系列文章目录
终章 1:Attention的结构
终章 2:带Attention的seq2seq的实现
终章 3:Attention的评价
终章 4:关于Attention的其他话题
终章 5:Attention的应用
目录
前言
到目前为止,我们研究了Attention(正确地说,是带Attention的 seq2seq),本节我们介绍几个之前未涉及的话题
一、双向RNN
这里我们关注seq2seq的编码器。首先复习一下,上一节之前的编码器如下图所示。
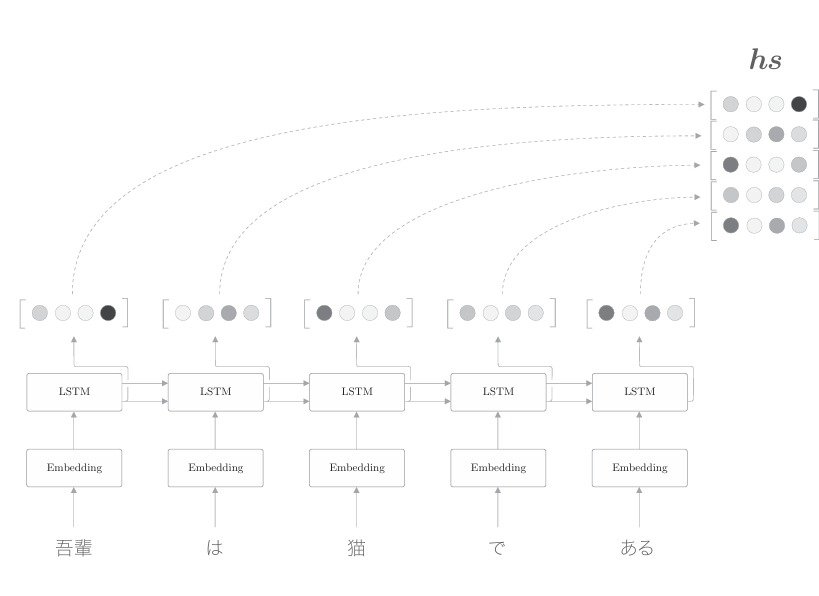
如上图所示,LSTM中各个时刻的隐藏状态向量被整合为hs。这里, 编码器输出的hs的各行中含有许多对应单词的成分。 需要注意的是,我们是从左向右阅读句子的。因此,在上图中,单词“猫”的对应向量编码了“吾輩”“は”“猫”这3个单词的信息。如果考虑整体的平衡性,我们希望向量能更均衡地包含单词“猫”周围的信息。为此,可以让LSTM从两个方向进行处理,这就是名为双向LSTM的 技术,如下图所示。
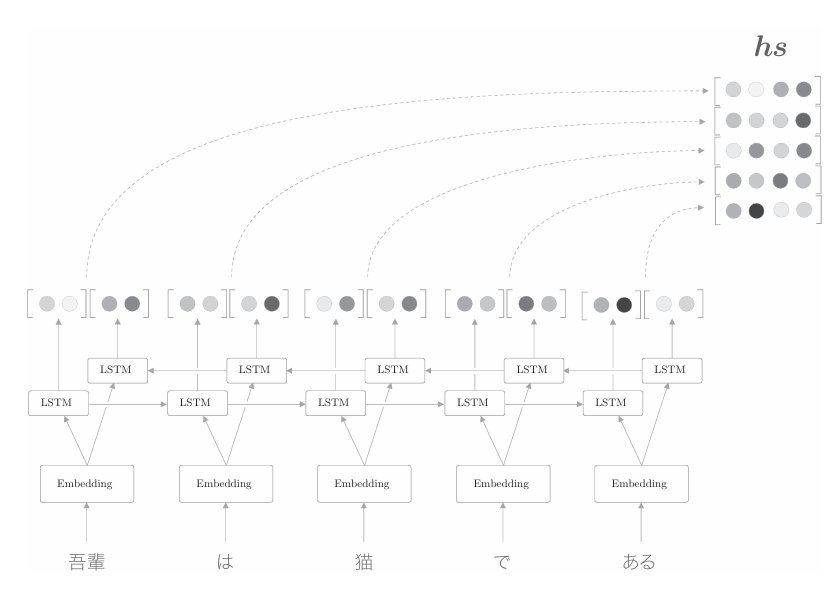
如上图所示,双向LSTM在之前的LSTM层上添加了一个反方向处理的LSTM层。然后,拼接各个时刻的两个LSTM层的隐藏状态,将其作为最后的隐藏状态向量(除了拼接之外,也可以“求和”或者“取平均”等)。通过这样的双向处理,各个单词对应的隐藏状态向量可以从左右两个方向聚集信息。这样一来,这些向量就编码了更均衡的信息。
双向LSTM的实现非常简单。一种实现方式是准备两个LSTM层(本章中是Time LSTM层),并调整输入各个层的单词的排列。具体而言,其中一个层的输入语句与之前相同,这相当于从左向右处理输入语句的常规的LSTM层。而另一个LSTM层的输入语句则按照从右到左的顺序输入。如果原文是“A B C D”,就改为“D C B A”。通过输入改变了顺序的输入语句,另一个LSTM层从右向左处理输入语句。之后,只需要拼接这两个LSTM层的输出,就可以创建双向LSTM层。
二、Attention层的使用方法
接下来,我们思考Attention层的使用方法。截止到目前,我们使用的 Attention 层的层结构如图所示
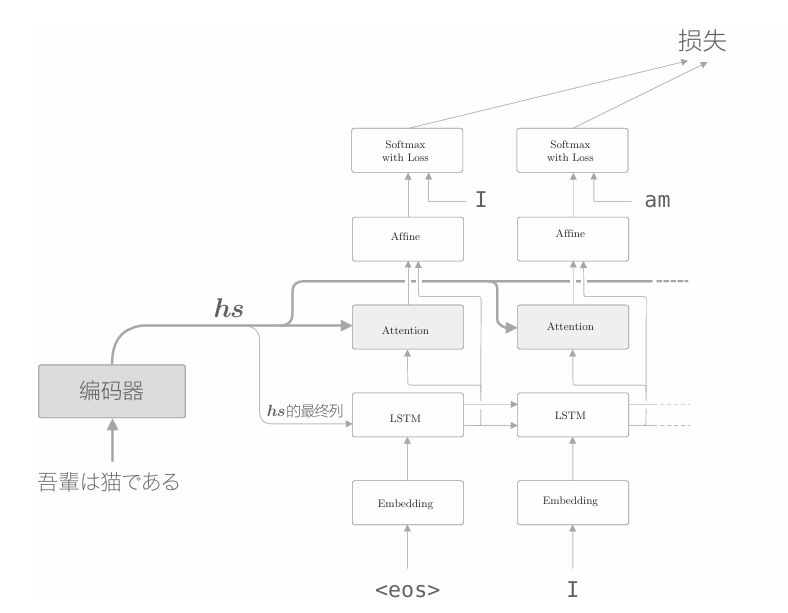
如上图所示,我们将Attention层插入了LSTM层和Affine层之间, 不过使用Attention层的方式并不一定非得像上图那样。实际上,使用 Attention 的模型还有其他好几种方式。比如,还有以下图的结构使用了Attention。
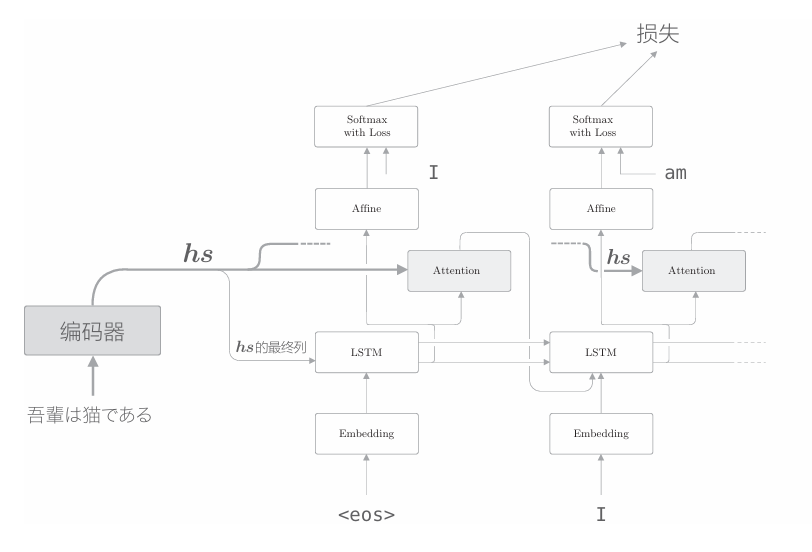
在上图中,Attention层的输出(上下文向量)被连接到了下一时刻的LSTM层的输入处。通过这种结构,LSTM层得以使用上下文向量的信息。相对地,我们实现的模型则是Affine层使用了上下文向量。 那么,Attention 层的位置的不同对最终精度有何影响呢?答案要试一下才知道。实际上,这只能使用真实数据来验证。不过,在上面的两个模型中,上下文向量都得到了很好的应用。因此,在这两个模型之间,我们可能看不到太大的精度差异。 从实现的角度来看,前者的结构(在LSTM层和Affine层之间插入Attention层)更加简单。这是因为在前者的结构中,解码器中的数据是从下往上单向流动的,所以Attention层的模块化会更加简单。实际上,我们轻松地将其模块化为了Time Attention层。
三、seq2seq的深层化和skip connection
在诸如翻译这样的实际应用中,需要解决的问题更加复杂。在这种情况下,我们希望带Attention的seq2seq具有更强的表现力。此时,首先 可以考虑到的是加深RNN层(LSTM层)。通过加深层,可以创建表现力 更强的模型,带Attention的seq2seq也是如此。那么,如果我们加深带 Attention 的 seq2seq,结果会怎样呢?下图给出了一个例子。

在上图的模型中,编码器和解码器使用了3层LSTM层。如本例所示,编码器和解码器中通常使用层数相同的LSTM层。另外,Attention层 的使用方法有许多变体。这里将解码器LSTM层的隐藏状态输入Attention 层,然后将上下文向量(Attention层的输出)传给解码器的多个层(LSTM 层和Affine 层 )。
另外,在加深层时使用到的另一个重要技巧是残差连接(skip connection,也称为residual connection 或 shortcut)这是一种“跨层 连接”的简单技巧,如下图所示
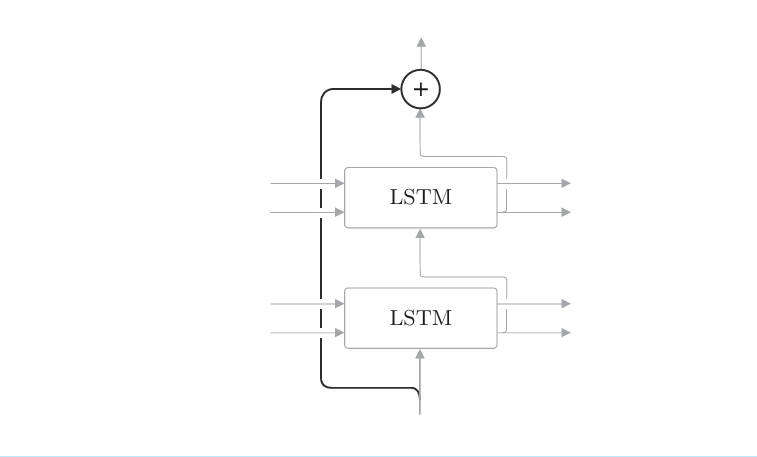
如上图所示,所谓残差连接,就是指“跨层连接”。此时,在残差连接的连接处,有两个输出被相加。请注意这个加法(确切地说,是对应元素 的加法)非常重要。因为加法在反向传播时“按原样”传播梯度,所以残差连接中的梯度可以不受任何影响地传播到前一个层。这样一来,即便加深了 层,梯度也能正常传播,而不会发生梯度消失(或者梯度爆炸),学习可以顺利进行。