1. 项目背景
AWS的官方文档,关于Glue和Vpc配置部分已经比较旧了,按照官方文档配置的流程始终跑不通,花了一番时间和波折后,才终于完整的跑通了。
在数据分析和商业智能(BI)领域,我们常需要将存储在 Amazon S3 上的原始数据加载到 Amazon Redshift Serverless,进行清理和转换后,再导入 Amazon QuickSight 进行可视化分析。本文将介绍如何使用 AWS Glue 读取 S3 文件,上传数据到 Redshift,并导出到 QuickSight,同时解决 VPC 访问问题。
2. 架构流程
数据存储:S3 作为数据源,存放 CSV、JSON 或 Parquet 文件。
数据 ETL:Glue 读取 S3 数据,转换格式后上传到 Redshift。
数据分析:Redshift 存储清洗后的数据,提供 SQL 查询能力。
可视化展示:QuickSight 连接 Redshift 进行数据分析。
VPC 配置:Redshift 运行在私有子网,需要 VPC 连接让 Glue 和 QuickSight 访问它。
AWS整体流程配置顺序:
配置VPC --> 创建 Redshfit 的IAM --> 创建含Glue读写权限的IAM --> 创建Redshift 命名空间 --> 创建Glue任务 --> Quicksight 创建VPC配置 --> 读取Redshift
3. 详细操作步骤
3.1 VPC配置 (最重要的一个环节)
创建VPC: 其他选项按照默认的配置,手动开启DSN设置。(或者直接使用默认的VPC)
创建子网,互联网网关,子网和路由按照默认的做配置,之后自己需要再手动配置路由,所有的配置的时候下拉框都选择刚刚创建的VPC
路由需要加入0.0.0.0/0 igw,才能访问公网 (如果使用默认VPC,此处需要确认,没有的话手动加一下)
配置网络ACL,入站和出站规则:


然后再点击子网关联,编辑子网,把创建的子网加入进去
创建一个安全组,把所有流量都配置到源为安全组名称自己的配置上
终端节点,添加vpce-svc-0704d47ebfd5f32fc,s3,redshift,sts,kms, secretsmanager,这几个都必须要,缺一不可。
3.2 创建 Amazon Redshift Serverless 集群
登录 AWS 控制台,进入 Amazon Redshift Serverless控制面板。
创建工作组,配置需注意:
Performance and cost controls:选择基本容量
RPU选择这个地方是大坑,天坑,一定要慎重选择,默认值是128, 一定要根据自己的数据大小看清楚合适的配置。(一个 RPU 提供 16 GB 内存),如果配置太高,哪怕只是执行简单一条查询,每次都按配置的RPU进行搜索计费。
Amazon Redshift Serverless 的计算容量 Amazon Redshift Serverless 的计费


网络和安全:选择配置的VPC,或者默认VPC,选择 私有子网
安全组:选择一个自定义的安全组,记住名称,这个安全组后面还需要做一些配置
增强型 VPC 路由:打开
IAM
创建表结构:写sql创建,例如:
CREATE TABLE zyytest1 ( id INT PRIMARY KEY, test_f1 VARCHAR(255), create_time TIMESTAMP );
3.3 在 S3 上传数据
在 S3 上传数据 zyytest1__max__3.json
[
{"id":5, "test_f1": "test_value_6", "create_time": "2025-03-26T10:00:06"},
{"id":7, "test_f1": "test_value_7", "create_time": "2025-03-26T10:00:07"},
{"id":8, "test_f1": "test_value_8", "create_time": "2025-03-26T10:00:08"}
]3.4 配置 AWS Glue 读取 S3 数据并上传到 Redshift
3.4.1 创建 Glue VPC网络
进入 AWS Glue 控制台,选择 Connections > Create connection
 选择Network --> next --> 选择3.1 里搭建的VPC,子网,安全组,保存default_vpc。创建完之后状态是ready就是正常的。
选择Network --> next --> 选择3.1 里搭建的VPC,子网,安全组,保存default_vpc。创建完之后状态是ready就是正常的。

3.4.2 创建 Glue 数据连接
进入 AWS Glue 控制台,选择 Connections > Create connection。
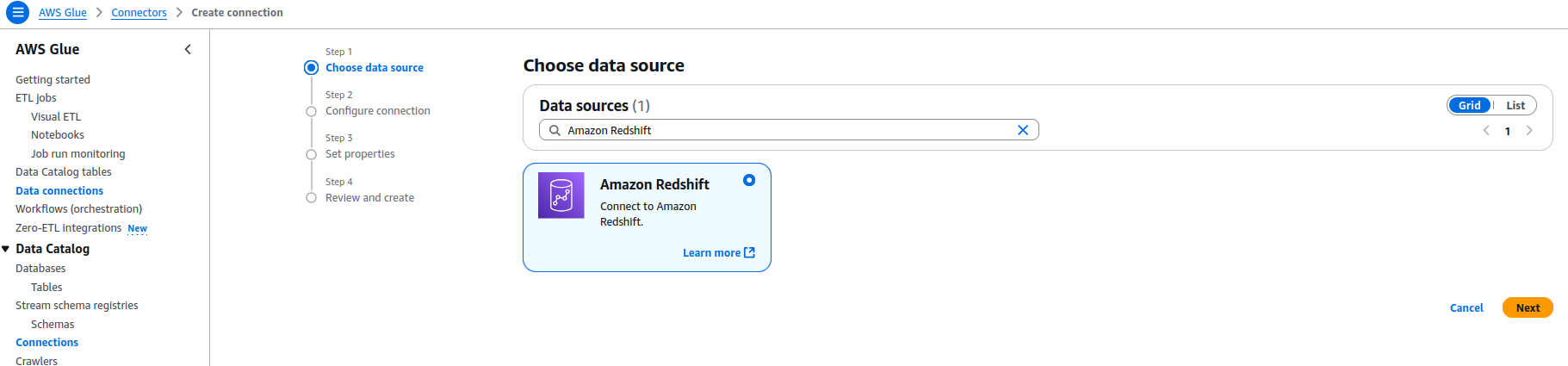
选择redshift --> 填写name:redshift-dev,把刚刚创建的redshift用户名命名填写上,保存后显示Ready,就是正常的可用状态。

如果配置完不可用,可以点击这个Test connection 来测试连接是否正常

3.4.3 创建 Glue Visual
点Visual ETL,选择S3,配置路径后,先查看schema是否正确
配置完之S3的路径之后,可以在左下角看到schema
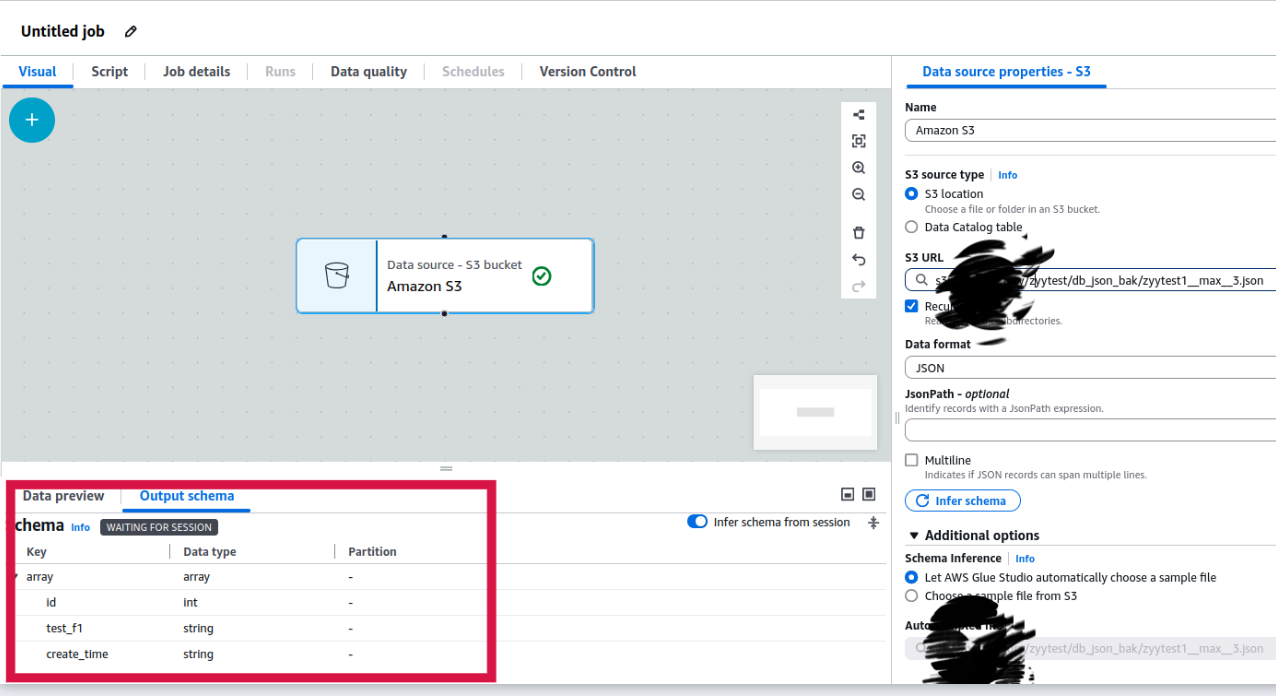 正确的话进行下一步,选择Redshift,配置数据库连接,查看数据库表的schema是否正确。
正确的话进行下一步,选择Redshift,配置数据库连接,查看数据库表的schema是否正确。
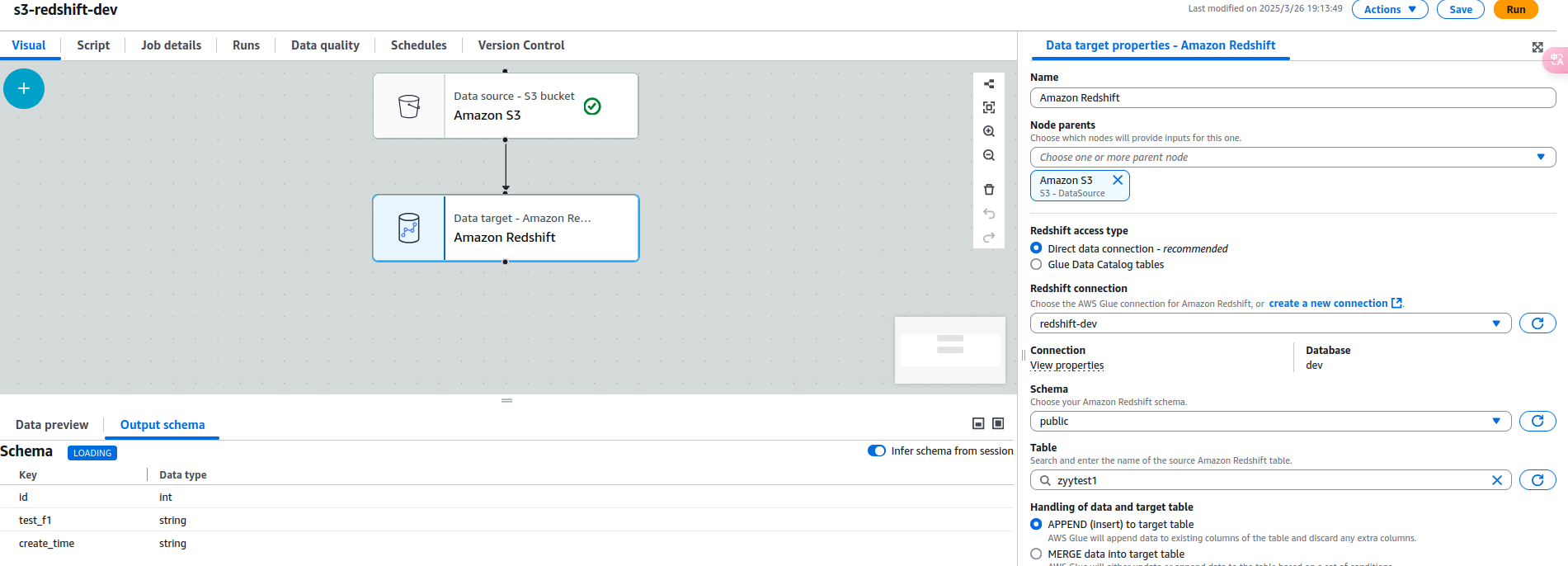
这个IAM记得配置上,就可以看到数据库的schema,在左下角。
然后点击Script,可以看到图形化的配置生成的Script,并且可以在这个Script上,用python脚本更改配置。
到这一步就证明VPC和Redshift的数据库都通了,接下来就可以摸索按照自己的需要,选择用图形化的方式配置更合适,或者用脚本的方式更合适了。
配置完保存之后运行一遍,成功的话,在redshift查询下是否完整存入,如果缺少数据,需要手动指定schema。
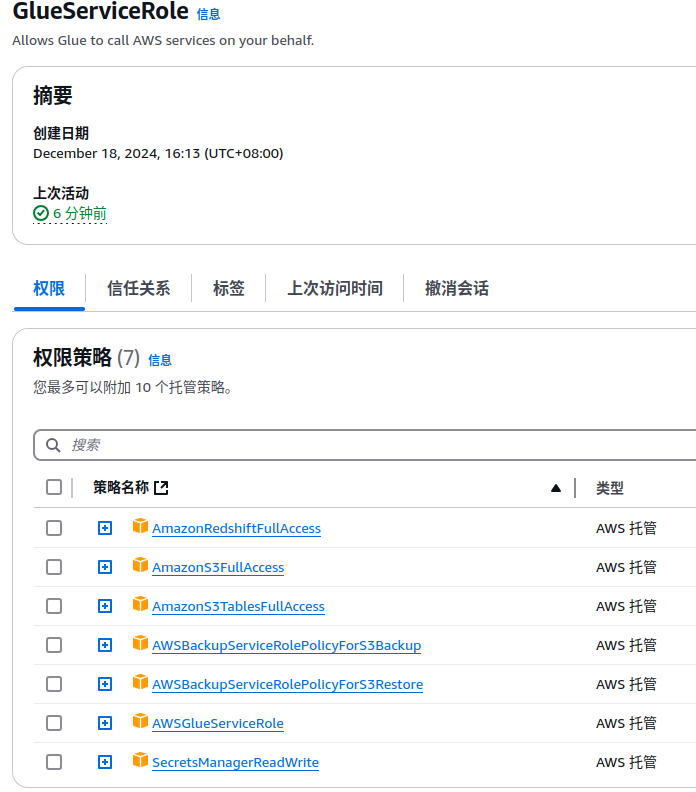
3.4.4 如果查询失败,再检查下IAM配置,选择合适的策略
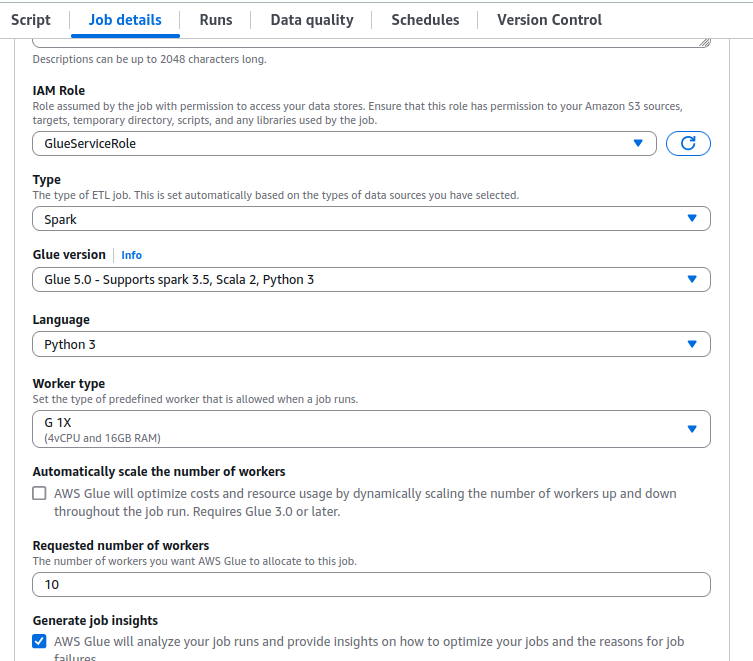
3.4.5 Job details 检查配置
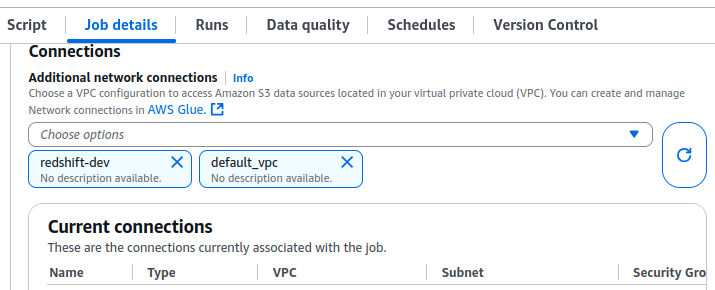
3.5 配置QuickSight VPC
点击右上角管理Quicksight --> 管理VPC链接 --> 添加VPC链接,把3.1配置的vpc,子网,安全组附加上去

3.6 配置 Amazon QuickSight 访问 Redshift
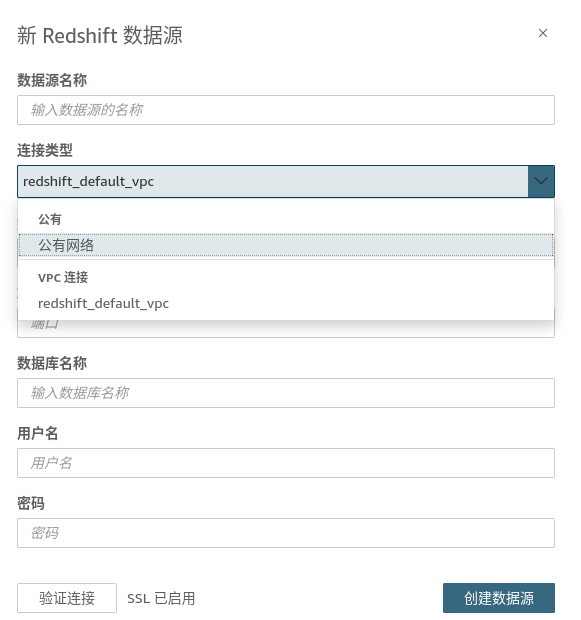
找到数据集 --> 新数据集 --> Redshift手动连接 ,选择刚刚创建的vpc,配置redshift的数据库账号密码,点击验证连接,验证通过后,创建数据源

点击分析,新分析,创建界面化的表格,进行DIY。
4. 总结
AWS Glue 负责从 S3 读取数据,转换后写入 Redshift。
VPC 配置 解决 Glue 和 QuickSight 无法访问 Redshift 的问题。
QuickSight 连接 Redshift 进行 数据可视化。
通过该流程,我们可以自动化数据管道,实现从 S3 -> Glue -> Redshift -> QuickSight 的完整数据流,为企业 BI 提供高效的数据分析能力! 🚀
参考链接: