
paper
Abstract
三维目标检测是自动驾驶中的一项重要任务。如果3D输入数据是从精确但昂贵的激光雷达技术获得的,那么最新的技术具有高精度的检测率。到目前为止,基于更便宜的单眼或立体图像数据的方法导致精度大大降低——这一差距通常归因于基于图像的深度估计不佳。然而,在本文中,我们认为这不是数据的质量,而是它的表示,占大部分的差异。考虑到卷积神经网络的内部工作原理,我们建议将基于图像的深度图转换为伪激光雷达表示-本质上模仿激光雷达信号。利用这种表示,我们可以应用不同的现有的基于激光雷达的检测算法。在流行的KITTI基准测试中,我们的方法在基于图像的性能方面取得了令人印象深刻的改进——将30米范围内物体的检测精度从以前的22%提高到前所未有的74%。在提交时,我们的算法在基于立体图像的方法的KITTI 3D物体检测排行榜上排名最高。
Introduction
可靠和鲁棒的三维目标检测是自动驾驶的基本要求之一。毕竟,为了避免与行人、骑自行车的人和汽车发生碰撞,车辆必须能够在第一时间检测到它们。现有的算法很大程度上依赖于激光雷达(光探测和测距),它提供了周围环境的精确3D点云。虽然高度精确,但出于多种原因,激光雷达的替代品是可取的。首先,激光雷达价格昂贵,这给自动驾驶硬件带来了高昂的成本。其次,过度依赖单一传感器是一种固有的安全风险,如果有第二个传感器,在发生意外时可以依靠,这将是有利的。一个自然的候选是来自立体或单目相机的图像。光学相机价格非常便宜(比Li- DAR便宜几个数量级),以高帧速率运行,并提供密集的深度图,而不是激光雷达信号固有的64或128个稀疏旋转激光束。
最近的一些出版物探讨了使用单眼和立体深度(视差)估计[13,19,32]用于3D目标检测[5,6,22,30]。然而,到目前为止,主要的成功主要是在补充激光雷达方法。例如,KITTI基准上领先的算法之一[17][11,12]使用传感器融合将汽车的3D平均精度(AP)从激光雷达的66%提高到激光雷达和单目图像的73%。相比之下,在仅使用图像的算法中,最先进的算法仅实现了10%的AP[30]。
一个直观和流行的解释,这种较差的性能是基于图像的深度估计精度差。与激光雷达相比,立体深度估计的误差随深度呈二次增长。然而,激光雷达和最先进的立体深度估计器[3]生成的3D点云的视觉比较显示,两种数据模式之间的高质量匹配(参见图1)-即使对于遥远的物体也是如此。

伪激光雷达信号的视觉深度估计。左上:一幅KITTI街景,用激光雷达(红色)和伪激光雷达(绿色)在汽车周围叠加了边界框。左下:估计的视差图。右:伪激光雷达(蓝色)vs。LiDAR(黄色)-伪LiDAR点与LiDAR点对齐得非常好。以彩色观看效果最佳(放大查看细节)。
在本文中,我们提供了一种具有重要性能影响的替代解释。我们认为,立体和激光雷达之间性能差距的主要原因不是深度精度的差异,而是基于convnet的三维目标检测系统在立体上运行时对3D信息表示的糟糕选择。具体来说,激光雷达信号通常表示为3D点云[23]或从自上而下的“鸟瞰”视角[33],并进行相应的处理。在这两种情况下,对象的形状和大小随深度而变化。相比之下,基于图像的深度对每个像素进行密集估计,通常表示为额外的图像通道[6,22,30],使远处的物体更小,更难检测。更糟糕的是,这种表示中的像素邻域将来自3D空间中遥远区域的点聚集在一起。这使得依赖于这些通道上的2D卷积的卷积网络很难在3D中推理和精确定位物体。
为了评估我们的主张,我们介绍了一种基于立体的3D物体检测的两步方法。我们首先将估计的深度图从立体或单目图像转换为3d点云,我们称之为伪激光雷达,因为它模拟了激光雷达信号。然后,我们利用现有的基于激光雷达的3D目标检测管道[16,23],我们直接在伪激光雷达表示上进行训练。通过将三维深度表示改为伪激光雷达,我们获得了基于图像的三维目标检测算法精度的前所未有的提高。具体来说,在“中等难度”汽车实例(官方排行榜中使用的指标)的IoU为0.7的KITTI基准上,我们在验证集上实现了45.3%的3D AP:比之前最先进的基于图像的方法提高了近350%。此外,我们将基于立体和基于激光雷达的系统之间的差距缩小了一半。
我们评估了立体深度估计和三维目标检测算法的多种组合,并得出了非常一致的结果。这表明我们观察到的增益是由于伪激光雷达表示,并且较少依赖于3D目标检测架构或深度估计技术的创新。总之,这篇论文的贡献是双重的。首先,我们的经验表明,基于立体和基于激光雷达的3D物体检测之间性能差距的主要原因不是估计深度的质量,而是其表示。其次,我们提出了伪激光雷达作为3D目标检测估计深度的新推荐表示,并表明它导致了最先进的基于立体的3D目标检测,有效地将现有技术提高了两倍。我们的研究结果表明,在自动驾驶汽车中使用立体摄像头是可能的,这可能会大幅降低成本,并/或提高安全性。
Related Work
LiDAR-based 3D object detection
我们的工作受到3D视觉和基于激光雷达的3D物体检测的最新进展的启发。许多最新的技术使用了这样一个事实,即激光雷达自然地表示为3D点云。例如,截锥体PointNet[23]对来自2D目标检测网络的每个截锥体提议应用PointNet[24]。MV3D[7]将激光雷达点投射到鸟瞰图(BEV)和正面视图中,以获得多视图特征。Vox- elNet[34]将三维点编码为体素,并通过三维卷积提取特征。UberATG-ContFuse[17]是KITTI基准[12]上的领先算法之一,它通过形成连续卷积[27]来融合视觉和BEV激光雷达特征。所有这些算法都以给定精确的三维点坐标为前提。因此,主要的挑战是在3D中预测点标签或绘制边界框来定位对象。
Stereo- and monocular-based depth estimation
基于图像的三维目标检测方法的关键是一种可靠的深度估计方法来取代激光雷达。这些可以通过单目视觉[10,13]或立体视觉[3,19]获得。自早期的单目深度估计工作以来,这些系统的精度急剧提高[8,15,26]。最近的算法,如DORN [10]com,将多尺度特征与有序回归相结合,以非常低的误差预测像素深度。对于立体视觉,PSMNet[3]应用Siamese网络进行视差估计,然后使用3D卷积进行细化,导致离群率低于2%。最近的工作已经使这些方法模式高效,能够在移动设备上以30 FPS运行精确的视差估计。
Image-based 3D object detection
立体和单目深度估计的快速发展表明,它们可以作为激光雷达在基于图像的三维目标检测算法中的替代品。这种风格的现有算法主要是建立在二维目标检测[25]上,增加了额外的几何约束[2,4,21,29]来创建三维提案。[5,6,22,30]应用基于立体的深度估计来获得每个像素的真实三维坐标。这些3D坐标要么作为额外的输入通道输入到2D检测管道中,要么用于提取手工制作的特征。尽管这些方法已经取得了显著的进步,但三维物体检测性能的最新技术仍落后于基于激光雷达的方法。正如我们在第3节中讨论的那样,这可能是因为这些方法使用的深度表示。
Method
尽管基于图像的3D物体识别具有许多优势,但在最先进的图像和基于激光雷达的方法的检测率之间仍然存在明显差距(见第4.3节中的表1)。人们很容易将这种差距归因于激光雷达和相机技术之间明显的物理差异及其影响。例如,基于立体的3D深度估计的误差随着物体的深度呈二次增长,而对于飞行时间(ToF)方法,如LiDAR,这种关系近似为线性。
提出了基于图像的三维目标检测管道。给定立体或单目图像,我们首先预测深度图,然后将其反向投影到激光雷达坐标系统中的3D点云中。我们将这种表示称为伪激光雷达,并完全像激光雷达一样处理它-任何基于激光雷达的检测算法都可以应用。
虽然这些物理差异中的一些确实可能导致准确性差距,但在本文中,我们声称大部分差异可以通过数据表示来解释,而不是数据质量或与数据收集相关的潜在物理特性。事实上,最近的立体深度估计算法可以生成非常精确的深度图[3](见图1)。因此,我们“缩小差距”的方法是仔细消除两种数据模式之间的差异,并尽可能地对齐两个识别管道。为此,我们提出了一种两步方法,首先从立体(甚至单眼)图像中估计密集像素深度,然后将像素反向投影到3D点云中。通过将这种表示视为伪激光雷达信号,我们可以应用任何现有的基于激光雷达的3D物体检测算法。图2描述了我们的管道。
Depth estimation
我们的方法不受不同深度估计算法的影响。我们主要使用立体视差估计算法[3,19],尽管我们的方法可以很容易地使用单目深度估计方法。Astereo视差估计算法以水平偏移量(即基线)b的一对摄像机拍摄的一对左右图像Il和Ir作为输入,输出与两幅输入图像中任意一幅大小相同的视差图Y。在不失一般性的前提下,我们假设深度估计算法将左侧图像Il作为参考,并在Y中记录每个像素到Ir的水平视差。结合左相机的水平焦距fU,我们可以通过以下变换得到深度图D:
Pseudo-LiDAR generation
不像[30]那样,将深度D作为多个额外通道合并到RGB图像中,我们可以在左侧相机坐标系中导出每个像素(u, v)的3D位置(x, y, z),如下所示:

式中(cU,cV)为相机中心对应的像素位置,fV为垂直焦距。
通过将所有像素反向投影到3D坐标中,我们得到一个3D点云{(x(n),y(n),z(n))}Nn=1,其中n是像素数。在给定参考视点和观察方向的情况下,这种点云可以转换成任意的坐标系。我们将得到的点云称为伪激光雷达信号。
LiDAR vs. pseudo-LiDAR
为了最大限度地与现有的LiDAR检测管道兼容,我们对伪LiDAR数据进行了一些额外的后处理步骤。由于真正的激光雷达信号只存在于一定的高度范围内,我们忽略了超出该范围的伪激光雷达点。例如,在KITTI基准测试中,在[33]之后,我们移除虚拟LiDAR源(位于自动驾驶车辆顶部)上方1米以上的所有点。由于大多数感兴趣的物体(如汽车和行人)不会超过这个高度范围,因此几乎没有信息丢失。除了深度,LiDAR还返回任何测量像素的反射率(在[0,1]内)。由于我们没有这样的信息,我们简单地将每个伪lidar点的反射率设置为1.0。
图1描绘了来自KITTI数据集的同一场景的ground-truth LiDAR和pseudo- LiDAR点[11,12]。利用金字塔立体匹配网络(PSMNet)[3]进行深度估计。令人惊讶的是,伪激光雷达点(蓝色)与真激光雷达点(黄色)对齐得非常好,这与人们普遍认为的基于图像的低精度深度是劣质3D物体检测的主要原因形成鲜明对比。我们注意到,激光雷达可以为一个场景捕获100万个点,这与像素计数是相同的数量级。然而,激光雷达点分布在几个(通常是64或128)水平波束上,仅稀疏地占据3D空间。
3D object detection
利用估计的伪激光雷达点,我们可以将任何现有的基于激光雷达的3D物体探测器应用于自动驾驶。在这项工作中,我们考虑了那些基于多模态信息的方法(即单图像+激光雷达),因为将原始视觉信息与伪激光雷达数据结合在一起是很自然的。具体来说,我们在AVOD[16]和frustum PointNet[23]上进行了实验,这两种算法在KITTI基准上的开源代码排名靠前。一般来说,我们区分两种不同的设置:
a)在第一个设置中,我们将伪lidar信息视为三维点云。在这里,我们使用截锥体Point- Net[23],将二维目标检测[18]投影到三维截锥体上,然后使用PointNet[24]提取每个三维截锥体上的点集特征。b)在第二种设置中,我们从鸟瞰(BEV)中查看伪激光雷达信息。特别是,从自上而下的角度将三维信息转换为二维图像,宽度和深度成为spa尺寸,高度记录在通道中。AVOD将视觉特征和BEV激光雷达特征连接到3D盒子提案,然后融合两者进行盒子分类和回归。
Data representation matters
虽然伪激光雷达传达的信息与深度图相同,但我们声称它更适合基于深度卷积网络的3D物体检测管道。要了解这一点,请考虑卷积网络的核心模块:2D卷积。在图像或深度图上操作的卷积网络在图像/深度图上执行一系列2D卷积。虽然卷积的过滤器可以学习,但中心假设是双重的:(a)图像中的局部邻域有意义,网络应该查看局部补丁,(b)所有邻域都可以以相同的方式操作。这些只是不完美的假设。首先,二维图像上的局部斑块只有在完全包含在单个物体中时才具有物理相干性。如果它们跨越对象边界,那么两个像素可以在深度图中彼此相邻,但在3D空间中可能非常遥远。其次,出现在多个深度的对象在深度图中以不同的比例尺投影。同样大小的贴片可能只捕获附近汽车的侧视镜或远处汽车的整个车身。现有的二维目标检测方法与这种假设的分解作斗争,必须设计新的技术,如特征金字塔b[18]来应对这一挑战。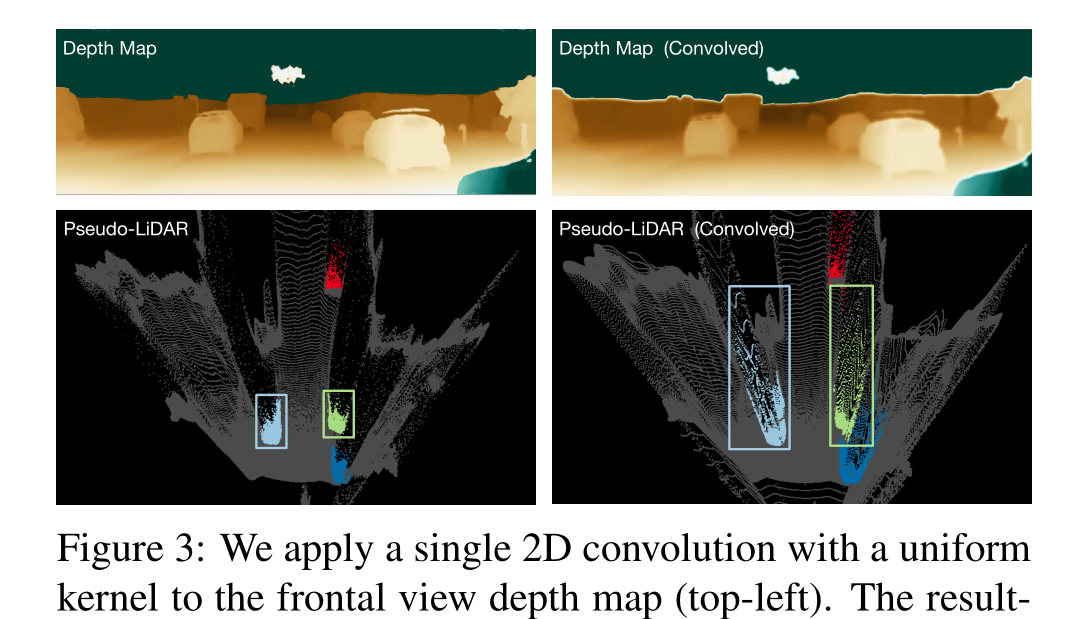
我们对正面视图深度图(左上)应用一个具有统一内核的单一2D卷积。结果深度图(右上),在反向投影到伪激光雷达并从鸟瞰图(右下)显示后,与原始伪激光雷达表示(左下)相比,显示出很大的深度失真,特别是对于远处的物体。我们用一种颜色标记每辆车的位置。这些盒子是叠加的,分别包含了绿色和青色汽车的所有点。
相比之下,点云上的3D卷积或鸟瞰切片中的2D卷积对物理上靠近的像素进行操作(尽管后者确实将来自不同高度的像素拉到一起,但世界的物理意味着在特定空间位置上不同高度的像素通常属于同一对象)。此外,远处的物体和附近的物体的处理方式完全相同。因此,这些操作本质上更有物理意义,因此应该导致更好的学习和更准确的模型。
为了进一步说明这一点,在图3中,我们进行了一个简单的实验。在左列中,我们展示了原始深度图和图像场景的伪激光雷达表示。场景中的四辆车用颜色突出显示。然后,我们在深度图(右上)上使用box filter执行单个11 × 11卷积,该卷积匹配5层3 × 3卷积的接受域。然后我们将得到的(模糊的)深度图转换为伪激光雷达表示(右下)。从图中可以明显看出,这种新的伪激光雷达表示深受模糊效应的影响。这些汽车被拉伸得远远超出了它们的实际物理比例,因此基本上不可能精确定位它们。为了更好的可视化,我们添加了包含绿色和青色汽车的所有点的矩形。经过卷积后,两个边界框都捕获了高度错误的区域。当然,2D卷积网络将学习使用比框过滤器更智能的过滤器,但是这个例子显示了卷积网络可能执行的一些操作可能接近荒谬。
Discussion and Conclusion
有时候,正是一些简单的发现带来了最大的不同。在本文中,我们已经证明了缩小基于图像和基于激光雷达的3D物体检测之间差距的关键组成部分可能只是3D信息的表示。把这些结果看作是对系统效率低下的纠正,而不是一种新的算法,这可能是公平的,然而,这并不会降低它的重要性。我们的发现与我们对卷积神经网络的理解一致,并通过实证结果得到证实。事实上,我们从这次修正中得到的改进是前所未有的,而且对所有方法都有影响。有了这一巨大的飞跃,基于图像的自动驾驶汽车3D目标检测在不久的将来可能成为现实。这种前景的影响是巨大的。目前,激光雷达硬件可以说是自动驾驶所需的最昂贵的附加组件。没有它,自动驾驶的额外硬件成本就变得相对较小。此外,即使在激光雷达设备存在的情况下,基于图像的目标检测也将是有益的。可以想象这样一种场景:激光雷达数据被用于持续训练和微调基于图像的分类器。在我们的传感器中断的情况下,基于图像的分类器可能会作为一个非常可靠的备份。类似地,我们可以想象这样一种场景:高端汽车配备了激光雷达硬件,并不断训练用于廉价车型的基于图像的分类器。
Future work
在未来的工作中,我们可以沿着多个直接的方向改进我们的结果:首先,更高分辨率的立体图像可能会显著提高远距离物体的精度。我们的结果是用40万像素获得的-与最先进的相机技术相去甚远。其次,在这篇论文中,我们没有关注实时图像处理,并且在一张图像中对所有物体进行分类需要15秒的时间。然而,有可能将这些速度提高几个数量级。最近对实时多分辨率深度估计的改进表明,一种有效的加速深度估计的方法是先在低分辨率下计算深度图,然后在公司高分辨率下对先前的结果进行细化。从深度图到伪激光雷达的转换非常快,应该可以通过模型蒸馏[1]或随时预测[14]来大大加快检测流程。最后,未来的工作可能会通过激光雷达和伪激光雷达的传感器融合来提高3D目标检测的最新水平。伪激光雷达的优点是其信号密度比激光雷达大得多,两种数据模式可以互补。我们希望我们的发现将引起基于图像的3D物体识别的复兴,我们的进展将激励计算机视觉社区在不久的将来完全缩小图像/激光雷达的差距。