模型部署学习笔记——模型部署关键知识点总结
- 模型部署学习笔记——模型部署关键知识点总结
-
- 1. CUDA中Grid和Block的定义是什么?Shared Memory的定义?Bank Conflict的定义?Stream和Event的定义?
- 2. TensorRT的工作流程?
- 3. ONNX是什么?如何从Pytorch导出ONNX?又如何将ONNX导入TensorRT?可能遇到的问题是什么?
- 4. Layer Fusion的方法有哪些?
- 5. FLOPS、TOPS、FLOPs等的定义是什么?Roofline Model是定义和用法?
- 6. 模型量化中PTQ和QAT的区别?Calibration的种类?常用的量化粒度有哪些?如果出现精度下降怎么办?
- 7. 什么是模型剪枝?模型剪枝的分类,各类剪枝的利弊都有哪些?
- 8. 模型推理中的基本框架?
- 9. 模型部署中的一些注意点
模型部署学习笔记——模型部署关键知识点总结
最近在工作之余学习了一些和模型部署相关的课程,本博客是对其中一些知识点的记录和总结,主要是模型部署中的一些基本概念。
1. CUDA中Grid和Block的定义是什么?Shared Memory的定义?Bank Conflict的定义?Stream和Event的定义?

Thread是执行计算任务的基本单位,每个线程执行同一内核函数(Kernel Function),但每个线程可以根据其Thread ID来处理不同的数据或计算任务:
- 线程是CUDA程序中并行计算的基本单位,它们通过Grid和Block组织起来,并执行内核函数。
- 每个线程通过Thread ID标识其在线程块中的位置,通过Block ID标识线程块在Grid中的位置。
- 线程之间可以通过共享内存和同步机制进行协调,但它们本身是独立执行的。
Block 是Grid的子集,每个Block内包含多个Thread,这些线程在同一个SM(Streaming Multiprocessor)上执行。Block是一个共享资源单元,在同一Block内的线程能够共享内存和同步执行。
- 每个Block有一个维度,通常为1D、2D或3D。
- Block中线程的数量是有限的,通常由硬件决定(每个Block最多1024个线程,具体限制取决于GPU架构)。
- 在同一个Block内,线程可以通过共享内存进行高效的通信。
Grid 是线程块(Block)的集合,表示了CUDA程序中的一个大规模并行计算任务的整体。每个Grid包含多个Block,这些Block可以在不同的SM(Streaming Multiprocessor)上并行执行。
- 一个Grid由多个线程块组成。
- 每个Grid有一个维度,通常为1D、2D或3D,具体取决于任务的需求。
- 每个Grid的大小通常由总的线程块数和每个Block中线程的数量决定。
Shared Memory是CUDA编程模型中的一种高效的内存类型,专门用于Block内部的线程之间的高速数据共享和通信。Shared Memory位于每个线程块内部,它比Global Memory要快得多,但每个Block只能访问其自己Block内的共享内存,不能访问其他Block的共享内存
不使用Shared Memory的代码如下:
__global__ void matrixMultiply(float *A, float *B, float *C, int N) {
int row = threadIdx.y + blockIdx.y * blockDim.y;
int col = threadIdx.x + blockIdx.x * blockDim.x;
if (row < N && col < N) {
float value = 0;
for (int i = 0; i < N; i++) {
value += A[row * N + i] * B[i * N + col];
}
C[row * N + col] = value;
}
}
使用Shared Memory的代码如下:
__global__ void matmul_shared_memory(float *A, float *B, float *C, int N) {
__shared__ float sharedA[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float sharedB[BLOCK_SIZE][BLOCK_SIZE];
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
float value = 0.0;
for (int k = 0; k < (N / BLOCK_SIZE); ++k) {
// Load data into shared memory
sharedA[threadIdx.y][threadIdx.x] = A[row * N + k * BLOCK_SIZE + threadIdx.x];
sharedB[threadIdx.y][threadIdx.x] = B[(k * BLOCK_SIZE + threadIdx.y) * N + col];
// Synchronize threads to ensure shared memory is filled
__syncthreads();
// Perform multiplication
for (int i = 0; i < BLOCK_SIZE; ++i) {
value += sharedA[threadIdx.y][i] * sharedB[i][threadIdx.x];
}
// Synchronize threads before the next iteration
__syncthreads();
}
// Store the result
C[row * N + col] = value;
}
Bank Conflict 是指当多个线程在同一时刻访问共享内存的同一Bank时发生的冲突。共享内存的访问速度比全局内存快得多,而通过将共享内存划分为多个Bank,能够让多个线程同时访问共享内存而不会发生冲突,从而提高性能。如果多个线程访问同一个Bank上的不同位置,硬件必须序列化这些访问,这样就会导致性能下降。一种比较简单地解决Bank Conflict问题的方法是在申请共享内存时进行Padding,如下:
#define N 32 // 假设线程块大小为32
__global__ void avoidBankConflict(float *data) {
__shared__ float shared[N + 1]; // 添加了padding,数组大小为N+1
int index = threadIdx.x;
// 原始数组数据存储
shared[index] = data[index];
// 示例计算:每个线程计算一个数据元素
shared[index] = shared[index] * 2.0f;
// 将结果存回全局内存
data[index] = shared[index];
}
其中shared[N + 1]中的N代表线程块中的线程数(假设为32),而我们给共享内存数组增加了1个额外元素(即N+1),这就是Padding。这样,线程0将访问shared[0],线程1访问shared[2],线程2访问shared[4],依此类推。通过间隔增加访问步长,避免了线程间的冲突。
Stream 是CUDA中的一种机制,用于管理异步执行的操作。同一个Stream的执行顺序和各个Kernel以及Memory Operation的启动顺序是一致的,但是只要资源没有被占用,不同流之间的执行时可以Overlap的,如下图所示:

如下是一个单流版本代码:
#include <cuda_runtime.h>
#include <stdio.h>
#define N (1 << 20) // 数据大小
#define NUM_STREAMS 4 // 数据块数量
__global__ void kernel(float *data, int size) {
int idx = blockIdx.x * blockDim.x + threadIdx.x;
if (idx < size) {
data[idx] *= 2.0f; // 简单的倍乘操作
}
}
void singleStreamExample() {
float *h_data, *d_data;
size_t size = N * sizeof(float);
cudaMallocHost(&h_data, size); // 主机内存
cudaMalloc(&d_data, size); // 设备内存
// 初始化数据
for (int i = 0; i < N; i++) h_data[i] = i;
cudaMemcpy(d_data, h_data, size, cudaMemcpyHostToDevice); // 数据传输
kernel<<<N / 256, 256>>>(d_data, N); // 内核执行
cudaMemcpy(h_data, d_data, size, cudaMemcpyDeviceToHost); // 数据返回
cudaFree(d_data);
cudaFreeHost(h_data);
}
如下是修改为多流版本的代码:
void multiStreamExample() {
float *h_data[NUM_STREAMS], *d_data[NUM_STREAMS];
cudaStream_t streams[NUM_STREAMS];
size_t size = (N / NUM_STREAMS) * sizeof(float);
// 为每个数据块分配内存和创建流
for (int i = 0; i < NUM_STREAMS; i++) {
cudaMallocHost(&h_data[i], size); // 主机内存
cudaMalloc(&d_data[i], size); // 设备内存
cudaStreamCreate(&streams[i]); // 创建流
// 初始化数据
for (int j = 0; j < N / NUM_STREAMS; j++) {
h_data[i][j] = j + i * (N / NUM_STREAMS);
}
}
// 使用多个流异步执行
for (int i = 0; i < NUM_STREAMS; i++) {
cudaMemcpyAsync(d_data[i], h_data[i], size, cudaMemcpyHostToDevice, streams[i]); // 异步数据传输
kernel<<<(N / NUM_STREAMS) / 256, 256, 0, streams[i]>>>(d_data[i], N / NUM_STREAMS); // 异步内核执行
cudaMemcpyAsync(h_data[i], d_data[i], size, cudaMemcpyDeviceToHost, streams[i]); // 异步数据返回
}
// 等待所有流完成
for (int i = 0; i < NUM_STREAMS; i++) {
cudaStreamSynchronize(streams[i]); // 等待每个流完成
}
// 释放资源
for (int i = 0; i < NUM_STREAMS; i++) {
cudaFree(d_data[i]);
cudaFreeHost(h_data[i]);
cudaStreamDestroy(streams[i]);
}
}
Event 是CUDA中的一种机制,用于标记某些操作的完成,并允许用户在不同的流或操作之间进行同步。事件通常用于监控计算或内存操作的进度,并在不同流之间建立同步依赖关系。如下是使用Event对Stream进行时间测量的代码:
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, 0);
// 调用 singleStreamExample 或 multiStreamExample
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float milliseconds = 0;
cudaEventElapsedTime(&milliseconds, start, stop);
printf("Execution time: %f ms\n", milliseconds);
cudaEventDestroy(start);
cudaEventDestroy(stop);
2. TensorRT的工作流程?
TensorRT 的工作流程是:
- 模型导入:通过工具(如Tensorflow中的tf2onnx或PyTorch中的torch.onnx.export)将训练好的模型转换为ONNX格式再加载到TensorRT中,或者通过Tensor API手动构建模型。
- 模型优化:TensorRT中模型优化策略包括Layer& Tensor Fusion,Kernel Auto-Tuning、Quantization等,如下图所示:

- 推理引擎构建:即使用优化后的模型构建一个高效的推理引擎(Engine)。推理引擎是一个轻量化、高性能的运行时表示,仅用于推理。
- 模型推理:将Engine部署到端侧,输入实时数据进行推理。
3. ONNX是什么?如何从Pytorch导出ONNX?又如何将ONNX导入TensorRT?可能遇到的问题是什么?
- ONNX(Open Neural Network Exchange)是一个开放的深度学习模型交换格式,旨在实现不同深度学习框架之间的互操作性。
ONNX采用Protobuf二进制形式进行序列化模型。模型的组织结构由几个主要的组件构成如下,如下是一个简化的 ONNX 模型的组织结构:
ModelProto
├── ir_version: 7
├── producer_name: "PyTorch"
├── producer_version: "1.10"
├── model_version: 1
├── graph
│ ├── name: "example_graph"
│ ├── node
│ │ ├── op_type: "Conv"
│ │ ├── input: ["input_tensor", "weight"]
│ │ ├── output: ["output_tensor"]
│ │ └── attribute: [{name: "kernel_shape", value: [3,3]}]
│ ├── node
│ │ ├── op_type: "Relu"
│ │ ├── input: ["output_tensor"]
│ │ └── output: ["relu_output"]
│ ├── input: ["input_tensor"]
│ ├── output: ["relu_output"]
│ ├── initializer: [weight_tensor]
│ └── value_info: [intermediate_tensor]
├── metadata_props: []
其中,ModelProto 包含了模型的基本信息;GraphProto 包含了一个名为 example_graph 的计算图,该图包含两个节点(一个卷积层和一个 ReLU 激活层);NodeProto 定义了每个操作节点,例如卷积层(Conv)和 ReLU 层(Relu);TensorProto 用于表示图中的张量(如 weight_tensor 和 input_tensor)。
- 从Pytorch导出ONNX方法如下:
import torch
import torch.onnx
# 假设你有一个训练好的 PyTorch 模型 `model`
model = ... # 加载或定义你的模型
model.eval() # 设置为评估模式
# 输入示例数据,应该与模型的输入形状相同
dummy_input = torch.randn(1, 3, 224, 224) # 示例输入(假设是一个图片输入)
# 导出模型为 ONNX 文件
onnx_path = "model.onnx"
torch.onnx.export(model, dummy_input, onnx_path, input_names=['input'], output_names=['output'])
- 将ONNX导入TensorRT方法如下:
import tensorrt as trt
import onnx
# 1. 加载 ONNX 模型
onnx_model_path = "model.onnx"
onnx_model = onnx.load(onnx_model_path)
# 2. 创建 TensorRT 的 ONNX 解析器
TRT_LOGGER = trt.Logger(trt.Logger.WARNING)
builder = trt.Builder(TRT_LOGGER)
network = builder.create_network(common.EXPLICIT_BATCH)
parser = trt.OnnxParser(network, TRT_LOGGER)
# 3. 解析 ONNX 模型并构建 TensorRT 引擎
with open(onnx_model_path, 'rb') as f:
parser.parse(f.read())
# 4. 构建 TensorRT 引擎
engine = builder.build_cuda_engine(network)
# 5. 使用 TensorRT 引擎执行推理(需要设置执行上下文等)
- 从Pytorch到出ONNX的时候有时候会遇到导出失败的问题,此时解决方案通常如下:
(1)修改opset的版本:查看不支持的算子在新的opset中是否被支持,以及onnx-tensorrt中是否被支持。opset支持的算子通常在ONNX算子文档有列出,onnx-tensorrt 支持的算子集通常会在其官方文档中列出。
(2)替换pytorch中的算子组合:即将某些计算替换为onnx中可以识别的算子。
(3)在pytorch登记onnx中某些算子:有可能onnx中支持,但是pytorch中没有被登记,登记方式可以使用 torch.onnx.export 的 custom_opsets 注册自定义算子或者通过 torch.onnx.symbolic 定义算子的符号
(4)直接修改onnx,创建plugin:这种方法需要使用onnx-surgeon,onnx-surgeon是一个Python 库,用于对ONNX模型进行修改和修剪。它允许用户通过 API 对 ONNX 模型的结构进行编辑、调整和修剪,支持添加、删除、修改节点等操作。
以上四种解决方案难度由易到难。
4. Layer Fusion的方法有哪些?
Layer Fusion是指将多个层可以通过融合来优化计算。Layer Fusion分为Horizontal Layer Fusion和Vertical Layer Fusion。Vertical Layer Fusion中典型的融合方式有Conv+ReLU、Conv+BN+ReLU,Horizontal Layer Fusion是将水平方向上同类Layer进行融合,如下图所示是两类融合方式的示意图;

Vertical Layer Fusion融合结果:

Horizontal Layer Fusion融合结果:

为什么融合可以减少计算量呢,我们知道BN的公式如下: y i = γ ∗ x i − μ B σ B 2 + ϵ + β y_i=\gamma * \frac{x_i-\mu_B}{\sqrt{\sigma_B^2+\epsilon}}+\beta yi=γ∗σB2+ϵxi−μB+β其中 γ \gamma γ和 β \beta β为可学习参数, μ B = 1 B ∑ i = 1 B x i \mu_B=\frac{1}{B} \sum_{i=1}^B x_i μB=B1∑i=1Bxi, σ B 2 = 1 B ∑ i = 1 B ( x i − μ B ) 2 + ϵ \sigma_B^2=\frac{1}{B} \sum_{i=1}^B\left(x_i-\mu_B\right)^2+\epsilon σB2=B1∑i=1B(xi−μB)2+ϵ,我们将卷积公式 x i = w ∗ x i + b x_i=w * x_i+b xi=w∗xi+b代入得: y = γ ∗ w ∗ x + b − μ B σ B 2 + ϵ + β y=\gamma * \frac{w * x+b-\mu_B}{\sqrt{\sigma_B^2+\epsilon}}+\beta y=γ∗σB2+ϵw∗x+b−μB+β进一步展开和代换可得: y = ( γ ∗ w σ B 2 + ϵ ) ∗ x + ( γ σ B 2 + ϵ ( b − μ B ) + β ) y=\left(\frac{\gamma * w}{\sqrt{\sigma_B^2+\epsilon}}\right) * x+\left(\frac{\gamma}{\sqrt{\sigma_B^2+\epsilon}}\left(b-\mu_B\right)+\beta\right) y=(σB2+ϵγ∗w)∗x+(σB2+ϵγ(b−μB)+β)我们定义 w ^ = γ ∗ w σ B 2 + ϵ \widehat{w}=\frac{\gamma * w}{\sqrt{\sigma_B^2+\epsilon}} w
=σB2+ϵγ∗w b ^ = γ σ B 2 + ϵ ( b − μ B ) + β \hat{b}=\frac{\gamma}{\sqrt{\sigma_B^2+\epsilon}}\left(b-\mu_B\right)+\beta b^=σB2+ϵγ(b−μB)+β由于 γ \gamma γ和 β \beta β在训练完成后都是已知的,因此我们可以将上述公式简化为: y = w ^ ∗ x + b ^ y=\widehat{w} * x+\hat{b} y=w
∗x+b^这样Conv+BN的计算量就和Conv本身基本接近。而ReLU只是做一个截取,因此进行融合。
5. FLOPS、TOPS、FLOPs等的定义是什么?Roofline Model是定义和用法?
| 名词 | 缩写/单位 | 定义和作用 |
|---|---|---|
| 计算峰值 | FLOPS (Floating point number operations per second) | 表示每秒钟进行的浮点运算次数,是衡量计算机性能的一个常见指标 |
| 计算峰值 | TOPS (Tera operations per second) | 表示每秒钟处理的整型运算的次数,是衡量计算机性能的另一个指标 |
| 计算量 | FLOPs(Floating point number operations) | 表示模型中有多少个浮点运算,是衡量模型大小的一个指标 |
| 参数量 | Byte | 表示模型中所有的weights的量,是另一个衡量模型大小的指标,指的注意的是conv的参数量和input/output无关,而transformer的参数会根据输入tensor的大小改变而改变 |
| 访存量 | Byte | 表示模型中模型中某一个算子或者某一个layer进行计算时需要与memory产生读写的量,是分析模型中某些计算的计算效率的标准之一 |
| 带宽量 | Byte/s | 表示的是单位时间内可以传输的数据量的多少,是衡量计算机硬件memory的性能的标准之一 |
| 计算密度 | Operation Intensity(FLOPs/Bytes) | 表示的是单位数据可以进行的浮点运算数,计算密度=计算量/访存量 |
Roofline Model 是一种用于描述计算机系统性能的可视化模型,特别用于展示计算密集型任务的性能瓶颈,如下图所示:

X轴表示计算密集度,单位为 FLOP/byte(浮点运算数与内存数据量的比率)。它衡量了应用程序的计算与数据访问的关系,通常越高表示计算密集度越大。Y轴表示计算性能,通常单位是 FLOPS(浮点运算每秒),即系统能够执行的浮点运算数。
实际应用的表现会被标示在 Roofline 图中,通常是在 Roofline 上下限之间。如果应用的性能接近 Roofline,那么它就已经接近硬件的理论最大性能;如果远低于 Roofline,则意味着有潜在的性能瓶颈,如上图中标识的,Algorithm Fully-connected计算密度过低,因此没法充分利用硬件性能,而Algorithm 2 Convolution已经达到Roofline。
这里我们可以给出一些结论:
(1)对于Convlution,随着Kernel Size、Output Size、Channel Size的增大计算密度都是增大的,但是计算密度增长率会逐渐下降;
(2) 1 × 1 1\times 1 1×1 Conv,Depth Wise Conv虽然计算量小,但是其计算密度很低;
(3)Fully Connected Layer计算密度非常小;
(4)模型中Reshape操作多也会导致整个模型的计算密度下降。
6. 模型量化中PTQ和QAT的区别?Calibration的种类?常用的量化粒度有哪些?如果出现精度下降怎么办?
- PTQ和QAT的区别如下:
PTQ (Post-Training Quantization) 是一种在模型训练完成后对模型进行量化的方法。它不需要重新训练模型,而是通过在训练好的模型上直接应用量化算法来减少模型的存储需求和加速推理过程。其优点是方便,缺点是会掉精度;
(1)TensorR的Kernel Autotuning会选择核函数来做FP16/INT8的计算,有可能会出现FP16在Tensor Core上计算,而INT8则在Cuda Core上,这样就有可能导致INT8量化后的速度反而比FP16/FP32要慢。
(2)量化后可能会导致层融合失效,这样也可能会导致INT8量化速度反而变慢的问题。
(3)量化过程中需要注意Sensitive Analysis,对于位于输入和输出的敏感层应该尽量使用FP16进行量化。
QAT(Quantization-Aware Training) 是一种在训练过程中就引入量化操作的技术,通过在训练时模拟低精度的运算来帮助模型适应量化带来的误差。其优点是精度高,缺点是实现复杂
(1)QAT通常通过Q/DQ Node实现,Q/DQ Node也被称为Fake Quantization Node实现,用来模拟FP32->INT8量化的Scale和Shift,以及INT8->FP32的反量化的Scale和Shift,QAT通过Q和DQ Node里面存储的信息对FP32或者INT8进行线性变换。
(2)QAT是一种Fine-Tuning方式,通过一个Pre-Trained Model进行添加Q/DQ节点模拟量化,并通过训练来更新权重去吸收量化过程带来的误差。添加Q/DQ节点后算子会以INT8精度执行

Calibration的种类有:
(1)Minmax Calibration、Entropy Calibration、Percentile Calibration;
(2)如果Floating Point的分布比较分散,各个区间下都比较均匀,Minmax Calibration是一个不错的选择;
(3)目前TensorRT使用默认是Entropy Calibration。一般来讲Entropy Calibration精度可以比较好;
(4)Weight一般使用Minmax Calibration(信息尽量不要有遗漏),Activation Values一般使用Entropy或者Percentile Calibration(不同Layer的Activation Values值分布会有较大不同);
(5)Calibration时Batch Size会影响精度,总的来讲,Batch Size越大越好,但不是绝对的。常用的量化粒度:
(1)Per-tensor 量化:在 Per-tensor 量化中,整个张量的所有元素使用相同的量化尺度和偏移量。也就是说,对于一个特定的层或整个网络的某一张量,所有的元素都共享一个全局的量化范围。其优点是延迟低,缺点是错误率高,因此一个Scale很难覆盖所有FP32的Dynamic Range。
(2)Per-channel 量化:在 Per-channel 量化中,每个通道(例如卷积核或特征图的通道)会使用独立的量化范围。这意味着每个通道的激活值或权重会有不同的量化尺度和偏移量。其优点是低错误率,缺点是高延迟,因为需要使用vector来存储一个Channel的Scale。
(3)Weight的量化一般会选取Per-Channel量化(因为BN的参数会融合在线性计算中,BN的参数是Per-Channle的,此外还有Depthwise Convolution的存在),Activation Values的量化一般会选取Per-Tensor量化。如果出现精度下降怎么办?
在我们进行模型量化时,
(1)第一步应该先进行PTQ,尝试多种Calibration算法,如果精度不满足考虑进行第二步,
(2)第二步应该是进行Partial-Quntization,通过Layer-wise的Sensitive Analysis分析每一层精度损失,尝试FP16+INT8的组合,将FP16用在敏感层,INT8用在计算密集层,如果精度还不满足再考虑第三步,
(3)第三步才是QAT,通过Fine-Tuning来训练权重(原本训练的10%个Epoch)。
量化后精度下降控制在相对精度损失小于2%是合理的
7. 什么是模型剪枝?模型剪枝的分类,各类剪枝的利弊都有哪些?
模型剪枝(Model Pruning) 是一种深度学习模型优化技术,旨在减少模型的复杂度(比如模型的参数数目或计算量),从而提升推理速度、减少内存占用并提高模型的部署效率。它通过移除不重要的模型参数,使得模型更加紧凑。步骤通常如下:
(1)获取一个已经训练好的初始模型
(2)对这个模型进行剪枝
1. 可以通过训练的方式让模型去学习哪些权重可以归零,例如使用L1 Regularization和BN的Scaling Factor让权重归零;
2. 自定义一些规则手动地让某些权重归零,例如对 1 × 4 1\times 4 1×4的Vector进行2:4的Weight Prunning;
(3)对剪枝后的模型进行Fine-tuning(剪枝后初期模型通常会掉点,通过Fine-tuning来恢复精度)
(4)获取到一个压缩的模型模型分类通常分为结构化剪枝和非结构化剪枝、粗粒度剪枝和细粒度剪枝
(1)粗粒度剪枝
1. 比较常见的是Channel/Kernel Pruning,通常是使用L1 Norm寻找权重中影响度比较低的卷积核
2. 优势是不依赖硬件,劣势是更容易掉精度,剪枝后可能反而不适合硬件加速(Tensor Core的使用条件是Channel是8或者16的倍数)
(2)细粒度剪枝
1. 细粒度剪枝可以进一步分为结构化剪枝(Vector-wise和Block-wise)和非结构化剪枝(Element-wise)
2. 优势是对精度影响较小,劣势是需要特殊硬件支持(Tensor Core可以支持Sparse)以及需要额外的Memory来存储哪些Index是可以保留计算的Channel-Level Pruning
参考文章是Learning Efficient Convolutional Networks through Network Slimming,主要思路是通过使用BN中的Scaling Factor与L1-Regularization的训练可以让权重趋于0,找到Conv中不是很重要的Channel,实现Channel-Level的Pruning。
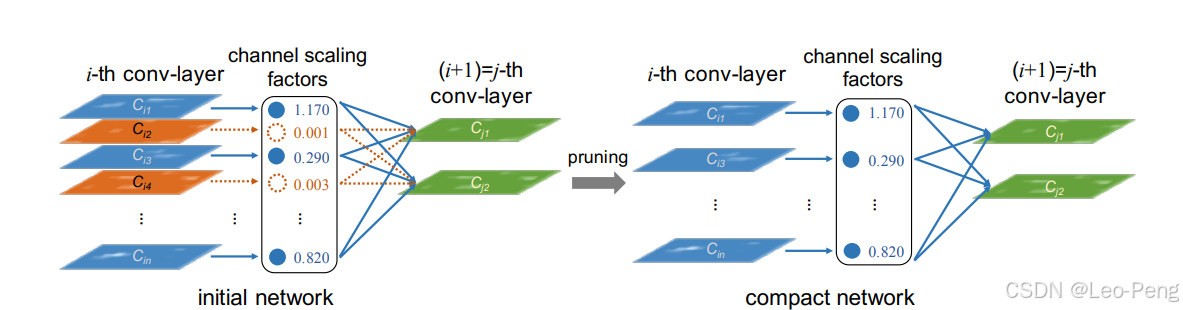
(1)L1 Regularization可以用来系数参数或者让参数趋向于零,L2 Regularization可以用来减小参数值的大小,这个通过L1 Regularization的公式就能理解: L = min f ( x ) + λ ∑ i = 1 n ∣ w i ∣ L=\min f(x)+\lambda \sum_{i=1}^n\left|w_i\right| L=minf(x)+λi=1∑n∣wi∣(2)Batch Normalization通常放在Conv之后对Conv的输出进行Normalization。整个计算是Channel-wise的,每个Channel都拥有自己的BN参数,如果Batch Normalization之后发现某一个Channle的Scaling非常小或者为零,那么就可以认为这个Channel参与的计算没有非常的大强度的改变或者特征提取,可以忽略。
(3)使用Batch Normalization和L1 Regularization对模型的权重进行计算和重要度排序: L = ∑ ( x , y ) l ( f ( x , W ) , y ) + λ ∑ γ ∈ Γ g ( γ ) g ( s ) = ∣ s ∣ L=\sum_{(x, y)} l(f(x, W), y)+\lambda \sum_{\gamma \in \Gamma} g(\gamma) \quad g(s)=|s| L=(x,y)∑l(f(x,W),y)+λγ∈Γ∑g(γ)g(s)=∣s∣这里和普通的L1 Regularization区别是惩罚的不再是每一个权重,而是Batch Normalization对于Conv中每一个Channel的Scaling Factor。从而在学习过程中使得Scaling Factor趋近于零。如上图所示我们可以将 C i 2 C_{i2} Ci2和 C i 4 C_{i4} Ci4去除掉。
8. 模型推理中的基本框架?
当我们对不同模型部署的时候可以发现:
(1)不管是分类、分割还是检测,模型推理的流程都是 前处理->模型推理->后处理;
(2)在创建推理引擎时,流程都是bulider->nertwork->config->serialize->save file;
(3)在执行推理引擎时,流程都是load file->deserialize->engine->context->enqueue;
(4)在模型推理中用得比较多的设计模式是工厂模式和消费者-生产者模式;
研究开源代码推荐Lidar_AI_Solution
9. 模型部署中的一些注意点
- FLOPs不能完全衡量模型性能,
(1)因为FLOPs只是模型大小的单位
(2)模型性能还需要考虑访存量、和计算无关的DNN部分(Reshape、Shortcut等)、和DNN以外的部分(前处理、后处理) - 模型部署不能完全依靠TensorRT
(1)计算密度低的 1 × 1 1\times 1 1×1 Conv,Depth Wise Conv不会重构;
(2)GPU无法优化的地方会到CPU执行,此时需要手动修改代码实现部分,让部分CPU执行转到GPU;
(3)部分冗长的计算,TensorRT可能为了优化天机一些多余的操作,比如reformatter这种;
(4)存在TensorRT尚未支持的算子
(5)TensorRT不一定会分配Tensor Core,因为TensorRT Kerner Auto Tunning会选择最合适的Kernel; - CUDA Core和Tensor Core的使用
(1)因此Kernel Auto Tuning自动选择最优解,有时候TensorRT并不会分配Tensor Core,所以有时候会出现INT8速度比FP16慢的问题;
(2)使用Tensor Core需要让Tensor Size为8或者16的倍数,8的倍数为FP16的精度,16的倍数为INT8的精度; - 不能前处理和后处理的Overhead
(1)对于一些轻量模型,前处理/后处理可能会更加耗时;
(2)可以把有些前处理/后处理中可并行的地方用GPU处理,例如RGP2BGR、Normalization、Resize、Crop、NCHW2NHWC;
(3)可以在CPU上使用一些图像处理优化库,例如Halide,Blur、Resize、Crop、DBSCAN、Sobel这些操作会比Opencv要快;
以上是对一些基本概念的总结,实际模型部署的工作会比上述更加复杂有趣,比如如果部署的算子导出失败如何通过ONNX的插件构建和修改等等,还会有很多工具和API需要学习,这些就在之后工作上具体遇到实际问题时再进一步了解吧