三、线性模型
文章目录
softmax是用的改进版一对其余,而剩下的都是二分类的线性模型,即g(f(x))形式,不一样的是他们使用了不同的损失函数,这会导致他们学出来的模型不一样,所以取的名字也不一样
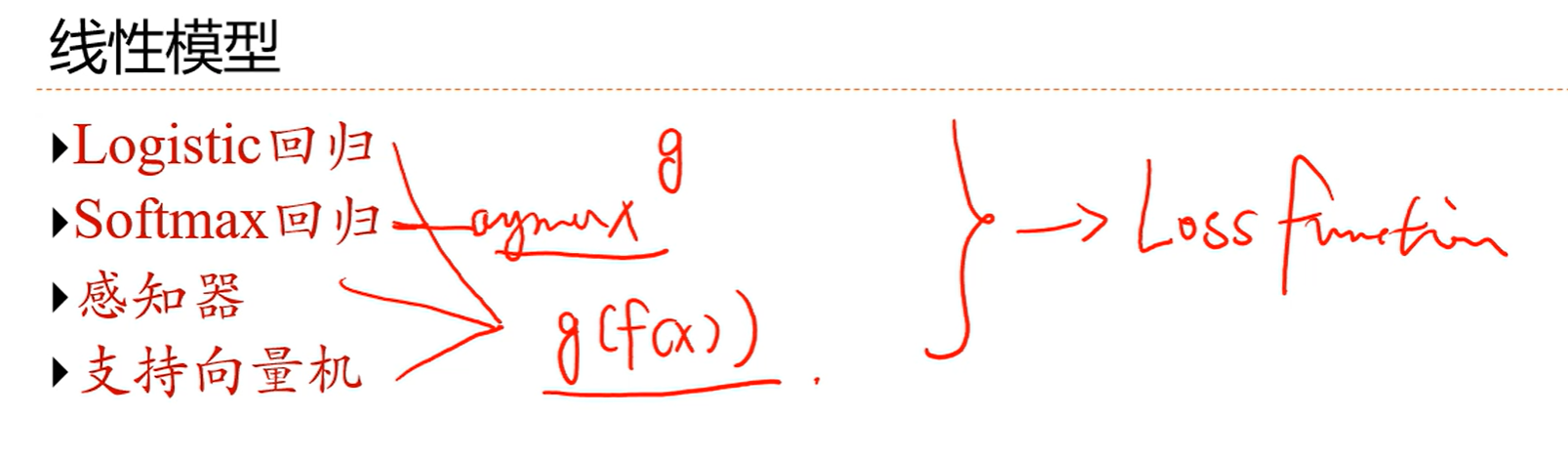
3.1 分类问题示例
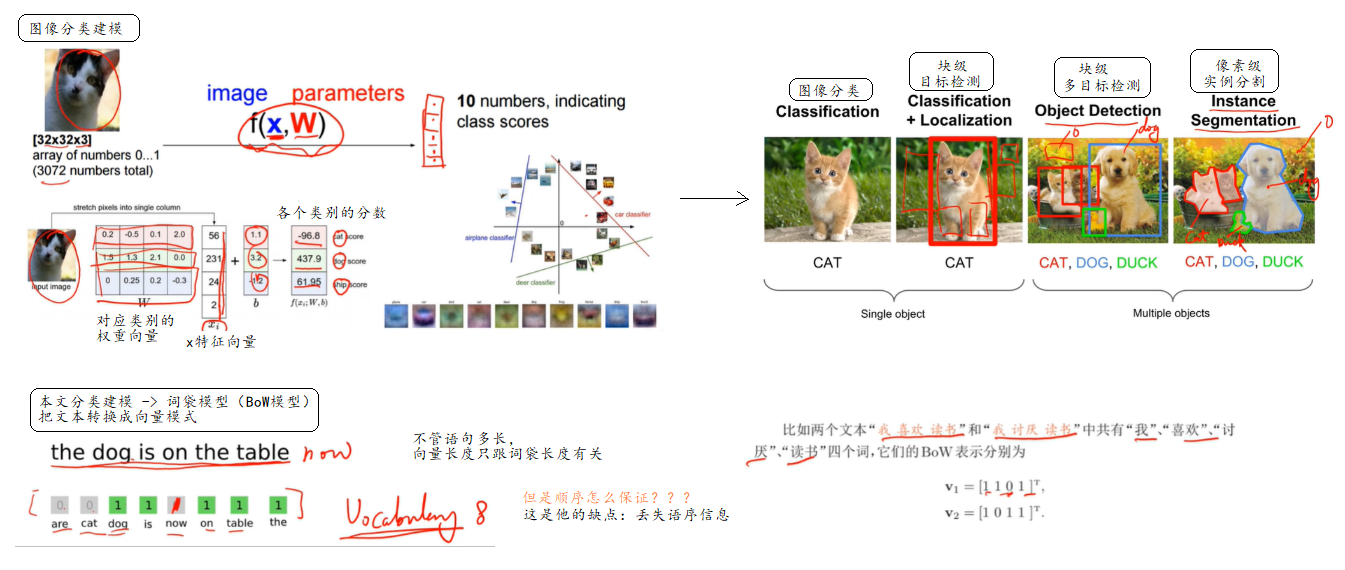
图像识别,垃圾邮件过滤,文档归类,情感分类这些都是分类问题
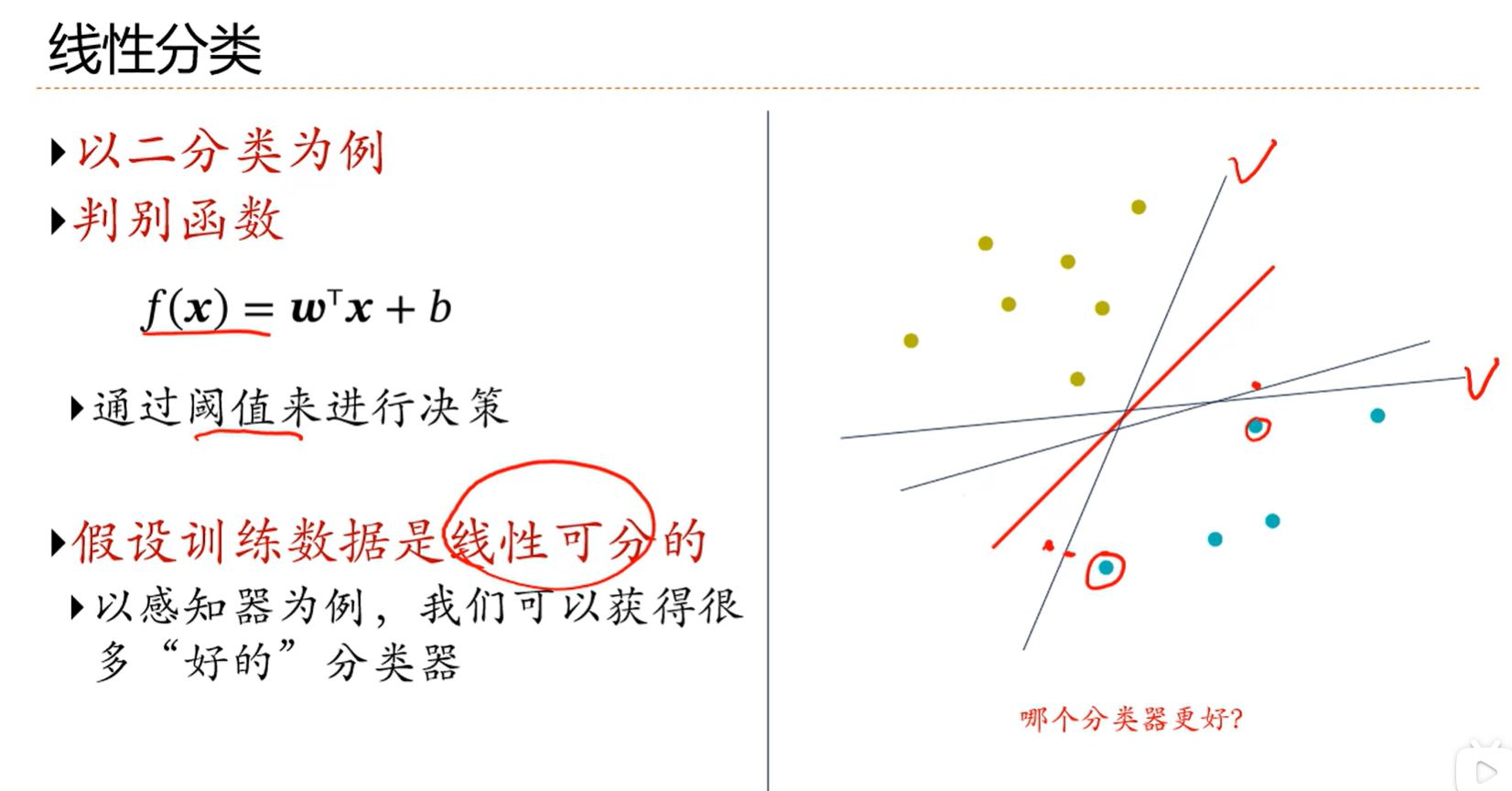
3.2 线性分类模型
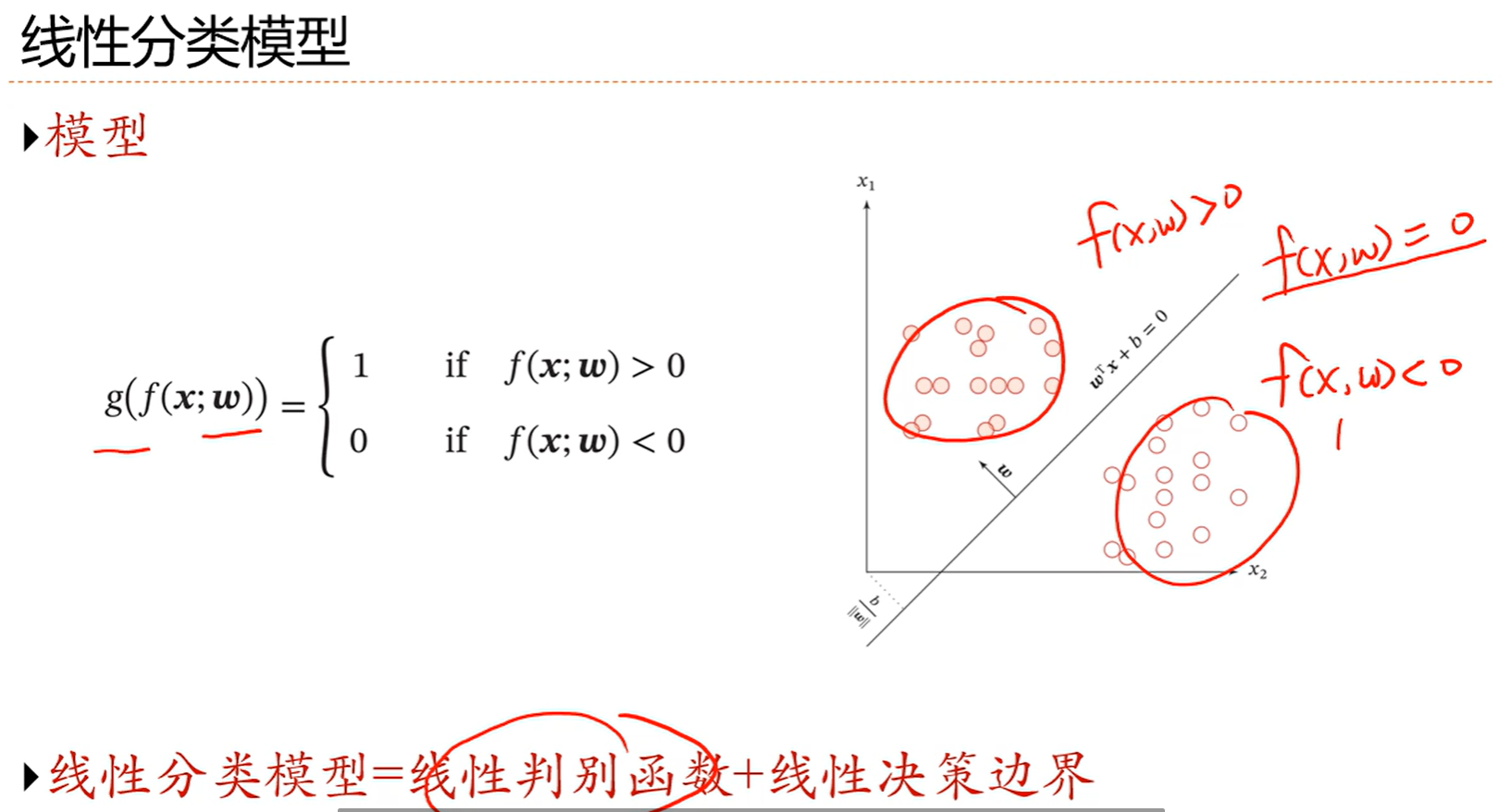
fx是判别函数,g(f(x))是决策函数 0和1表示正类和负类

一条线把两个分类隔开
有了模型下一个就是学习准则就是损失函数,01损失函数不可求导,无法转化为最优化问题所以要重新选择一个更好的损失函数

多分类不可以用一个函数表示,那就表示要用多个函数表示
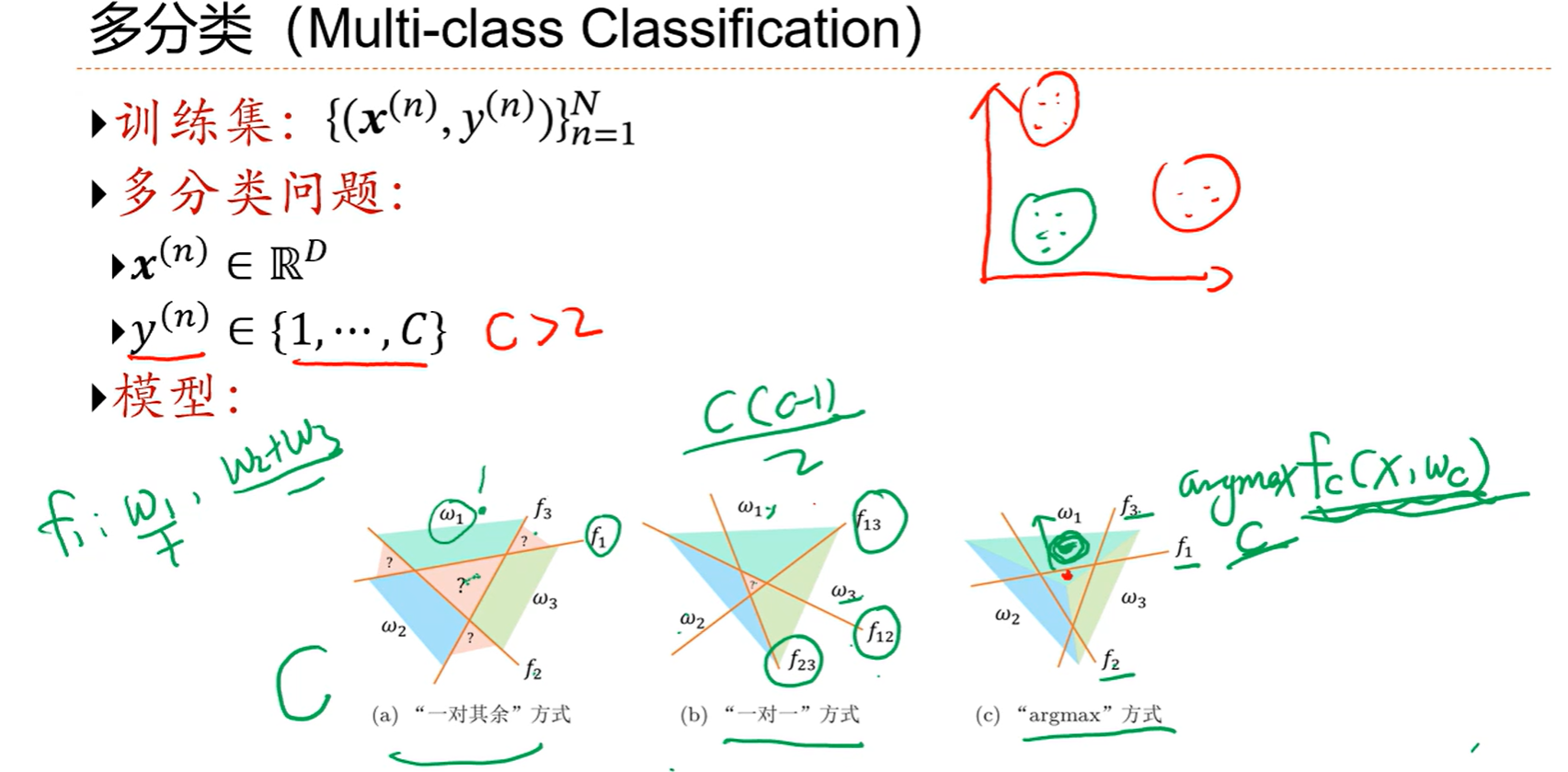
虽然是改进的一对其余,但是仍然是不可导的,那说明我们还是得去找一个更好的损失函数

3.3 交叉熵和对数似然
信息压缩就是信息编码

applicatio_剩下的字符几乎只能写n,概率就是1
appl_剩下的字符可以是e可以是y,概率就是分别0.5,或者根据使用频率另外再说
自信息衡量一个随机事件的信息量是多少
其实就是对应概率的取对数的相反数
表示的其实就是一个事件如果经常发生,那说明这件事包含的信息量就很少
applicatio_就没有什么信息量,因为他的结果几乎是确定的,也就是说最后一位取n这件事经常发生
而另外appl_那就有信息量了,因为他的结果并不确定,结果越不确定信息量越大
信息量具有可加性


可以用来衡量两个分布的差异

KL散度是用概率分布q来近似p时所造成的信息损失量;
最小化KL散度=最小化交叉熵损失=最大化对数似然


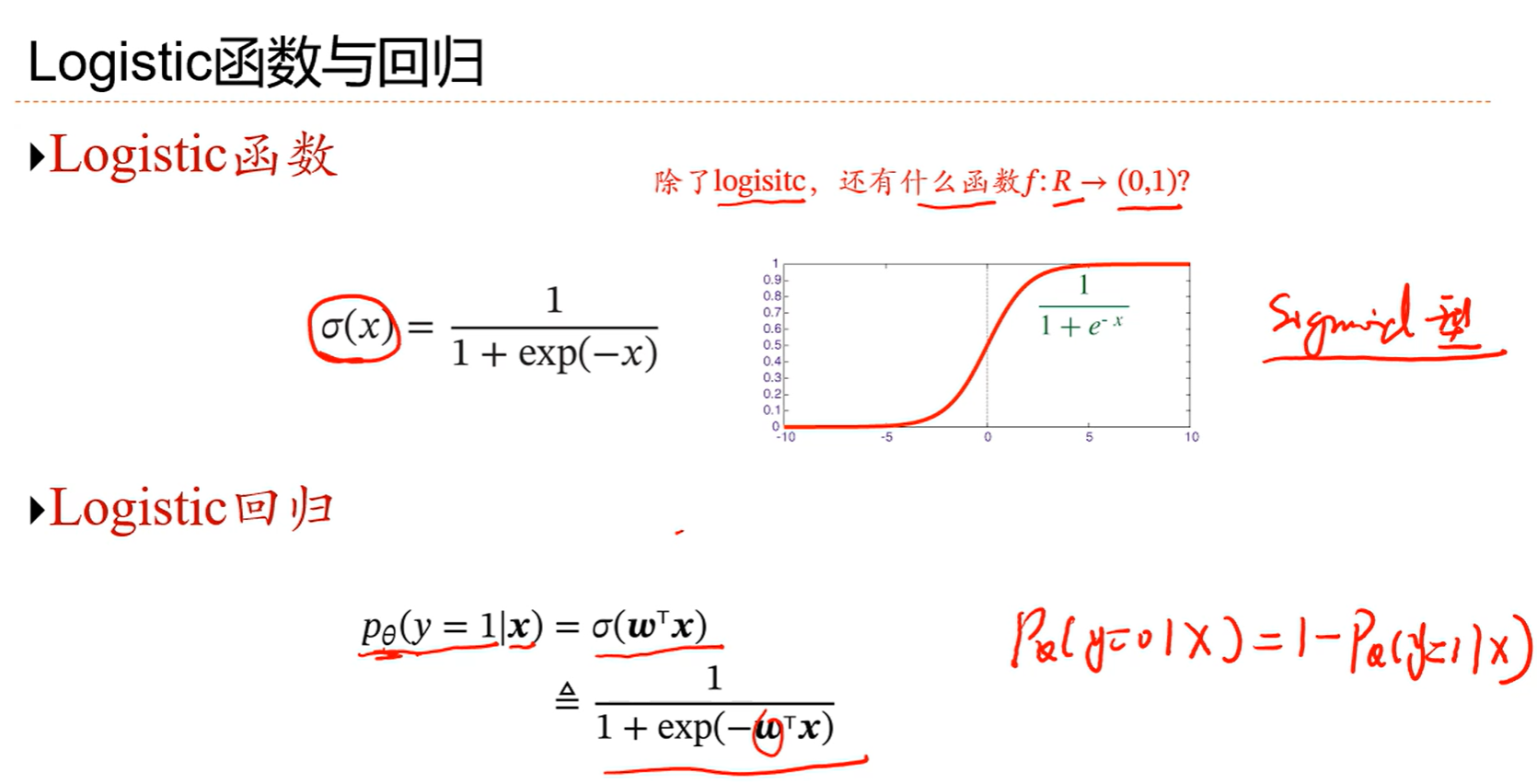
3.4 Logistic回归
用交叉熵作为损失函数,并使用梯度下降法进行参数优化
logistic回归 != 逻辑回归
判别函数fx=wtx
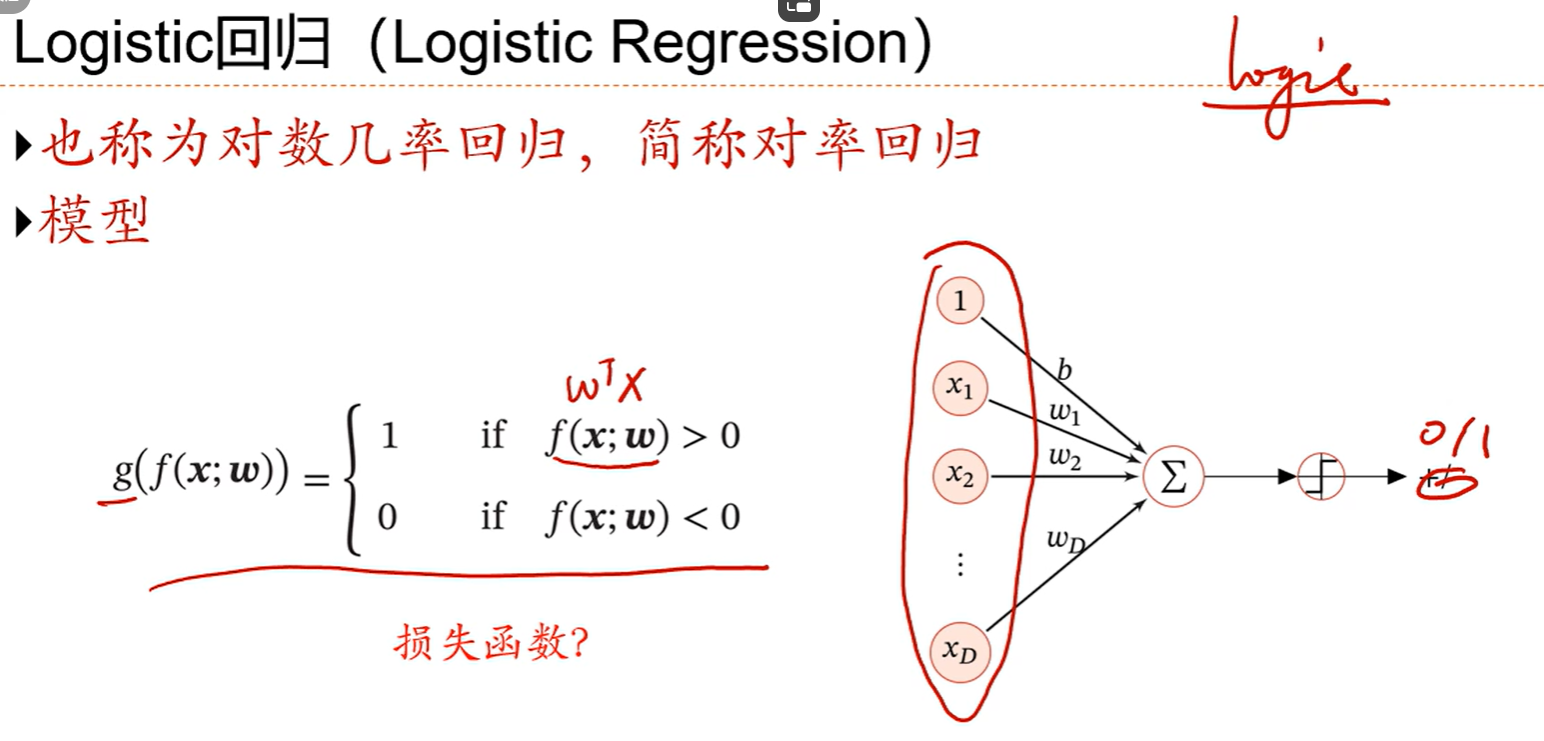



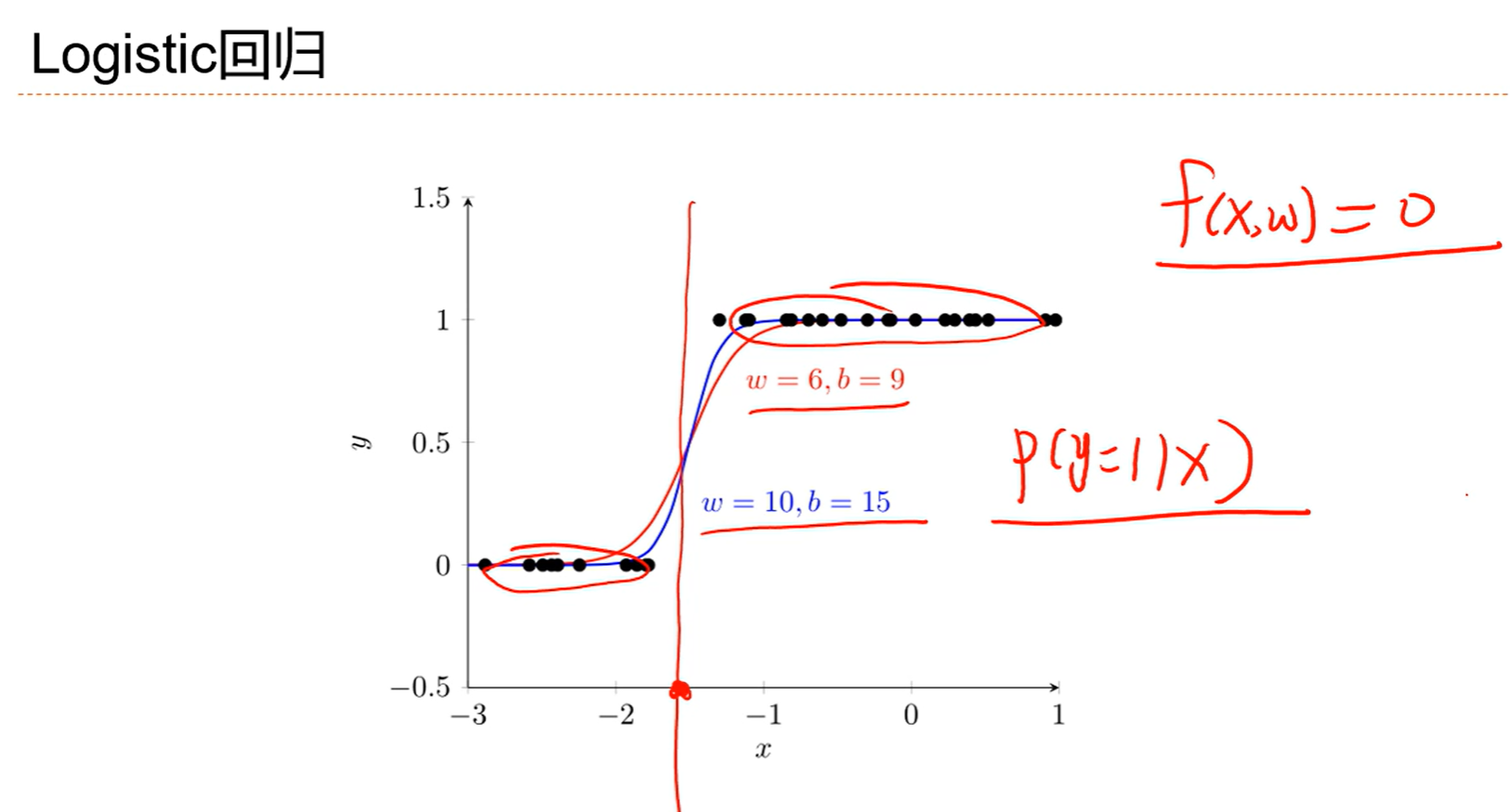
没必要优化到01分布,只要能够优化到能把两个分类给分开就好了
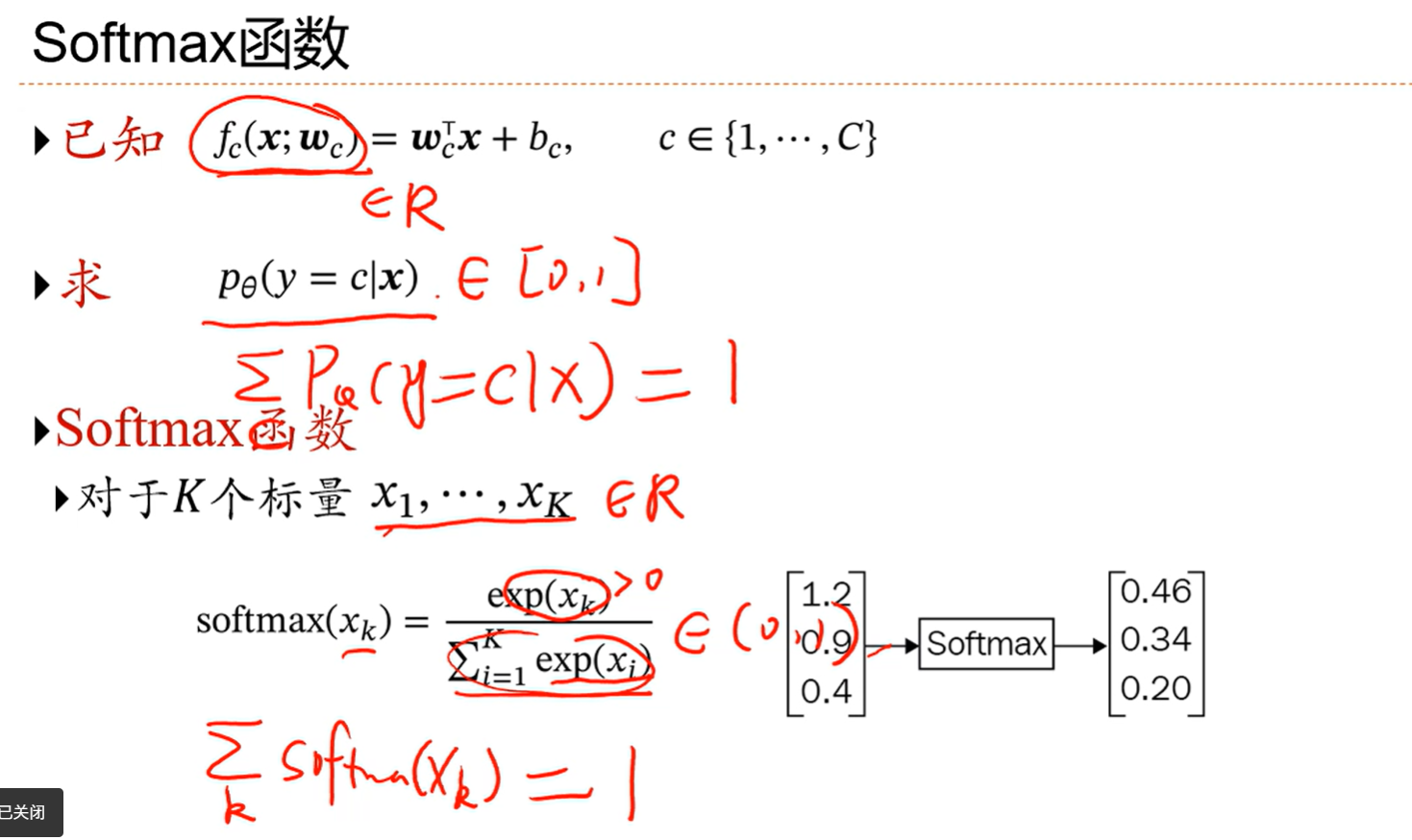
3.5 Softmax回归
解决多分类问题;
把要分类的东西代入fc,哪个分类的评分最高,就把东西归为哪个分类

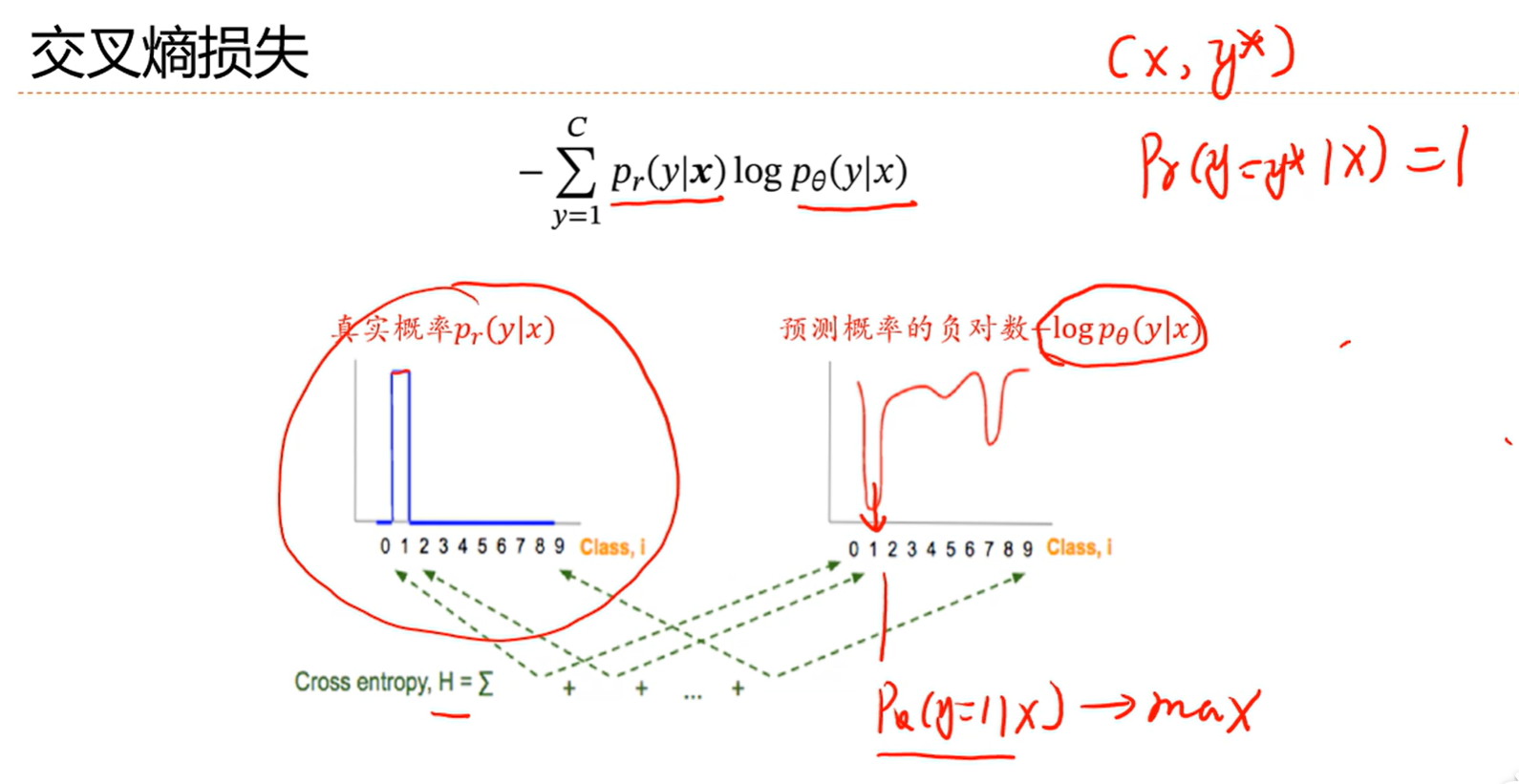
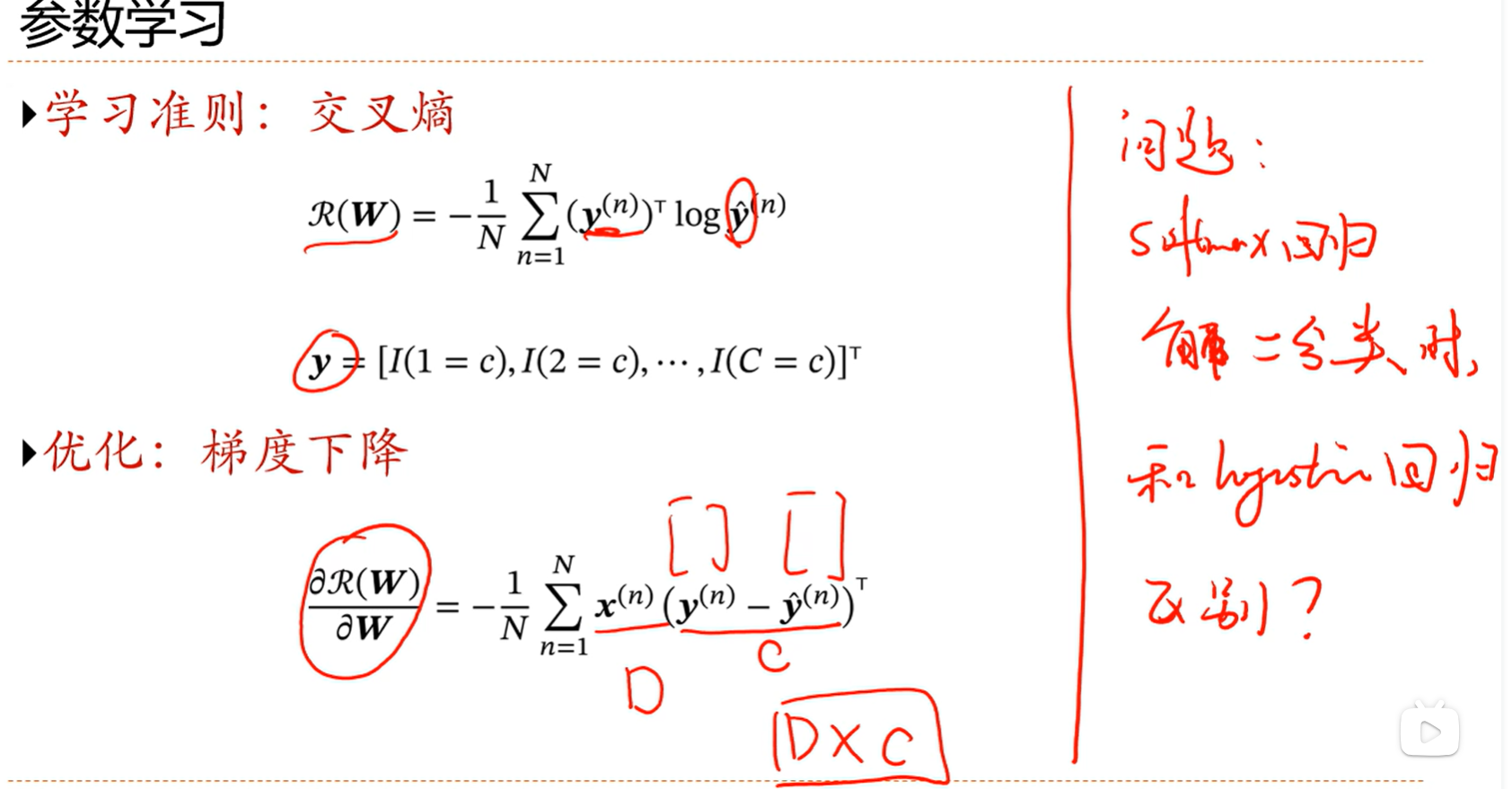
学习准则:参数化的条件概率和真实条件概率的交叉熵

损失函数:依旧使用交叉熵
交叉熵损失也是一种最大似然估计

图中y是真实概率,y^是softmax函数预测出来的概率
而y这个向量就是一个one hot向量
c取1,那第一维就是1,剩下的都是0
c取2,那第二维就是2,剩下的都是0
答案(元宝的部分答案:
| 维度 | Softmax回归(二分类) | Logistic回归 |
|---|---|---|
| 数学形式 | 等价于Logistic,但需参数冗余处理 | 直接通过Sigmoid输出概率 |
| 正则化 | 必需(避免参数冗余) | 可选(通常用于防止过拟合) |
| 实现复杂度 | 需处理多分类框架(如两个输出神经元) | 单神经元输出,实现更简单 |
| 扩展性 | 天然支持多分类 | 需额外策略(如“一对多”) |
| 适用场景 | 互斥类别 | 互斥或非互斥均可 |
实际建议:若问题明确为二分类且无需扩展,优先使用Logistic回归(代码更简洁);若未来可能扩展为多分类,或需统一模型结构,可选用Softmax回归
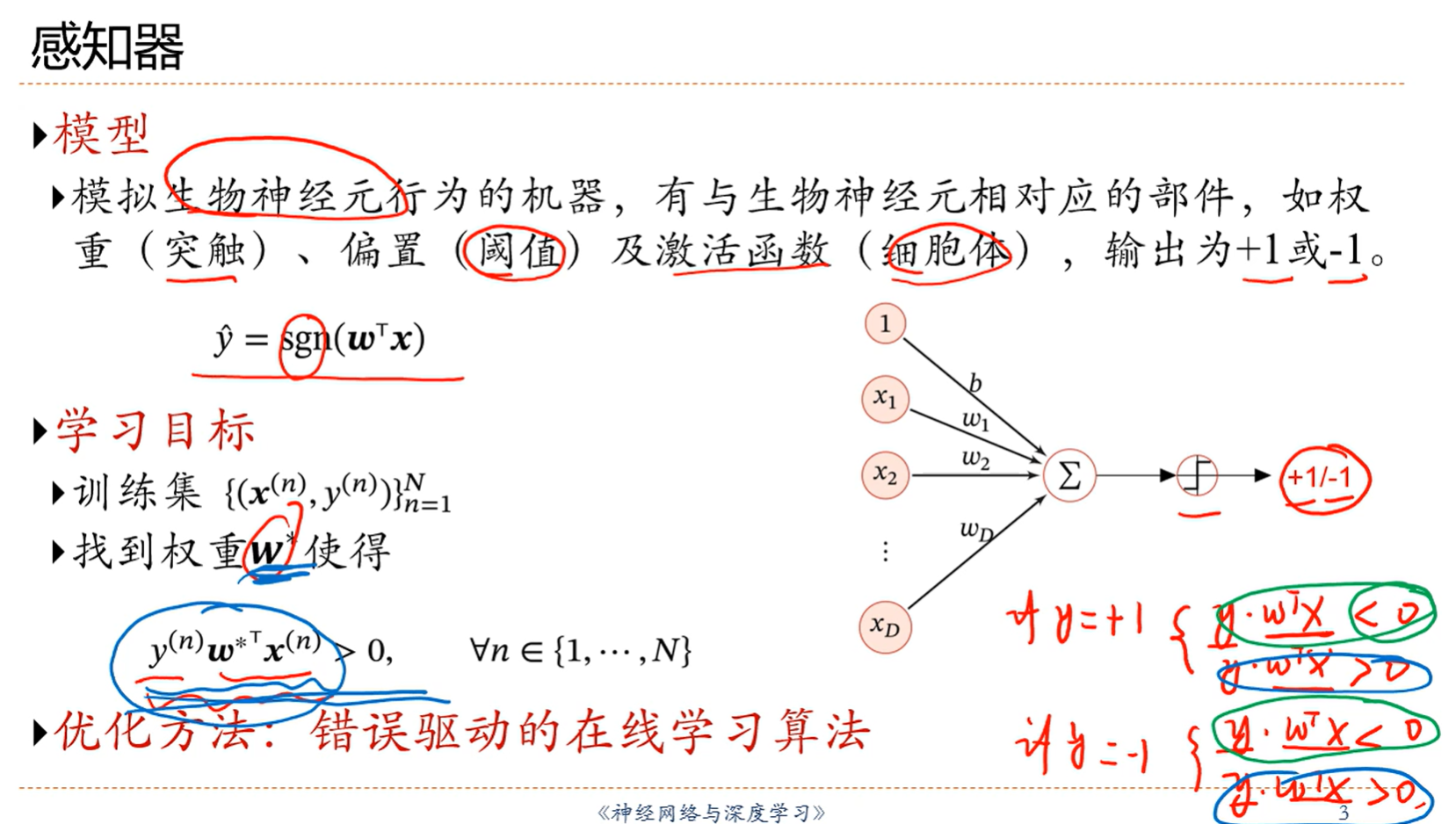
3.6 感知机
sgn是符号函数,大于0返回1小于0返回-1
不管y=1还是-1,ywx<0都代表分类分错了
如果y=1,ywx<0,那么wx就<0,根据y^=wx,预测的结果就是-1,但是y=1,说明分类分错了,剩下的情况都类似分析
不管y=1还是-1,ywx>0都代表分类分对了
学习目标就是找到这个w使得上面这两条成立
感知器前提:数据集是线性可分的,不然w就不存在

只有在犯错的时候才会更新参数,更新就用w+yx代替w,最后证明出来yw(t+1)x>=ywtx,说明每一次迭代参数都会增大,直到ywx大于0,说明了有一种能力可以把错误给纠正
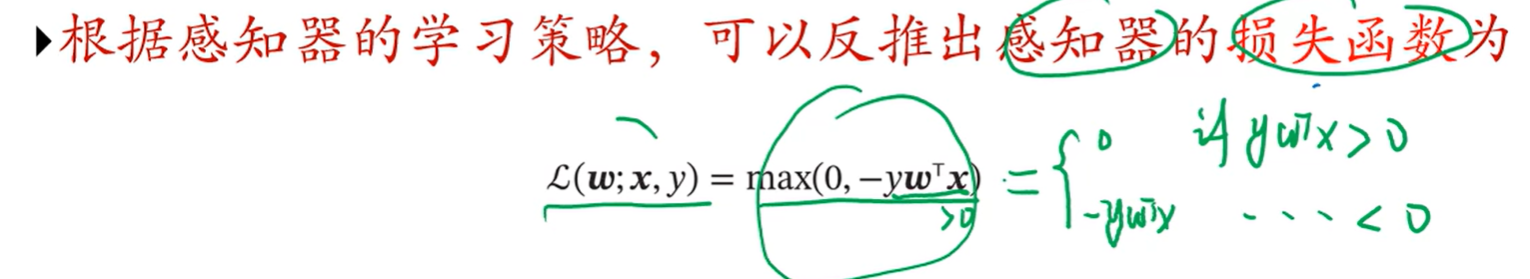

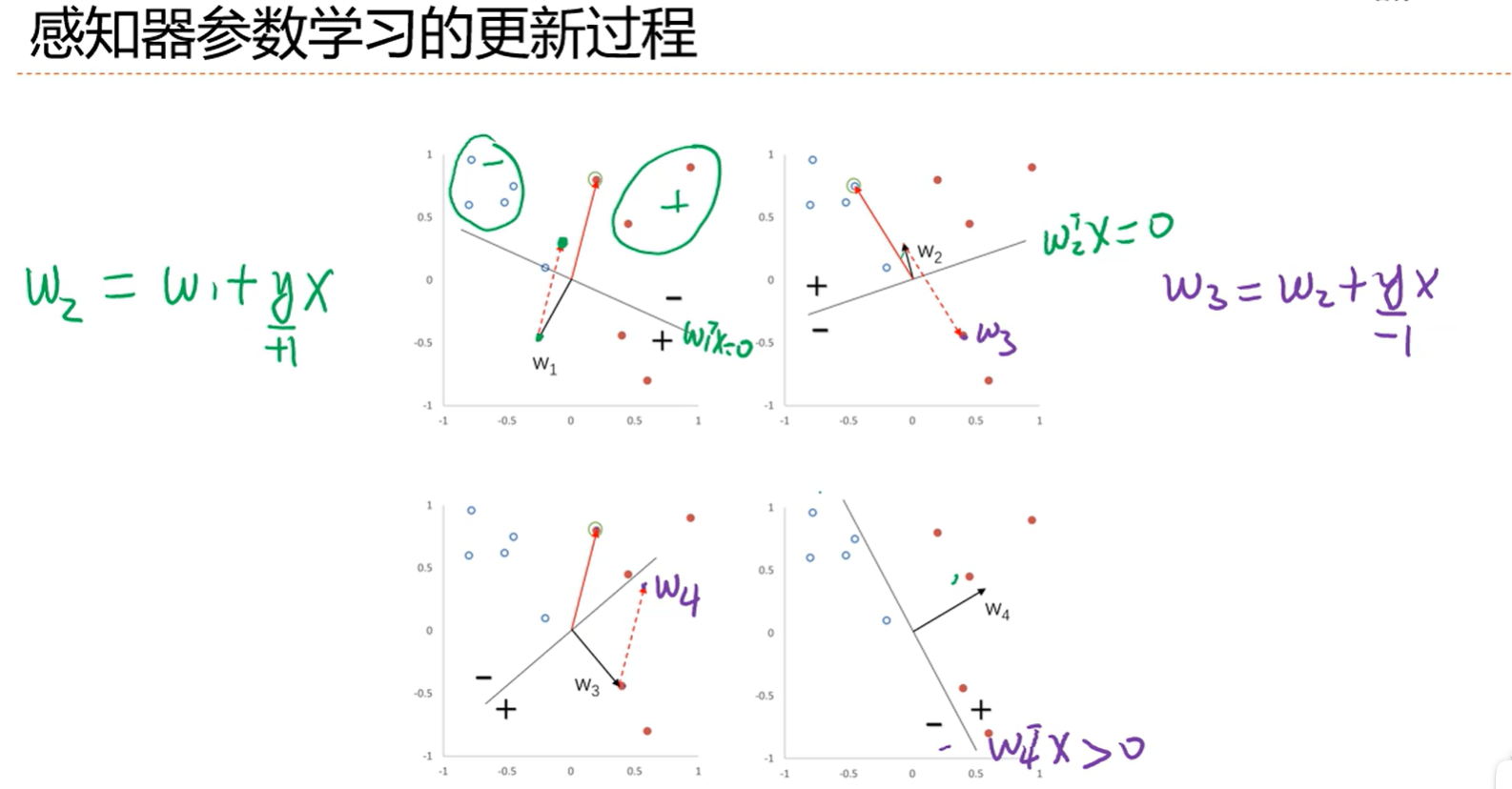
分界线的直线方程就是wx,第一个是w1x,第一个分不开两个类别,那么就迭代到第二个,第二个是wx2,w2=w1+yx

也就是说迭代次数一定会在R2/y2之内完成更新,即我已经可以在有限的次数内一个权重w使得wx可以把两个分类给分开


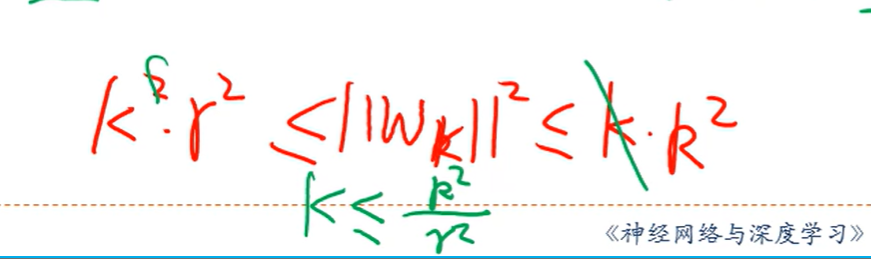
这个k可以描述样本的分离程度
如果伽马越大说明两类样本分得很开,越小说明分的越不开
分母即伽马越大,那么所需要的迭代次数就越小,因为样本分得很开更容易找到一个分界线wx分开两类样本
3.7 支持向量机
一个良好的分界线,他要离所有的样本都比较远,这样不至于因为某个噪声点而造成较大的干扰,直观上也会感觉模型的健壮性更好;容忍一定的噪声问题;
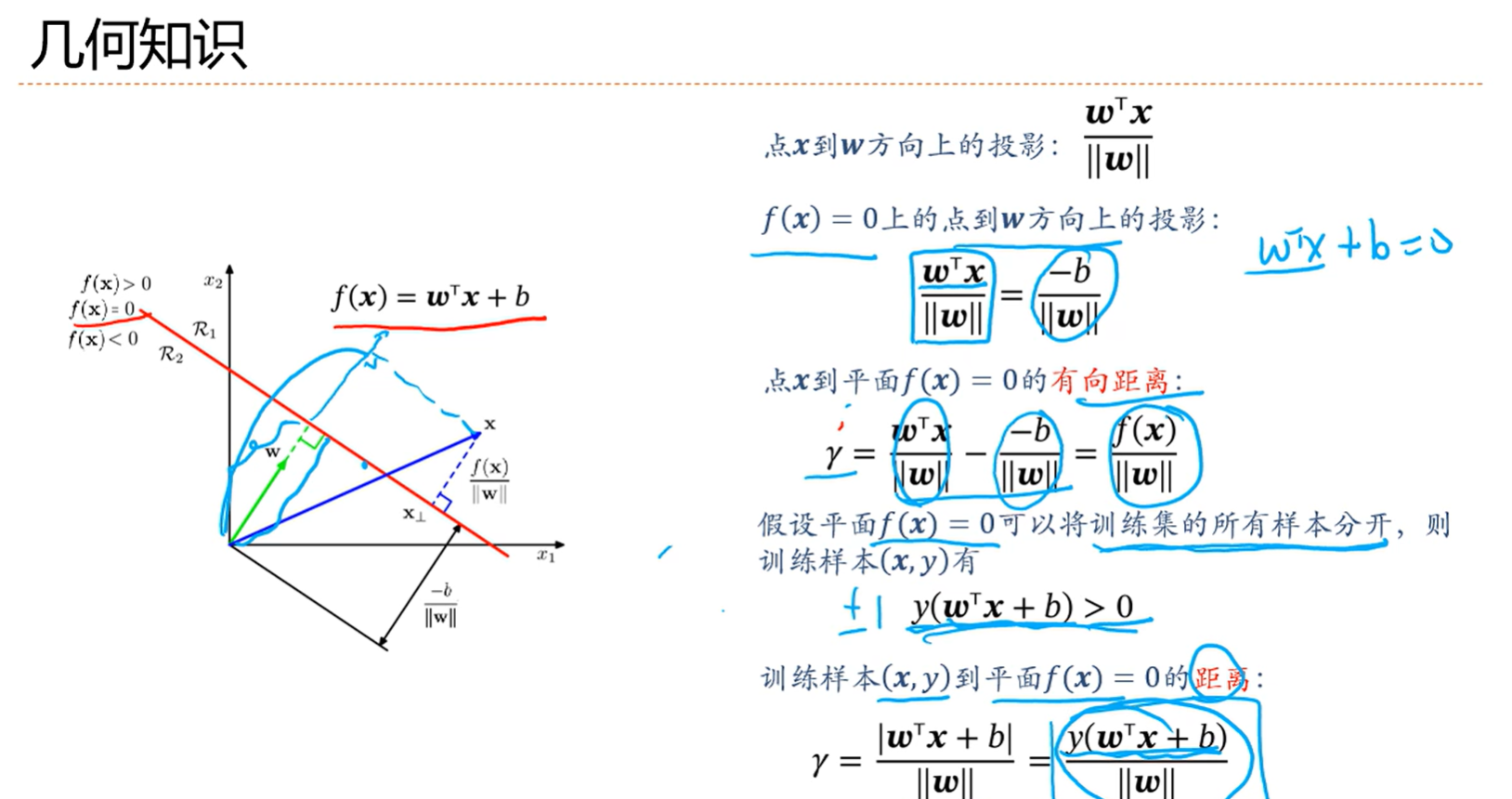
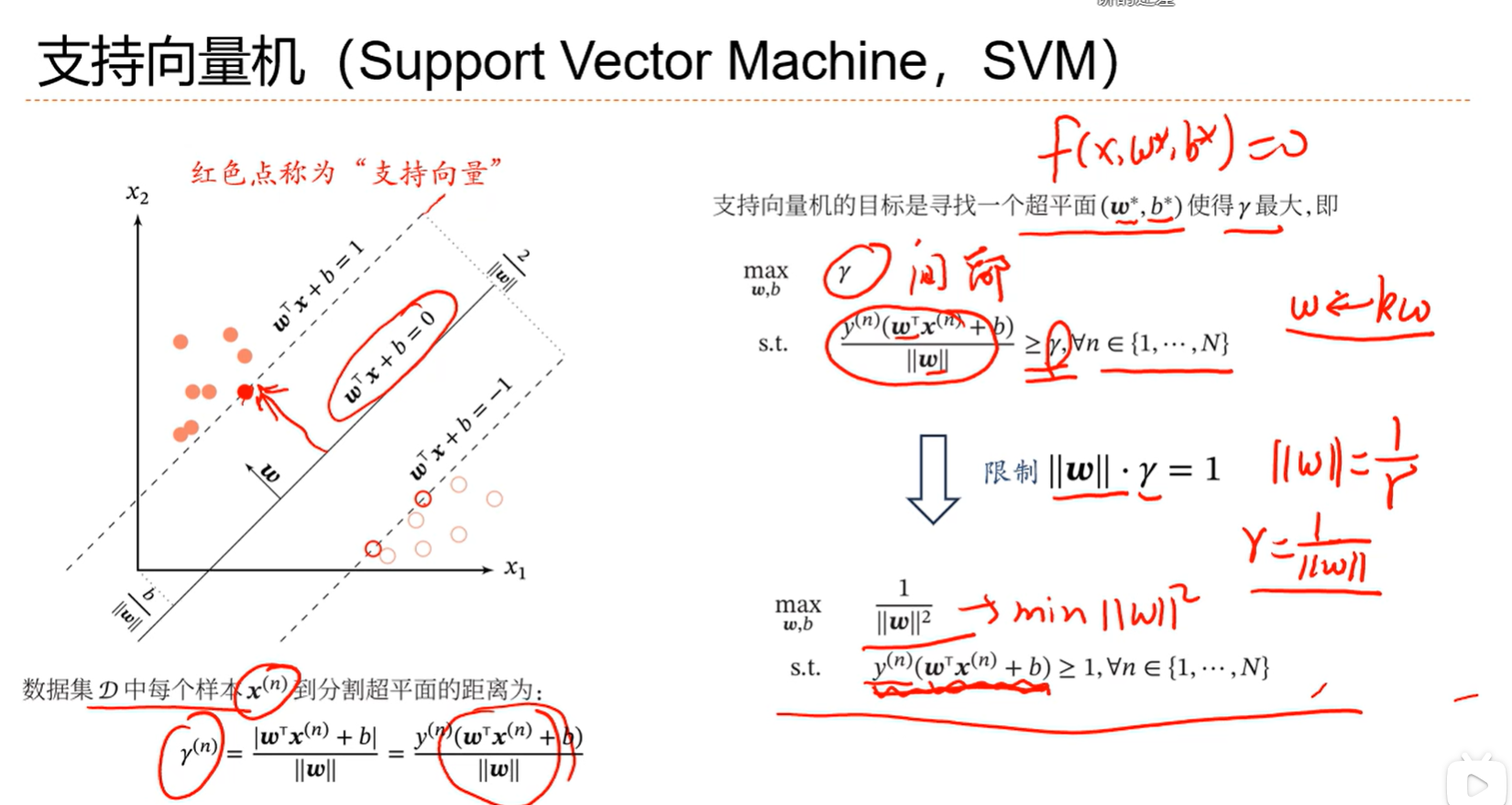
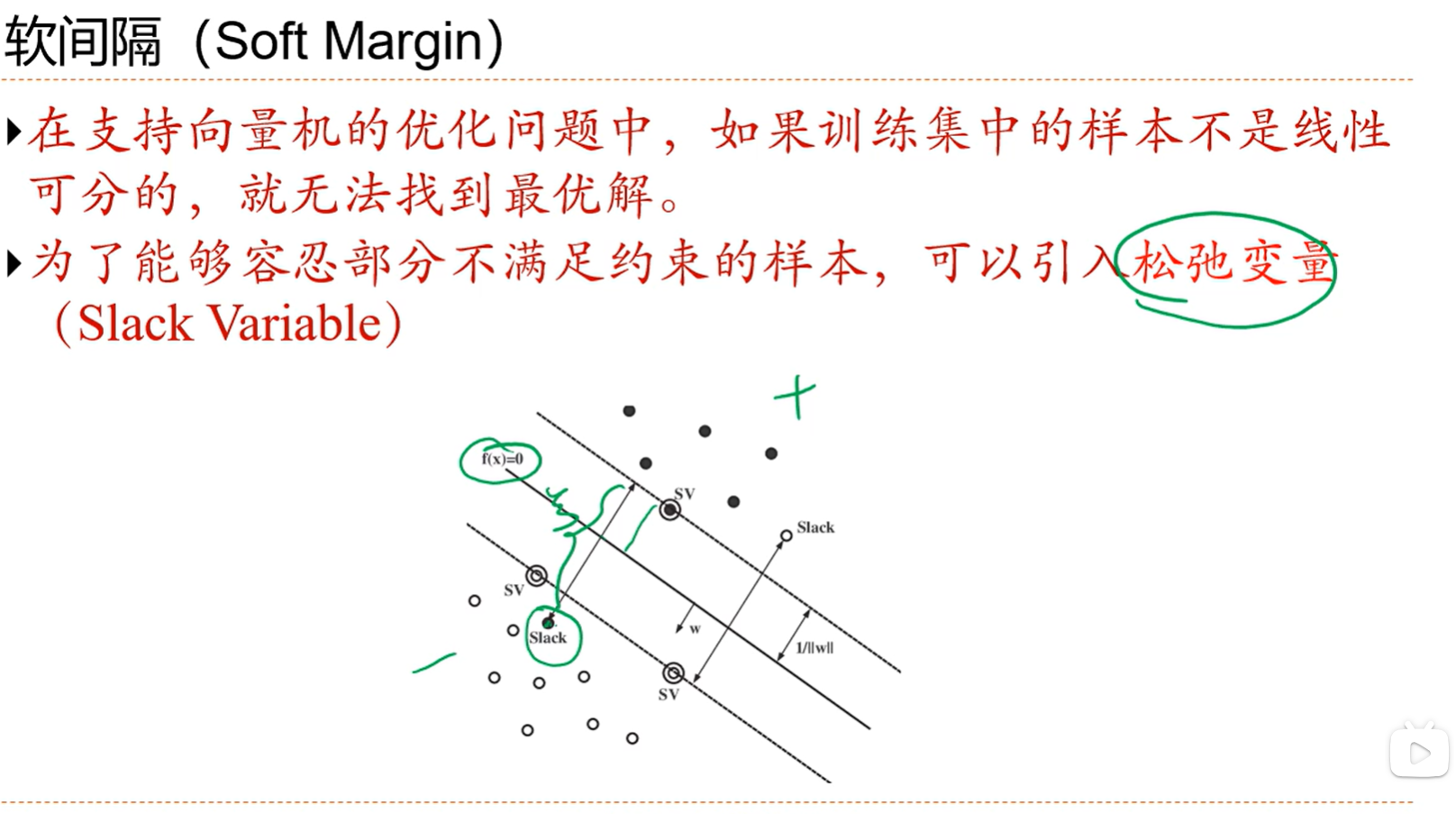
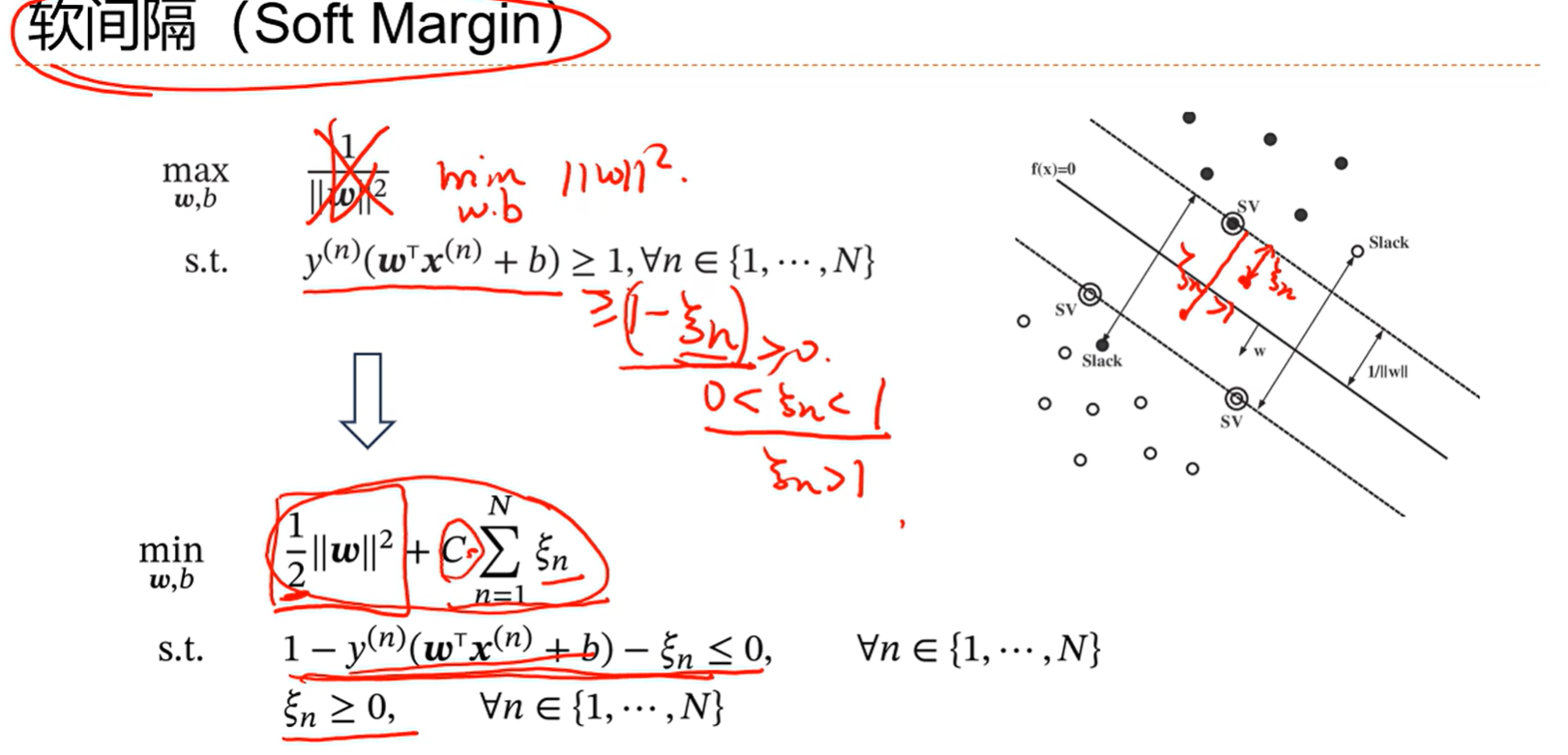
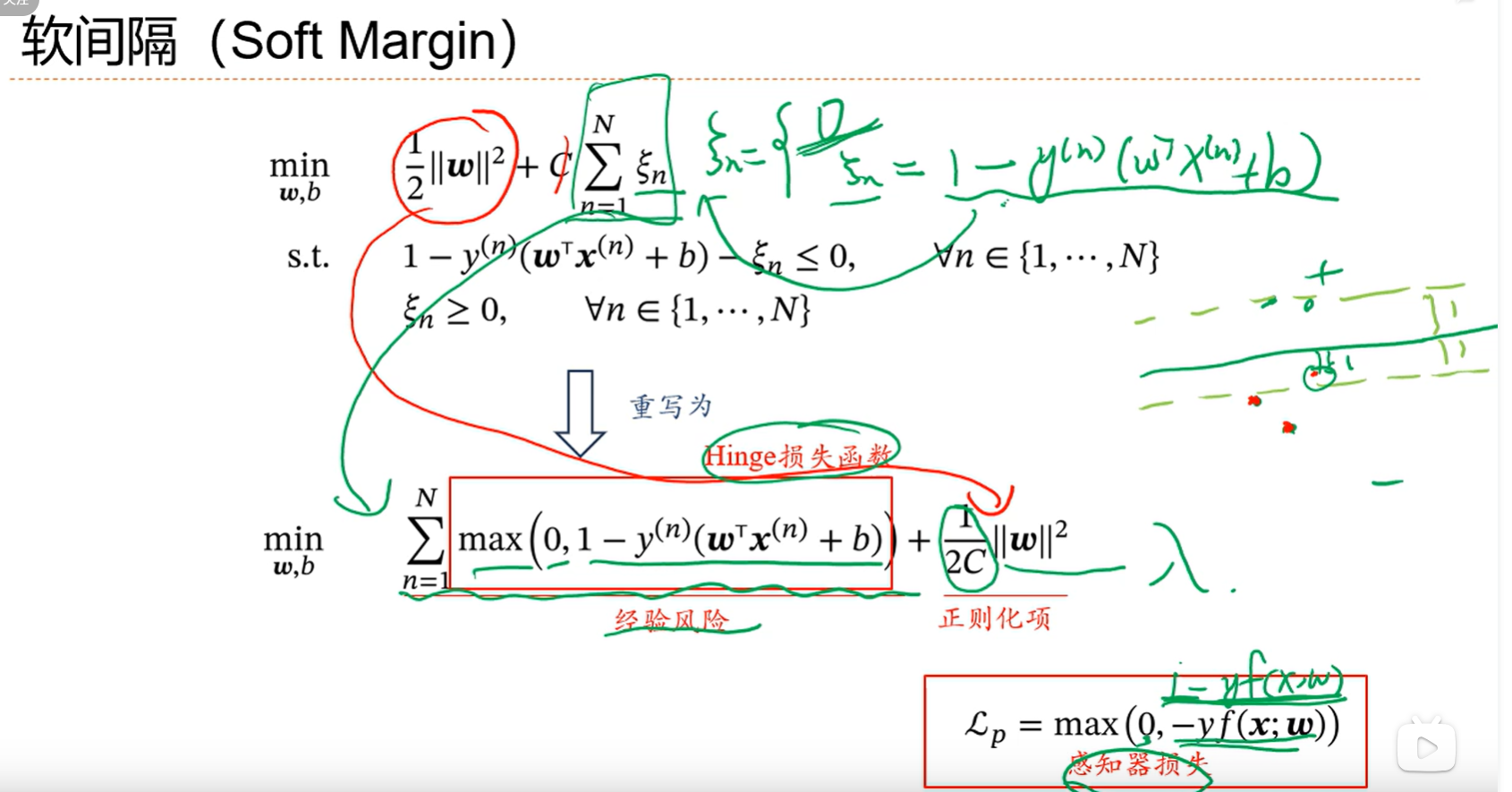
感知器是分类分对了就行,支持向量机是支持向量距离wx还要大于一个间隔
3.8 线性模型小总结


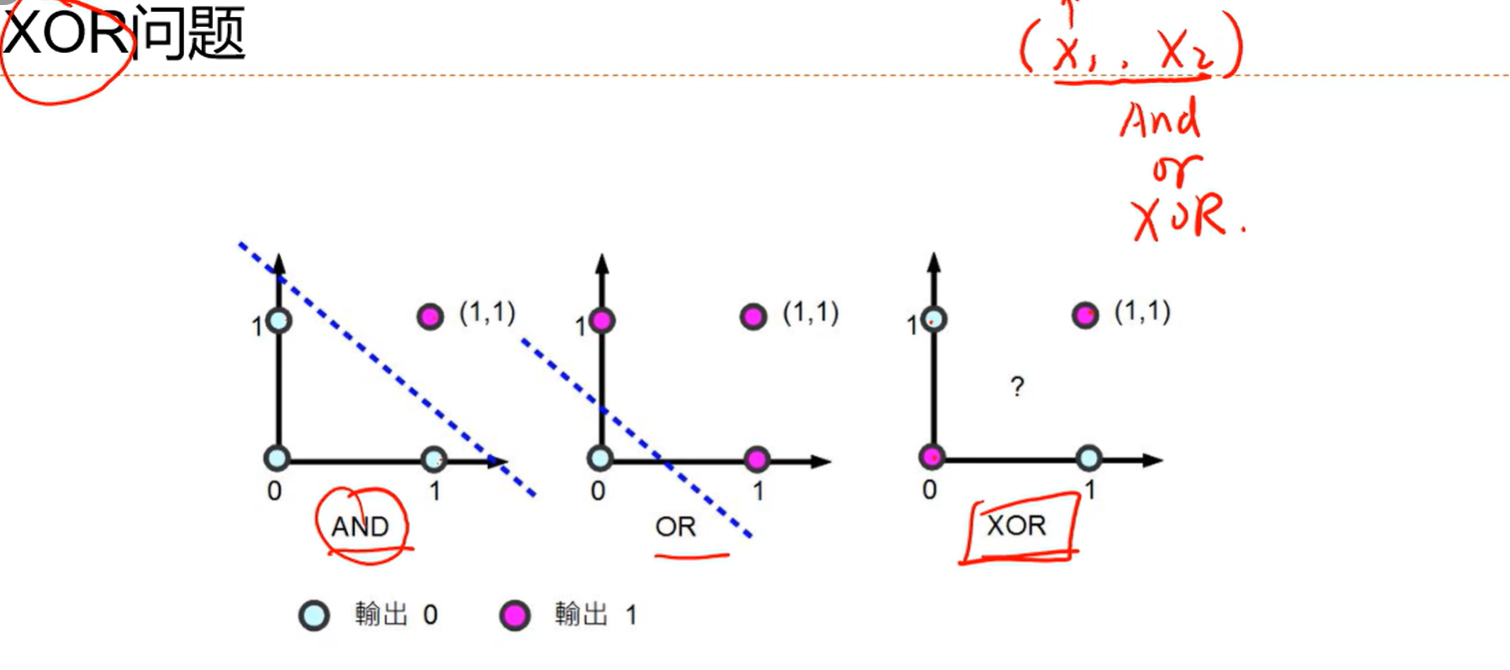
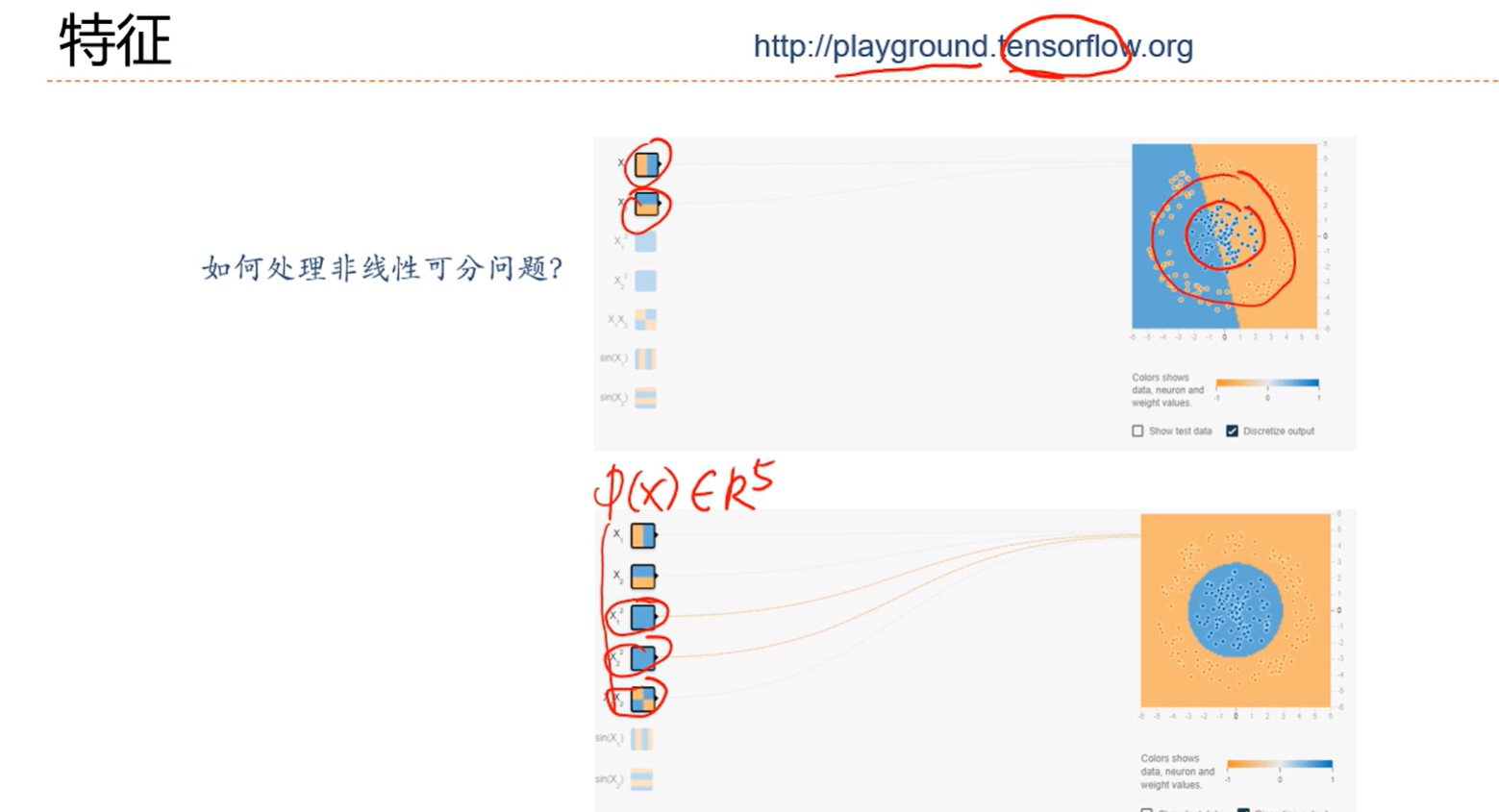
解决方案:
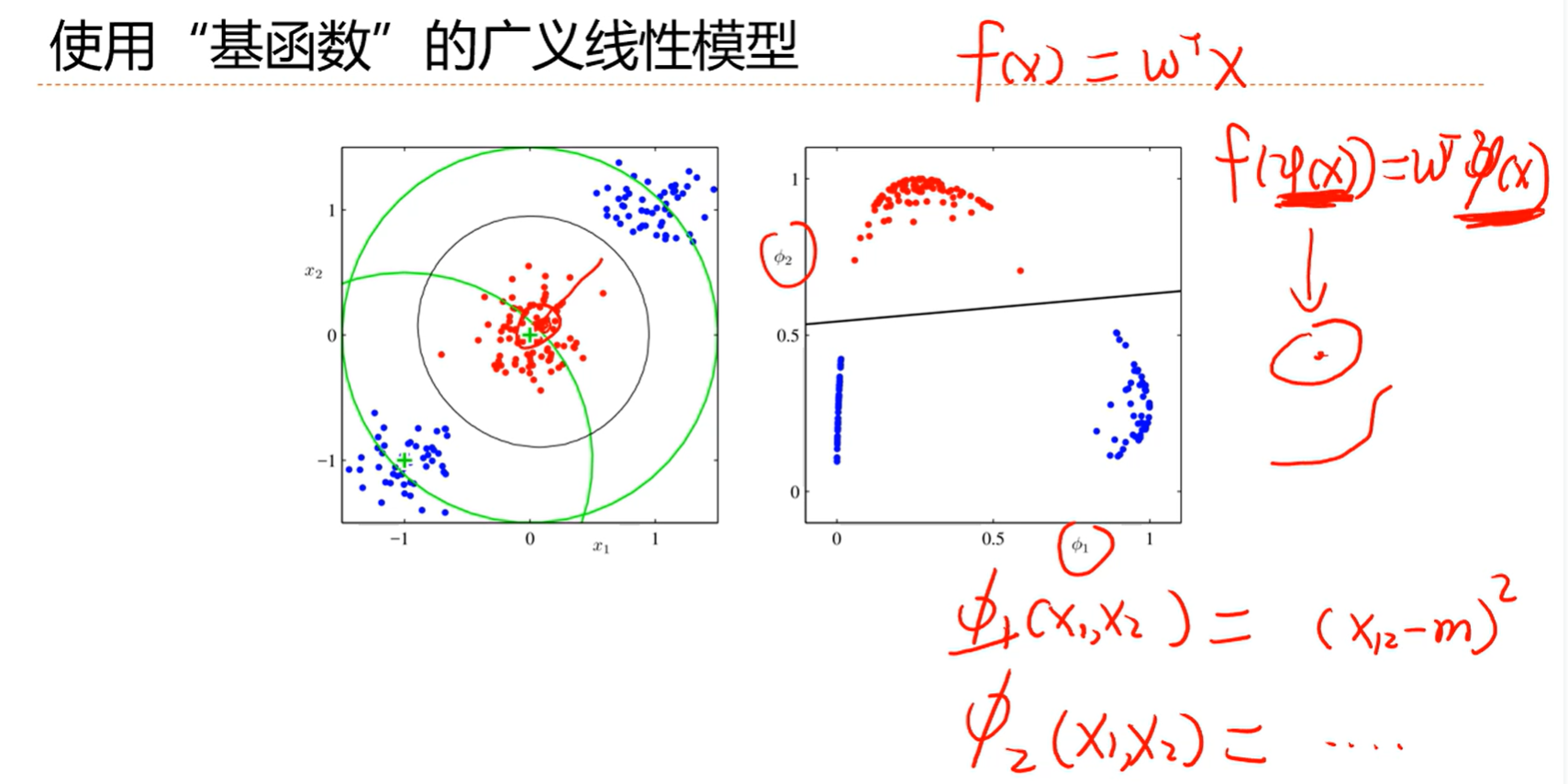
多加了几个维度能找到平面给分成两类的