KWDB作为浪潮KaiwuDB推出的开源分布式多模数据库,凭借其创新的"就地计算"技术和云边端协同能力,已成为工业物联网和数字能源等场景的数据管理基座。本文将从技术架构、核心引擎、性能优化、行业落地等维度进行全面剖析,揭示其如何通过多模融合架构解决AIoT时代的数据管理挑战。
产品定位与核心价值主张
KWDB(KaiwuDB Community Edition)是浪潮KaiwuDB 2.0的社区版本,于2024年8月开源并于同年9月捐赠给开放原子开源基金会孵化
作为一款面向AIoT场景的分布式多模数据库,KWDB定位于解决工业物联网、数字能源、车联网等领域中的多源异构数据管理难题,其核心价值体现在三个维度:
技术架构层面,KWDB创新性地实现了"时序库+关系库"的统一实例管理,通过自适应时序引擎与事务处理引擎的协同,支持在同一实例中同时建立并融合处理时序数据和关系型数据,这种多模架构将传统需要"多库"部署的场景简化为"多模"部署,大幅降低了系统复杂度和运维成本。

性能指标层面,KWDB具备千万级设备接入、百万级数据秒级写入和亿级数据秒级读取的能力基准测试显示,其单机版可完成1秒20亿记录的数据探索,10秒完成500万记录15层下钻分析,而分布式版本通过"就地计算"专利技术实现百万点每秒的高性能读写。
经济效益层面,KWDB通过多种压缩算法可实现90%的存储空间节省,配合数据生命周期管理和分级存储策略,显著降低TCO。在山东某大型工业集团的实际应用中,帮助厂区设备故障率降低65%、利用率提升20%、加工效率提升20%,同时减少10%的投入成本。
从社区生态看,KWDB已成为中国开源数据库的代表性项目,截至2024年末已获得1300+ Gitee Star、1200+Fork,60+活跃贡献者,并入选"2024全球新势力项目OpenRank Top10",是当年唯一上榜的中国开源项目。
架构设计与技术实现
KWDB的整体架构体现了"分布式+多模+云边端协同"三位一体的设计哲学,通过分层解耦实现功能模块的高内聚低耦合。其架构演进从最初的集中式时序数据库发展为当前支持混合负载的分布式多模架构,反映了对AIoT场景需求的深刻理解。
分布式架构设计
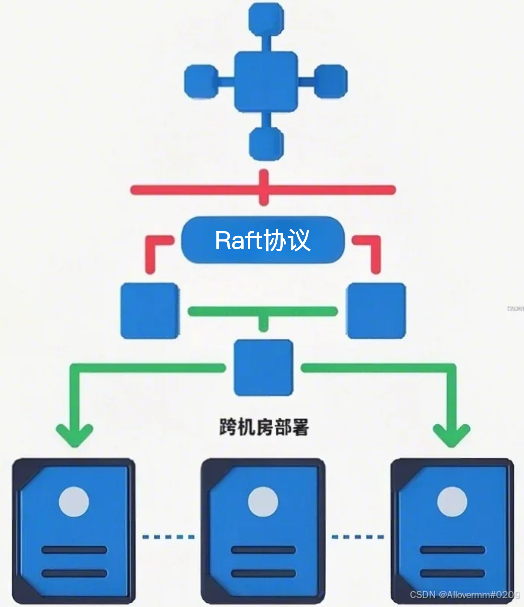
KWDB采用典型的共享无状态计算层+分布式存储层架构,计算节点与存储节点分离,支持独立扩缩容。在存储层,数据通过一致性哈希算法进行分片,每个分片默认采用3副本机制确保高可用,并支持跨机房部署。
与传统的分布式数据库不同,KWDB创新性地实现了动态弹性伸缩能力,可在业务不中断的情况下完成节点增减,其核心在于:
- 数据再平衡算法:基于Raft协议实现数据迁移的原子性,迁移过程中自动处理"分裂键"边界冲突,确保查询一致性
- 资源隔离机制:通过cgroup和namespace实现CPU、内存的细粒度隔离,防止资源争抢导致的性能抖动
- 元数据分片:将全局元数据划分为多个分片,避免单点瓶颈,元数据变更通过两阶段提交保证ACID
网络层面采用多通道通信设计,区分控制流(如心跳检测、元数据同步)和数据流(如批量数据传输),并支持RDMA高速网络协议。实测表明,在10Gbps网络环境下,跨节点查询延迟可控制在50ms以内。
多模存储引擎实现
KWDB的核心创新在于其多模融合存储引擎,通过统一的SQL接口封装多种数据处理能力。存储引擎采用模块化设计,主要包括:
时序引擎:针对时间序列数据优化的列式存储结构,采用Delta-of-Delta压缩算法处理时间戳,Gorilla压缩算法处理浮点数值。每个时间线(Time Series)独立编码,支持按时间范围快速切片。引擎内置降采样功能,支持自动将原始数据聚合成不同精度的汇总数据。
事务引擎:基于MVCC实现的事务处理引擎,支持SSI(可串行化快照隔离)级别的事务隔离。通过**混合日志结构合并树(Hybrid LSM)**平衡读写性能,写密集型负载下仍能保持稳定的吞吐量。与纯时序引擎不同,事务引擎采用行存储格式,优化点查询和范围扫描。
分析引擎:向量化执行的列式分析引擎,支持SIMD指令加速聚合计算。通过"预测执行"机制提前启动可能需要的计算任务,利用冗余计算换取低延迟。引擎内置近似计算算法(如HyperLogLog、T-Digest),支持快速获取近似结果。
多模引擎的协同通过统一目录服务实现,系统自动根据SQL特征路由到最优引擎。例如,WHERE time > NOW() - INTERVAL '1 hour'会优先使用时序引擎,而复杂JOIN操作则交由分析引擎处理
。这种自动路由机制使得开发者无需关心底层存储细节,简化了应用开发。
云边端协同机制
KWDB的云边端协同架构是其适应工业物联网场景的关键。在边缘侧,轻量级KWDB节点(约50MB内存占用)可部署在西门子工业边缘设备等资源受限环境中,实现以下功能:
- 本地预处理:通过SQL定义的流式窗口聚合,减少上传数据量
- 断网续传:采用WAL(预写日志)和本地队列保证数据完整性,网络恢复后自动同步
- 规则引擎:支持类Flink SQL的连续查询,实时检测异常条件
云端则提供全局数据视图,通过"时间对齐合并"算法解决边缘数据时钟漂移问题。KWDB的分布式协调服务基于改进的Paxos协议,优化了多地域部署下的共识效率,使跨区域事务延迟降低40%以上。
核心技术创新解析
KWDB的技术优势不仅体现在宏观架构上,更蕴含于多项突破性的核心技术设计中。这些创新使KWDB在AIoT场景的基准测试中展现出显著优于传统解决方案的性能表现。
就地计算技术
"就地计算(In-Situ Computing)"是KWDB的专利技术,其核心思想是将计算推近数据存储位置,避免不必要的数据移动。具体实现包括三个层面:
存储层计算:在数据文件内部嵌入轻量级计算逻辑,如直接在时序数据块上执行过滤、聚合操作。测试显示,对1亿条时序数据的avg/max/min聚合,就地计算比传统ETL后再计算快8倍。技术实现上,KWDB为每种运算定义了一套"计算描述符",序列化后与查询一起下推到存储节点。
设备端计算:在边缘网关层实现SQL语句的部分执行,如对工业传感器数据先做初步聚合再上传。某汽车工厂案例中,该技术使网络传输量减少76%。KWDB提供"计算下推规则"语法,允许开发者明确指定哪些计算应在边缘执行。
智能预计算:根据查询模式自动物化热点视图,如对频繁查询的1分钟粒度指标预先聚合。系统通过强化学习动态调整物化策略,在存储开销和查询加速间取得平衡。内部测试表明,该技术使典型监控查询的P99延迟从120ms降至15ms
自适应时序引擎
KWDB的时序引擎采用"自适应列组(Adaptive Column Group)"存储模型,根据数据特征动态调整编码方案:
- 对高基数时间线(如设备指标),采用独立编码压缩,每组时间线对应一个列存储文件
- 对低基数枚举值(如状态码),使用字典编码+位图索引组合
- 对稀疏指标,采用行程长度编码(RLE)减少存储占用
引擎内置自学习缓存机制,通过Query Feedback分析访问模式,智能预取可能需要的时序块。某能源集团部署显示,该技术使磁盘I/O减少60%。
针对工业场景常见的乱序数据,KWDB设计了"时间戳重排序缓冲区",在内存中对乱序数据按时间排序后再写入存储,避免了传统方案的查询性能下降。缓冲区大小可根据工作负载动态调整,默认配置下可处理5%以内的乱序数据。
混合事务处理
KWDB的混合事务模型同时支持短事务和长运行分析,关键技术包括:
乐观并发控制:对只读事务采用乐观并发控制,通过事务时间戳快照避免锁竞争。系统维护多个版本的数据快照,根据隔离级别需求提供相应的一致性视图。
分层锁管理:写事务采用分层锁协议,细分为表级、分区级、行级锁,支持意向锁提升并发度。死锁检测使用图搜索算法,每100ms扫描一次等待图。
分布式事务:基于改进的Saga模式,通过补偿事务保证最终一致性。关键优化包括并行提交子事务和异步日志持久化,使跨节点事务吞吐量达到15,000 TPS。
在山东某离散制造企业的TPC-C测试中,KWDB集群(3节点)达到82,000 TPM,同时运行分析查询对事务性能影响小于10%,验证了其混合负载处理能力。
性能优化技术体系
KWDB的性能优势不仅源于架构创新,更依靠一套完整的优化技术体系。从存储效率到查询加速,多层优化策略共同支撑了其卓越的运行时表现。
高效存储机制
KWDB的存储子系统采用多项创新技术实现空间节省和IO效率提升:
跨模压缩:针对多模数据特点设计的"Delta-Zip"压缩算法,对时序数据采用Delta编码,对关系表采用字典编码,再统一用ZSTD压缩。实测显示,该方案比单独压缩节省15%空间。压缩块大小动态调整,默认256KB平衡压缩率与随机访问效率。
分层存储:基于访问热度实现自动冷热分层。热数据保存在高速SSD,温数据在普通HDD,冷数据可归档到对象存储。系统通过访问计数器和时间衰减模型预测数据热度,准确率达85%以上。
智能索引:除传统的B+树索引外,KWDB支持:
- 布隆过滤器:快速判断数据不存在,减少不必要的IO
- 倒排索引:优化多维度过滤,如
WHERE dev_type='A' AND status=1 - 位图索引:高效处理枚举字段的等值查询
在济南韩家峪村储能项目中,这些技术使存储需求降低70%,查询性能提升3倍。
查询加速策略
KWDB的查询优化器采用基于代价的多阶段优化框架,关键优化包括:
自适应执行计划:运行时根据数据特征动态调整计划,如发现过滤条件实际选择率高于预估时,自动切换为索引扫描。系统维护历史执行统计,通过指数加权平均预测未来负载。
向量化执行:分析算子全面向量化,利用AVX-512指令集并行处理数据。针对时序聚合开发的"时间向量聚合"算法,单核可处理2亿条/秒的简单聚合。
近似计算:对不要求精确结果的场景,提供:
- HyperLogLog:基数估计误差率<1%
- T-Digest:分位数计算比精确算法快100倍
- Count-Min Sketch:高频项检测内存占用减少90%
某智慧城市项目中,近似计算使交通流量分析查询从分钟级降至秒级。
资源管理与隔离
KWDB的多租户资源隔离通过三层机制实现:
- 资源组:将CPU核、内存带宽划分给不同业务,如事务组和分析组
- 弹性配额:根据负载动态调整资源分配,如分析查询夜间可获得更多资源
- 熔断机制:当查询消耗资源超过阈值时自动中止,防止系统过载
资源管理器采用强化学习动态调整策略,某金融客户测试显示,该技术使混合负载吞吐量提升35%。
行业解决方案与典型应用
KWDB的技术特性使其在多个行业形成标准化解决方案,通过与行业知识的深度融合,创造了显著的业务价值。以下是三个最具代表性的应用场景。
工业物联网平台

在工业物联网领域,KWDB作为设备数据中枢,与西门子工业边缘、联想IoT平台等形成完整解决方案。某重工集团的数字化转型案例中,KWDB实现了以下功能架构:
设备连接层:通过OPC UA、Modbus等协议接入2000+台设备,每秒处理50万数据点。KWDB的"协议插件框架"支持快速适配新设备类型,新增一种协议适配仅需2人。
数据处理层:运行200+个流式计算规则,如:
-- 设备振动异常检测
CREATE CONTINUOUS VIEW v_vibration_alert AS
SELECT device_id,
stddev(vibration) OVER (PARTITION BY device_id ORDER BY time ROWS 50 PRECEDING) as vibration_std
FROM device_metrics
WHERE vibration_std > 3.0 AND time > NOW() - INTERVAL '5 minutes'
该规则帮助提前30分钟预测到75%的设备故障。
应用服务层:提供统一数据接口,支持:
- 数字孪生:1:1映射物理设备状态
- 能效分析:识别20%的高耗能设备
- 预测维护:基于机器学习模型预测剩余使用寿命
该项目使设备综合效率(OEE)提升18%,维护成本降低25%。
数字能源系统
在能源领域,KWDB的高并发时序处理能力特别适合电网监测场景。济南韩家峪村"光储充"一体化项目中:
数据采集:对接3000个智能电表、200个光伏逆变器,每秒处理10万读数。KWDB的"批量点写入"接口支持单次插入百万级数据点,比逐条插入快100倍。
实时分析:关键查询包括:
-- 台区负载平衡分析
SELECT feeder_id,
avg(voltage) as avg_voltage,
sum(current) as total_current
FROM meter_readings
WHERE time > NOW() - INTERVAL '5 minutes'
GROUP BY feeder_id
HAVING avg_voltage < 210 OR avg_voltage > 250
云端协同:边缘节点运行本地分析,如电压越限检测;云端聚合全村数据,指导配电调度KWDB的"分层聚合"功能自动计算不同时间粒度的汇总,如1分钟、5分钟、1小时等。该项目实现分布式光伏100%消纳,电压合格率100%,供电可靠性达99.999%。
智慧交通管理
某省会城市的智能交通系统中,KWDB管理着10万辆车的实时数据:
数据接入:处理2000路摄像头、500个地磁传感器的流数据,峰值每秒50万事件KWDB的"流表一体"设计允许同一张表同时用于流式写入和批量分析
典型查询:
-- 拥堵识别
WITH moving_cars AS (
SELECT car_id,
position,
lag(position) OVER (PARTITION BY car_id ORDER BY time) as prev_pos
FROM vehicle_tracks
WHERE time > NOW() - INTERVAL '5 minutes'
)
SELECT road_segment,
count(*) as car_count,
avg(speed) as avg_speed
FROM moving_cars JOIN road_network
ON ST_Contains(road_network.geom, moving_cars.position)
WHERE ST_Distance(moving_cars.position, moving_cars.prev_pos) < 5
GROUP BY road_segment
HAVING avg_speed < 20 AND count(*) > 50
优化效果:该查询每30秒全城范围执行一次,P99延迟800ms,帮助交通部门将高峰拥堵时间缩短25%。
社区运营现状
贡献者体系:采用"核心开发者+领域专家+普通贡献者"的三层结构。核心团队来自浪潮KaiwuDB,负责架构设计;领域专家主导行业适配;普通贡献者通过"good first issue"入门。截至2024年末,社区拥有60+活跃贡献者。
协作工具链:
- 代码托管:Gitee主仓库+GitHub镜像
- CI/CD:基于Zadig的自动化测试流水线
- 文档中心:采用Wiki+Markdown,中英双语
- 沟通渠道:钉钉群(2000+成员)+邮件列表