拥有一个文件,其中文件内容(内容随便写符合规矩即可)分别为电话号码 上行流量 下行流量(第一行是写给大家看的 注释不用写出来)
提前创好一个文件夹分为四个类
FlowBean中的代码内容为:
package org.example.flow;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//hadoop 序列化
//三个属性:手机号,上行流量,下行流量
public class FlowBean implements Writable {
private String phone;
private Long upFlow;
private Long downFlow;
public FlowBean(String phone, Long upFlow, Long downFlow) {
this.phone = phone;
this.upFlow = upFlow;
this.downFlow = downFlow;
}
//定义get/set方法
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public Long getUpFlow() {
return upFlow;
}
public void setUpFlow(Long upFlow) {
this.upFlow = upFlow;
}
public Long getDownFlow() {
return downFlow;
}
public void setDownFlow(Long downFlow) {
this.downFlow = downFlow;
}
//定义无参结构
public FlowBean() {}
//定义一个获取总流量的方法
public Long getTotalFlow(){
return upFlow+downFlow;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(phone);
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
phone = dataInput.readUTF();
upFlow = dataInput.readLong();
downFlow = dataInput.readLong();
}
}FlowDriver中的代码内容为:
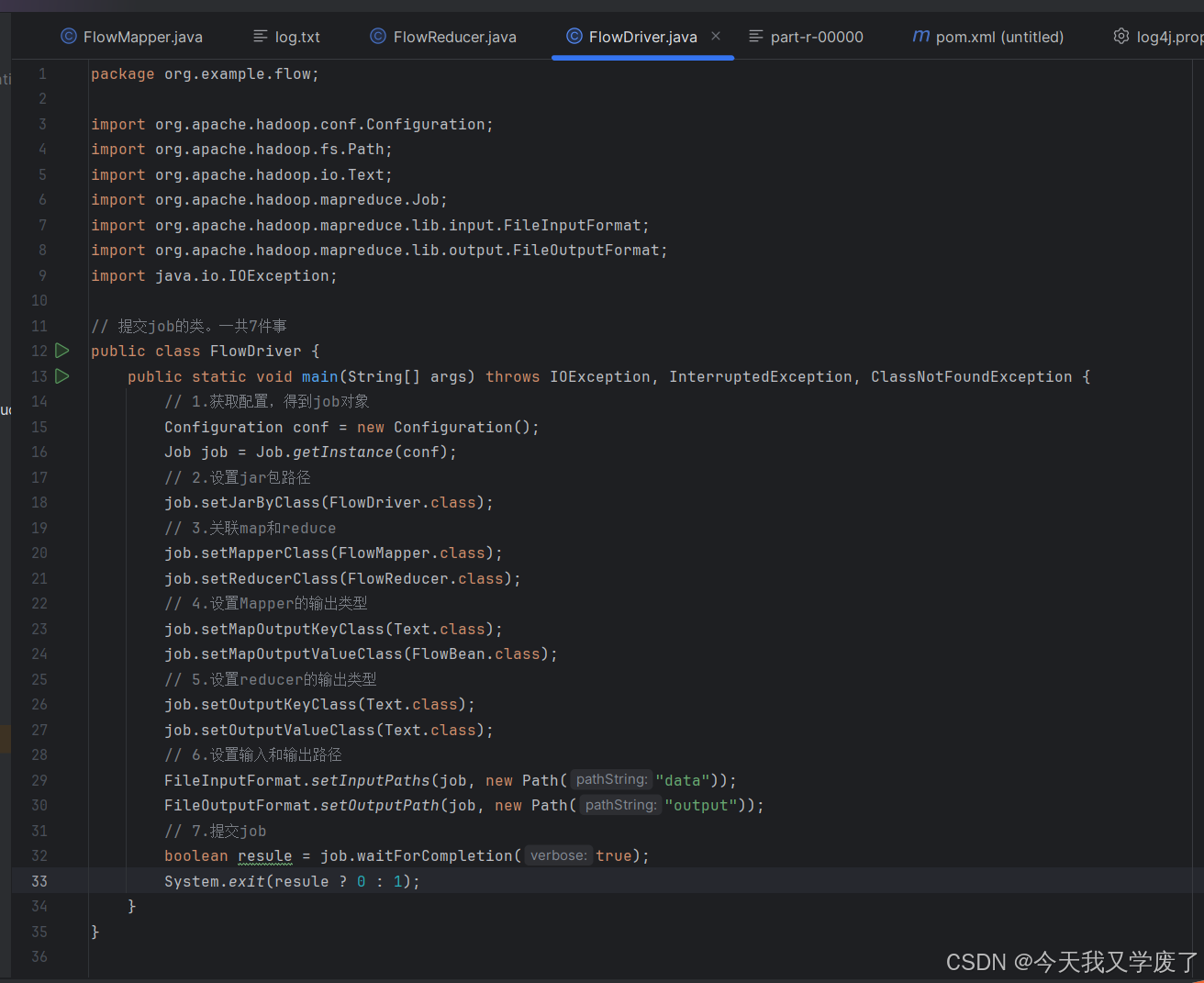
注:此为运行代码
FlowMapper中的代码内容为:
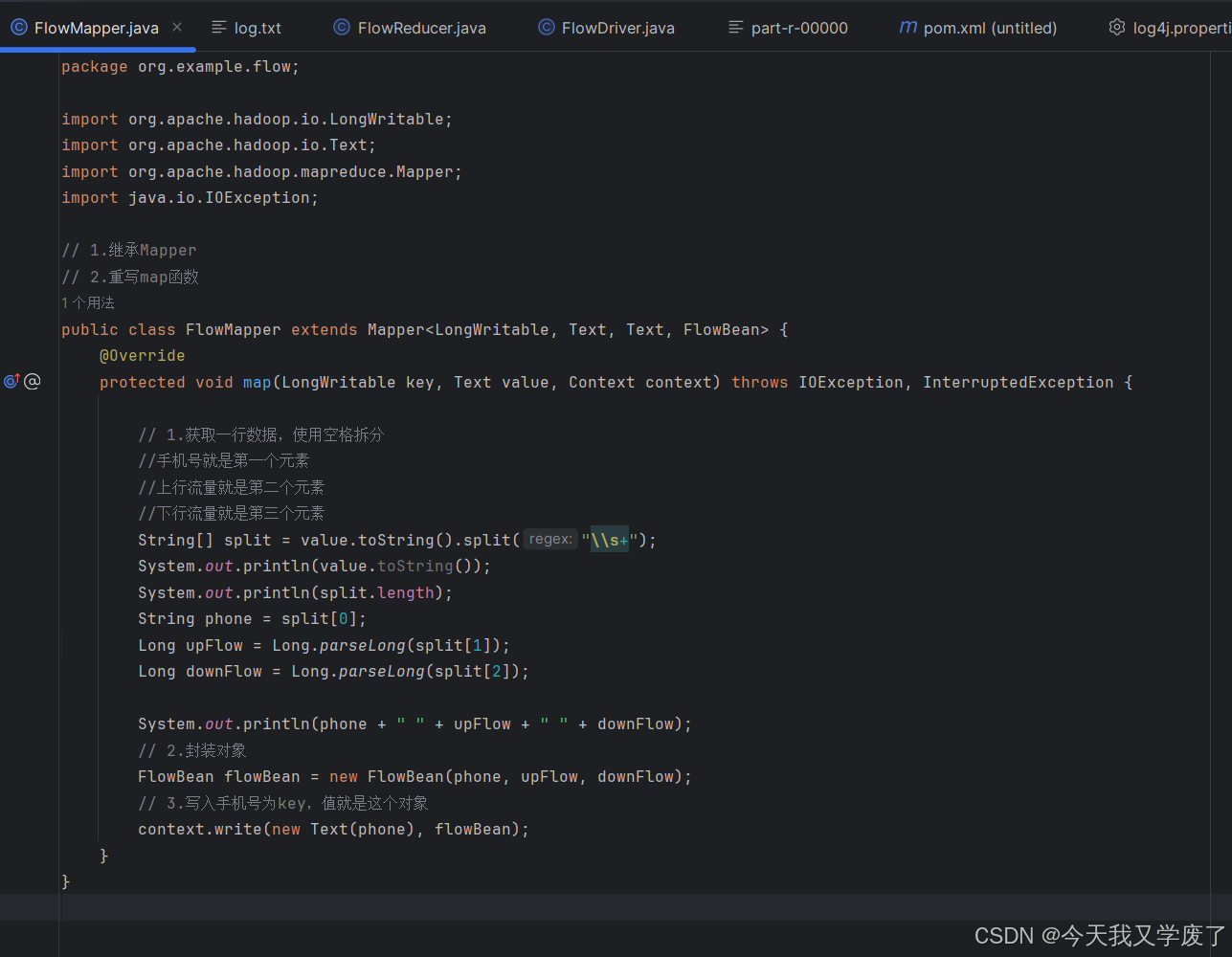
FlowReducer中的代码内容为: