题目内容

样例1
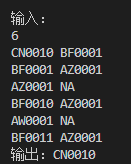

样例2
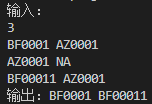

思考思路
题目让我们找出所有迭代次数最多的补丁版本,并且按字典序排列输出。迭代次数指的是从该版本到根节点的路径长度,而根节点的迭代次数是0,子节点是父节点次数+1。比如,样例1中的CN0010,它的父节点是BF0001,而BF0001的父节点是AZ0001,所以迭代次数是2次,是最大的。
首先,需要构建每个节点的深度。这里的数据结构是树,每个节点可能有多个子节点,但每个节点的父节点最多只有一个,因为题目中说过前序版本的个数<=1,且不会有环。所以可以建立一个父节点的映射,然后通过递归或者迭代的方式计算每个节点的深度。
其次,计算每个节点的深度时,需要考虑父节点的存在与否。具体来说:
1、如果一个节点的父节点是NA,那么它的迭代次数是0。
2、如果父节点存在,则迭代次数是父节点的迭代次数 +1。
3、如果父节点不存在于父节点字典中(即父节点未被记录过),那么该节点的迭代次数是1。比如某个节点的父节点是某个不在输入中的版本,即输入中有X的父节点是Y,但Y没有出现在任何行中的当前版本或者父版本的位置,那么Y不在字典中,此时X的迭代次数是1。
所以,正确的处理步骤可能是:
1、建立父节点字典:每个当前版本的父节点被记录下来。例如,parent_map[current] = predecessor.
例如,对于输入中的每一行,current和predecessor。所以,parent_map[current] = predecessor.
2、对于每个节点(即parent_map中的所有键),计算它的迭代次数(深度)。同时,对于父节点不在parent_map中的情况,也需要处理。例如,当predecessor不是NA,并且不在parent_map中时,该predecessor的父节点视为NA,所以其迭代次数是0,当前节点的次数是1。
3、如果current的父节点是NA → 深度是0.
否则,父节点是p:
如果p的父节点存在(在parent_map中),则当前深度是p的深度 +1.
如果p的父节点不存在(即p不在parent_map中),则p的父节点是NA → p的深度是0 → current的深度是0+1=1.
这样,可以用一个字典depth_cache来保存各个节点的深度,避免重复计算。
紧接着,建立父节点字典的步骤如下:
1、收集所有非NA的字符串,包括current和predecessor。
2、建立parent_map,其中对于每个current,parent_map[current] = predecessor(以current当前版本为键,predecessor前序版本为值)。predecessor可能为NA或其他字符串。
3、对于所有补丁版本中的节点,如果不在parent_map的键中,则将其父节点设置为NA,并添加到parent_map中。
然后,可以用一个字典depth来保存每个节点的深度。然后,对于每个节点s,我们遍历其父链,直到找到NA,并记录路径长度。
不过,对于树结构来说,递归或迭代都可以。但为了避免递归可能导致的栈溢出(比如树深度很大),迭代方式更安全。
所以,可以采用迭代方式,或者使用带记忆化的递归。
例如,记忆化递归:
depth_cache = {}
def get_depth(node):
if node == 'NA':
return 0
if node not in depth_cache:
# 版本树映射关系,键到值的映射赋值给predecessor
predecessor = parent_map.get(node, 'NA') # 但根据之前的处理,parent_map已经包含了所有补丁版本,所以不需要处理这种情况.
if predecessor == 'NA':
depth_cache[node] = 0
else:
depth_cache[node] = get_depth(predecessor) + 1
return depth_cache[node]
然后,对于每个补丁版本s in S:
depth = get_depth(s)
记录最大深度,并收集所有具有该深度的节点。
最后,排序后输出。
这样,可以正确计算每个节点的深度。
现在,将所有步骤综合起来,编写代码:
# 读取输入:
n = int(input()) # 接下来读取的版本行数
lines = [input().strip() for _ in range(n)]
# 收集补丁版本:
s = set() # 所有版本的集合
parent_map = {}
for line in lines:
current, predecessor = line.strip().split()
s.add(current)
if predecessor != 'NA':
s.add(predecessor)
parent_map[current] = predecessor
处理所有补丁版本,设置不在parent_map中的节点的父节点为NA:
for node in s:
if node not in parent_map:
parent_map[node] = 'NA'
# 计算每个节点的深度:
depth_cache = {}
max_depth = -1
result = []
for node in s:
d = get_depth(node)
if d > max_depth:
max_depth = d
result = [node]
elif d == max_depth:
result.append(node)
# 排序结果:
result.sort()
print(' '.join(result))
其中,get_depth函数如前所述。
算法思路
1、收集所有补丁版本:包括输入中的所有当前版本和前序版本(除去NA)。
2、建立父节点映射字典:记录每个当前版本的父节点,若父节点未在输入中出现,则其父节点设为NA。
3、计算每个节点的深度:使用递归和记忆化技术来高效计算每个节点的深度。
4、找出最大深度节点:遍历所有节点,找到深度最大的节点并排序输出。
实现代码(封装Class中)
class Solution:
from typing import List
def find_max_depth_versions(self, lines: List[str]) -> List[str]:
# 收集所有非NA的版本号
versions = set()
parent_map = {}
for line in lines:
current, predecessor = line.strip().split()
versions.add(current)
if predecessor != 'NA':
versions.add(predecessor)
parent_map[current] = predecessor
# 处理未在parent_map中的版本,设置其父节点为NA
for version in versions:
if version not in parent_map:
parent_map[version] = 'NA'
# 计算每个版本的深度
depth_cache = {}
def get_depth(node):
if node == 'NA':
return 0
if node not in depth_cache:
predecessor = parent_map[node]
depth_cache[node] = get_depth(predecessor) + 1 if predecessor != 'NA' else 0
return depth_cache[node]
max_depth = -1
result = []
for version in versions:
current_depth = get_depth(version)
if current_depth > max_depth:
max_depth = current_depth
result = [version]
elif current_depth == max_depth:
result.append(version)
# 按字典序排序
result.sort()
return result
# 示例输入
def main():
print("输入:")
# 读取输入数据
n = int(sys.stdin.readline())
lines = [sys.stdin.readline().strip() for _ in range(n)]
# 调用算法逻辑
sol = Solution()
result = sol.find_max_depth_versions(lines)
# 输出结果
print(f"输出:{' '.join(result)}")
if __name__ == "__main__":
import sys
main()
代码解释:
1、收集版本和建立父节点映射:遍历输入行,收集所有非NA的版本号,并建立每个当前版本到其前序版本的映射。
2、处理未记录的版本:对于出现在前序版本但未出现在当前版本的节点,设置其父节点为NA。
3、计算深度:使用递归和记忆化缓存来高效计算每个节点的深度。若父节点是NA,深度为0;否则递归计算父节点深度并加1。
4、找出最大深度节点:遍历所有版本,记录深度最大的节点,最后按字典序排序输出结果。