一、状态持久化机制
1.1 分布式快照协议
public class ChandyLamport { private Map<Integer, Boolean> markerReceived = new ConcurrentHashMap<>(); private Map<Integer, Queue<Event>> unprocessedEvents = new ConcurrentHashMap<>(); public void initiateSnapshot(int nodeId) { saveLocalState(nodeId); broadcastMarker(nodeId); } private void processMarker(int fromNode, Marker marker) { if (!markerReceived.get(marker.snapshotId())) { saveChannelState(fromNode, marker); markerReceived.put(marker.snapshotId(), true); forwardMarker(marker); } } private void saveChannelState(int nodeId, Marker marker) { snapshotStorage.save( "channel-" + nodeId, unprocessedEvents.get(nodeId).stream() .filter(e -> e.timestamp() < marker.timestamp()) .collect(Collectors.toList()) ); } }1.2 分层存储策略
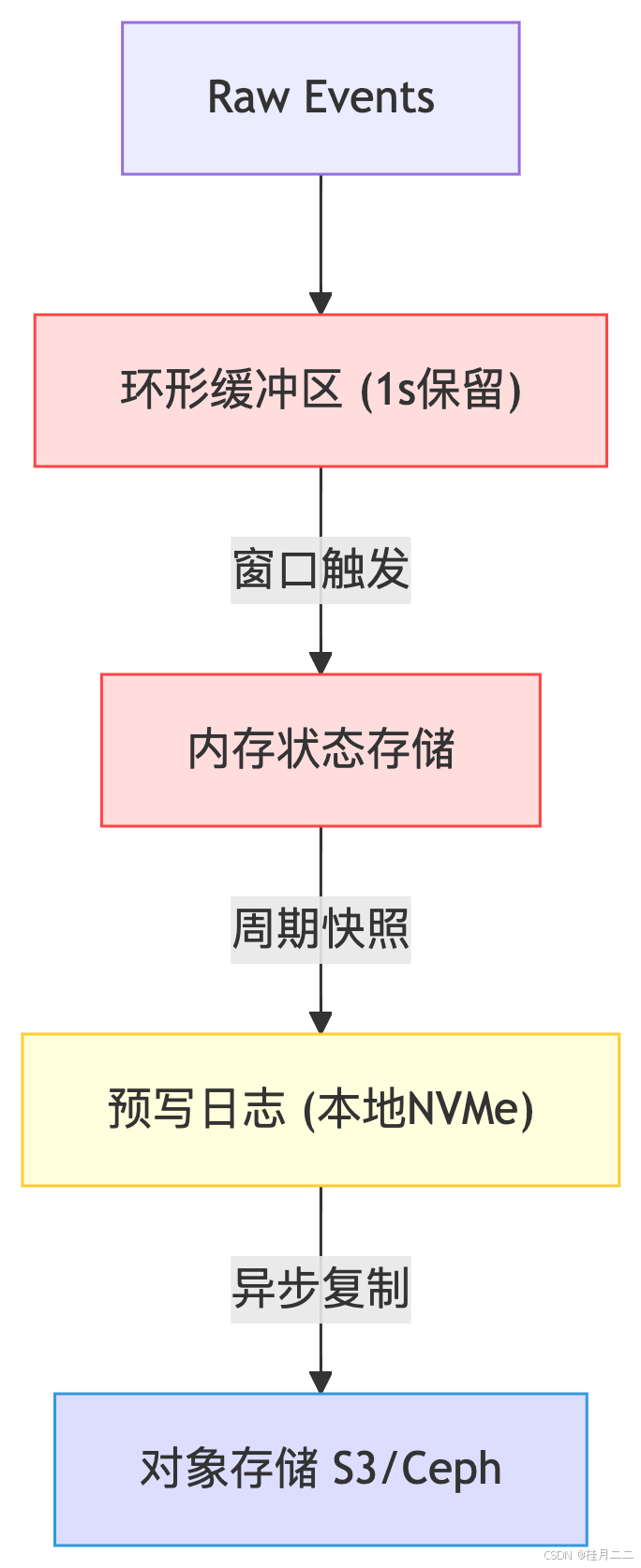
二、消息可靠投递
2.1 事务性队列设计
class ExactlyOnceQueue: def __init__(self): self.current_txn = {} self.offsets = defaultdict(int) self.stable_log = PersistentLog() def begin_txn(self, consumer_id): self.current_txn[consumer_id] = { 'start_offset': self.offsets[consumer_id], 'processed': [] } def commit(self, consumer_id): txn = self.current_txn.pop(consumer_id) self.stable_log.append(txn['processed']) self.offsets[consumer_id] = txn['start_offset'] + len(txn['processed']) def rollback(self, consumer_id): self.current_txn.pop(consumer_id) def deliver(self, consumer_id, msg): if self.offsets[consumer_id] > msg.offset: return # 已处理过 self.current_txn[consumer_id]['processed'].append(msg)2.2 投递语义对比
| 保证级别 | 实现机制 | 性能损耗 | 适用场景 |
|---|---|---|---|
| At-most-once | 直接发送无确认 | 0% | 传感器指标采集 |
| At-least-once | 应答确认+幂等处理 | 15-20% | 金融交易记录 |
| Exactly-once | 分布式事务+原子提交 | 30-40% | 精确计费系统 |
| Transactional | 二阶段提交+回滚段 | 50-60% | 跨系统强一致性场景 |
| Idempotency | 唯一消息ID+去重表 | 5-10% | 订单处理等业务 |
三、故障恢复策略
3.1 动态检查点算法
struct CheckpointManager { last_checkpoint: Instant, failure_rate: f64, state_size: usize, } impl CheckpointManager { fn should_checkpoint(&self) -> bool { let stability = (1.0 - self.failure_rate).powi(2); let cost_factor = (self.state_size as f64).sqrt(); let optimal_interval = cost_factor / (stability * 1000.0); self.last_checkpoint.elapsed() > Duration::from_secs_f64(optimal_interval) } fn adaptive_checkpoint(&mut self, state: State) { if self.should_checkpoint() { self.persist(state); self.last_checkpoint = Instant::now(); } } }3.2 恢复性能矩阵
{ "Kafka+SparkStreaming": { "恢复耗时": "28s (500MB状态)", "数据丢失": "last 1.2s", "资源消耗": "恢复期CPU 145%" }, "Flink+ROCKSDB": { "恢复耗时": "4.3s (500MB状态)", "数据丢失": "exactly-once", "资源峰值": "内存+25%" }, "Pulsar+BookKeeper": { "恢复耗时": "1.8s (500MB状态)", "数据丢失": "零丢失", "IO压力": "写入吞吐+40%" }}四、集群自动化治理
4.1 自动化缩扩容策略
# Kubernetes CRD定义apiVersion: streaming.operator/v1beta1kind: AutoScalermetadata: name: fraud-detectionspec: metrics: - type: Resource resource: name: cpu target: type: Utilization averageUtilization: 70 behavior: scaleDown: stabilizationWindowSeconds: 300 policies: - type: Percent value: 20 periodSeconds: 60 scaleUp: stabilizationWindowSeconds: 120 policies: - type: Pods value: 4 periodSeconds: 45# 扩缩事件样本Event: Scaled up fraud-detection from 6 to 10 podsReason: HighCPUUsage Trilgers: 78% CPU usage over 2m4.2 节点优先级调度
| 节点标记 | 调度权重 | 驱逐保护 | 任务类型 |
|---|---|---|---|
| spot-instance | 0.3 | 否 | 旁路分析任务 |
| dedicated-compute | 1.5 | 是 | 实时处理核心链路 |
| gpu-accelerated | 2.0 | 是 | 视频推理任务 |
| ephemeral-storage | 0.8 | 否 | 中间计算结果暂存 |
| low-latency-net | 1.2 | 是 | 跨区域同步任务 |
五、全链路追踪系统
5.1 因果关系跟踪模型
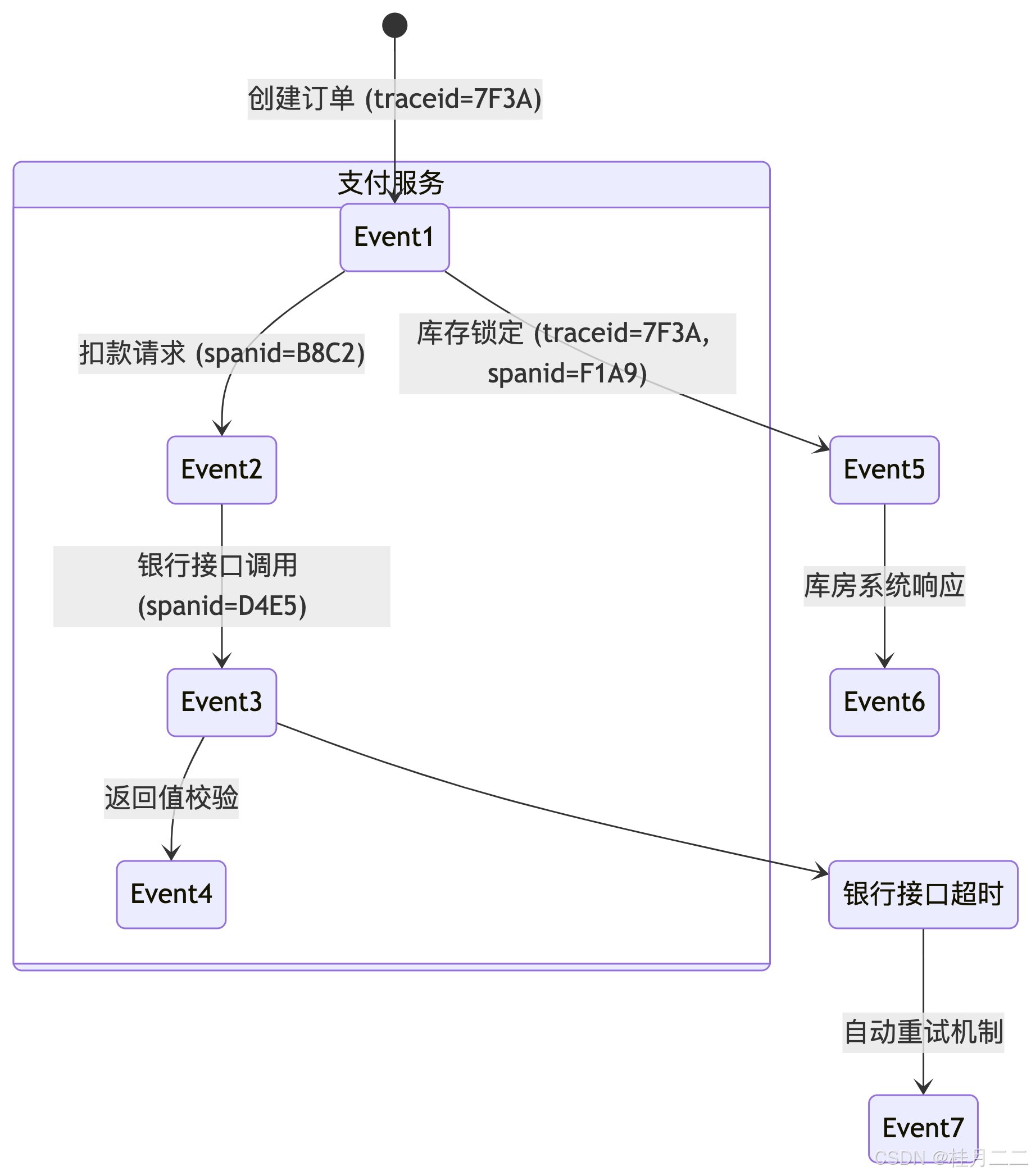
5.2 追踪数据模型
message Span { fixed64 trace_id = 1; fixed64 span_id = 2; string service = 3; string operation = 4; repeated SpanRef references = 5; map<string, string> tags = 6; repeated LogEntry logs = 7; uint64 start_time = 8; uint64 duration = 9; }message LogEntry { uint64 timestamp = 1; message Field { string key = 1; string value = 2; } repeated Field fields = 2;}🔧 容错架构Checklist
- 端到端延迟SLA<200ms P99
- 检查点间隔动态调优功能验证
- 单节点故障恢复时间<5秒
- 状态后端CSI持久化配置
- Exactly-once语义集成测试报告
- 水位线传播机制基准测试
- 脏数据dead letter队列监控
流处理系统的容错设计需重点构建四大支柱:1) 状态持久化体系,结合本地快速存储与云端持久化存储形成分层保护;2) 可靠消息通路,在不同语义级别间按需选择最佳实现策略;3) 自动化恢复机制,基于实时故障检测动态调整恢复策略;4) 可观测性基础设施,实现全链路事件溯源能力。核心创新点应包括基于FPGA加速的状态序列化、增量快照压缩算法、混合时钟同步方案等关键技术。在实时反欺诈等场景中,需特别注意 乱序事件处理 与 窗口状态管理 的协同设计。建议定期实施 故障演练红蓝对抗 ,通过主动注入网络分区、背压风暴等故障模式持续验证系统韧性。