决策树与随机森林:从原理到实战的全面解析(2025最新版)
引言
在机器学习的世界里,决策树和森林模型(包括随机森林)常常是数据科学家们常用的工具之一。无论是初学者还是资深从业者,理解这些模型的原理和应用,都能帮助你在数据分析和预测任务中获得更好的结果。本文将从基础概念到进阶应用,逐步介绍决策树、决策森林和随机森林的知识,并结合2025年的最新技术趋势,分享一些实践经验和未来的技术风向。
一、决策树:机器学习的基础模型
1.1 决策树是什么?
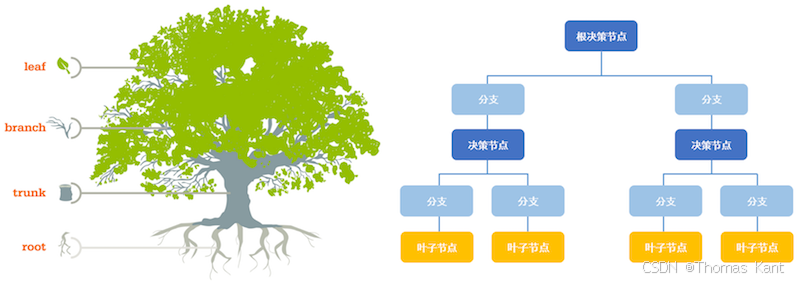
决策树(Decision Tree,简称DT)是一种常用的分类与回归模型,尤其在处理具有层级结构的数据时,表现十分优异。简单来说,决策树就像一棵树,它通过从根节点到叶节点的路径进行决策。
- 根节点(Root Node):表示数据的特征或属性。
- 分支(Branch):通过某个属性的阈值将数据分成不同的子集。
- 叶节点(Leaf Node):最终预测的类别或值。
1.2 决策树如何工作?
决策树的构建是一个递归过程,算法会基于某个特征或属性将数据集不断分割,直到满足某个停止条件(如数据纯度达到某个阈值,或者树的深度达到最大值)。每次分割时,决策树都会选择一个最能区分数据的特征,这个过程通常通过“信息增益”(ID3算法)或“基尼不纯度”(CART算法)等度量标准来决定。
- 信息增益:衡量通过某个特征进行数据划分后,数据的不确定性降低的程度。
- 基尼不纯度:衡量数据集的不纯度,数值越小,表示该节点的数据越纯。
1.3 决策树的最新演进(2025前沿)
决策树算法已从传统的ID3/C4.5/CART发展为代价敏感混合分裂策略的新型算法:
- Gini系数与信息增益的线性组合: S c o r e = α ⋅ G i n i + ( 1 − α ) ⋅ I G Score = \alpha \cdot Gini + (1-\alpha) \cdot IG Score=α⋅Gini+(1−α)⋅IG
- 代价敏感因子加权:对少数类错误施加更高惩罚权重,解决样本不平衡问题
- 多根节点并行构建:每个特征作为独立根节点生成子树,提升对稀疏特征的捕捉能力
1.4 优缺点
优点:
- 直观易懂,输出结果可以通过图形呈现。
- 可以处理分类和回归问题。
- 不需要对数据进行过多预处理,如归一化和标准化。
缺点:
- 容易过拟合,特别是树的深度过大时。
- 对噪声数据敏感。
二、决策森林与随机森林
2.1 决策森林的概念
“决策森林”通常指的是多个决策树的集合。一个单独的决策树可能不够强大,容易出现过拟合的情况,而通过集成多个决策树,可以降低模型的方差,提高泛化能力。这就是集成学习的核心思想。
2.2 随机森林:集成学习中的明星模型
随机森林(Random Forest,简称RF)是一种基于决策树的集成学习方法,它通过构建多个决策树,并结合投票或平均的方式来进行最终预测。与传统的决策树不同,随机森林通过以下两种技巧来增强模型的表现:
- Bootstrap抽样(自助法):对于每棵树,随机从原始训练数据中有放回地采样,得到不同的子集来训练每棵树。
- 随机特征选择:每次节点分裂时,不是考虑所有特征,而是随机选择一部分特征进行分裂,这样可以减少树之间的相关性。
2.3 随机森林的数学本质
随机森林通过双重随机性降低方差:
- Bootstrap采样:生成M个样本子集
( x i ∗ m , y i ∗ m ) i = 1 n , m = 1 , 2 , . . . , M (x_i^{*m}, y_i^{*m})_{i=1}^n, m=1,2,...,M (xi∗m,yi∗m)i=1n,m=1,2,...,M - 特征随机选择:每个节点仅考虑 d \sqrt{d}