【深度学习】【目标检测】【Ultralytics-YOLO系列】YOLOV3源码整体结构解析
文章目录
前言
Ultralytics YOLO 是一系列基于 YOLO(You Only Look Once)算法的检测、分割、分类、跟踪和姿势估计模型,此前博主已经搭建完成绍Ultralytics–YOLOv人脸检测项目【Windows11下YOLOV3人脸检测】,本博文解析Ultralytics–YOLOV3源码的整体结构。
代码结构整体
核心结构部分如下图所示:
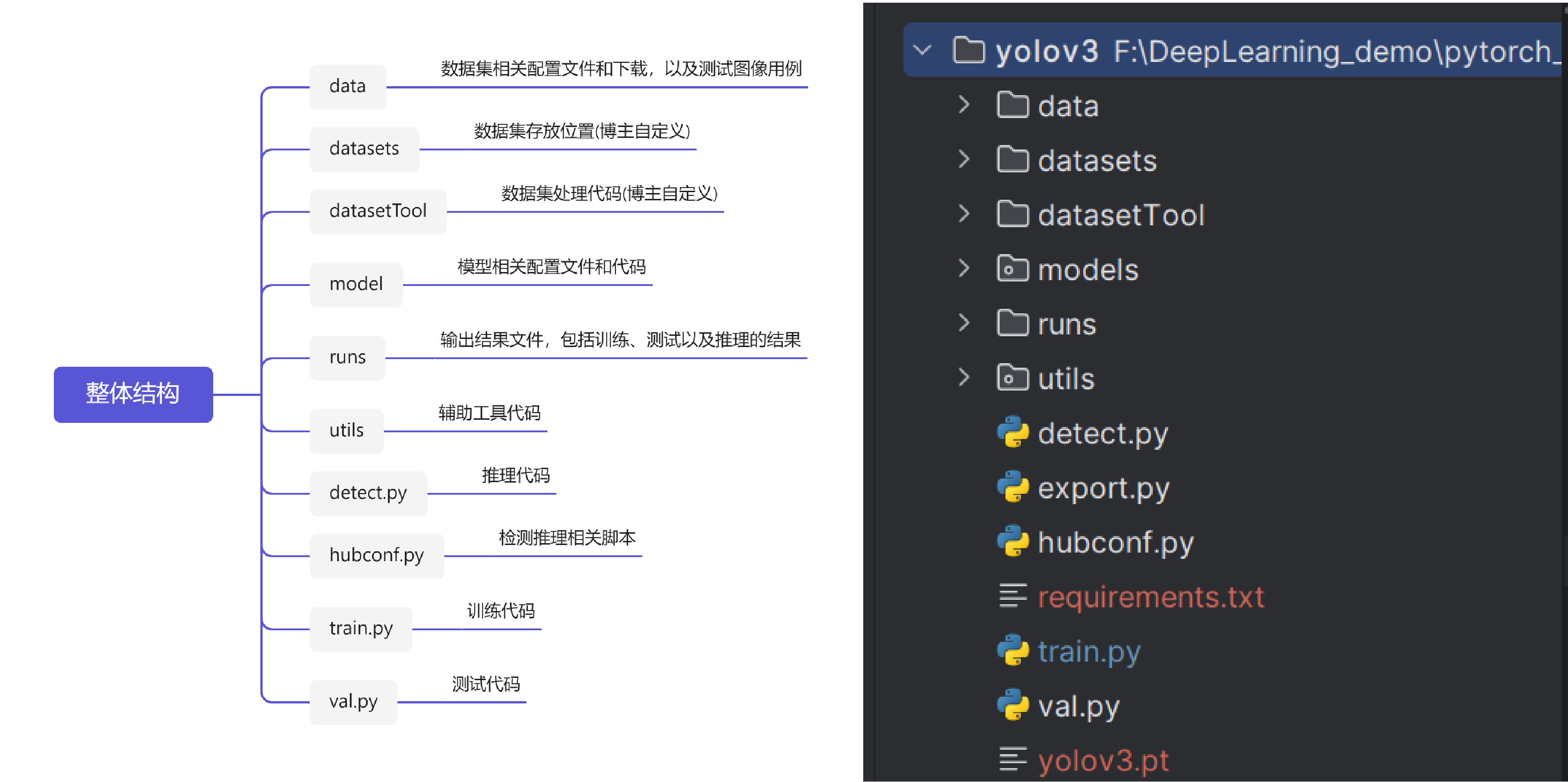
本博文不对具体的代码进行讲解,只对主要的yaml配置文件进行解析。
data文件结构

模型训练超参数配置文件解析
hyp.scratch.yaml内容解析:
################## 1、学习率相关参数 ##################
lr0: 0.01 # 学习率的初始值:通常使用SGD时为0.01,使用Adam时为0.001.
lrf: 0.1 # 学习率调度器OneCycleLR中的最终学习率(lr0 * lrf):在一个训练周期内逐步增加然后减少学习率来加速模型的收敛,有助于模型跳出局部最优解.
momentum: 0.937 # 学习率动量:记录之前梯度(方向和大小)的加权平均值并将其用于参数更新以决定当前梯度的大小和方向
weight_decay: 0.0005 # optimizer权重衰减系数5e-4:有效地限制模型复杂度,减少过拟合的风险.
warmup_epochs: 3.0 # 预热阶段:先用较小的学习率在训练初始时预热,避免出现不稳定的梯度或损失的情况.
warmup_momentum: 0.8 # 预热学习率动量
warmup_bias_lr: 0.1 # 预热学习率
################## 学习率相关参数 ####################
################### 2、损失函数相关参数 ###################
box: 0.05 # 预测边界框损失的系数(位置和尺寸)
cls: 0.5 # 分类损失的系数
cls_pw: 1.0 # 分类损失的二元交叉熵损失中正样本的权重
obj: 1.0 # 置信度损失权重
obj_pw: 1.0 # 置信度损失的二元交叉熵损失中正样本的权重
iou_t: 0.20 # Iou阈值:当预测框和真实框之间的IoU大于阈值时为检测正确,否则为检测错误.
anchor_t: 4.0 # anchor的阈值:真实框与预测框的尺寸的比例在阈值范围内为检测正确,否则为检测错误.
# anchors: 3 # anchors per output layer (0 to ignore)
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5) 通过调节因子降低容易分类样本的权重,gamma值越大模型更加关注难分类的样本.
################### 损失函数相关参数 #######################
#################### 3、数据增强相关参数 ####################
# hsv_h、hsv_s、hsv_v表示图像HSV颜色空间的色调、饱和度、明度的增强参数,取值范围都是[0, 1],值越大强度越大.
hsv_h: 0.015 # 色调
hsv_s: 0.7 # 饱和度
hsv_v: 0.4 # 明度
# degrees、translate、scale、shear表示图像旋转、平移、缩放、扭曲的增强参数
degrees: 0.0 # 旋转角度
translate: 0.1 # 水平和垂直随机平移,取值范围都是[0,1],这里允许的最大水平和垂直平移比例分别为原图宽高的0.1
scale: 0.5 # 随机缩放,图像会被随机缩放到原图大小的0.5到1之间。
shear: 0.0 # 剪切:沿着某个方向对图像进行倾斜或拉伸
# 模拟从不同的角度拍摄图像:将图像中的点映射到一个新的位置,产生类似倾斜、拉伸或压缩的效果,取值范围都是[0, 0.001].
perspective: 0.0 # 透视变换参数
# flipud、fliplr表示图像上下翻转、左右翻转的增强概率,取值范围都是[0, 1]。
flipud: 0.0 # 上下翻转
fliplr: 0.5 # 左右翻转
# mosaic、mixup、copy_paste表示选择不同方式增强训练集多样性的概率,取值范围都是[0, 1].
mosaic: 1.0 # 将四张图片拼接成一张,增强了模型对多物体的感知能力和位置估计能力
mixup: 0.0 # 对两张图片进行线性混合,增强了模型对物体形状和纹理的学习能力
copy_paste: 0.0 # 将一张图片的一部分复制到另一张图片上,增强了模型对物体的位置和尺度变化的鲁棒性。
#################### 数据增强相关参数 ######################
其他的模型训练超参数配置文件只是一些具体超参数数值上不同。
数据集配置文件解析
coco.yaml内容解析:
path: ../datasets/coco128 # 数据集源路径
train: images/train2017 # path下训练集地址,
val: images/train2017 # path下验证集地址
test: # path下测试集地址
nc: 80 # 检测的类别数量
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # 检测的类别名,避免用中文
# 数据集下载URL(可选)
download: https://ultralytics.com/assets/coco128.zip
coco128.yaml内容解释: 调用了utils中的函数,采用脚本方式下载数据集。
path: ../datasets/coco # 数据集源路径
# txt列出了训练集/验证集/测试集中的所有图像文件名或相对路径
train: train2017.txt # path下训练集地址
val: val2017.txt # path下验证集地址
test: test-dev2017.txt # path下测试集地址
nc: 80 # 检测的类别数量
names: ['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light',
'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee',
'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard',
'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple',
'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch',
'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear',
'hair drier', 'toothbrush'] # 检测的类别名,避免用中文
# 数据集下载脚本(可选)
download: |
# 导入模块utils下的函数
from utils.general import download, Path
# 下载标签
segments = False # 决定下载的标签类型(分割标签或者检测标签)
dir = Path(yaml['path']) # 指定了数据集的路径
# 构建标签下载URL
url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/' # 基础URL
urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # 下载指定标签的URL
download(urls, dir=dir.parent) # 下载标签文件
# 下载数据文件
urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
# 使用3个线程并行下载提高下载速度
download(urls, dir=dir / 'images', threads=3)
voc.yaml内容解释: 调用了utils中的函数,采用脚本方式下载数据集。
path: ../datasets/VOC # 数据集源路径
train: # path下训练集地址
- images/train2012 # YAML语法格式中 - 表示一个列表项
- images/train2007
- images/val2012
- images/val2007
val: # path下验证集地址
- images/test2007
test: # path下测试集地址
- images/test2007
nc: 20 # 检测的类别数量
names: ['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog',
'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor'] # 检测的类别名,避免用中文
# 数据集下载脚本(可选)
download: |
# 导入模块
import xml.etree.ElementTree as ET
from tqdm import tqdm
# 导入utils下的函数
from utils.general import download, Path
# 将PASCAL VOC的XML标注文件转换为YOLO格式的标注文件
def convert_label(path, lb_path, year, image_id):
# 将PASCAL VOC的边界框坐标(xmin, xmax, ymin, ymax)转换为YOLO格式的归一化的中心点坐标和宽高
def convert_box(size, box):
dw, dh = 1. / size[0], 1. / size[1]
x, y, w, h = (box[0] + box[1]) / 2.0 - 1, (box[2] + box[3]) / 2.0 - 1, box[1] - box[0], box[3] - box[2]
return x * dw, y * dh, w * dw, h * dh
# 读取XML文件
in_file = open(path / f'VOC{year}/Annotations/{image_id}.xml')
# 保存YOLO格式的.txt文件
out_file = open(lb_path, 'w')
# 并解析XML文件内容
tree = ET.parse(in_file)
root = tree.getroot()
# 获取图像的尺寸
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
# 遍历XML文件中的每个目标对象
for obj in root.iter('object'):
# 获取目标对象的类别名称
cls = obj.find('name').text
# 类别属于数据集配置文件中的内容中且不是困难样本,则进行转换
if cls in yaml['names'] and not int(obj.find('difficult').text) == 1:
# 获取目标对象的边界框信息
xmlbox = obj.find('bndbox')
# 转化为YOLO格式的归一化的中心点坐标和宽高
bb = convert_box((w, h), [float(xmlbox.find(x).text) for x in ('xmin', 'xmax', 'ymin', 'ymax')])
# 类别序号
cls_id = yaml['names'].index(cls)
# 保存数据
out_file.write(" ".join([str(a) for a in (cls_id, *bb)]) + '\n')
# 下载数据集
# 数据集存储的根目录
dir = Path(yaml['path'])
# : 需要下载的文件 URL 列表
url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
urls = [url + 'VOCtrainval_06-Nov-2007.zip', # 446MB, 5012 images
url + 'VOCtest_06-Nov-2007.zip', # 438MB, 4953 images
url + 'VOCtrainval_11-May-2012.zip'] # 1.95GB, 17126 images
# 下载urls指定的数据集
download(urls, dir=dir / 'images', delete=False)
# 转换数据集
path = dir / f'images/VOCdevkit'
# 遍历年份和数据集类型
for year, image_set in ('2012', 'train'), ('2012', 'val'), ('2007', 'train'), ('2007', 'val'), ('2007', 'test'):
# 创建对应的图像和标签文件夹
imgs_path = dir / 'images' / f'{image_set}{year}'
lbs_path = dir / 'labels' / f'{image_set}{year}'
imgs_path.mkdir(exist_ok=True, parents=True)
lbs_path.mkdir(exist_ok=True, parents=True)
# 读取每组数据集的图像ID列表
image_ids = open(path / f'VOC{year}/ImageSets/Main/{image_set}.txt').read().strip().split()
# 遍历所有图片
for id in tqdm(image_ids, desc=f'{image_set}{year}'):
# 移动图像文件到目标目录
f = path / f'VOC{year}/JPEGImages/{id}.jpg' # 旧图像路径
lb_path = (lbs_path / f.name).with_suffix('.txt') # 新图像路径
f.rename(imgs_path / f.name) # 移动图像
convert_label(path, lb_path, year, id) # 生成YOLO格式的标签文件
其他的数据集配置文件基本结构都与这三种相似,除了下载数据集脚本略微不同。
models文件结构
网络模型配置文件yolov3.yaml内容解析:
nc: 80 # 模型识别的类别数量
# 通过以下两个参数就可以实现不同复杂度的模型设计(原本Joseph Redmon的YOLOV3版本没有以下俩个参数的)
depth_multiple: 1.0 # 模型深度系数:卷积模块的缩放因子,原始模型的所有模块乘以缩放因子,得到当前模型的模块数
width_multiple: 1.0 # 模型通道系数:卷积层通道的缩放因子,backbone和head中所有卷积层的通道数乘以缩放因子得到,得到当前模型的所有卷积层的新通道数
# 初始化了9个anchors,在3个检测头中中使用,每个检测头对应的特征图中,每个网格单元都有3个anchor进行预测
anchors: # 以下3组anchors不能保证适用于所有的数据集
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# darknet53 主干网络
backbone:
# [from, number, module, args]
# from表示当前模块的输入来自那一层的输出,-1表示来自上一层的输出.
# number表示本模块的理论重复次数,实际的重复次数:number×depth_multiple.
# module表示模块名,通过模块名在common.py中寻找相应的类完成模块化的搭建网络.
# args表示模块搭建所需参数的列表,包括channel,kernel_size,stride,padding,bias等.
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Bottleneck, [64]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 2, Bottleneck, [128]],
[-1, 1, Conv, [256, 3, 2]], # 5-P3/8
[-1, 8, Bottleneck, [256]],
[-1, 1, Conv, [512, 3, 2]], # 7-P4/16
[-1, 8, Bottleneck, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 9-P5/32
[-1, 4, Bottleneck, [1024]], # 10
]
# 检测头(包含了neck模块)
head:
# [from, number, module, args] 同理
[[-1, 1, Bottleneck, [1024, False]],
[-1, 1, Conv, [512, [1, 1]]],
[-1, 1, Conv, [1024, 3, 1]],
[-1, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [1024, 3, 1]], # 15 (P5/32-large)
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 8], 1, Concat, [1]], # cat backbone P4
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Bottleneck, [512, False]],
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [512, 3, 1]], # 22 (P4/16-medium)
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P3
[-1, 1, Bottleneck, [256, False]],
[-1, 2, Bottleneck, [256, False]], # 27 (P3/8-small)
[[27, 22, 15], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
模型配置文件与模型结构图的对应关系如下图所示:
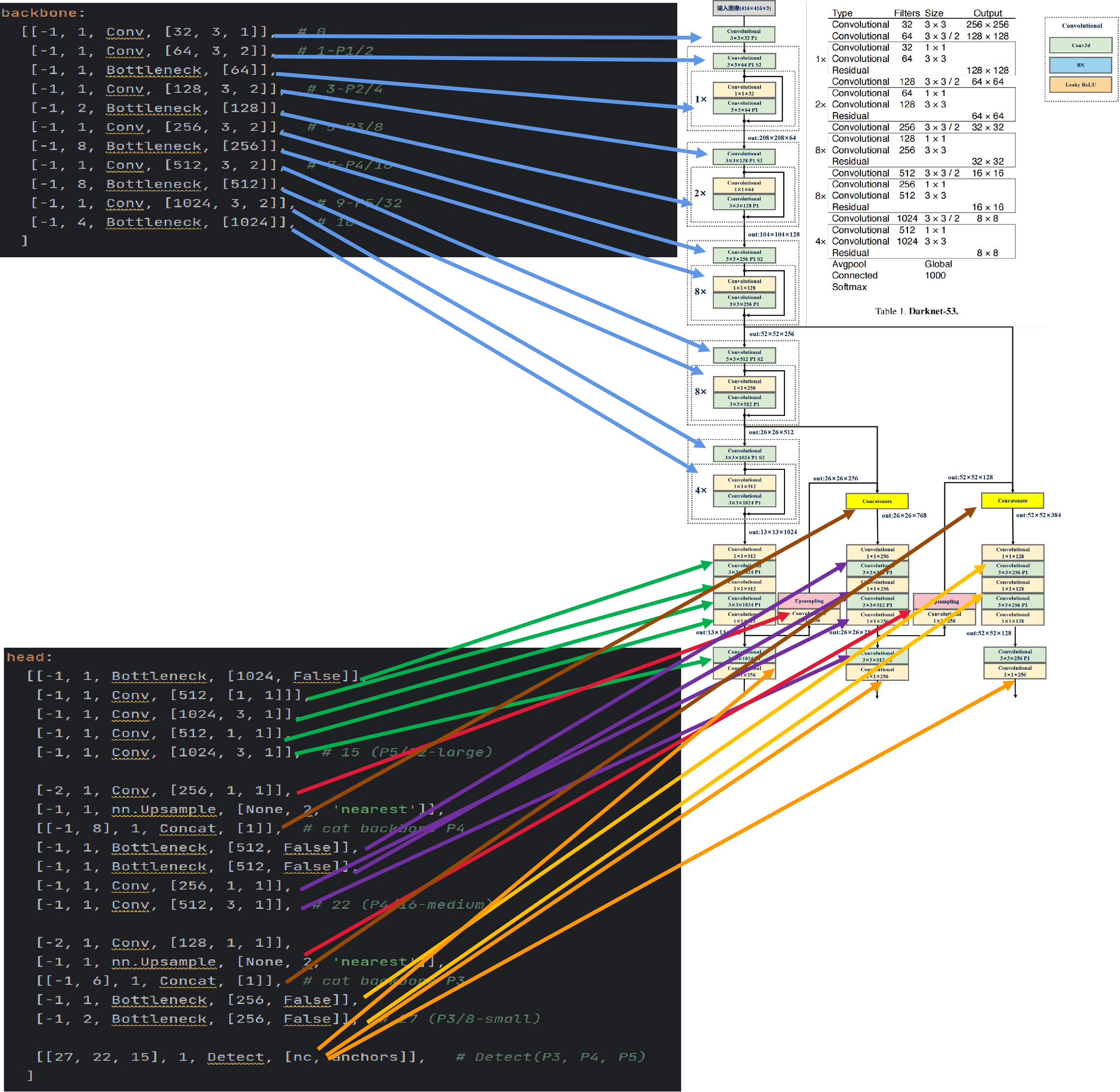
这里注意一个点,Bottleneck是2个卷积层组成:1×1卷积层和3×3卷积层,所以在head配置部分与模型结构图的对应有点差异,即模型结构图展现了1×1卷积层和3×3卷积层,但是在head配置部分用Bottleneck代替了。
其他网络模型配置文件基本与yolov3.yaml相似。
utils文件结构
功能性代码部分,在使用到这部分代码时候再详细讲解内容。
runs文件结构
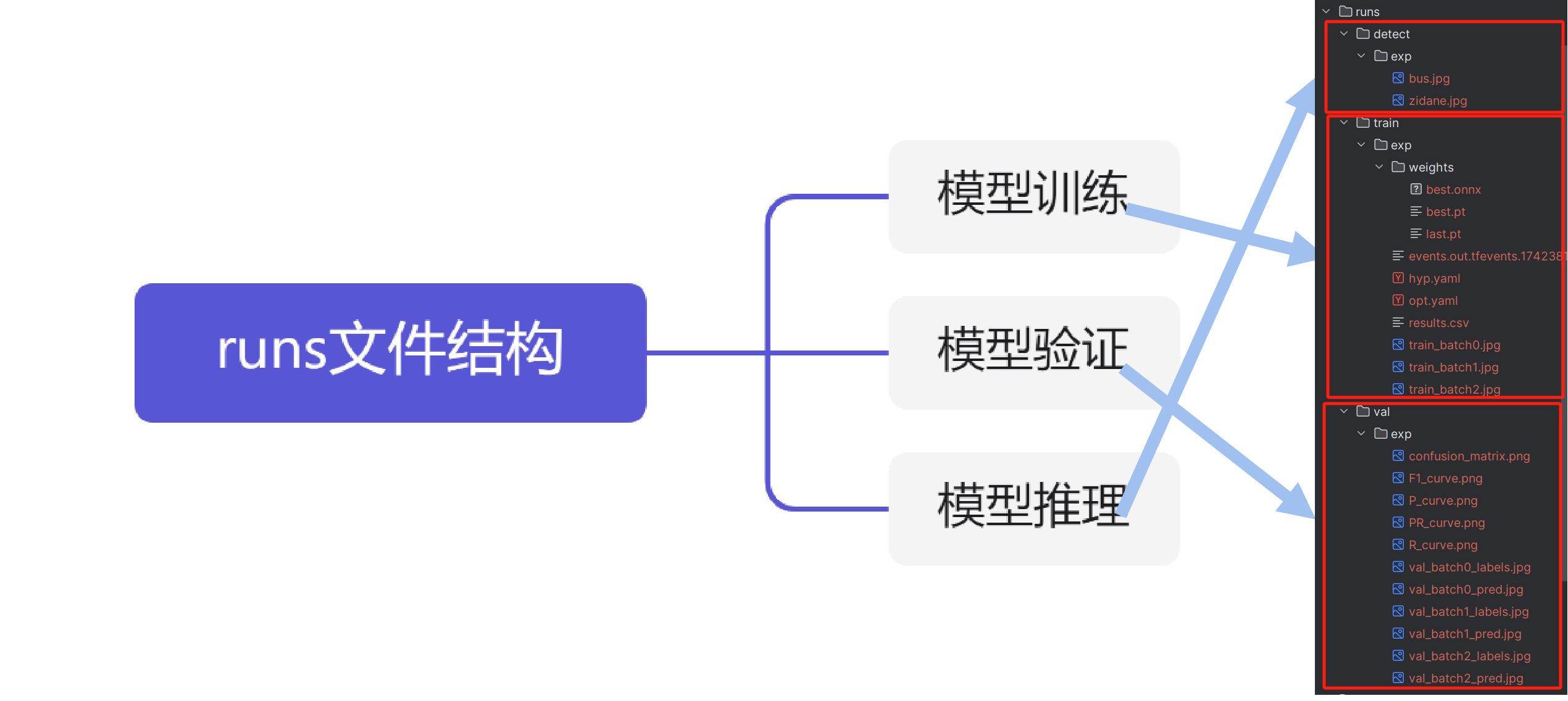
执行训练、验证和推理三个不同阶段都会得出相应的输出结果,具体输出的含义在后续不同阶段内容时候详细讲解。
总结
尽可能简单、详细的介绍了YOLOV3源码整体结构解析。后续会根据自己学到的知识结合个人理解讲解YOLOV3的每个阶段的详细代码。