一、重载函数
(一)函数模板重载
- 详细解析:函数模板提供了一种通用的函数定义方式,可针对不同类型进行实例化。当存在函数模板与普通函数、其他函数模板同名时,就构成了函数模板重载。编译器在编译阶段,依据调用函数时传入实参的具体类型,结合模板参数推导规则,从多个重载函数版本中挑选最合适的进行调用。
- 代码注释示例
// 普通函数
int add(int a, int b) {
return a + b;
}
// 函数模板
template <typename T>
T add(T a, T b) {
return a + b;
}
int main() {
int intResult = add(1, 2); // 调用普通函数add,因为实参是int类型,普通函数更匹配
double doubleResult = add(1.5, 2.5); // 调用函数模板add,推导T为double类型
return 0;
}
- 函数实现功能:实现了对不同类型数据相加操作的统一接口,普通函数处理
int类型,函数模板可处理各种支持+运算的类型,增强了代码的复用性和灵活性。 - 原理:编译器通过对实参类型的分析,确定是调用普通函数还是对函数模板进行实例化调用。函数模板实例化过程中,编译器根据实参类型替换模板参数,生成特定类型的函数代码。
(二)运算符重载与函数重载
- 详细解析:运算符在 C++ 中本质上也是一种函数调用形式。运算符重载就是通过定义特殊的函数(以
operator关键字加上运算符符号命名,如operator+),让自定义类型能够像内置类型一样使用运算符进行操作,这符合函数重载的特征(相同函数名,不同形参列表,这里形参由操作数类型决定)。 - 代码注释示例
class Complex {
private:
double real;
double imag;
public:
Complex(double r = 0, double i = 0) : real(r), imag(i) {}
// 重载+运算符
Complex operator+(const Complex& other) const {
return Complex(real + other.real, imag + other.imag);
}
};
int main() {
Complex c1(1, 2);
Complex c2(3, 4);
Complex result = c1 + c2; // 调用重载的operator+函数
return 0;
}
- 函数实现功能:使自定义的
Complex类(复数类)能够使用+运算符进行复数相加操作,让代码更符合直观的数学运算表达习惯。 - 原理:当编译器遇到自定义类型对象使用重载运算符的表达式(如
c1 + c2)时,会将其转换为对应的运算符重载函数调用(c1.operator+(c2)),通过函数定义的逻辑执行相应操作。
二、默认参数规则
(一)默认参数与函数重载
- 详细解析:当函数带有默认参数时,其调用形式可能与其他重载函数产生重叠,导致编译器无法明确确定要调用的函数版本,从而引发调用歧义。例如,一个有默认参数的函数和另一个参数数量不同但部分参数类型相同的重载函数,在特定调用形式下编译器难以抉择。
- 代码注释示例(存在歧义情况)
void func(int a) {
// 函数逻辑
}
void func(int a, int b = 10) {
// 函数逻辑
}
int main() {
func(5); // 此处会产生歧义,编译器不知道调用哪个func函数
return 0;
}
- 函数实现功能:在正常无歧义情况下,默认参数函数可提供更灵活的调用方式,允许调用者根据需求省略部分参数。但在与重载函数搭配时,需合理设计参数避免歧义,以保证程序正确执行。
- 原理:编译器依据函数调用时传入的实参数量和类型,与函数声明(包括默认参数情况)进行匹配。当存在多个匹配度相近的函数时,就会出现无法确定调用哪个函数的问题。
(二)默认参数的作用域
- 详细解析:默认参数值通常应在函数声明处指定,这是为了让调用者在使用函数前就能知晓参数的默认取值情况。若在函数定义处指定默认参数值,必须确保与声明处一致,否则会导致代码逻辑混乱和编译错误。
- 代码注释示例
// 函数声明,指定默认参数值
void printMessage(const char* message = "Default message");
// 函数定义,默认参数值与声明处一致
void printMessage(const char* message) {
// 打印逻辑
}
- 函数实现功能:统一函数声明和定义中默认参数值,保证函数调用的一致性和可预期性,使调用者能正确使用默认参数进行函数调用。
- 原理:编译器在编译过程中,先依据函数声明来检查函数调用的合法性和参数匹配情况,函数定义则是具体实现函数逻辑。若声明和定义中默认参数值不一致,编译器无法准确判断调用者意图,导致编译错误。
三、内联函数
(一)内联扩展限制
- 详细解析:内联函数的目的是通过在调用处直接嵌入函数体代码,减少函数调用的开销(如压栈、跳转、恢复现场等操作)。然而,递归函数由于自身不断调用自身的特性,若进行内联扩展会导致代码量急剧膨胀;包含循环或复杂控制结构的函数,内联后会使调用处代码变得冗长复杂,失去内联优化的意义,所以编译器通常会忽略这类函数的内联请求。
- 代码注释示例(递归函数不适合内联)
// 递归函数,虽声明为内联,但编译器可能忽略
inline int factorial(int n) {
if (n == 0 || n == 1) {
return 1;
}
return n * factorial(n - 1);
}
- 函数实现功能:在理想情况下,内联函数可提高执行效率。但对于递归、复杂结构函数,编译器不进行内联扩展,仍以普通函数调用方式执行,保证程序的合理执行和代码规模可控。
- 原理:编译器在处理内联函数时,会评估函数的复杂度和结构。对于递归函数,内联会导致无限展开;对于循环等复杂结构函数,内联后代码膨胀严重,所以编译器依据一定规则决定是否真正进行内联扩展。
(二)内联与调试
- 详细解析:内联函数在编译阶段,其函数体代码会被直接嵌入到调用处,这使得在调试过程中,调试工具难以像对待普通函数调用那样准确标识出函数调用的层次和位置,给调试带来困难。为解决此问题,可通过编译器选项关闭内联优化,使函数以普通函数形式进行调用,方便调试。
- 代码注释示例(假设编译器支持关闭内联优化选项,不同编译器选项不同)
// 内联函数
inline int sum(int a, int b) {
return a + b;
}
int main() {
int result = sum(1, 2);
return 0;
}
在调试时,若发现内联函数调试不便,可在编译命令中添加关闭内联优化的选项(如在 g++ 中可使用 -fno-inline 选项),让编译器将内联函数按普通函数处理。
- 函数实现功能:在开发调试阶段,通过控制内联优化,既能在需要时利用内联函数提高效率,又能在调试时准确跟踪代码执行流程,便于排查问题。
- 原理:调试工具依赖函数调用的堆栈信息来标识代码执行位置和函数调用层次。内联函数展开后,函数调用的堆栈信息被打乱,调试工具难以识别。关闭内联优化后,恢复普通函数调用形式,堆栈信息正常,便于调试。
四、友元函数
(一)友元类
- 详细解析:友元类是一种特殊的类间关系,当一个类被声明为另一个类的友元类时,友元类的所有成员函数都拥有访问另一个类私有和保护成员的权限。这种机制打破了类的封装性,因为通常类的私有和保护成员只能被自身成员函数访问,但在某些特定场景(如类之间紧密协作)下有其使用价值。
- 代码注释示例
class ClassB; // 前向声明
class ClassA {
private:
int privateData;
friend class ClassB; // 声明ClassB为友元类
public:
ClassA() : privateData(0) {}
};
class ClassB {
public:
void accessPrivateData(ClassA& a) {
a.privateData = 10; // ClassB的成员函数可访问ClassA的私有成员
}
};
- 函数实现功能:在类之间存在紧密数据交互或协作需求时,友元类机制可让一个类方便地访问另一个类的内部数据,实现特定功能。但同时要注意,过度使用会破坏类的封装性,增加代码维护难度。
- 原理:编译器在处理友元类相关代码时,会记录友元关系,当友元类的成员函数访问另一个类的私有或保护成员时,编译器允许这种访问,突破了常规的访问控制规则。
(二)友元关系的传递性
- 详细解析:友元关系不具备传递性,即若
A是B的友元,B是C的友元,并不意味着A就是C的友元。每个友元关系都是独立建立的,不会自动在相关类之间传递。 - 代码注释示例
class ClassC;
class ClassB;
class ClassA {
private:
int dataA;
friend class ClassB;
public:
ClassA() : dataA(0) {}
};
class ClassB {
private:
int dataB;
friend class ClassC;
public:
ClassB() : dataB(0) {}
};
class ClassC {
public:
void func() {
ClassA a;
// a.dataA; // 此处会报错,因为ClassC不是ClassA的友元
}
};
- 函数实现功能:明确友元关系的非传递性,可帮助开发者准确控制类之间的访问权限,避免因错误假设友元关系传递而导致的非法访问问题,保证代码的安全性和正确性。
- 原理:编译器依据每个类中明确声明的友元关系来确定访问权限,不存在基于友元关系传递的默认访问许可,每个友元声明都是独立的访问授权。
五、运算符重载函数
(一)不可重载的运算符
- 详细解析:C++ 规定了部分运算符不能被重载,如
::(作用域解析运算符)用于明确标识作用域,若可重载会导致程序结构混乱,难以确定标识符所属作用域;.*(成员指针访问运算符)用于通过对象指针访问成员,其语义和使用方式具有特殊性,重载会破坏语言的一致性和安全性;?:(条件运算符)是一种简洁的三元操作符,其语法和语义已固定,重载会带来极大的逻辑理解和使用上的困扰。 - 代码注释示例(试图重载不可重载运算符会报错)
// 以下代码试图重载::运算符,会导致编译错误
// class MyClass {
// public:
// operator::(/* 参数 */) {
// // 逻辑
// }
// };
- 函数实现功能:这些不可重载的运算符在 C++ 语言体系中承担着基础且明确的功能,禁止重载可保证语言核心功能的稳定性和可预测性,防止因不合理重载导致代码逻辑混乱和不可控。
- 原理:C++ 编译器在语法分析阶段,对这些特定运算符有固定的处理规则和语义理解,不允许用户通过自定义函数改变其基本行为,从语言设计层面保障语言特性的正常使用。
(二)重载运算符的语义一致性
- 详细解析:重载运算符时,其实现的逻辑应与内置类型运算符的语义相近。例如重载
operator+实现自定义类型加法,应遵循加法运算的基本逻辑(如交换律等),否则会使代码语义混乱,其他开发者难以理解和使用。保持语义一致性可让自定义类型在使用运算符时符合常规编程习惯和数学逻辑。 - 代码注释示例
class Vector2D {
private:
double x;
double y;
public:
Vector2D(double _x = 0, double _y = 0) : x(_x), y(_y) {}
// 重载+运算符,实现向量加法,符合向量加法语义
Vector2D operator+(const Vector2D& other) const {
return Vector2D(x + other.x, y + other.y);
}
};
- 函数实现功能:使自定义类型能够以符合常规认知的方式使用运算符,增强代码的可读性和可维护性,方便开发者在自定义类型上进行类似内置类型的操作。
- 原理:开发者在重载运算符时,按照既定的语义规则编写函数逻辑,编译器编译时并不对语义本身进行深度检查(仅检查语法合法性等),但从代码规范和可理解性角度,遵循语义一致性可让代码更符合逻辑和使用习惯。
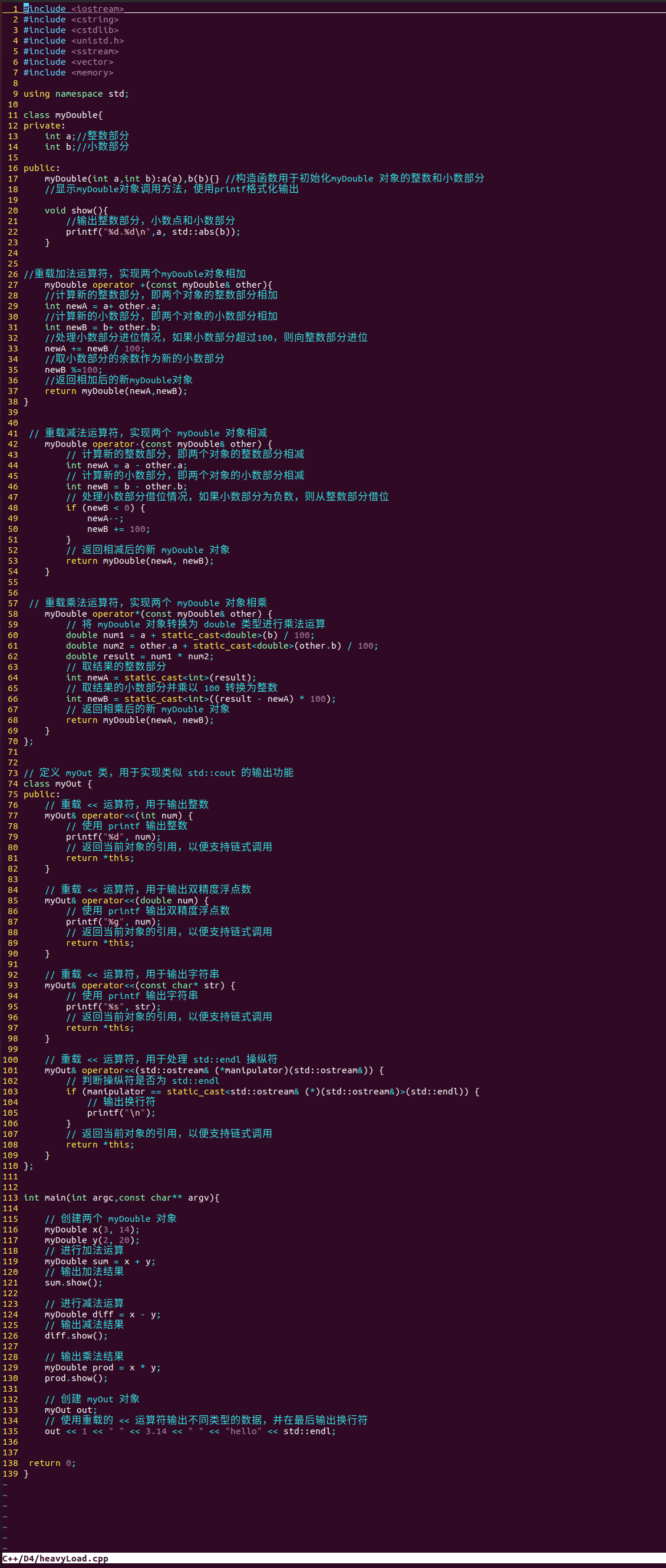
六、练习
(一)重载函数的运算