
rm -r dp500 -f
git clone https://github.com/MicrosoftLearning/DP-500-Azure-Data-Analyst dp500

cd dp500/Allfiles/01
./setup.ps1


- On the Data page, view the Linked tab and verify that your workspace includes a link to your Azure Data Lake Storage Gen2 storage account, which should have a name similar to synapse*xxxxxxx* (Primary - datalake*xxxxxxx*).

- Right-click any of the files and select Preview to see the data it contains. Note that the files do not contain a header row, so you can unselect the option to display column headers.


In the sales folder, open the parquet folder and observe that it contains a subfolder for each year (2019-2021), in each of which a file named orders.snappy.parquet contains the order data for that year.

Select the csv folder, and then in the New SQL script list on the toolbar, select Select TOP 100 rows


In the Properties pane for SQL Script 1 that is created, change the name to Sales CSV query, and change the result settings to show All rows. Then in the toolbar, select Publish to save the script and use the Properties button (which looks similar to 🗏.) on the right end of the toolbar to hide the Properties pane.


-- This is auto-generated code
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/sales/csv/',
FORMAT = 'CSV',
PARSER_VERSION='2.0'
) AS [result]
Note the results consist of columns named C1, C2, and so on. In this example, the CSV files do not include the column headers. While it's possible to work with the data using the generic column names that have been assigned, or by ordinal position, it will be easier to understand the data if you define a tabular schema. To accomplish this, add a WITH clause to the OPENROWSET function as shown here (replacing datalakexxxxxxx with the name of your data lake storage account), and then rerun the query:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/sales/csv/',
FORMAT = 'CSV',
PARSER_VERSION='2.0'
)
WITH (
SalesOrderNumber VARCHAR(10) COLLATE Latin1_General_100_BIN2_UTF8,
SalesOrderLineNumber INT,
OrderDate DATE,
CustomerName VARCHAR(25) COLLATE Latin1_General_100_BIN2_UTF8,
EmailAddress VARCHAR(50) COLLATE Latin1_General_100_BIN2_UTF8,
Item VARCHAR(30) COLLATE Latin1_General_100_BIN2_UTF8,
Quantity INT,
UnitPrice DECIMAL(18,2),
TaxAmount DECIMAL (18,2)
) AS [result]
Select the parquet folder, and then in the New SQL script list on the toolbar, select Select TOP 100 rows.
-- This is auto-generated code
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/sales/parquet/**',
FORMAT = 'PARQUET'
) AS [result]
-- This is auto-generated code
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/sales/parquet/**',
FORMAT = 'PARQUET'
) AS [result]
SELECT YEAR(OrderDate) AS OrderYear,
COUNT(*) AS OrderedItems
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/sales/parquet/**',
FORMAT = 'PARQUET'
) AS [result]
GROUP BY YEAR(OrderDate)
ORDER BY OrderYear
Note that the results include order counts for all three years - the wildcard used in the BULK path causes the query to return data from all subfolders.
The subfolders reflect partitions in the parquet data, which is a technique often used to optimize performance for systems that can process multiple partitions of data in parallel. You can also use partitions to filter the data.
SELECT YEAR(OrderDate) AS OrderYear,
COUNT(*) AS OrderedItems
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/sales/parquet/year=*/',
FORMAT = 'PARQUET'
) AS [result]
WHERE [result].filepath(1) IN ('2019', '2020')
GROUP BY YEAR(OrderDate)
ORDER BY OrderYear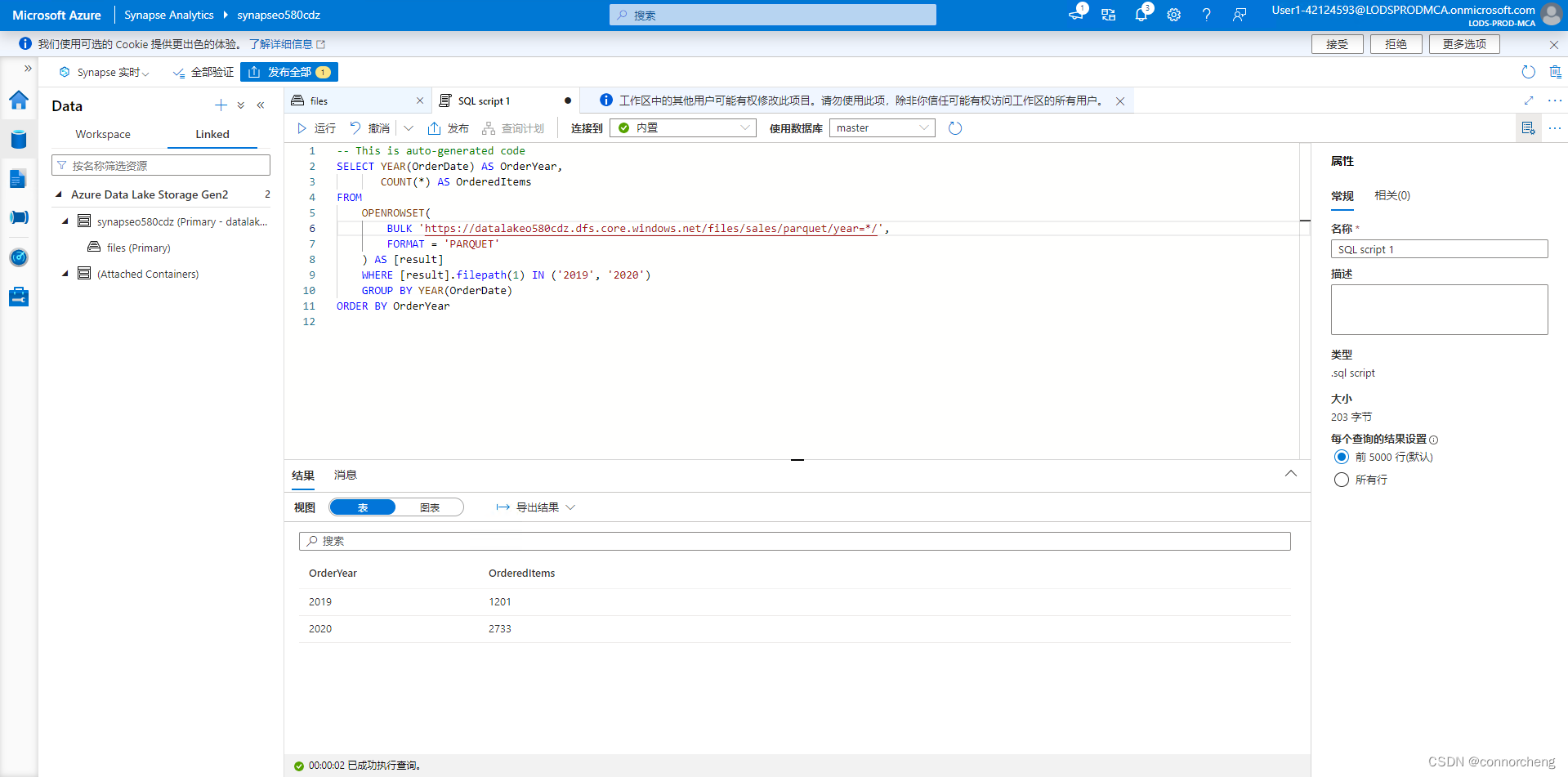
Name your script Sales Parquet query, and publish it. Then close the script pane.

-- This is auto-generated code
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/sales/json/',
FORMAT = 'CSV',
PARSER_VERSION = '2.0'
) AS [result]


Modify the script as follows (replacing datalakexxxxxxx with the name of your data lake storage account) to:
- Remove the parser version parameter.
- Add parameters for field terminator, quoted fields, and row terminators with the character code 0x0b.
- Format the results as a single field containing the JSON row of data as an NVARCHAR(MAX) string.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/sales/json/',
FORMAT = 'CSV',
FIELDTERMINATOR ='0x0b',
FIELDQUOTE = '0x0b',
ROWTERMINATOR = '0x0b'
) WITH (Doc NVARCHAR(MAX)) as rows
Modify the query as follows (replacing datalakexxxxxxx with the name of your data lake storage account) so that it uses the JSON_VALUE function to extract individual field values from the JSON data.
SELECT JSON_VALUE(Doc, '$.SalesOrderNumber') AS OrderNumber,
JSON_VALUE(Doc, '$.CustomerName') AS Customer,
Doc
FROM
OPENROWSET(
BULK 'https://datalakexxxxxxx.dfs.core.windows.net/files/sales/json/',
FORMAT = 'CSV',
FIELDTERMINATOR ='0x0b',
FIELDQUOTE = '0x0b',
ROWTERMINATOR = '0x0b'
) WITH (Doc NVARCHAR(MAX)) as rows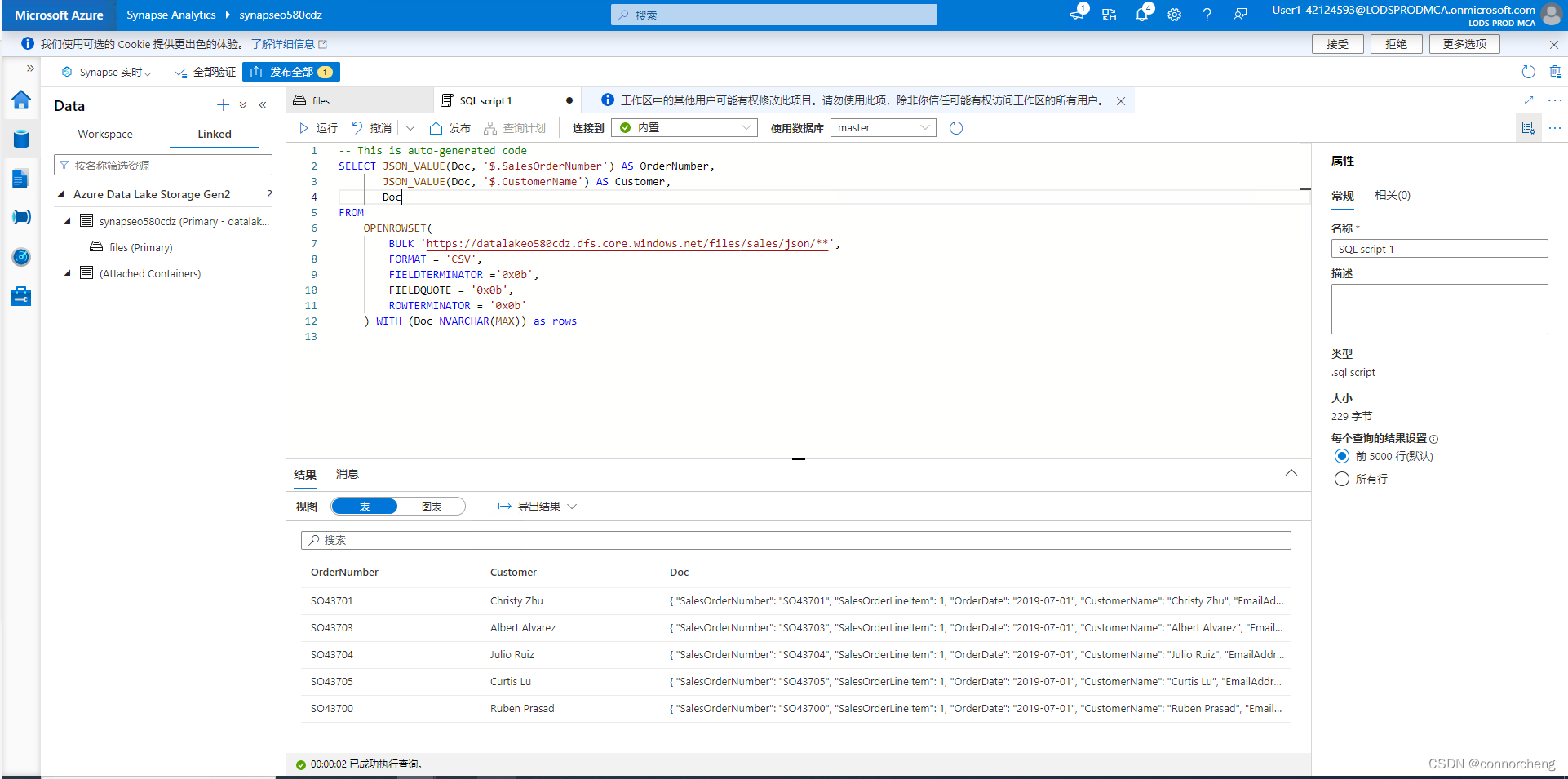

Access external data in a database
So far, you've used the OPENROWSET function in a SELECT query to retrieve data from files in a data lake. The queries have been run in the context of the master database in your serverless SQL pool. This approach is fine for an initial exploration of the data, but if you plan to create more complex queries it may be more effective to use the PolyBase capability of Synapse SQL to create objects in a database that reference the external data location.
Create an external data source
By defining an external data source in a database, you can use it to reference the data lake location where the files are stored.
CREATE DATABASE Sales
COLLATE Latin1_General_100_BIN2_UTF8;
GO;
Use Sales;
GO;
CREATE EXTERNAL DATA SOURCE sales_data WITH (
LOCATION = 'https://datalakexxxxxxx.dfs.core.windows.net/files/sales/'
);
GO;

Switch back to the Data page and use the ↻ button at the top right of Synapse Studio to refresh the page. Then view the Workspace tab in the Data pane, where a SQL database list is now displayed. Expand this list to verify that the Sales database has been created.
Expand the Sales database, its External Resources folder, and the External data sources folder under that to see the sales_data external data source you created
In the … menu for the Sales database, select New SQL script > Empty script. Then in the new script pane, enter and run the following query:
SELECT *
FROM
OPENROWSET(
BULK 'csv/*.csv',
DATA_SOURCE = 'sales_data',
FORMAT = 'CSV',
PARSER_VERSION = '2.0'
) AS orders

SELECT *
FROM
OPENROWSET(
BULK 'parquet/year=*/*.snappy.parquet',
DATA_SOURCE = 'sales_data',
FORMAT='PARQUET'
) AS orders
WHERE orders.filepath(1) = '2019'
Create an external table
The external data source makes it easier to access the files in the data lake, but most data analysts using SQL are used to working with tables in a database. Fortunately, you can also define external file formats and external tables that encapsulate rowsets from files in database tables.
CREATE EXTERNAL FILE FORMAT CsvFormat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS(
FIELD_TERMINATOR = ',',
STRING_DELIMITER = '"'
)
);
GO;
CREATE EXTERNAL TABLE dbo.orders
(
SalesOrderNumber VARCHAR(10),
SalesOrderLineNumber INT,
OrderDate DATE,
CustomerName VARCHAR(25),
EmailAddress VARCHAR(50),
Item VARCHAR(30),
Quantity INT,
UnitPrice DECIMAL(18,2),
TaxAmount DECIMAL (18,2)
)
WITH
(
DATA_SOURCE =sales_data,
LOCATION = 'csv/*.csv',
FILE_FORMAT = CsvFormat
);
GO

Refresh and expand the External tables folder in the Data pane and confirm that a table named dbo.orders has been created in the Sales database.

Run the SELECT script that has been generated, and verify that it retrieves the first 100 rows of data from the table, which in turn references the files in the data lake.
Note: You should always choose the method that best fits your specific needs and use case. For more detailed information, you can check the How to use OPENROWSET using serverless SQL pool in Azure Synapse Analytics and Access external storage using serverless SQL pool in Azure Synapse Analytics
Visualize query results
Now that you've explored various ways to query files in the data lake by using SQL queries, you can analyze the results of these queries to gain insights into the data. Often, insights are easier to uncover by visualizing the query results in a chart; which you can easily do by using the integrated charting functionality in the Synapse Studio query editor.
SELECT YEAR(OrderDate) AS OrderYear,
SUM((UnitPrice * Quantity) + TaxAmount) AS GrossRevenue
FROM dbo.orders
GROUP BY YEAR(OrderDate)
ORDER BY OrderYear;

Experiment with the charting functionality in the query editor. It offers some basic charting capabilities that you can use while interactively exploring data, and you can save charts as images to include in reports. However, functionality is limited compared to enterprise data visualization tools such as Microsoft Power BI.