本节代码定义了一个函数 causal_mask,用于生成因果掩码(Causal Mask)。因果掩码通常用于自注意力机制中,以确保模型在解码时只能看到当前及之前的位置,而不能看到未来的信息。这种掩码在自然语言处理任务(如语言生成)中非常重要,因为它模拟了人类阅读或写作时的顺序性。
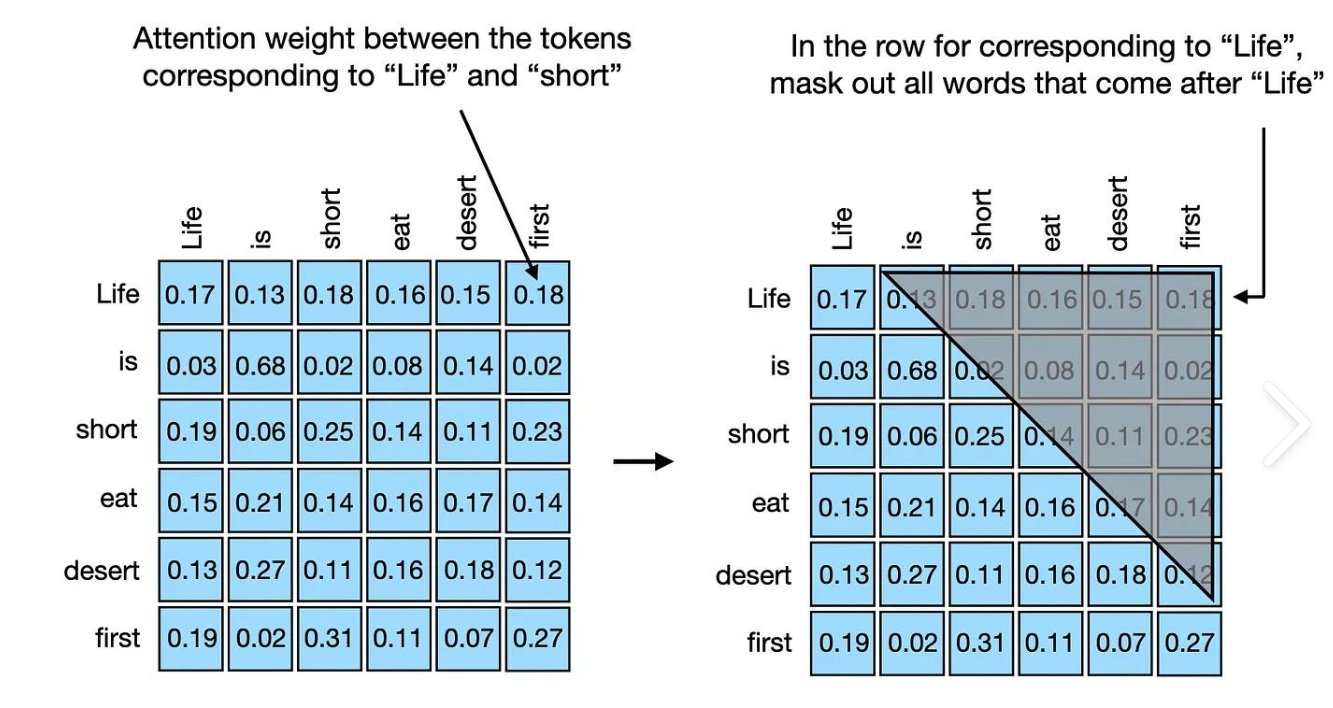
一、因果掩码(Causal Mask)代码实现
def causal_mask(x):
mask = torch.triu(torch.ones(x.shape[0], x.shape[0]), diagonal=1) == 0
return mask1. 输入参数
x:输入张量,通常是一个序列,形状为(seq_len, d_model)或(batch_size, seq_len, d_model)。这里的seq_len是序列的长度。
2. 生成掩码
mask = torch.triu(torch.ones(x.shape[0], x.shape[0]), diagonal=1) == 0torch.ones(x.shape[0], x.shape[0]):生成一个形状为(seq_len, seq_len)的全1矩阵。torch.triu(..., diagonal=1):取该矩阵的上三角部分(包括对角线),其余部分设置为0。diagonal=1表示从对角线的下一个位置开始取上三角部分。== 0:将上三角部分(包括对角线)的值设置为False,其余部分设置为True。这样生成的掩码矩阵中,True表示需要保留的注意力位置,False表示需要被忽略的注意力位置。
3. 返回值
mask:生成的因果掩码,形状为(seq_len, seq_len),是一个布尔张量。
示例
假设输入张量 x 的形状为 (5, d_model),即序列长度为5。那么:
x = torch.randn(5, d_model) # 示例输入
mask = causal_mask(x)
print(mask)输出的掩码矩阵 mask 将是:
tensor([[ True, False, False, False, False],
[ True, True, False, False, False],
[ True, True, True, False, False],
[ True, True, True, True, False],
[ True, True, True, True, True]])作用
在自注意力机制中,因果掩码用于确保模型在计算注意力分数时,只能看到当前及之前的位置,而不能看到未来的信息。具体来说:
True:表示可以计算注意力分数。False:表示需要被忽略,注意力分数会被设置为一个非常小的值(如-1e9),从而在 softmax 归一化后,其权重趋近于0。
二、因果掩码如何使用?
1. 因果掩码的生成
因果掩码的生成函数如下:
def causal_mask(x):
mask = torch.triu(torch.ones(x.shape[0], x.shape[0]), diagonal=1) == 0
return mask输入:
x是一个张量,通常是一个序列的嵌入表示,形状为(seq_len, d_model)或(batch_size, seq_len, d_model)。输出:生成一个布尔张量
mask,形状为(seq_len, seq_len),其中上三角部分(包括对角线)为True,其余部分为False。
2. 因果掩码的应用
因果掩码在 Poetry 数据集类中被应用,具体如下:
class Poetry(Dataset):
def __init__(self, poetries, tokenizer: Tokenizer):
self.poetries = poetries
self.tokenizer = tokenizer
self.pad_id = self.tokenizer.vocab["[PAD]"]
self.bos_id = self.tokenizer.vocab["[BOS]"]
self.eos_id = self.tokenizer.vocab["[EOS]"]
def __len__(self):
return len(self.poetries)
def __getitem__(self, idx):
poetry = self.poetries[idx]
poetry_ids = self.tokenizer.encode(poetry)
input_ids = torch.tensor([self.bos_id] + poetry_ids)
input_msk = causal_mask(input_ids)
label_ids = torch.tensor(poetry_ids + [self.eos_id])
return {
"input_ids": input_ids,
"input_msk": input_msk,
"label_ids": label_ids
}__getitem__方法:对于每首诗
poetry,将其编码为poetry_ids。在输入序列的开头添加
[BOS](开始标记符),生成input_ids。使用
causal_mask函数生成因果掩码input_msk。在标签序列的末尾添加
[EOS](结束标记符),生成label_ids。
3. 因果掩码的传递
在训练过程中,因果掩码 input_msk 会被传递给模型的自注意力层。具体如下:
for epoch in range(epochs):
for batch in tqdm(trainloader, desc="Training"):
batch_input_ids = batch["input_ids"]
batch_input_msk = batch["input_msk"]
batch_label_ids = batch["label_ids"]
output = model(batch_input_ids, batch_input_msk)
loss = loss_fn(output.view(-1, len(vocab)), batch_label_ids.view(-1))
loss.backward()
optim.step()
optim.zero_grad()model(batch_input_ids, batch_input_msk):batch_input_ids是输入序列的嵌入表示。batch_input_msk是对应的因果掩码。模型在计算自注意力时,会使用
batch_input_msk来确保解码器只能看到当前及之前的位置。
4. 因果掩码的作用
在 MultiHeadAttention 类中,因果掩码被应用到注意力分数矩阵中:
if attn_mask is not None:
attn_mask = attn_mask.unsqueeze(1)
atten_scores = atten_scores.masked_fill(attn_mask == 0, -1e9)attn_mask.unsqueeze(1):将掩码的形状从
(batch_size, seq_len, seq_len)扩展为(batch_size, 1, seq_len, seq_len)。
masked_fill:将掩码中为
False的位置的注意力分数设置为-1e9,确保这些位置的注意力权重趋近于0。
5. 生成诗歌时的因果掩码
在生成诗歌时,因果掩码同样被应用:
def generate_poetry(method="greedy", top_k=5):
model.eval()
with torch.no_grad():
input_ids = torch.tensor(vocab["[BOS]"]).view(1, -1)
while input_ids.shape[1] < seq_len:
output = model(input_ids, None)
probabilities = torch.softmax(output[:, -1, :], dim=-1)
if method == "greedy":
next_token_id = torch.argmax(probabilities, dim=-1)
elif method == "top_k":
top_k_probs, top_k_indices = torch.topk(probabilities[0], top_k)
next_token_id = top_k_indices[torch.multinomial(top_k_probs, 1)]
if next_token_id == vocab["[EOS]"]:
break
input_ids = torch.cat([input_ids, next_token_id.view(1, 1)], dim=1)
return input_ids.squeeze()model(input_ids, None):在生成诗歌时,输入序列
input_ids会逐渐增长,但因果掩码是隐含的,因为模型的自注意力层会自动处理序列的顺序性。生成过程中,模型只能看到当前及之前的位置,这与训练时使用因果掩码的目的相同。