首先根据官网描述:
 常见生成全局ID的方法:
常见生成全局ID的方法:
UUID:

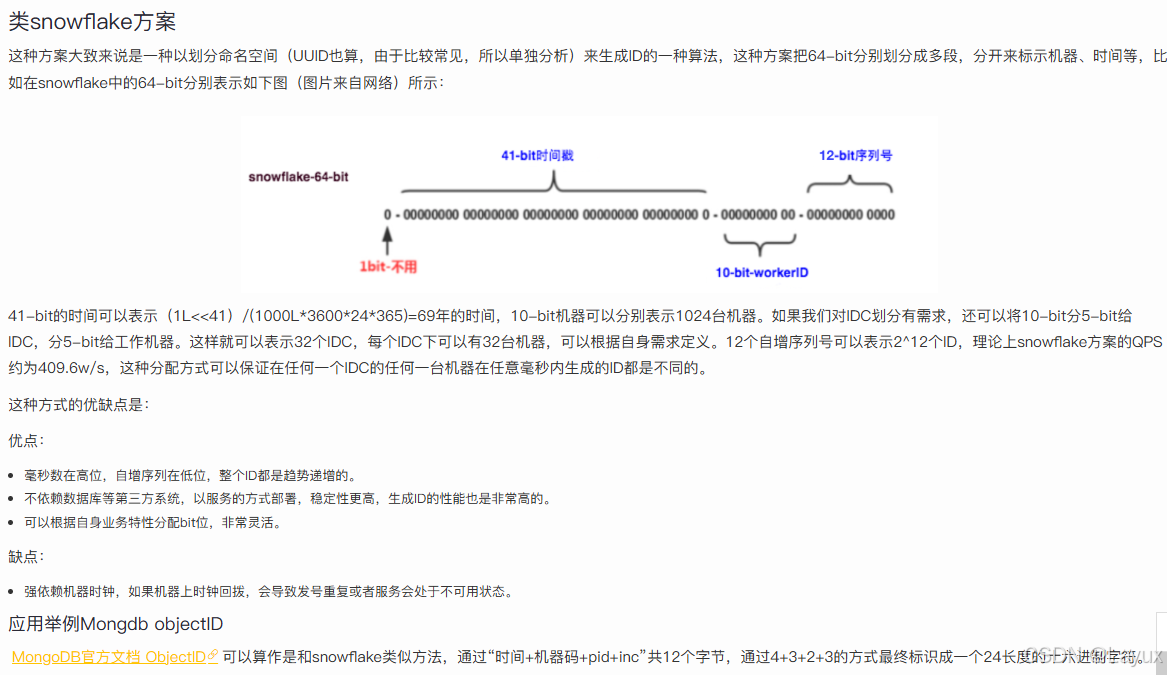
类snowflake方案:
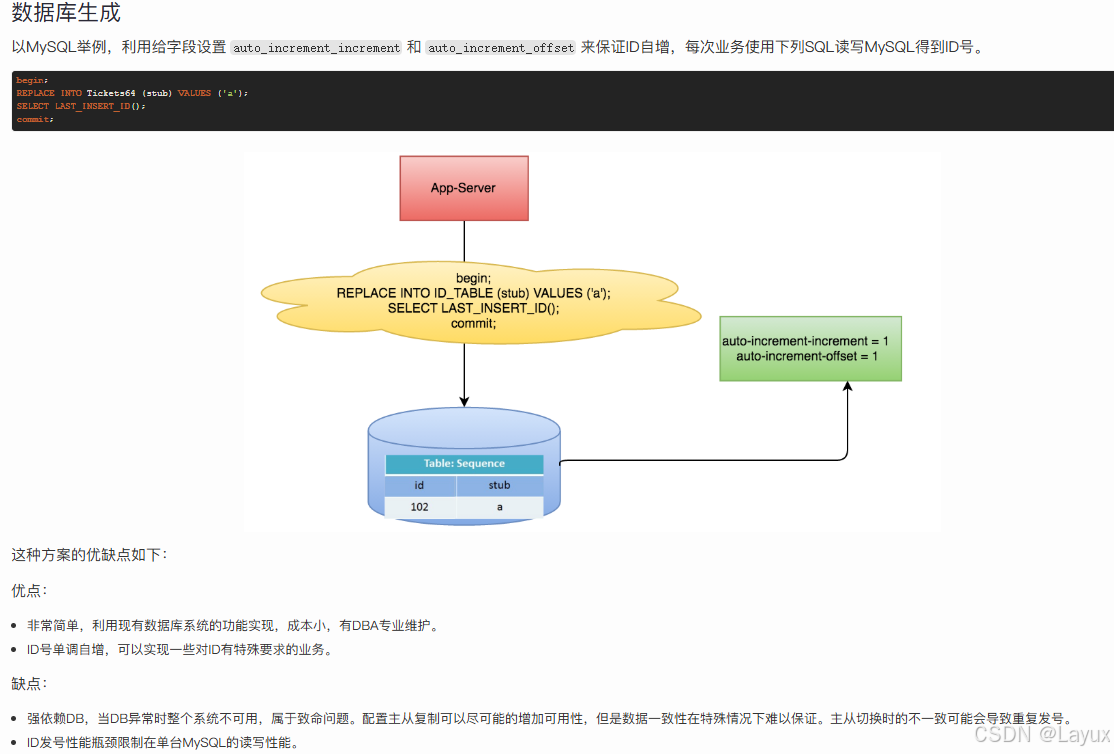
- 数据库生成:
数据库生成:
上述每种方案都不符合我们的要求
所以我们这里使用Leaf来实现分布式ID,它的描述是“世界上没有两片完全相同的树叶”
它分别在上述第二种和第三种方案上做了优化
使用美团Leaf有两种实现方案,号段模式:Leaf-segment和雪花算法模式:Leaf-snowflake
接下来我们就来说明一下怎么样用Leaf来得到分布式ID:
号段模式:Leaf-segment:
在使用数据库的方案上做了如下改变:
原方案每次获取ID都得读写一次数据库,造成数据库压力大。
预分配 ID 段
号段模式(Segment Mode)通过预先从数据库或中央服务中申请一段连续的 ID(也称为号段)来工作。每个号段通常包含一批连续的数字,例如从 100000 到 100999。
本地缓存与批量分配
一旦一个号段被获取,该服务会将这段 ID 缓存在本地内存中。之后,每当有请求生成 ID 时,就直接从这段本地缓存中分配,避免每次都去访问数据库,从而大大提高了生成速度和并发性能。
后台异步预取
当当前号段即将耗尽时,系统会在后台异步申请下一个号段。这种设计确保了 ID 的生成是无阻塞的,能平滑地过渡到新的号段,减少了因等待新号段而引起的延迟。
原子性与一致性
号段的获取通常依赖于数据库中的一张记录表,该表记录了每个业务(或 Key)的当前最大 ID。系统会采用事务或其他原子操作来更新这个值,以确保每次分配的号段都是唯一且连续的。这样可以保证不同节点之间不会产生重复的 ID。
使用号段模式:
1.配置数据库表
首先,需要在数据库中创建一张专门用于存储 ID 生成状态的表。表中至少包括业务标识(Key)和当前的最大 ID(或者下一个可用的 ID)字段。此表负责记录每个业务已经分配到哪里。
在这里我们创建数据库:
biz_tag: 用来区分业务,例如生成用户 ID、生成笔记 ID通过此标识隔离开来;max_id: 表示该 biz_tag 目前所被分配的 ID 号段的最大值;step: 表示每次分配的号段长度。
CREATE TABLE `leaf_alloc` (
`biz_tag` varchar(128) NOT NULL DEFAULT '',
`max_id` bigint(20) NOT NULL DEFAULT '1',
`step` int(11) NOT NULL,
`description` varchar(256) DEFAULT NULL,
`update_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
PRIMARY KEY (`biz_tag`)
) ENGINE=InnoDB;
insert into leaf_alloc(biz_tag, max_id, step, description) values('leaf-segment-test', 1, 2000, 'Test leaf Segment Mode Get Id')
2.服务端配置
在部署 Leaf 服务时,需要配置好数据库连接信息、每个业务的号段大小(即每次申请的 ID 数量)、申请间隔、以及其他容错相关参数。
<号段大小:通常根据业务的请求量来调优,较大的号段减少数据库访问频率,但可能会造成较多的 ID 空洞(ID 丢失);较小的号段则反之。
leaf.name=com.sankuai.leaf.opensource.test
leaf.segment.enable=true
leaf.jdbc.url=jdbc:mysql://127.0.0.1:3306/leaf?useUnicode=true&characterEncoding=utf-8&autoReconnect=true&useSSL=false&serverTimezone=Asia/Shanghai
leaf.jdbc.username=root
leaf.jdbc.password=123456
leaf.snowflake.enable=false
#leaf.snowflake.zk.address=
#leaf.snowflake.port=
3.集成客户端 SDK
Leaf 通常会提供客户端库供业务系统调用。在你的代码中,只需调用相应的接口来获取 ID。客户端会从本地缓存中返回一个可用的 ID,若本地缓存不足则自动触发后台预取逻辑。
引入依赖:
<dependency>
<groupId>com.tencent.devops.leaf</groupId>
<artifactId>leaf-boot-starter</artifactId>
<version>1.0.2-RELEASE</version>
</dependency>接下来就可以在业务类Service中注入号段模式的SegmentService来调用SegmentService中的getId方法来获得一个同步时ID,而传入的key就是数据库中的biz_tag,也就是不同的业务可以对分布式ID独立的进行控制的
号段模式的缺点,可能会导致一些号段会被浪费掉
雪花算法模式:Leaf-snowflake:
雪花算法在 Leaf 中通过将时间戳、机器标识和序列号按位拼接生成 64 位的唯一 ID,保证了高并发和分布式环境下的唯一性和有序性。
它是依赖与Zookeeper的,我们可以先用docker将Zookeeper的环境搭建好,这里就不多赘述了。
Apache ZooKeeper 是一个开源的分布式协调服务,用于大型分布式系统的开发和管理。它提供了一种简单而统一的方法来解决分布式应用中常见的协调问题,如命名服务、配置管理、集群管理、组服务、分布式锁、队列管理等。ZooKeeper 通过提供一种类似文件系统的结构来存储数据,并允许客户端通过简单的 API 进行读写操作,从而简化了分布式系统的复杂度。
Zookeeper 的核心特性如下:
一致性:对于任何更新,所有客户端都将看到相同的数据视图。这是通过 ZooKeeper 的原子性保证的,意味着所有更新要么完全成功,要么完全失败。
可靠性:一旦数据被提交,它将被持久化存储,即使在某些服务器出现故障的情况下,数据也不会丢失。
实时性:ZooKeeper 支持事件通知机制,允许客户端实时接收到数据变化的通知。
高可用性:ZooKeeper 通常以集群形式部署,可以容忍部分节点的故障,只要集群中超过半数的节点是可用的,ZooKeeper 就能继续提供服务
使用雪花算法模式:
1.在配置类中开启雪花算法模式:
# 是否开启 snowflake 模式
leaf.snowflake.enable=true
# snowflake 模式下的 zk 地址
leaf.snowflake.zk.address=127.0.0.1:2181
# snowflake 模式下的服务注册端口
leaf.snowflake.port=2222
2.添加Zookeeper的依赖配置:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0,1</version>
</dependency>3.注入SnowflakeService,调用方法和SegmentService一样
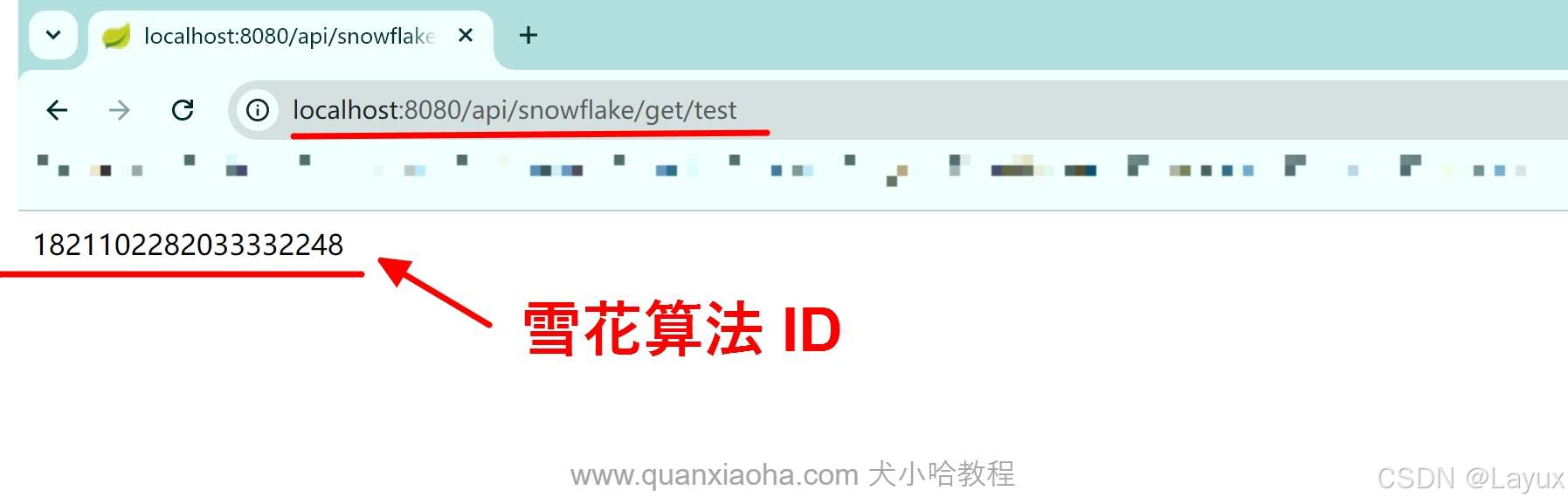
这就是生成的雪花算法的ID