1. 背景
大模型(LLM)和多模态大模型(MLLM)利用基于Transformer的架构获得了很迅速的发展。为满足对这些模型的训练和轻量级微调需求,目前已有一些开源框架,如LLaMA-Factory、Firefly、FastChat、Axolotl和LMFlow等。但这些框架在支持的模型、技术和功能上各有限制。例如,LLaMA-Factory支持超过100种文本LLM,但对多模态模型支持有限;FastChat主要关注模型推理和部署,训练支持相对有限。我们今天主要聊一下SWIFT。在之前,我们已经用SWIFT框架微调过部分大模型,包括Qwen系列和ChatGLM系列。事实上,swift支持超过300种LLM和50种MLLM,是提供最全面大模型微调支持的开源框架,尤其是在多模态模型支持方面也是有其独有的特点。此外,swift还整合了推理、评估和模型量化等后处理功能。
之所以想聊SWIFT框架,是因为实际使用下来,发现框架的完整度很高,并且支持的主流大模型很多,是一个不错且容易上手的微调框架,框架涉及的内容很多,我希望后续逐步分享,将swift框架能够拆开揉碎了来理解。
大模型通常包含数十亿参数,训练和微调成本高昂,成为AI普及的瓶颈。虽然有诸如Prefix Tuning、LoRA等轻量级微调方法出现,但各种方法的差异和复杂性仍然使开发者面临挑战。此外,为确保训练模型能有效部署,还需要考虑后处理过程,如推理、评估等。
为解决这些问题,ModelScope团队开发了SWIFT开源框架,简化大模型的轻量级训练,并集成后处理功能。
2. 训练架构
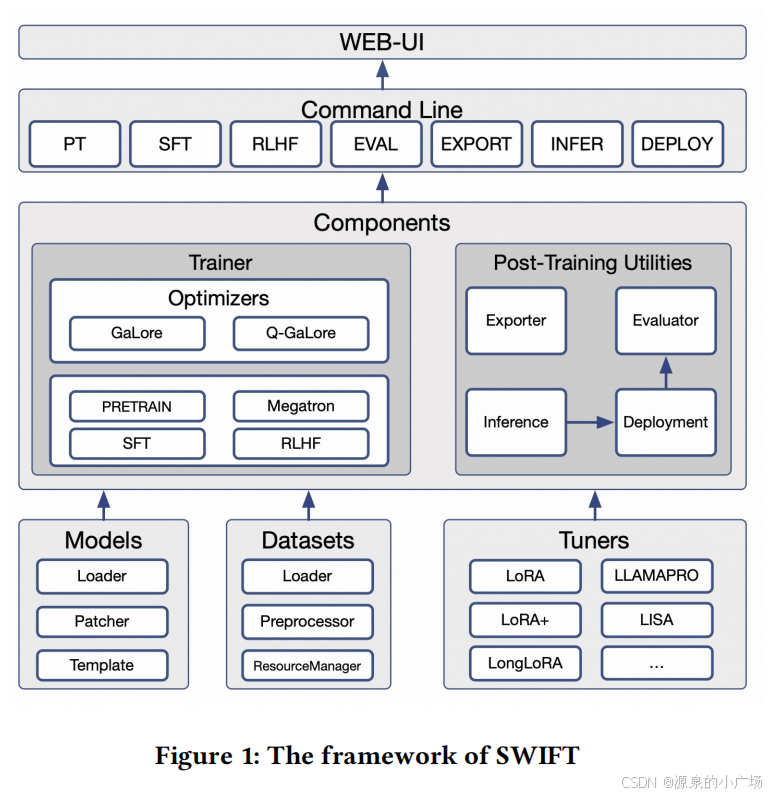
SWIFT框架设计遵循统一文本和多模态模型的理念,消除训练纯文本LLM和多模态MLLM之间的差距,通过建立数据处理、模型模板和模型训练的统一标准来实现。同时,框架集成了训练、推理、评估、量化和部署等全流程功能。
SWIFT支持多种轻量级微调技术:
- 减少可训练参数:如LISA,通过随机激活不同层,显著减少内存使用
- 模型量化:支持BNB、HQQ、EETQ、AWQ、GPTQ和AQLM六种量化方法
- 减少梯度值内存使用:如GaLore对梯度值进行SVD分解
- 冻结原始模型:支持LoRA和AdaLoRA等额外结构训练
- 分片或混合精度:支持DeepSpeed Zero1/2/3、FSDP等
SWIFT的微调器(Tuner)模块在PEFT库基础上进行扩展,支持LoRA、AdaLoRA、IA3、BOFT和Vera等技术,并进行调整以确保与MLLM训练兼容。此外,SWIFT还提供了其他微调器支持,包括SCEdit、ResTuning、LLaMA-Pro、LongLoRA和LISA等,这些微调器可以组合使用,类似PEFT的MixedPeftModel功能。
在模型功能模块中,SWIFT提供基本模型加载器,允许灵活自定义模型配置。考虑到训练中可能出现的兼容性问题,SWIFT使用补丁(patcher)模块在模型加载后解决这些问题,确保在单GPU、多GPU、全参数或LoRA训练等不同场景中的顺利操作。
在数据集模块中,支持三种数据源:ModelScope的MsDataset、Hugging Face的datasets模块以及用户自定义数据集(如本地CSV或JSONL文件)。数据集模块的预处理功能将不同数据集转换为标准格式。
模型模块的关键组件是模板(template),确保SWIFT支持的各种模型能正确生成input_ids、attention_masks、pixel_values和labels等关键字段。对于多模态定位任务,在模板中转换边界框(bbox)坐标。
在训练组件中,包括SFT/PT训练器和人类对齐训练器。前者直接继承自Transformers的训练器,用于预测和训练下一个token的交叉熵。后者继承自TRL的相应类,用于训练DPO、ORPO和KTO等各种RLHF算法。
2.1 推理与部署架构设计
SWIFT的推理和部署功能基于三种后端:PyTorch Native(PT)、vLLM和LMDeploy。这三个推理框架共享相同的参数。SWIFT使用FastAPI封装推理为服务,符合OpenAI通用接口定义。对于Agent功能的部署,SWIFT支持tools和tool等OpenAI标准字段,并支持ToolBench和ReACT等Agent数据格式的推理和部署。
2.2 评估架构设计
SWIFT依赖ModelScope社区的EvalScope框架构建评估能力,该框架通过集成OpenCompass(用于文本模型)和VLMEvalKit(用于多模态模型)构建评估功能。通过集成EvalScope,SWIFT目前支持100多个纯文本和多模态评估集,以及两种自定义评估数据集:
- 客观问题评估:类似CEval,开发者可以将数据集格式化为CEval风格的CSV文件
- QA主观问题评估:使用ROUGE和BLEU等标准指标
2.3 量化与导出架构设计
导出模块主要用于合并微调器、转换检查点格式和量化。目前支持以下操作:
- 合并微调器:包括LoRA、LongLoRA和LLaMA-Pro等
- 转换检查点:在Transformers格式和Megatron格式之间相互转换
- 量化:支持AWQ、GPTQ和BNB三种量化方法
- 导出到Ollama:包括模型的模板配置
3. 实验结果
3.1 轻量级微调基准
研究团队使用SWIFT复制和验证了各种轻量级微调算法对模型的影响。使用qwen-7b-chat作为基础模型,在单个A100-80G GPU上进行训练,比较内存使用和损失等指标。
| 微调器 | 训练/评估损失 | 可训练参数(M) | 内存(GiB) | 速度(样本/秒) |
|---|---|---|---|---|
| AdaLoRA | 0.57 / 1.07 | 26.84 (0.35%) | 32.55 | 0.92 |
| DoRA | 0.53 / 1.01 | 19.25 (0.25%) | 32.46 | 0.51 |
| GaLore | 0.55 / 1.00 | 7721.32 (100%) | 47.02 | 1.10 |
| Q-GaLore | 0.54 / 1.00 | 7721.32 (100%) | 41.53 | 1.45 |
| LLaMAPro | 0.53 / 1.00 | 809.58 (9.49%) | 38.11 | 1.53 |
| LoRA+ | 0.53 / 0.98 | 17.89 (0.23%) | 32.35 | 0.95 |
| LoRA | 0.53 / 1.01 | 17.89 (0.23%) | 32.35 | 0.95 |
| RsLoRA | 0.53 / 0.99 | 17.89 (0.23%) | 32.35 | 0.94 |
| LISA | 0.62 / 1.06 | - | 31.11 | 2.66 |
| Full | 0.54 / 0.95 | 7721.32 (100%) | 73.53 | 1.43 |
实验结果显示,LISA实现了最低的内存消耗和最快的速度。在额外结构微调器中,LoRA+记录了最低的评估损失。在梯度减少方法中,Q-GaLore表现出最低的内存消耗。
3.2 Agent训练
Agent训练是模型SFT中的重要类别。使用ToolBench数据集和AgentFlan数据集的混合数据集进行了一系列实验,采用LLaMA3-8b-instruct模型和Qwen2-7b-instruct模型进行训练,并比较了训练前后的结果。还引入了loss-scale技术,增强某些重要token的权重。基于LLaMA3-8b-instruct模型的实验结果显示,引入loss-scale显著改善了所有评估指标。
| 模型 | Plan.EM | Act.EM | 幻觉率 | Avg.F1 | R-L |
|---|---|---|---|---|---|
| 原始 | 74.22 | 36.17 | 15.68 | 20.0 | 12.14 |
| 无loss-scale | 84.29 | 55.71 | 4.85 | 49.40 | 25.06 |
| 有loss-scale | 85.1 | 58.15 | 1.57 | 52.10 | 26.02 |
对于Qwen2-7b-instruct的实验结果,与官方Qwen2模型相比,训练后的平均指标提高了8.25%,模型幻觉减少到个位数。
| 模型 | Plan.EM | Act.EM | 幻觉率 | Avg.F1 | R-L |
|---|---|---|---|---|---|
| 原始 | 74.11 | 54.74 | 4.16 | 46.53 | 8.51 |
| GPT4 | 80.28 | 55.52 | 5.98 | 48.74 | 28.69 |
| LoRA(本文) | 77.05 | 56.97 | 0.9 | 49.53 | 19.81 |
| Full(本文) | 83.37 | 60.01 | 2.58 | 54.41 | 26.34 |
对于LLaMA3-8b-instruct,基于LoRA训练,平均指标提高了17%。这表明开源模型和数据集对实际垂直场景中的Agent训练具有意义。
3.3 与其他框架的比较
| 功能/框架 | LLaMA-Factory | FireFly | FastChat | Axolotl | LMFlow | SWIFT(本文) |
|---|---|---|---|---|---|---|
| 支持LLM预训练 | ✓ | ✓ | ✓ | ✓ | ||
| 支持Megatron预训练 | ✓ | |||||
| 支持LLM-SFT | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| 支持LLM-DPO | ✓ | ✓ | ✓ | |||
| 支持多模态预训练 | ✓ | |||||
| 支持多模态SFT | 3个模型 | 50+模型 | ||||
| 支持多模态RLHF | 3个模型 | 50+模型 | ||||
| 支持vLLM | ✓ | ✓ | ✓ | |||
| 支持LMDeploy | ✓ | |||||
| LLM评估 | 3个数据集 | ✓ | 48个数据集 | |||
| 多模态评估 | 95个数据集 | |||||
| WEB-UI | ✓ | ✓ | ✓ |
4. 一些改进项
尽管SWIFT已经具备丰富功能,但有些特性依然待实现,包括:
- 更好地支持Megatron大规模并行训练,目前SWIFT对Megatron模型的支持未完全覆盖主流LLM和MLLM
- 更深入的多模态研究,如提供高质量数据集防止知识遗忘,或使用ModelScope自研数据集训练新的多模态模型
5. 部分脚本示例
# 多GPU SFT命令
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 \
NPROC_PER_NODE=8 \
swift sft \
--model_type qwen1half-32b-chat \
--dataset blossom-math-zh \
--deepspeed default-zero3
# 单GPU RLHF命令
swift rlhf \
--model_type llama3-8b-instruct \
--rlhf_type dpo \
--dataset hh-rlhf
# 推理多模态模型
swift infer \
--model_type internvl2-8b \
--infer_backend lmdeploy
# 使用vLLM部署检查点
swift deploy \
--ckpt_dir /mnt/my-custom/ckpt-1100 \
--infer_backend vllm
# 评估NLP模型
swift eval \
--model_type llama3-8b-instruct \
--eval_dataset ceval gsm8k
# 合并LoRA
swift export --ckpt_dir /mnt/my-custom/ckpt-1100 --merge_lora true
6. 参考材料
【1】SWIFT:A Scalable lightWeight Infrastructure for Fine-Tuning