🌟 JVM 调试与内存优化实战详解 🌟
前言
在微服务与云原生架构盛行的当下,Java 应用常面临高并发、高可用与大数据量处理的挑战。JVM(Java Virtual Machine)作为 Java 程序运行的基石,其性能直接影响系统的稳定性与吞吐能力。本文将从 JVM 内存模型入手,结合真实生产环境中的常见内存问题与排查流程,深入剖析调试工具与优化手段,帮助开发者构建高性能、低延迟的 Java 服务。🚀
一、JVM 内存模型概览
Java 虚拟机将运行时内存划分为多个逻辑区域,各区域职责明确,问题定位也各有侧重:
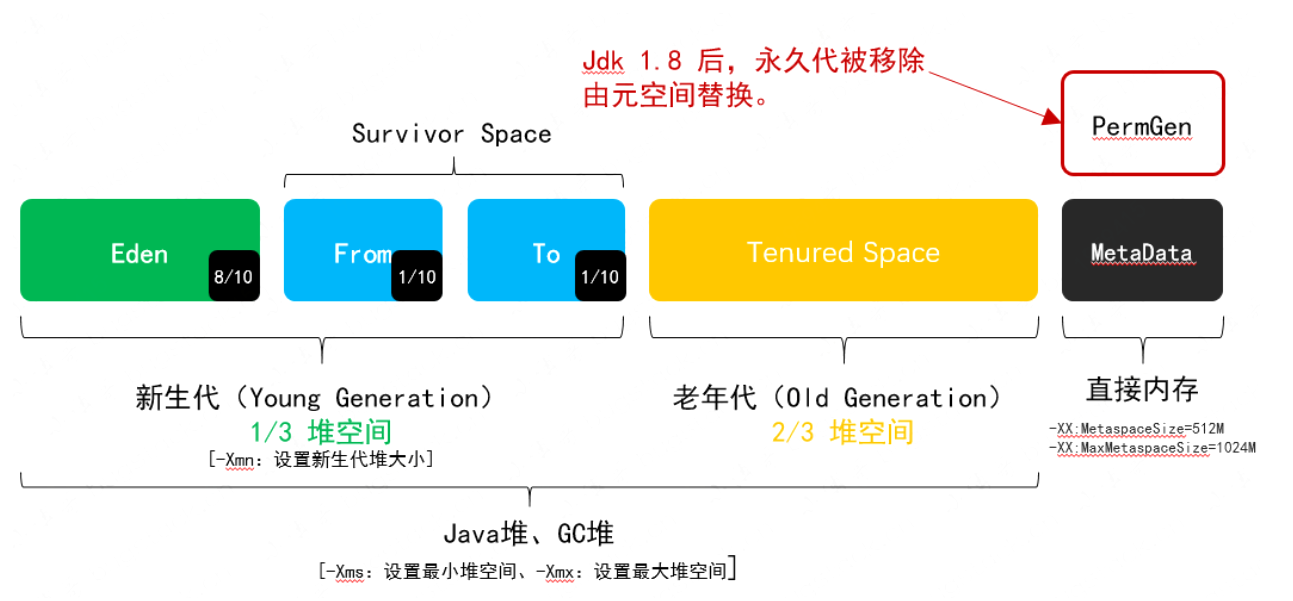
年轻代(Young Gen):Eden + Survivor,频繁 Minor GC 🌀
老年代(Old Gen):长期存活对象,高代价 Full GC ⏳
Metaspace:类元数据区,JDK 8+ 替代 PermGen 📦
直⽅内存(Direct Memory):NIO/Netty 缓冲区,需谨慎管理 🌐
二、常见内存问题与诊断思路
| ❗️ 问题表现 | 🔍 可能原因 | 🛠️ 初步诊断工具 |
|---|---|---|
| 频繁 Full GC | 老年代满载;对象晋升过快;缓存泄漏 | jstat -gcutil、GC 日志 |
| 响应延迟、卡顿 | GC 停顿时间过长;大对象分配频繁 | jstat -gc、jconsole |
| 堆内存持续增长至 OOM | 隐蔽内存泄漏(静态集合、ThreadLocal、缓存) | jmap -dump + MAT |
| Metaspace 溢出 | 动态生成类过多;ClassLoader 泄漏 | jcmd GC.class_stats |
| Direct Memory 溢出 | NIO/Netty Buffer 泄漏;过度使用直接缓冲区 | 应用日志 + Netty 监控 |
三、核心调试工具与命令详解
| 工具 / 命令 | 功能说明 |
|---|---|
jps |
列出 Java 进程 PID |
jstat -gcutil <pid> 1000 |
内存区使用率与 GC 次数 |
jmap -histo:live <pid> |
堆中对象分布 |
jmap -dump:live,format=b,file=heap.hprof <pid> |
导出堆快照,仅包含存活对象 |
jstack <pid> > thread.log |
导出线程栈,排查死锁/阻塞 |
jcmd <pid> GC.class_stats |
查看 Metaspace 类加载统计 |
| VisualVM / JConsole | GUI 监控:内存、线程、GC |
| Arthas | heap、monitor、ttop、trace、jad 等命令 |
| MAT (Memory Analyzer) | 分析 .hprof,查找泄漏疑点 |
| Async‑profiler | CPU/内存/锁竞争火焰图,直观定位热点 |
四、实战案例一:频繁 Full GC 深度排查与优化
1. 🕵️ 问题现象
服务运行数小时后,响应延迟飙升至 2000ms+
Old Gen 使用率稳定 95%+
Full GC 停顿偶现 > 500ms
2. 🔬 排查流程
(1)日志 & 监控:确认 System.gc() 或 CMS ConcurrentModeFailure
(2)堆快照:
jmap -dump:live,format=b,file=fullgc.hprof <pid>
(3)晋升行为:检查 Survivor 利用率,调整 -XX:SurvivorRatio
- 代码审查:大对象复用 & 缓存清理策略
3. ✅ 优化方案
JVM 参数
-Xms8g -Xmx8g -Xmn2g \ -XX:SurvivorRatio=8 \ -XX:+UseG1GC -XX:MaxGCPauseMillis=200切换 G1GC:Region 管理,混合回收,适合大堆 (>6GB)
代码优化:对象池 & Caffeine 缓存(容量/过期策略)
五、实战案例二:隐蔽内存泄漏定位与修复
1. 🕵️ 问题现象
应用长时间运行后,Heap 使用率持续上升直至 OOM
Minor GC 后 Eden/S0 可回收,Old Gen 稳步增长
2. 🔬 排查流程
(1)堆快照:
jmap -dump:live,format=b,file=leak.hprof <pid>
(2)MAT 分析:
Leak Suspects Report
Dominator Tree
(3)GC Roots:静态变量 / ThreadLocal / 未关闭资源
3. ✅ 修复策略
弱引用缓存
Cache<K, V> cache = Caffeine.newBuilder() .weakKeys().weakValues() .expireAfterWrite(10, TimeUnit.MINUTES) .build();ThreadLocal 管理
try { threadLocal.set(v); /*...*/ } finally { threadLocal.remove(); }资源关闭:JDBC/IO/Netty Channel/Listener
定期清理:
Executors.newSingleThreadScheduledExecutor() .scheduleAtFixedRate(cache::cleanUp,1,1,TimeUnit.HOURS);
六、实战案例三:大对象分配导致 Young GC 瓶颈
1. 🕵️ 问题背景
处理大文件上传时,构造 50MB 左右的
byte[]或ByteBuffer。并发高时,Minor GC 频繁,停顿 50–100ms,影响响应。
2. 🔬 排查流程
(1)监控:
jstat -gcutil <pid> 500
(2)堆快照:
jmap -histo:live <pid>
(3)GC 日志:
-Xlog:gc*,gc+heap=debug:file=gc.log:time,level,tags
3. 🔍 分析思路
大对象直接进入 Old Gen,Old Gen 使用率上升;
Eden 中小对象频繁分配,触发更多 Minor GC。
4. ✅ 优化方案
堆外分配
ByteBuffer buffer = ByteBuffer.allocateDirect(size);对象复用:使用
PooledByteBufAllocator调整年轻代大小
-Xmn1g -XX:MaxNewSize=1g
七、实战案例四:Web 应用 Session 内存泄漏
🕵️ 问题背景
Spring MVC 应用,Session 中存储自定义对象。
活跃用户增多,堆内存持续增长,触发 OOM。
🔬 排查流程
(1)监控:
jconsole观察堆内存趋势(2)堆快照:
jmap -dump:live,format=b,file=session_leak.hprof <pid>(3)MAT 分析:定位
StandardSession实例过多(4)GC Roots:Session Map 引用链
✅ 优化方案
Session 过期策略
<session-config><session-timeout>15</session-timeout></session-config>轻量化 Session:仅存必要字段
分布式 Session:Redis 存储,设置过期
八、实战案例五:多线程池配置不当导致内存压力
- 🕵️ 问题背景
多个
ThreadPoolExecutor,无界队列。高并发时,任务堆积,
Runnable对象大量堆积,内存飙升。
🔬 排查流程
(1)监控:
jstat -gcutil显示 Old Gen 上升(2)队列监控:
jconsole查看队列长度(3)堆快照:
jmap -histo:live定位FutureTask✅ 优化方案
有界队列 + 拒绝策略
new ThreadPoolExecutor(50,100,60,TimeUnit.SECONDS, new ArrayBlockingQueue<>(1000), new ThreadPoolExecutor.CallerRunsPolicy());监控告警:队列长度、活跃线程数
动态扩缩容:基于响应与队列长度自动调整
九、高级调优策略与 JVM 参数解读
| 参数 | 作用 |
|---|---|
-XX:+UseG1GC |
启用 G1 收集器,低停顿 |
-XX:MaxGCPauseMillis=200 |
G1 目标最大停顿 |
-XX:InitiatingHeapOccupancyPercent=45 |
G1 并发标记阈值 |
-XX:+UseStringDeduplication |
G1 字符串去重 |
-XX:MetaspaceSize=128m |
Metaspace 初始大小 |
-XX:MaxMetaspaceSize=512m |
Metaspace 最大大小 |
-XX:+HeapDumpOnOutOfMemoryError |
OOM 时生成堆转储 |
-XX:HeapDumpPath=/path/dump.hprof |
指定堆转储路径 |
-Xlog:gc*:file=/path/gc.log:time |
JDK 9+ 统一 GC 日志格式 |
十、堆外内存与 Metaspace 优化
✨ Direct Memory
Netty Buffer 泄漏:启用
ResourceLeakDetector参数:
-XX:MaxDirectMemorySize=2g
✨ Metaspace
动态类卸载:Spring Devtools / 自定义 ClassLoader 清理
参数:
-XX:MaxMetaspaceSize=256m+jcmd GC.class_stats
十一、在线诊断利器:Arthas 与 Async‑profiler
Arthas:
heap histogram、monitor、ttop、trace、jad
Async‑profiler:
./profiler.sh -d30 -f cpu.svg <pid> ./profiler.sh -e alloc -f mem.svg <pid>
🔥 火焰图直观定位 CPU/内存热点
十二、新一代 GC 对比与选型
| 特性 | G1GC | ZGC | Shenandoah |
|---|---|---|---|
| 停顿时间 | < 200ms | < 10ms | < 10ms |
| 最大堆支持 | 多 TB | 多 TB | 多 TB |
| 并发标记整理 | 并发标记 + 短暂停顿整理 | 全并发,无停顿搬迁 | 并发标记与整理,无停顿搬迁 |
| CPU 开销 | 中等 | 较高 | 中等偏高 |
| JDK 支持 | 9+ | 11+ | 12+ |
十三、容器化与云原生场景下的 JVM 调优
- CGroup 内存识别
JDK 8:
-XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeapJDK 10+ 自动感知
- 避免 OOMKilled
-Xmx≈ 容器内存 75%,保留 25% 给 Metaspace/DirectMemory/OS
- 水平扩缩容
HPA:
jvm_memory_bytes_used+jvm_gc_pause_secondsIstio/Linkerd 限流熔断
可观测性
management: metrics: export: prometheus: enabled: true
十四、总结与最佳实践
监控为先:实时 GC/内存/线程报警与可视化
日志为证:规范 GC 日志,定期归档分析
快照为王:关键时刻堆 & 线程快照 + 深度剖析
策略为纲:选对 GC:G1GC、ZGC、Shenandoah
代码为本:缓存 & 资源管理需严谨,弱引用 + 清理
持续优化:CI/CD + 运维闭环,确保线上健康 💪
通过对 JVM 内存模型的深入理解、系统化的诊断流程,以及工具链与参数的合理应用,开发者能够在复杂生产环境中快速定位瓶颈并实施有效优化,确保 Java 服务的高可用与高性能。🎉