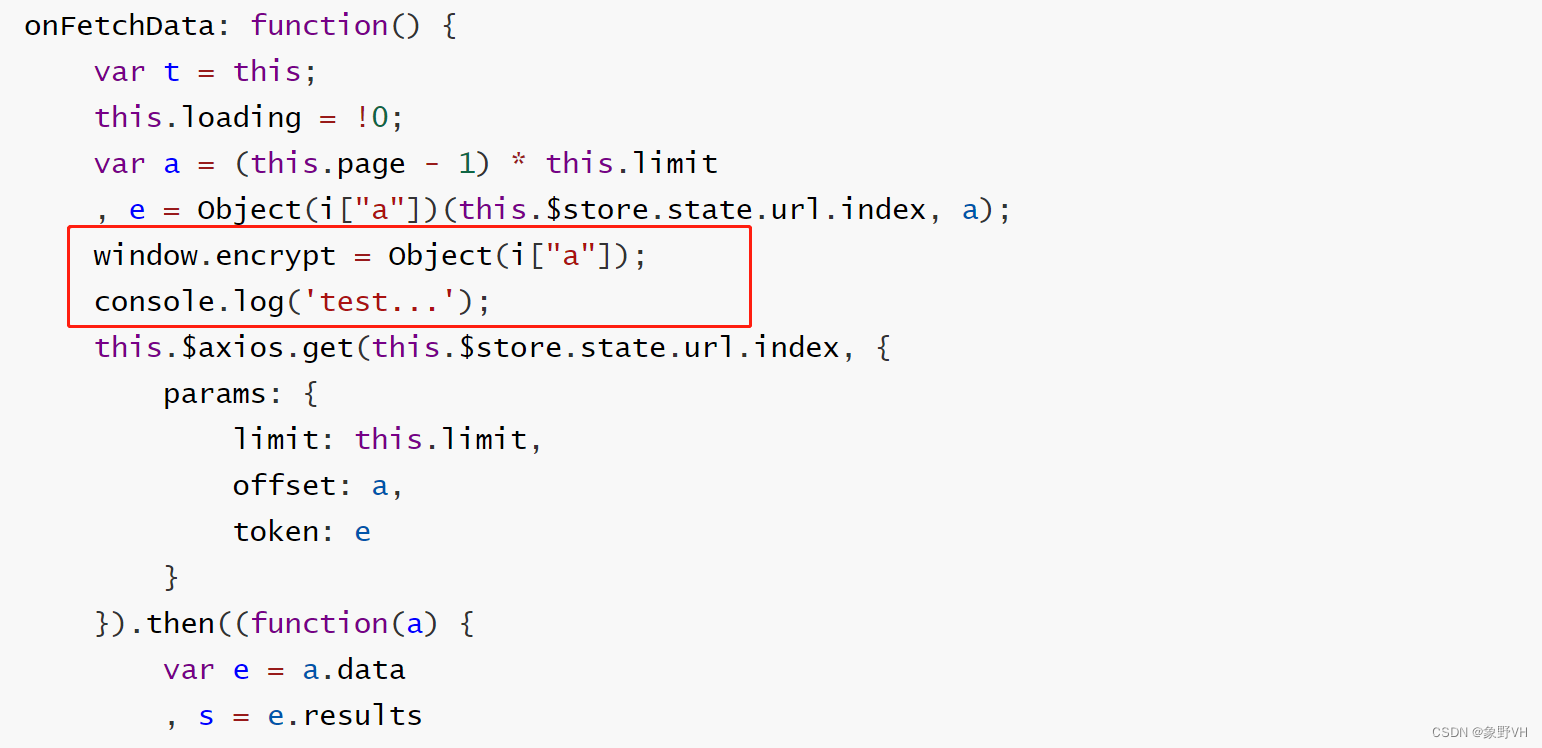
python 调用代码如下:
from playwright.sync_api import sync_playwright
import time
import requests
BASE_URL = 'https://spa2.scrape.center/'
INDEX_URL = BASE_URL + '/api/movie?limit={limit}&offset={offset}&token={token}'
MAX_PAGE = 10
LIMIT = 10
context = sync_playwright().start()
browser = context.chromium.launch(headless=True)
page = browser.new_page()
page.route( # 指定路由
"**/js/chunk-10192a00.243cb8b7.js",
lambda route: route.fulfill(path="./chunk.js")
)
page.goto(BASE_URL)
def get_token(offset):
result = page.evaluate('''() => {
return window.encrypt("%s","%s")
}''' % ('/api/movie', offset))
return result
for i in range(MAX_PAGE):
offset = i * LIMIT
token = get_token(offset)
index_url = INDEX_URL.format(limit=LIMIT,offset=offset,token=token)
response = requests.get(index_url)
print('response',response.json())

BASE_URL的值来自下图位置:
这种方法似乎是一种神技,以后实操用起来。
emm,在对今日头条案例的_signature使用这种方法时,未成功,返回None。暂时没有找到是哪里出了问题。
下面这种形式更加通用:
from playwright.sync_api import sync_playwright
BASE_URL = 'https://static.geetest.com/static/js/slide.7.9.2.js'
context = sync_playwright().start()
browser = context.chromium.launch(headless=True)
page = browser.new_page()
page.route(
"**/static/js/slide.7.9.2.js",
lambda route: route.fulfill(path="chunk.js")
)
page.goto(BASE_URL)
result = page.evaluate('''() => {
return window.vahan;
}''')
print(result)