前言 :
在分布式数据库架构中,分库分表、高可用性(HA)和查询优化是核心需求。本文将深入解析三款主流工具:MyCat(分布式数据库中间件)、MHA(MySQL高可用方案)、ProxySQL(高性能数据库代理),从设计原理、核心功能、适用场景等维度对比分析,并结合实例示范帮助开发者理解落地细节。
数据库的发展历史可以追溯到20世纪60年代,经历了多个重要的阶段和技术创新。以下是数据库发展的主要历程:
数据库发展简史:
1. 早期数据库(20世纪60年代)
层次数据库(Hierarchical Databases)
- 1960年代,IBM开发了层次数据库系统,如 IBM Information Management System (IMS)。这种数据库使用树状结构存储数据,主要用于大型机系统,适合处理具有固定层次关系的数据(如企业资源规划系统)。
- 特点:数据结构固定,查询效率高,但灵活性差。
网状数据库(Network Databases)
- 1969年,CODASYL(Conference on Data Systems Languages)发布了网状数据库标准,代表产品是 CODASYL DBTG。这种数据库使用图结构来表示数据之间的关系。
- 特点:比层次数据库更灵活,但仍然需要复杂的导航操作。
2. 关系型数据库(1970年代)
- 理论基础:1970年,IBM研究员 E. F. Codd 提出了关系型数据库模型,奠定了现代数据库的基础。他提出了关系代数和关系模型,强调数据的逻辑结构和独立性。
- 实现:1974年,IBM开发了 System R,这是第一个实现关系型数据库的原型。
- 商业化:
- 1979年,Oracle(最初名为 Oracle V1)成为第一个商业化的关系型数据库系统。
- 1980年代,其他关系型数据库如 SQL Server 和 DB2 也相继推出。
3. MySQL的出现(1995年)
- 开发背景:MySQL由 Michael Widenius 和 David Axmark 开发,最初是一个轻量级的数据库,主要用于 Web 应用。
- 特点:开源、高性能、易用性,迅速在互联网行业流行。
- 应用:广泛用于 Web 开发(如 LAMP 架构:Linux、Apache、MySQL、PHP)。
4. NoSQL数据库(2000年代末)
- 背景:随着互联网应用的爆炸式增长,传统关系型数据库在处理大规模数据和高并发时遇到了瓶颈。
- 特点:
- 非关系型:不使用表结构,而是采用键值对、文档、列族或图结构。
- 分布式:通过分布式架构实现高扩展性和高可用性。
- CAP定理:在一致性(Consistency)、可用性(Availability)和分区容错性(Partition Tolerance)之间进行权衡。
- 代表产品:
- 键值数据库:Redis、Memcached(适用于缓存和简单数据存储)。
- 文档数据库:MongoDB(适用于灵活的 JSON 文档存储)。
- 列族数据库:Cassandra、HBase(适用于大规模时间序列数据)。
- 图数据库:Neo4j(适用于复杂关系数据,如社交网络)。
5. NewSQL数据库(2010年代)
- 背景:NewSQL 数据库结合了关系型数据库的事务处理能力和 NoSQL 数据库的扩展性。
- 特点:
- 支持 ACID 事务(原子性、一致性、隔离性、持久性)。
- 提供水平扩展能力,适合大规模分布式系统。
- 代表产品:
- Google Spanner:分布式关系型数据库,支持全球分布式事务。
- CockroachDB:开源的分布式 SQL 数据库,受 Spanner 启发。
- Amazon Aurora:AWS 提供的高性能、高可用的云数据库服务。
6. 现代数据库趋势(2020年代)
- 云原生数据库:如 Amazon Aurora、Google Cloud Spanner、阿里云 PolarDB,提供弹性扩展和自动管理。
- 多模数据库:支持多种数据模型(如关系型、文档、键值、图)的统一数据库,如 ArangoDB。
- AI 驱动的数据库:结合机器学习优化查询性能和资源管理,如 Google 的 SQLFlow 和 TensorFlow 集成。
总结
数据库技术从早期的层次和网状数据库,到关系型数据库的普及,再到 NoSQL 和 NewSQL 的兴起,经历了多次重大变革。每种数据库类型都有其特定的应用场景和优势,现代数据库的发展正朝着云原生、多模和智能化方向迈进。
数据库中间件MyCat、MHA、ProxySQL:
一、MyCat:分布式数据库的“路由器”
1. 定位与核心价值
- 定位:基于 Java 开发的开源数据库中间件,介于应用层和数据库层之间,实现分库分表、读写分离、分布式事务等功能,屏蔽底层数据库细节。
- 核心价值:将单机数据库扩展为分布式集群,解决数据量/流量爆炸时的扩展性问题,适用于互联网高并发、海量数据场景(如电商订单、用户中心)。
2. 核心原理与架构
架构层级思维导图:
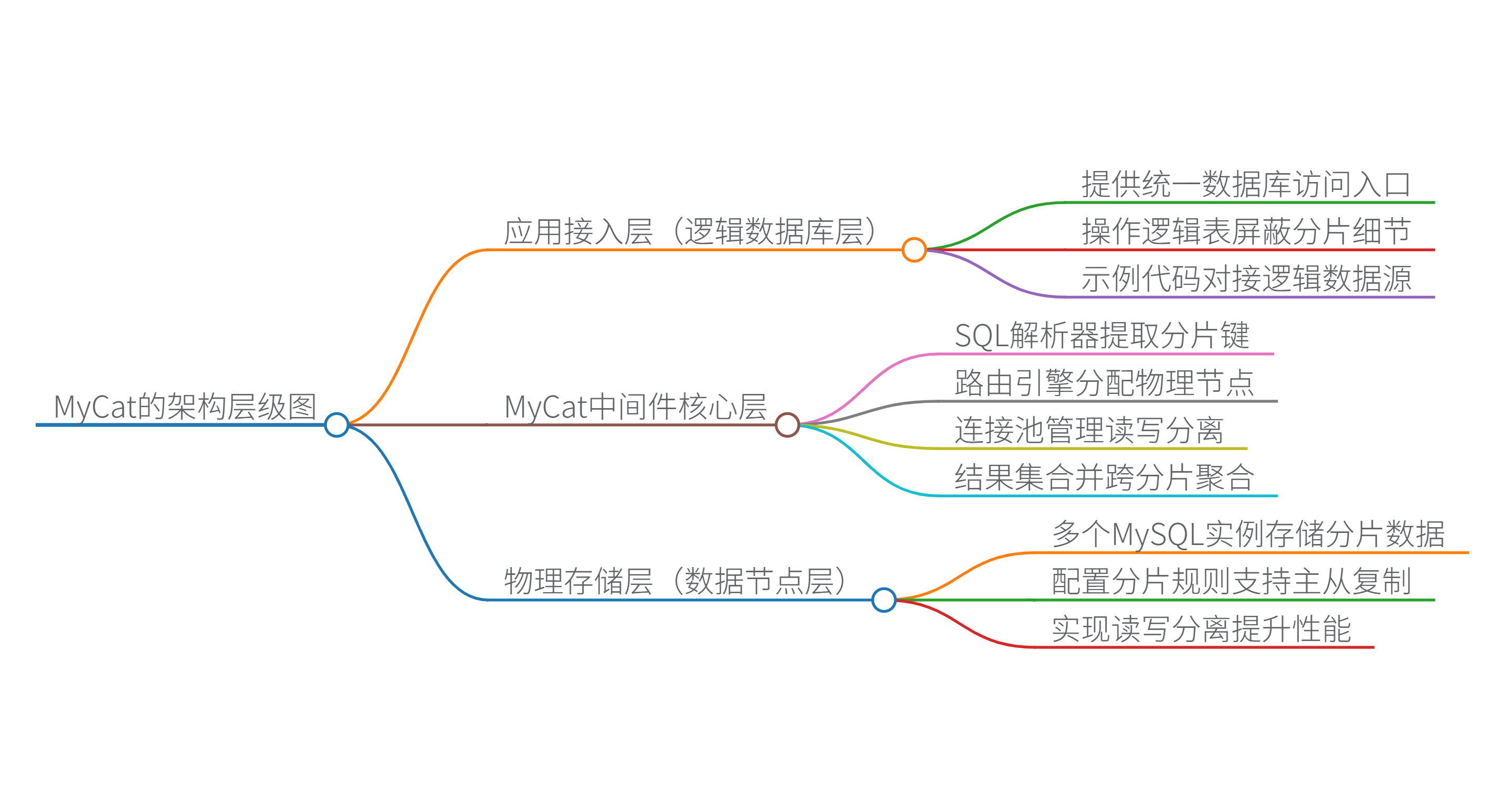
(注:图示为逻辑架构,实际需结合具体部署)
核心模块:
- SQL 解析器:将 SQL 语句拆解为 AST(抽象语法树),识别表名、分片键、操作类型等。
- 路由规则引擎:根据分片策略(如哈希分片、范围分片、枚举分片)决定 SQL 路由到哪个分片节点。
- 连接池:管理与后端数据库的连接,支持连接复用和负载均衡。
- 结果集合并:聚合多个分片的查询结果(如分页、排序、聚合函数),返回给应用层。
分片策略:
- 垂直分片:按业务模块拆分(如用户库、订单库)。
- 水平分片:按数据特征拆分(如按用户 ID 哈希分到多个库表)。
3. 核心功能
- 分库分表:支持全局表(各分片同步数据,如字典表)、ER 分片(关联表按主外键分片)。
- 读写分离:根据 SQL 类型(SELECT/INSERT/UPDATE/DELETE)路由到主库或从库。
- 分布式事务:支持基于 XA 协议的强一致事务,或柔性事务(最终一致性)。
- 兼容性:模拟 MySQL 协议,应用无需修改代码即可接入,支持跨数据库(MySQL、Oracle、PostgreSQL 等)。
4. 优缺点与适用场景
- 优点:
- 开箱即用,支持复杂分片逻辑,适合业务快速迭代。
- 兼容 MySQL 协议,对应用透明。
- 缺点:
- 引入中间件层,增加系统复杂度和网络开销。
- 分片键设计一旦确定难以修改,需提前规划数据模型。
- 适用场景:
- 数据量超过单库瓶颈(如单表超千万行)。
- 需要读写分离、分库分表的分布式系统(如电商、社交平台)。
5. 实例示范:用户表水平分片配置
假设业务需求:用户表(user_info)按 user_id 哈希分片到 2 个数据库(db_0、db_1),每个库包含 2 个表(user_info_0、user_info_1)。
步骤 1:配置分片规则(rule.xml)
<rule>
<name>hash_user_id</name>
<ruleType>1</ruleType>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
<function>
<name>mod-long</name>
<class>io.mycat.route.function.PartitionByMod</class>
<property>count>2</property> <!-- 分片数量为 2,user_id % 2 决定数据节点 -->
</function>
步骤 2:定义逻辑库与表(schema.xml)
<schema name="test_schema" checkSQLschema="false">
<table name="user_info" dataNode="dn0,dn1" rule="hash_user_id" />
</schema>
<dataNode name="dn0" dataHost="host0" database="db_0" />
<dataNode name="dn1" dataHost="host1" database="db_1" />
<dataHost name="host0" maxCon="1000" minCon="10" balance="0">
<heartbeat>select user()</heartbeat>
<writeHost host="master0" url="192.168.1.10:3306" user="root" password="123456" />
</dataHost>
<dataHost name="host1" maxCon="1000" minCon="10" balance="0">
<heartbeat>select user()</heartbeat>
<writeHost host="master1" url="192.168.1.11:3306" user="root" password="123456" />
</dataHost>
步骤 3:启动 MyCat 并测试路由
- 连接 MyCat(默认端口 8066):
mysql -u mycat -p123456 -h 127.0.0.1 -P 8066 - 插入数据验证分片:
INSERT INTO user_info (user_id, username) VALUES (1, 'user1'); -- user_id=1 % 2 = 1,路由到 dn1(db_1) INSERT INTO user_info (user_id, username) VALUES (2, 'user2'); -- user_id=2 % 2 = 0,路由到 dn0(db_0) - 登录物理数据库查看表数据,确认分片规则生效。
二、MHA:MySQL 高可用性的“守护者”
- 架构层级思维导图:

1. 定位与核心价值
- 定位:基于 Perl 开发的 MySQL 高可用性解决方案,专注于主从架构下的故障自动切换,确保主库宕机时快速提升从库为新主库,减少服务中断时间。
- 核心价值:解决传统主从架构中故障切换依赖人工的问题,实现自动化、可靠的 HA 机制,适用于对可用性要求极高的业务(如交易、支付系统)。
2. 核心原理与架构
- 架构组件:
- Manager 节点:监控主从集群状态,执行故障检测和切换逻辑(通常部署在独立服务器)。
- Node 节点:每个 MySQL 实例(主/从库)上运行的脚本,提供状态汇报和切换执行功能。
- 依赖条件:主从复制(需开启 GTID 或二进制日志)、SSH 互信(Manager 需远程操作 Node 节点)。
- 故障切换流程:
- Manager 检测到主库宕机,通过
ping命令和 MySQL 协议双重验证。 - 筛选出拥有最新数据的从库(基于 relay log 应用进度)。
- 在新主库上应用所有未同步的 relay log,确保数据一致性。
- 更新其他从库指向新主库,通知应用层切换连接地址(需配合 DNS 或配置中心)。
- Manager 检测到主库宕机,通过
3. 核心功能
- 快速故障切换:秒级检测(可配置检测间隔),分钟级完成切换(取决于日志应用时间)。
- 数据一致性保障:切换前补全所有 relay log,避免主从数据不一致(需关闭
sync_binlog=0等风险配置)。 - 多节点支持:支持一主多从架构,可配置候选主库优先级。
4. 优缺点与适用场景
- 优点:
- 专注 MySQL 高可用,轻量高效,资源消耗低。
- 社区成熟,支持 GTID 模式(简化复制管理)。
- 缺点:
- 仅支持主从架构,不解决分片问题。
- 切换过程中可能出现短暂服务中断(需配合连接池重试机制)。
- 适用场景:
- 以 MySQL 为主库的主从集群,需高可用性(如金融、实时交易系统)。
- 业务规模中等,暂不需要分库分表,但需保障主库故障时的自动容灾。
5. 实例示范:一主两从集群故障切换
假设集群节点:
- 主库:192.168.1.10(port 3306)
- 从库1:192.168.1.11(port 3306,候选主库)
- 从库2:192.168.1.12(port 3306)
- MHA Manager:192.168.1.20(需安装 Perl 及 MHA 工具包)
步骤 1:配置主从复制(所有节点)
- 主库开启 GTID(
my.cnf):[mysqld] server-id=1 gtid_mode=ON enforce_gtid_consistency=1 - 从库配置复制(以从库1为例):
CHANGE MASTER TO MASTER_HOST='192.168.1.10', MASTER_USER='repl', MASTER_PASSWORD='repl', MASTER_AUTO_POSITION=1; START SLAVE;
步骤 2:配置 MHA 配置文件(mha.cnf)
[server default]
manager_workdir=/var/log/mha
manager_log=/var/log/mha/manager.log
master_binlog_dir=/var/lib/mysql
master_ip_failover_script=/usr/local/bin/master_ip_failover # 自定义切换后更新 IP 脚本
ssh_user=root
repl_user=repl
repl_password=repl
[server1]
hostname=192.168.1.10
port=3306
[server2]
hostname=192.168.1.11
port=3306
candidate_master=1 # 标记为优先候选主库
[server3]
hostname=192.168.1.12
port=3306
步骤 3:启动 MHA 并验证
- 检查 SSH 互信与复制状态:
masterha_check_ssh --conf=mha.cnf # 确保 Manager 可无密登录所有节点 masterha_check_repl --conf=mha.cnf # 验证主从复制正常 - 启动 Manager 进程:
nohup masterha_manager --conf=mha.cnf & - 模拟主库故障(关闭主库服务):
ssh 192.168.1.10 'systemctl stop mysql' - 观察切换日志,确认从库1提升为主库:
-- 连接新主库(192.168.1.11),查看 GTID 状态 SHOW MASTER STATUS; # 确保 Log_slave_updates=ON,且无 Slave 相关状态
三、ProxySQL:高性能数据库的“流量调节器”
- 架构层级思维导图:
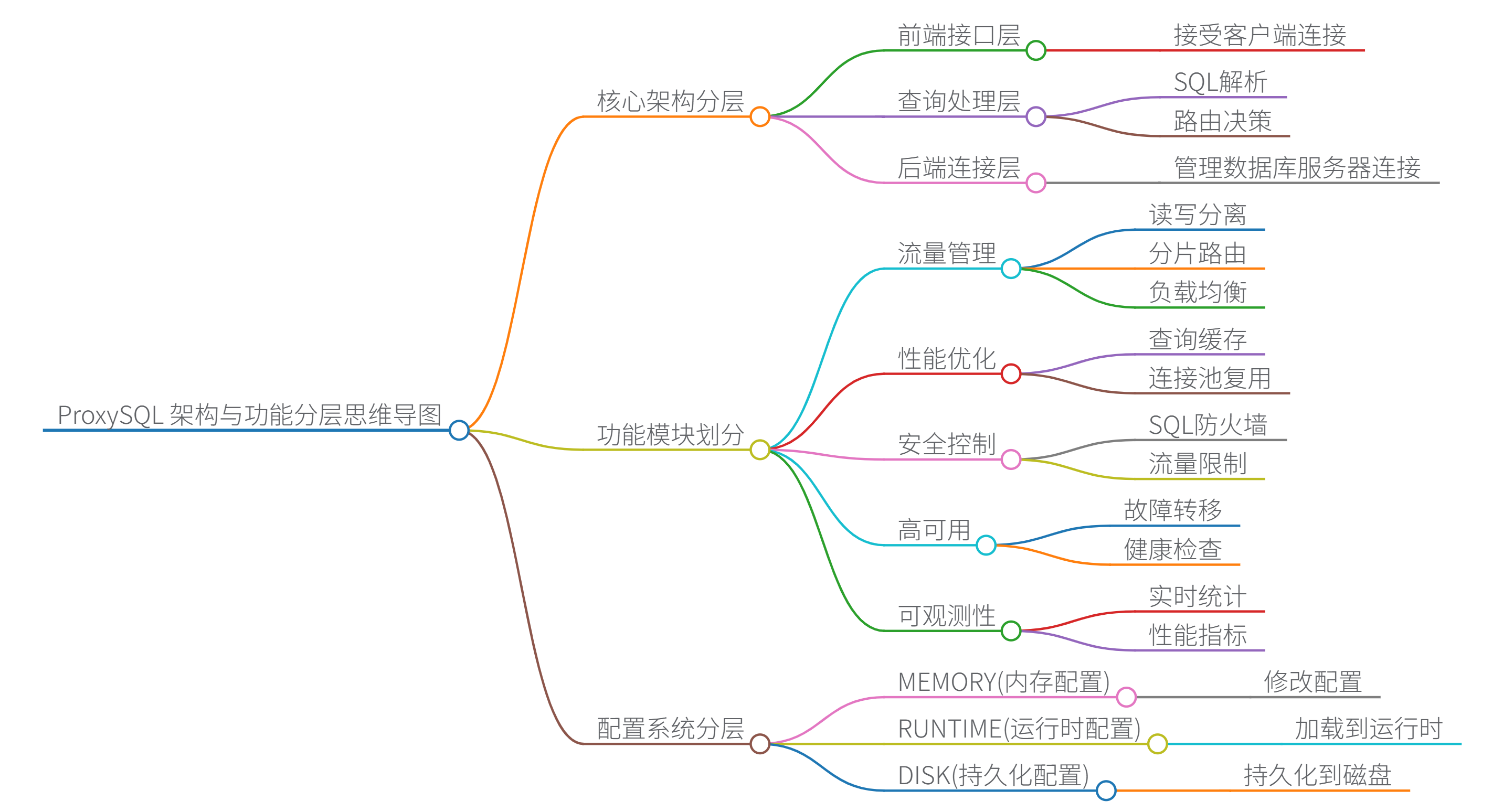
1. 定位与核心价值
- 定位:基于 C++ 开发的高性能数据库代理,支持连接池管理、查询优化、流量控制,可部署在应用与数据库之间,降低连接开销和提升查询效率。
- 核心价值:解决高并发场景下连接数爆炸、慢查询拖垮数据库等问题,适用于需要精细化流量管理的场景(如秒杀、高并发 API)。
2. 核心原理与架构
- 架构特性:
- 分层架构:
- 管理节点(Admin Interface):通过 MySQL 协议连接,动态配置路由规则、连接池参数等(数据存储在内存和磁盘)。
- 运行节点(Runtime):处理实际流量,基于配置进行查询路由和连接管理。
- 连接池机制:
- 为每个后端数据库维护独立连接池,支持最大/最小连接数、连接超时等参数。
- 连接复用:避免频繁创建/销毁连接,减少数据库压力(尤其适合短连接场景)。
- 分层架构:
- 查询优化能力:
- 查询缓存:缓存 SELECT 语句结果(需显式开启,支持 TTL 和大小限制)。
- 语法分析:识别读写语句,实现精准的读写分离(如根据表名、SQL 模式路由)。
- 负载均衡:支持轮询、权重、延迟感知等策略分配读请求到从库。
3. 核心功能
- 连接池管理:降低连接数峰值,避免数据库被连接打满(如限制每个应用的最大连接数)。
- 动态路由:通过正则表达式或 SQL 模式匹配,实现细粒度路由(如将
SELECT * FROM users固定路由到从库)。 - 监控与统计:记录查询耗时、连接池状态、慢查询日志,支持与 Prometheus、Grafana 集成。
- 事务支持:完整传递事务语句到后端数据库,确保事务原子性。
4. 优缺点与适用场景
- 优点:
- 高性能(内存级处理,单节点可支持数万 QPS),资源占用低。
- 灵活的动态配置,无需重启即可修改路由规则。
- 缺点:
- 不支持分库分表,仅作为代理层优化(需与 MyCat 等中间件配合使用)。
- 查询缓存功能较弱,复杂查询缓存命中率低。
- 适用场景:
- 高并发读场景(如抢购、实时报表),需降低数据库连接压力。
- 读写分离架构中,需精细化流量控制和连接管理。
5. 实例示范:读写分离与连接池配置
假设后端数据库:
- 主库(写):192.168.1.10:3306
- 从库1(读):192.168.1.11:3306
- 从库2(读):192.168.1.12:3306
步骤 1:启动 ProxySQL 并连接 Admin 接口
# 启动 ProxySQL(默认 Admin 端口 6032,数据端口 6033)
proxysql -d
# 连接 Admin 接口(默认用户名/密码:admin/admin)
mysql -u admin -padmin -h 127.0.0.1 -P 6032
步骤 2:配置后端节点(分写节点组和读节点组)
-- 写节点组(hostgroup_id=1)
INSERT INTO mysql_servers (hostgroup_id, hostname, port, weight) VALUES (1, '192.168.1.10', 3306, 100);
-- 读节点组(hostgroup_id=2)
INSERT INTO mysql_servers (hostgroup_id, hostname, port, weight) VALUES (2, '192.168.1.11', 3306, 50), (2, '192.168.1.12', 3306, 50);
步骤 3:配置路由规则(按 SQL 类型路由)
-- SELECT 语句路由到读节点组(hostgroup=2)
INSERT INTO mysql_query_rules (rule_id, active, match_digest, destination_hostgroup)
VALUES (1, 1, '^SELECT .*', 2);
-- 写语句路由到写节点组(hostgroup=1)
INSERT INTO mysql_query_rules (rule_id, active, match_digest, destination_hostgroup)
VALUES (2, 1, '^(INSERT|UPDATE|DELETE) .*', 1);
-- 加载规则到运行时并持久化
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;
步骤 4:配置连接池参数(限制后端节点连接数)
-- 写节点最大连接数 200
UPDATE mysql_server_groups SET max_connections=200 WHERE hostgroup_id=1;
-- 读节点最大连接数 500
UPDATE mysql_server_groups SET max_connections=500 WHERE hostgroup_id=2;
LOAD MYSQL SERVER GROUPS TO RUNTIME;
SAVE MYSQL SERVER GROUPS TO DISK;
步骤 5:压测与监控
- 通过 ProxySQL 数据端口(6033)连接应用:
mysql -u app_user -papp_pass -h 127.0.0.1 -P 6033 - 使用
sysbench压测读请求,观察监控数据:-- 查看各节点连接数和请求量 SELECT * FROM stats_mysql_servers; -- 查看慢查询日志(需配置慢查询阈值) SELECT * FROM stats_mysql_slow_log;
四、对比与选型建议
| 维度 | MyCat | MHA | ProxySQL |
|---|---|---|---|
| 核心定位 | 分布式数据库中间件(分库分表) | MySQL 高可用(主从故障切换) | 数据库代理(连接池+查询优化) |
| 核心功能 | 分片、读写分离、分布式事务 | 自动故障检测、主从切换 | 连接池、查询路由、流量控制 |
| 支持数据库 | 多数据库(MySQL、Oracle 等) | 仅 MySQL | 仅 MySQL(支持 MariaDB、Percona) |
| 部署复杂度 | 较高(需设计分片策略) | 中等(需配置 SSH 互信、主从复制) | 低(动态配置,轻量部署) |
| 适用场景 | 海量数据分布式架构 | 主从架构高可用性保障 | 高并发连接管理与查询优化 |
| 典型案例 | 电商订单系统、用户中心 | 金融交易系统、核心数据库集群 | 高并发 API 服务、秒杀系统 |
五、总结
- MyCat 是分布式数据库的“基建工具”,通过分库分表解决数据扩展问题,需提前规划分片策略(如实例中的哈希分片配置)。
- MHA 是 MySQL 高可用的“刚需方案”,通过自动化故障切换保障主从集群的可靠性,适合对可用性敏感的核心业务(如实例中的 GTID 模式切换)。
- ProxySQL 是高性能场景的“优化利器”,通过连接池和动态路由降低数据库压力,适合高并发读写分离场景(如实例中的读写规则配置)。
实际部署中,三者可组合使用:MyCat 负责分片,MHA 保障分片内高可用,ProxySQL 优化应用到中间件的连接和查询。选择时需结合业务规模——小项目可先用 ProxySQL 优化连接,中等规模用 MHA 保障 HA,数据量爆炸时引入 MyCat 分片。技术选型的核心是“合适”,而非“全能”,通过实例落地可更高效地验证方案可行性。
以下是结合 MyCat、MHA、ProxySQL 的分布式数据库架构图,展示三者在系统中的角色和协作关系:
分布式数据库架构图(MyCat + MHA + ProxySQL)
┌───────────────┐
│ 应用层 │
└───────────────┘
│
▼
┌───────────────┐
│ ProxySQL 代理 │ (连接池管理、查询优化)
└───────────────┘
│
▼
┌───────────────┐
│ MyCat 中间件 │ (分库分表、读写分离)
└───────────────┘
│
┌───────────────┼───────────────┐
│ ▼ │
▼ ▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 分片集群1 │ │ 分片集群2 │ │ 分片集群N │
└─────────────┘ └─────────────┘ └─────────────┘
│ │ │
▼ ▼ ▼
┌─────────────┬─────────────┐ ┌─────────────┬─────────────┐
│ 主库 (M) │ 从库 (S) │ │ 主库 (M) │ 从库 (S) │
├──────┬───────┼──────┬───────┤ ├──────┬───────┼──────┬───────┤
│ ▼ │ ▼ │ ▼ │ ▼
├───────MHA───────┼───────MHA───────┤
│ Manager 节点 │ (故障检测与切换)
└─────────────────┘
图例说明:
分层架构:
- 应用层:业务系统通过数据库连接(如 JDBC/MySQL 驱动)访问 ProxySQL。
- ProxySQL 层:作为数据库代理,管理应用的连接池,根据 SQL 类型(读/写)路由到 MyCat,并优化查询流量(如负载均衡、慢查询缓存)。
- MyCat 层:分布式中间件,解析 SQL 并按分片规则(如哈希、范围)路由到具体的分片集群(如
user_id分片到集群 1 或 2)。 - 分片集群层:每个分片是独立的主从集群(M-S),由 MHA 保障高可用性。主库处理写请求,从库处理读请求(通过 MyCat 或 ProxySQL 分流)。
- MHA 层:Manager 节点监控所有分片集群的主从状态,当主库故障时自动提升从库为新主库,确保数据一致性。
核心数据流:
- 写请求:应用 → ProxySQL(识别写操作)→ MyCat(解析分片规则)→ 目标分片的主库(M)。
- 读请求:应用 → ProxySQL(识别读操作)→ MyCat(路由到从库)→ 目标分片的从库(S)。
- 高可用保障:MHA Manager 定期检测主库状态,主库宕机时触发切换,更新从库指向新主库,并通过配置中心/DNS 通知应用层切换连接地址。
关键组件交互:
- MyCat 与 ProxySQL:ProxySQL 可部署在 MyCat 前端,降低应用到中间件的连接开销;也可直接部署在数据库前端(MyCat 后端),优化中间件到数据库的连接。
- MHA 与分片集群:每个分片集群独立部署 MHA(或共享 Manager 节点),确保单个分片内的主从切换不影响其他分片。
架构特点:
- 扩展性:通过 MyCat 水平分片,支持数据量和流量的线性扩展。
- 高可用性:MHA 保障每个分片集群的主从故障切换,结合 ProxySQL 的连接重试机制,减少服务中断时间。
- 性能优化:ProxySQL 的连接池复用和查询路由降低数据库压力,适合高并发场景。
此架构适用于数据量庞大、需高可用性和高性能的分布式系统(如电商、社交平台核心数据库)。实际部署时可根据业务规模调整节点数量和部署方式(如 ProxySQL 集群、MyCat 多实例负载均衡)。
