解决的问题
Multi-Head Latent Attention,MLA——解决的问题:KV cache带来的计算效率低和内存需求大以及上下文长度扩展问题。
MLA原理
MLA原理:其核心思想是将键(Key)和值(Value)矩阵压缩到一个低维的"潜在"空间中,从而显著减少KV缓存的内存占用。与传统MHA相比,MLA不直接存储完整的键值矩阵,而是存储一个维度更小的压缩向量。在需要进行注意力计算时,再通过解压缩重构出所需的键和值(减少了权重矩阵要学习的参数量)。这种压缩-解压缩机制使得模型可以在显著减少内存占用的同时,保持甚至提升性能。DeepSeek-V2的技术报告显示,MLA使KV缓存减少了93.3%,训练成本节省了42.5%,生成吞吐量提高了5.76倍。在8个H800 GPU上实际部署时,实现了超过50,000令牌每秒的生成速度,这一数据充分证明了MLA的高效性。
步骤
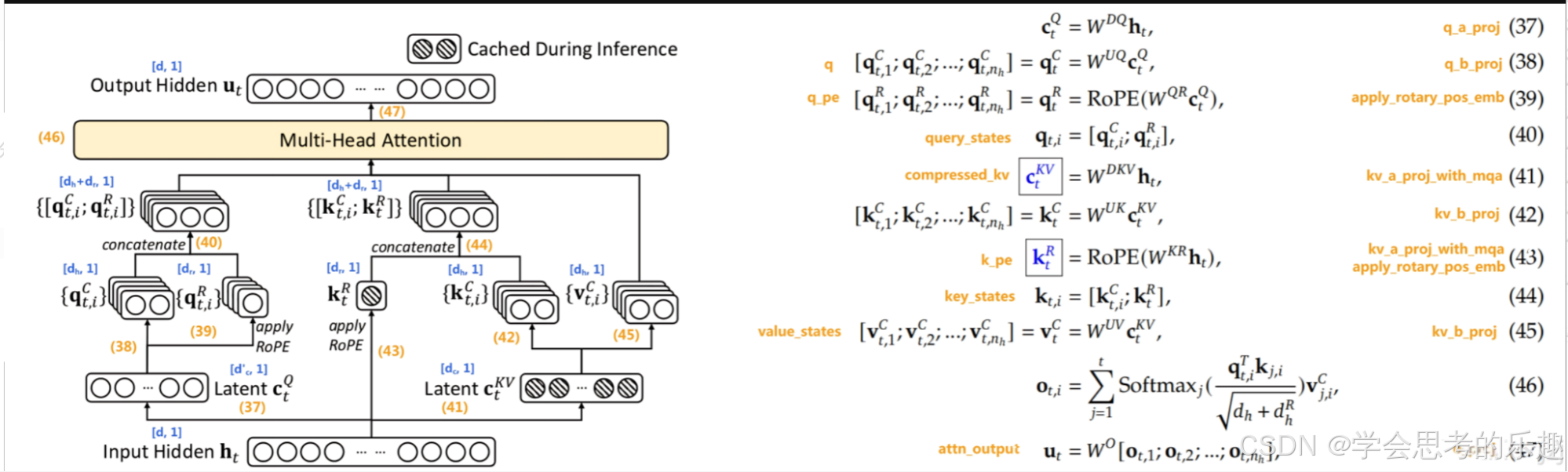
首先压缩Q即公式(37)。
从5120先降维再升维,好处是相比直接使用大小为 [5120, 24576] 的矩阵# [5120, 1536] * [1536, 24576] 这样的低秩分解在存储空间和计算量上都大幅度降低维降到1536维 。也就是(37)-(40)模型所要学习的矩阵。
# 对隐藏状态进行线性投影和归一化,生成查询张量
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states)))
# 调整查询张量的形状
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)

解压缩C并拆分,即(38)、(39)和(40)
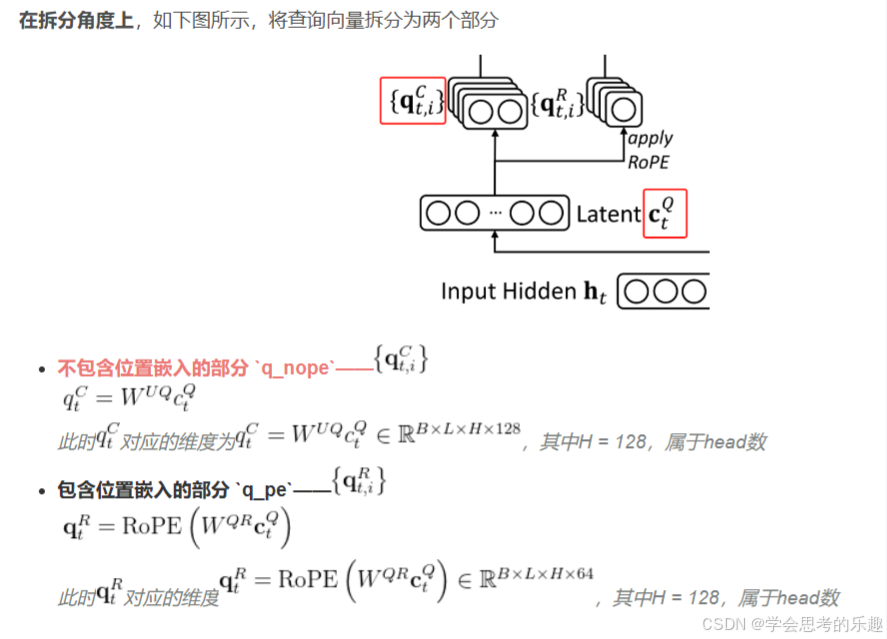

q_nope, q_pe = torch.split(
# 将查询张量拆分为不包含位置嵌入的部分和包含位置嵌入的部分
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
对KV张量的降维、分裂K、拆分KV且升维
具体的代码涉及公式(41) kv_a_proj_with_mqa 和 公式(42)kv_b_proj 两个参数矩阵。

升维之后计算注意力
给q_pe, k_pe给加上rope且合并,然后做标准注意力计算。
这一部分也涉及一个权重矩阵: o_proj,大小 [num_heads * v_head_dim, hidden_size] = [128*128, 5120]

将查询和键张量 `q_pe` 和 `k_pe` 进行旋转
# 计算旋转位置嵌入的余弦和正弦值
cos, sin = self.rotary_emb(value_states, seq_len=kv_seq_len)
# 应用旋转位置嵌入
q_pe, k_pe = apply_rotary_pos_emb(q_pe, k_pe, cos, sin, position_ids)
接着,方法创建新的查询状态张量 `query_states` ,然后将旋转后的部分和不包含位置嵌入的部分合并便可得到最终的Q向量
# 创建新的查询状态张量
query_states = k_pe.new_empty(bsz, self.num_heads, q_len, self.q_head_dim)
# 将不包含位置嵌入的部分赋值给查询状态张量
query_states[:, :, :, : self.qk_nope_head_dim] = q_nope
# 将包含位置嵌入的部分赋值给查询状态张量
query_states[:, :, :, self.qk_nope_head_dim :] = q_pe
K相似操作。
关于矩阵吸收十倍提速


这里不用展开计算的意思我理解为就是不需要再单独升维计算,UK矩阵被吸收后直接与降维压缩的K相乘即可。 这样减少了中间变量的存储,提高了计算效率。
# 以下和原本实现相同
bsz, q_len, _ = hidden_states_q.size()
q = self.q_b_proj(self.q_a_layernorm(self.q_a_proj(hidden_states_q)))
q = q.view(bsz, q_len, self.num_heads, self.q_head_dim).transpose(1, 2)
q_nope, q_pe = torch.split(
q, [self.qk_nope_head_dim, self.qk_rope_head_dim], dim=-1
)
kv_seq_len = compressed_kv.size(1)
compressed_kv, k_pe = torch.split(
compressed_kv, [self.kv_lora_rank, self.qk_rope_head_dim], dim=-1
)
k_pe = k_pe.view(bsz, 1, kv_seq_len, self.qk_rope_head_dim)
# 从 kv_b_proj 中分离的 W^{UK} 和 W^{UV} 两部分,他们要分别在不同的地方吸收
kv_b_proj = self.kv_b_proj.weight.view(self.num_heads, -1, self.kv_lora_rank)
q_absorb = kv_b_proj[:, :self.qk_nope_head_dim,:]#W^{UK}
out_absorb = kv_b_proj[:, self.qk_nope_head_dim:, :]#W^{UV}
cos, sin = self.rotary_emb(q_pe)
q_pe = apply_rotary_pos_emb(q_pe, cos, sin, q_position_ids)
# !!! 关键点,W^{UK} 即 q_absorb 被 q_nope(W^{UQ}) 吸收
q_nope = torch.einsum('hdc,bhqd->bhqc', q_absorb, q_nope)
# 吸收后 attn_weights 直接基于 compressed_kv 计算不用展开。
attn_weights = torch.matmul(q_pe, k_pe.transpose(2, 3)) + torch.einsum('bhqc,blc->bhql', q_nope, compressed_kv)
attn_weights *= self.softmax_scale ![]()
#原始顺序
v_t = einsum('hdc,blc->blhd', W_UV, c_t_KV) # (1)
o = einsum('bqhl,blhd->bqhd', attn_weights, v_t) # (2)
u = einsum('hdD,bhqd->bhD', W_o, o) # (3)
# 将上述三式合并,得到总的计算过程
u = einsum('hdc,blc,bqhl,hdD->bhD', W_UV, c_t_KV, attn_weights, W_o)
#改变顺序
# 利用结合律改变计算顺序
o_ = einsum('bhql,blc->bhqc', attn_weights, c_t_KV) # (4)#将注意力权重attn_weights与压缩的键-值矩阵c_t_KV相乘,直接得到一个更紧凑的中间结果o_。
o = einsum('bhqc,hdc->bhqd', o_, W_UV) # (5)#将中间结果o_与权重矩阵W_UV相乘,得到o
u = einsum('hdD,bhqd->bqD', W_o, o) # (6)#将权重矩阵W_o与o相乘,得到最终输出u总结
MLA不直接存储完整的键值矩阵,而是存储一个维度更小的压缩向量。在需要进行注意力计算时,再通过解压缩重构出所需的键和值
1.减少了权重矩阵要学习的参数量。2.通过矩阵吸收减少了中间需要解压后的K和V的矩阵,减少了中间存储数据量提高了计算效率。
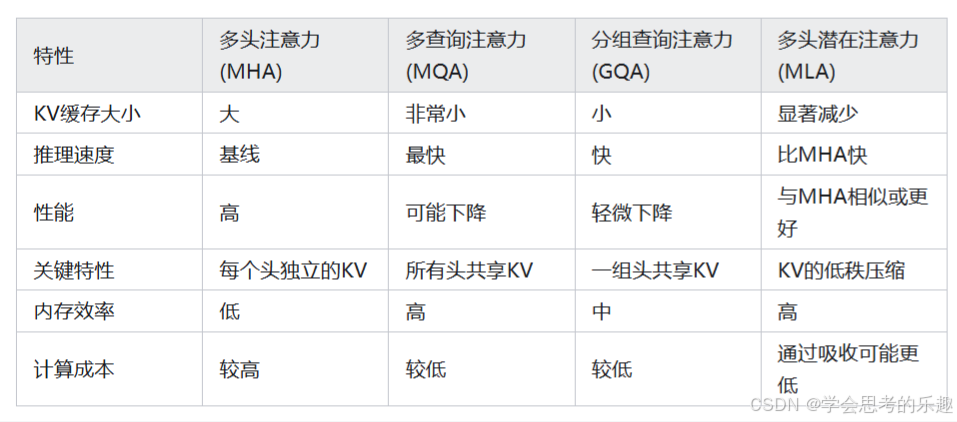
与其他注意力机制的比较
参考说明
[1] [深度剖析Deepseek 多头潜在注意力(MLA) - 知乎
[2]MLA实现及其推理上的十倍提速——逐行解读DeepSeek V2中多头潜在注意力MLA的源码(图、公式、代码逐一对应)_mla加速 csdn-CSDN博客