TCP

TCP三次握手
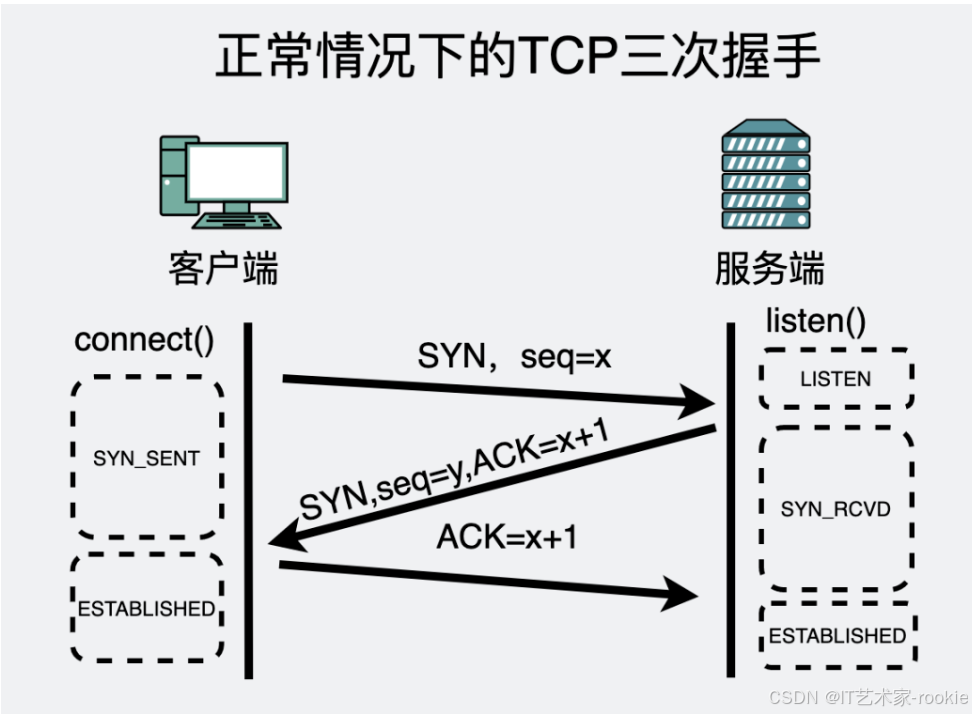
在服务端启动好后会调用 listen() 方法,进入到 LISTEN 状态,然后静静等待客户端的连接请求到来。
而此时客户端主动调用 connect(IP地址) ,就会向某个IP地址发起第一次握手,会先建立个半连接,发送SYN 到目的服务器,这时候需要有个地方可以暂存这些半连接。这个地方就叫半连接队列。服务器在收到第一次握手后就会响应客户端,这是第二次握手。
- 半连接队列(SYN队列),是个
哈希表。服务端收到第一次握手后,会将sock加入到这个队列中,队列内的sock都处于SYN_RECV 状态。
客户端在收到第二次握手的消息后,响应服务的一个ACK,这算第三次握手,此时客户端 就会进入 ESTABLISHED状态,半连接就会升级为全连接,认为连接已经建立完成。然后全连接暂存到另外一个叫全连接队列的地方,坐等程序执行accept()方法将其取走使用。
- 全连接队列(ACCEPT队列),
是个链表。在服务端收到第三次握手后,会将半连接队列的sock取出,放到全连接队列中。队列里的sock都处于 ESTABLISHED状态。这里面的连接,就等着服务端执行accept()后被取出了。执行accept()只是为了从全连接队列里取出一条连接。
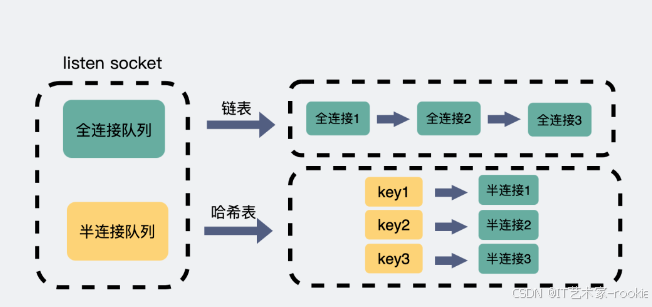
为什么半连接队列要设计成哈希表?
先对比下全连接里队列,他本质是个链表,因为也是
线性结构,说它是个队列也没毛病。它里面放的都是已经建立完成的连接,这些连接正等待被取走。而服务端取走连接的过程中,并不关心具体是哪个连接,只要是个连接就行,所以直接从队列头取就行了。这个过程算法复杂度为O(1)。
而半连接队列却不太一样,因为队列里的都是不完整的连接,嗷嗷等待着第三次握手的到来。那么现在有一个第三次握手来了,则需要从队列里
把相应IP端口的连接取出,如果半连接队列还是个链表,那我们就需要依次遍历,才能拿到我们想要的那个连接,算法复杂度就是O(n)。而如果将半连接队列设计成哈希表,那么查找半连接的算法复杂度就回到O(1)了。
怎么观察两个队列的大小
查看全连接队列
# ss -lnt
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 127.0.0.1:46269 *:*
通过ss -lnt命令,可以看到全连接队列的大小,其中Send-Q是指全连接队列的最大值,可以看到我这上面的最大值是128;Recv-Q是指当前的全连接队列的使用值,我这边用了0个,也就是全连接队列里为空,连接都被取出来了。当上面Send-Q和Recv-Q数值很接近的时候,那么全连接队列可能已经满了。可以通过下面的命令查看是否发生过队列溢出。
是队列就有长度,有长度就有可能会满,如果它们满了,那新来的包就会被丢弃。
可以通过下面的方式查看是否队列溢出。这个查看到的是历史发生过的次数
# 全连接队列溢出次数
# netstat -s | grep overflowed
4343 times the listen queue of a socket overflowed
# 半连接队列溢出次数
# netstat -s | grep -i "SYNs to LISTEN sockets dropped"
109 times the listen queue of a socket overflowed
如果配合使用watch -d 命令,可以自动每2s间隔执行相同命令,还能高亮显示变化的数字部分,如果溢出的数字不断变多,说明正在发生溢出的行为。
# watch -d 'netstat -s | grep overflowed'
Every 2.0s: netstat -s | grep overflowed Fri Sep 17 09:00:45 2021
4343 times the listen queue of a socket overflowed
查看半连接队列
半连接队列没有命令可以直接查看到,但因为半连接队列里,放的都是SYN_RECV 状态的连接,那可以通过统计处于这个状态的连接的数量,间接获得半连接队列的长度。
可以替换成自己想要查看的IP端口
# netstat -nt | grep -i '127.0.0.1:8080' | grep -i 'SYN_RECV' | wc -l
0
当队列里的半连接不断增多,最终也是会发生溢出,可以通过下面的命令查看。
同样建议配合watch -d 命令使用。
# netstat -s | grep -i "SYNs to LISTEN sockets dropped"
26395 SYNs to LISTEN sockets dropped
全连接队列满了会怎样?
如果队列满了,服务端还收到客户端的第三次握手ACK,默认当然会丢弃这个ACK。但除了丢弃之外,还有一些附带行为,这会受 tcp_abort_on_overflow 参数的影响。
# cat /proc/sys/net/ipv4/tcp_abort_on_overflow
0
- tcp_abort_on_overflow设置为 0,全连接队列满了之后,会丢弃这个第三次握手ACK包,并且开启定时器,重传第二次握手的SYN+ACK,如果重传超过一定限制次数,还会把对应的半连接队列里的连接给删掉。
- tcp_abort_on_overflow设置为 1,全连接队列满了之后,就直接发RST给客户端,效果上看就是连接断了。
半连接队列要是满了会怎么样
一般是丢弃,但这个行为可以通过 tcp_syncookies 参数去控制。但比起这个,更重要的是先了解下半连接队列为什么会被打满。
如果半连接都满了,说明服务端疯狂收到第一次握手请求,可能遇到了SYN Flood攻击。
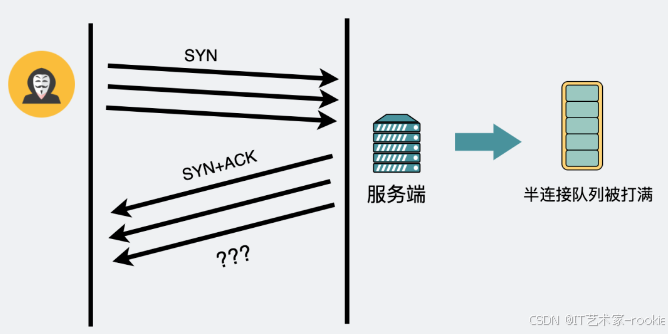
有一种方法可以绕过半连接队列
# cat /proc/sys/net/ipv4/tcp_syncookies
1
当它被设置为1的时候,客户端发来第一次握手SYN时,服务端不会将其放入半连接队列中,而是直接生成一个cookies,这个cookies会跟着第二次握手,发回客户端。客户端在发第三次握手的时候带上这个cookies,服务端验证到它就是当初发出去的那个,就会建立连接并放入到全连接队列中。可以看出整个过程不再需要半连接队列的参与。
实际上cookies并不会有一个专门的队列保存,它是通过通信双方的IP地址端口、时间戳、MSS等信息进行实时计算的,保存在TCP报头的seq里。
当服务端收到客户端发来的第三次握手包时,会通过seq还原出通信双方的IP地址端口、时间戳、MSS,验证通过则建立连接。
cookies方案为什么不直接取代半连接队列?
- 因为服务端并不会保存连接信息,所以如果传输过程中数据包丢了,也不会重发第二次握手的信息。
- 编码解码cookies,都是比较
耗CPU的,利用这一点,如果此时攻击者构造大量的第三次握手包(ACK包),同时带上各种瞎编的cookies信息,服务端收到ACK包后以为是正经cookies,憨憨地跑去解码(耗CPU),最后发现不是正经数据包后才丢弃。这种通过构造大量ACK包去消耗服务端资源的攻击,叫ACK攻击,受到攻击的服务器可能会因为CPU资源耗尽导致没能响应正经请求。
没有listen,为什么还能建立连接
那既然没有accept方法能建立连接,那是不是没有listen方法,也能建立连接?是的,客户端是可以自己连自己的形成连接(TCP自连接),也可以两个客户端同时向对方发出请求建立连接(TCP同时打开),这两个情况都有个共同点,就是没有服务端参与,也就是没有listen,就能建立连接。
那么客户端会有半连接队列吗?
显然没有,因为客户端没有执行listen,因为半连接队列和全连接队列都是在执行listen方法时,内核自动创建的。但内核还有个全局hash表,可以用于存放sock连接的信息。这个全局hash表其实还细分为ehash,bhash和listen_hash等,但因为过于细节,大家理解成有一个全局hash就够了,在TCP自连接的情况中,客户端在connect方法时,最后会将自己的连接信息放入到这个全局hash表中,然后将信息发出,消息在经过回环地址重新回到TCP传输层的时候,就会根据IP端口信息,再一次从这个全局hash中取出信息。于是握手包一来一回,最后成功建立连接。TCP同时打开的情况也类似,只不过从一个客户端变成了两个客户端而已。
四次握手
TCP同时打开
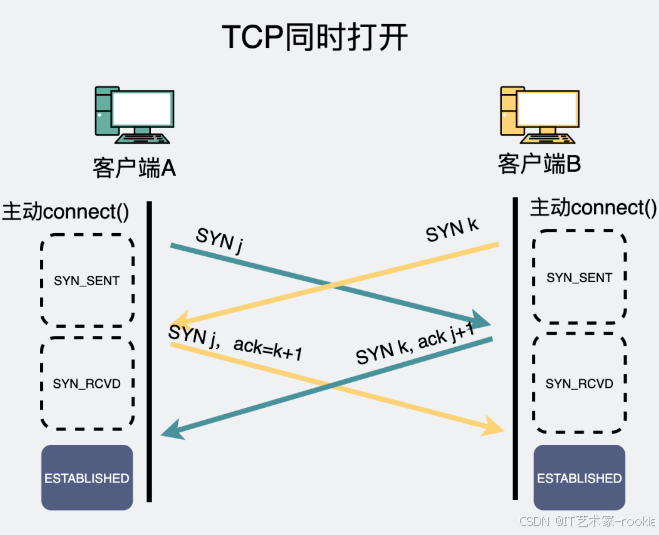
复现TCP同时打开分别在两个控制台下,分别执行下面两行命令。
while true; do nc -p 2224 127.0.0.1 2223 -v;done
while true; do nc -p 2223 127.0.0.1 2224 -v;done
上面两个命令的含义也比较简单,两个客户端互相请求连接对方的端口号,如果失败了则不停重试。执行后看到的现象是,一开始会疯狂失败,重试。一段时间后,连接建立完成。
# netstat -an | grep 2223
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 127.0.0.1:2224 127.0.0.1:2223 ESTABLISHED
tcp 0 0 127.0.0.1:2223 127.0.0.1:2224 ESTABLISHED
只有两个客户端,没有listen() ,为什么能建立TCP连接?
Socket 缓冲区
对于TCP,我们一般使用下面的方式创建socket。sockfd=socket(AF_INET,SOCK_STREAM, 0))
返回的sockfd是socket的句柄id,用于在整个操作系统中唯一标识你的socket是哪个,可以理解为socket的身份证id。创建socket时,操作系统内核会顺带为socket创建一个发送缓冲区和一个接收缓冲区。分别用于在发送和接收数据的时候给暂存一下数据。
用户发送消息的时候写给 send buffer(发送缓冲区)
用户接收消息的时候写给 recv buffer(接收缓冲区)
也就是说一个socket ,会带有两个缓冲区,一个用于发送,一个用于接收。因为这是个先进先出的结构,有时候也叫它们发送、接收队列。

观察 socket 缓冲区
在linux环境下执行 netstat -nt 命令。
# netstat -nt
Active Internet connections (w/o servers)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 60 172.22.66.69:22 122.14.220.252:59889 ESTABLISHED
这上面表明了,这里有一个协议(Proto)类型为 TCP 的连接,同时还有本地(Local Address)和远端(Foreign Address)的IP信息,状态(State)是已连接。还有Send-Q 是发送缓冲区,下面的数字60是指,当前还有60 Byte在发送缓冲区中未发送。而 Recv-Q 代表接收缓冲区, 此时是空的,数据都被应用进程接收干净了。
在用户进程中,程序通过操作 socket 会从用户态进入内核态,而 send方法会将数据一路传到传输层。在识别到是 TCP协议后,会调用 tcp_sendmsg 方法。
写数据tcp_sendmsg() 函数
// net/ipv4/tcp.c
int tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t size)
{
// 加锁
lock_sock(sk);
// ... 拷贝到发送缓冲区的相关操作
// 解锁
release_sock(sk);
}
从tcp_sendmsg的代码中可以看到,在对socket的缓冲区执行写操作的时候,linux内核已经自动帮我们加好了锁,也就是说,是线程安全的。
但是也不可以多线程不加锁并发写入数据,因为锁的粒度其实是每次"写操作",但每次写操作并不保证能把消息写完整,从而有消息体乱序的问题。
在 tcp_sendmsg 中, 核心工作就是将待发送的数据组织按照先后顺序放入到发送缓冲区中, 然后根据实际情况(比如拥塞窗口等)判断是否要发数据。如果不发送数据,那么此时直接返回。
读数据tcp_recvmsg函数
/ net/ipv4/tcp.c
int tcp_recvmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,
size_t len, int nonblock, int flags, int *addr_len)
{
// 加锁
lock_sock(sk);
// ... 将数据从接收缓冲区拷贝到用户缓冲区
// 释放锁
release_sock(sk);
}
读socket其实也是加锁了的,所以并发多线程读socket这件事是线程安全的。
但就算是线程安全,也不代表你可以用多个线程并发去读。因为这个锁,只保证你在读socket 接收缓冲区时,只有一个线程在读,但并不能保证你每次的时候,都能正好读到完整消息体后才返回。所以虽然并发读不报错,但每个线程拿到的消息肯定都不全,因为锁的粒度并不保证能读完完整消息。
如果发送缓冲区空间不足,或者满了,执行发送,会怎么样?
socket在创建的时候,是可以设置是阻塞的还是非阻塞的。
- 非阻塞
如果此时 socket 是非阻塞的,程序就会立刻返回一个 EAGAIN 错误信息,意思是 Try again , 现在缓冲区满了,你也别等了,待会再试一次。 - 阻塞
如果此时 socket 是阻塞的,那么程序会在那干等、死等,直到释放出新的缓存空间,就继续把数据拷进去,然后返回。
如果接收缓冲区为空,执行 recv 会怎么样?
- 非阻塞
如果此时 socket 是非阻塞的,程序就会立刻返回一个 EAGAIN 错误信息。 - 阻塞
如果此时 socket 是阻塞的,那么程序会在那干等,直到接收缓冲区有数据,就会把数据从接收缓冲区拷贝到用户缓冲区,然后返回。

如果socket缓冲区还有数据,执行close了,会怎么样?
那么正常情况下,如果 socket 缓冲区为空,执行 close。就会触发四次挥手
如果接收缓冲区还有数据未读,会先把接收缓冲区的数据清空,然后给对端发一个RST。
丢包
建立连接时丢包
半连接队列或者全连接队列长度满了。
流量控制丢包【qdisc(Queueing Disciplines,排队规则)】
流量控制机制
可以通过下面的ifconfig命令查看到,里面涉及到的txqueuelen后面的数字1000,其实就是流控队列的长度。当发送数据过快,流控队列长度txqueuelen又不够大时,就容易出现丢包现象。
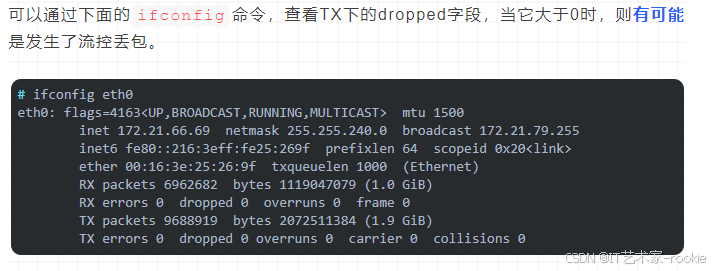
可以尝试修改下流控队列的长度。比如像下面这样将eth0网卡的流控队列长度从1000提升为1500.
# ifconfig eth0 txqueuelen 1500
网卡丢包
RingBuffer过小导致丢包
在接收数据时,会将数据暂存到RingBuffer接收缓冲区中,然后等着内核触发软中断慢慢收走。如果这个缓冲区过小,而这时候发送的数据又过快,就有可能发生溢出,此时也会产生丢包。
我们可以通过下面的命令去查看是否发生过这样的事情。
查看overruns指标,它记录了由于RingBuffer长度不足导致的溢出次数。
# ifconfig
eth0: RX errors 0 dropped 0 overruns 0 frame 0

上面的输出内容,含义是RingBuffer最大支持4096的长度,但现在实际只用了1024。
想要修改这个长度可以执行ethtool -G eth1 rx 4096 tx 4096将发送和接收RingBuffer的长度都改为4096。RingBuffer增大之后,可以减少因为容量小而导致的丢包情况。
网卡性能不足
网卡作为硬件,传输速度是有上限的。当网络传输速度过大,达到网卡上限时,就会发生丢包。这种情况一般常见于压测场景。
我们可以通过ethtool加网卡名,获得当前网卡支持的最大速度。
# ethtool eth0
Settings for eth0:
Speed: 10000Mb/s
可以看到,我这边用的网卡能支持的最大传输速度speed=1000Mb/s。也就是俗称的千兆网卡,但注意这里的单位是Mb,这里的b是指bit,而不是Byte。1Byte=8bit。所以10000Mb/s还要除以8,也就是理论上网卡最大传输速度是1000/8 = 125MB/s。
我们可以通过sar命令从网络接口层面来分析数据包的收发情况。
# sar -n DEV 1
Linux 3.10.0-1127.19.1.el7.x86_64 2022年07月27日 _x86_64_ (1 CPU)
08时35分39秒 IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
08时35分40秒 eth0 6.06 4.04 0.35 121682.33 0.00 0.00 0.00
其中 txkB/s是指当前每秒发送的字节(byte)总数,rxkB/s是指每秒接收的字节(byte)总数。
当两者加起来的值约等于12~13w字节的时候,也就对应大概125MB/s的传输速度。此时达到网卡性能极限,就会开始丢包。
遇到这个问题,优先看下你的服务是不是真有这么大的真实流量,如果是的话可以考虑下拆分服务,或者就忍痛充钱升级下配置吧。
接收缓冲区丢包
这两个缓冲区是有大小限制的,可以通过下面的命令去查看。
# 查看接收缓冲区
# sysctl net.ipv4.tcp_rmem
net.ipv4.tcp_rmem = 4096 87380 6291456
# 查看发送缓冲区
# sysctl net.ipv4.tcp_wmem
net.ipv4.tcp_wmem = 4096 16384 4194304
不管是接收缓冲区还是发送缓冲区,都能看到三个数值,分别对应缓冲区的最小值,默认值和最大值 (min、default、max)。缓冲区会在min和max之间动态调整。
如果缓冲区设置过小会怎么样?
当接受缓冲区满了,事情就不一样了,它的TCP接收窗口会变为0,也就是所谓的零窗口,并且会通过数据包里的win=0,告诉发送端,“球球了,顶不住了,别发了”。一般这种情况下,发送端就该停止发消息了,但如果这时候确实还有数据发来,就会发生丢包。
我们可以通过下面的命令里的TCPRcvQDrop查看到有没有发生过这种丢包现象。
cat /proc/net/netstat
TcpExt: SyncookiesSent TCPRcvQDrop SyncookiesFailed
TcpExt: 0 157 60116
我们一般也看不到这个TCPRcvQDrop,因为这个是5.9版本里引入的打点,而我们的服务器用的一般是2.x~3.x左右版本。你可以通过下面的命令查看下你用的是什么版本的linux内核。
# cat /proc/version
Linux version 3.10.0-1127.19.1.el7.x86_64
两端之间的网络丢包
前面提到的是两端机器内部的网络丢包,除此之外,两端之间那么长的一条链路都属于外部网络,这中间有各种路由器和交换机还有光缆啥的,丢包也是很经常发生的。这些丢包行为发生在中间链路的某些个机器上,我们当然是没权限去登录这些机器。但我们可以通过一些命令观察整个链路的连通情况。
ping命令查看丢包
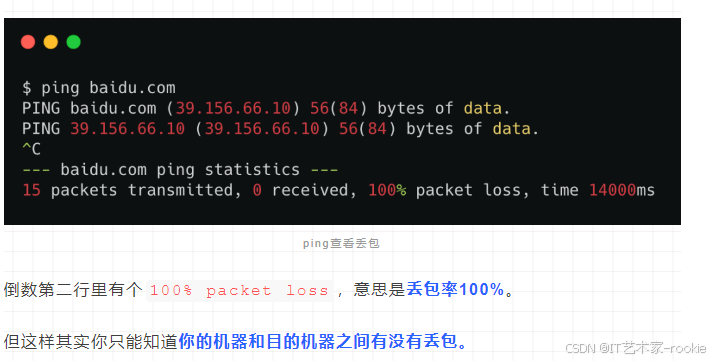
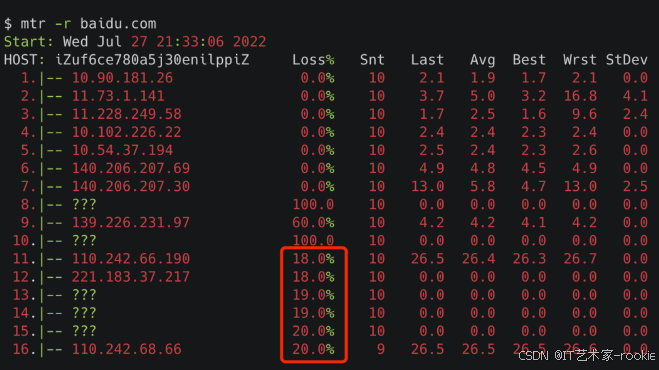
mtr命令(想知道你和目的机器之间的这条链路,哪个节点丢包了)
mtr命令可以查看到你的机器和目的机器之间的每个节点的丢包情况。
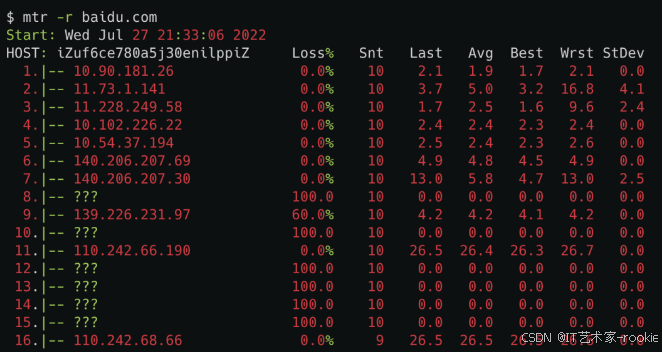
其中-r是指report,以报告的形式打印结果。
可以看到Host那一列,出现的都是链路中间每一跳的机器,Loss的那一列就是指这一跳对应的丢包率。
需要注意的是,中间有一些是host是???,那个是因为mtr默认用的是ICMP包,有些节点限制了ICMP包,导致不能正常展示。我们可以在mtr命令里加个-u,也就是使用udp包,就能看到部分???对应的IP。
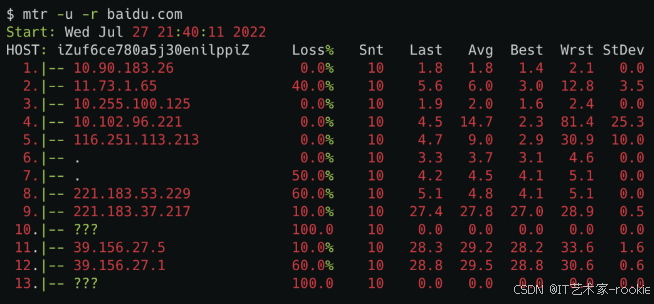
还有个小细节,Loss那一列,我们在icmp的场景下,关注最后一行,如果是0%,那不管前面loss是100%还是80%都无所谓,那些都是节点限制导致的虚报。但如果最后一行是20%,再往前几行都是20%左右,那说明丢包就是从最接近的那一行开始产生的,长时间是这样,那很可能这一跳出了点问题。如果是公司内网的话,你可以带着这条线索去找对应的网络同事。如果是外网的话,那耐心点等等吧,别人家的开发会比你更着急。
TCP只保证传输层的消息可靠性,并不保证应用层的消息可靠性。如果我们还想保证应用层的消息可靠性,就需要应用层自己去实现逻辑做保证。
重传机制(可靠性)
但重传这件事本身对性能影响是比较严重的,TCP就需要思考有没有办法可以尽量避免重传。
因为数据发送方和接收方处理数据能力可能不同,因此如果可以根据双方的能力去调整发送的数据量就好了,于是就有了发送和接收窗口,基本上从名字就能看出它的作用,接收窗口的大小就是指,接收方当前能接收的数据量大小,发送窗口的大小就指发送方当前能发的数据量大小。TCP根据窗口的大小去控制自己发送的数据量,这样就能大大减少丢包的概率。
怎么降低重传的概率
滑动窗口机制
接收方的接收到数据之后,会不断处理,处理能力也不是一成不变的,有时候处理的快些,那就可以收多点数据,处理的慢点那就希望对方能少发点数据。毕竟发多了就有可能处理不过来导致丢包,丢包会导致重传,这可是下下策。因此我们需要动态的去调节这个接收窗口的大小,于是就有了滑动窗口机制。
流量控制和滑动窗口机制貌似很像,它们之间是啥关系?我总结一下。其实现在TCP是通过滑动窗口机制来实现流量控制机制的。
拥塞控制机制
有时候发生丢包,并不是因为发送方和接收方的处理能力问题导致的。而是跟网络环境有关。
TCP会先慢慢试探的发数据,不断加码数据量,越发越多,先发一个,再发2个,4个…。直到出现丢包,这样TCP就知道现在当前网络大概吃得消几个包了,这既是所谓的拥塞控制机制。
流量控制针对的是单个连接数据处理能力的控制,拥塞控制针对的是整个网络环境数据处理能力的控制。
分段机制(重传这个事情就是无法避免的,那如果确实发生了,有没有办法降低它带来的影响呢?)
当我们需要发送一个超大的数据包时,如果这个数据包丢了,那就得重传同样大的数据包。但如果我能将其分成一小段一小段,那就算真丢了,那我也就只需要重传那一小段就好了,大大减小了重传的压力,这就是TCP的分段机制。
MSS(Maximum Segment Size)(传输层)
数据包长度大于MSS则会分成N个小于等于MSS的包。
MTU(Maximum Transmit Unit)(网络层)
一般情况下,MSS=MTU-40Byte,所以TCP分段后,到了IP层大概率就不会再分片了。
乱序重排机制
既然数据包会被分段,链路又这么复杂还会丢包,那数据包乱序也就显得不奇怪了。依靠数据包的sequence,接收方就能知道数据包的先后顺序。
后发的数据包先到是吧,那就先放到专门的乱序队列中,等数据都到齐后,重新整理好乱序队列的数据包顺序后再给到用户,这就是乱序重排机制。
连接机制
TCP通过上面提到的各种机制实现了数据的可靠性。这些机制背后是通过一个个数据结构来实现的逻辑。而为了实现这套逻辑,操作系统内核需要在两端代码里维护一套复杂的状态机(三次握手,四次挥手,RST,closing等异常处理机制),这套状态机其实就是所谓的"连接"。这其实就是TCP的连接机制,而UDP用不上这套状态机,因此它是"无连接"的。
用UDP就一定比用TCP快吗?
正因为没有这些复杂的TCP可靠性机制,所以我很快啊
对于UDP+重传的场景,如果要传超大数据包,并且没有实现分段机制的话,那数据就会在IP层分片,一旦丢包,那就需要重传整个超大数据包。而TCP则不需要考虑这个,内部会自动分段,丢包重传分段就行了。这种场景下,其实TCP更快。
TCP四次挥手
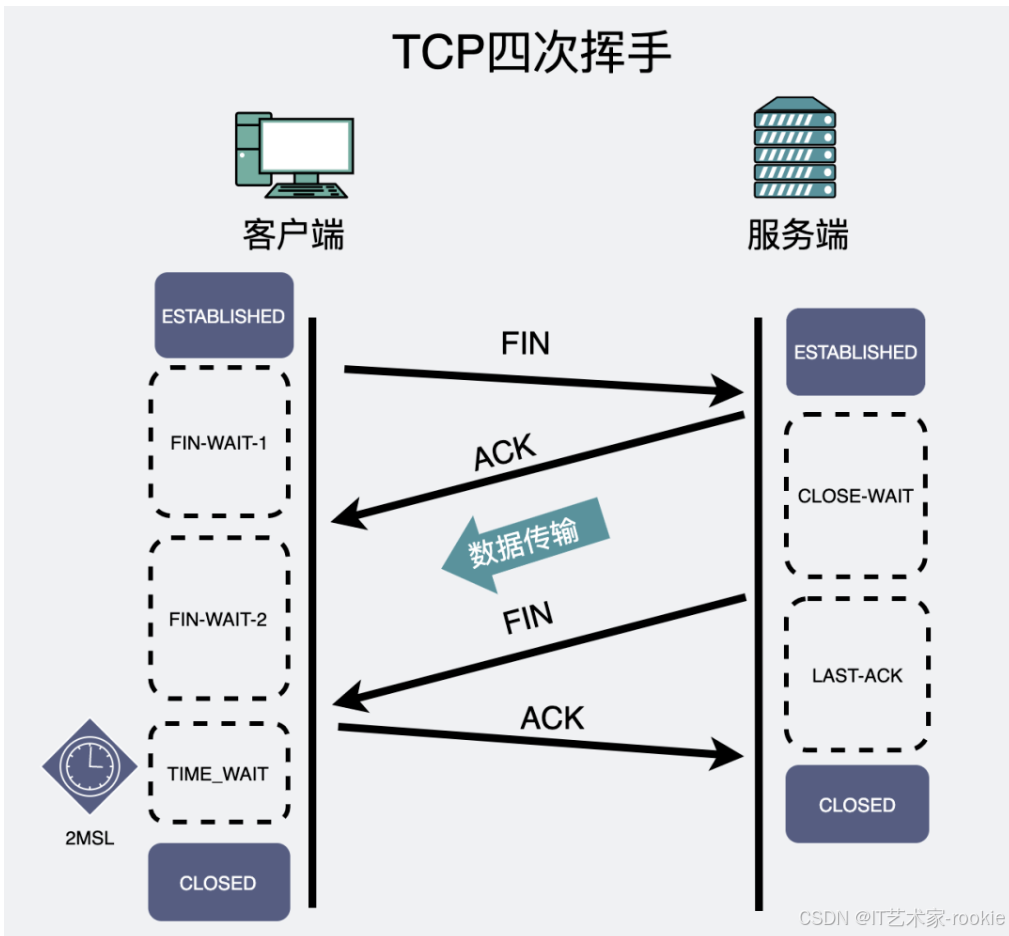
正常情况下。只要数据传输完了,不管是客户端还是服务端,都可以主动发起四次挥手,释放连接。
- 第一次挥手:一般情况下,主动方执行
close()或shutdown()方法,会发个FIN报文出来,表示"我不再发送数据了"。 - 第二次挥手:在收到主动方的FIN报文后,被动方立马
回应一个ACK,意思是"我收到你的FIN了,也知道你不再发数据了"。上面提到的是主动方不再发送数据了。但如果这时候,被动方还有数据要发,那就继续发。
注意,虽然第二次和第三次挥手之间,被动方是能发数据到主动方的,但主动方能不能正常收就不一定了,这个待会说。 - 第三次挥手:在被动方在感知到第二次挥手之后,会做了一系列的收尾工作,最后也调用一个 close(), 这时候就会发出
第三次挥手的 FIN-ACK。 - 第四次挥手:主动方回一个ACK,意思是收到了。其中
第一次挥手和第三次挥手,都是我们在应用程序中主动触发的(比如调用close()方法),也就是我们平时写代码需要关注的地方。第二和第四次挥手,都是内核协议栈自动帮我们完成的,我们写代码的时候碰不到这地方,因此也不需要太关心。
连一个 IP 不存在的主机时,握手过程是怎样的
局域网内
这里可以使用golang写一个连接TCP的程序,然后抓包
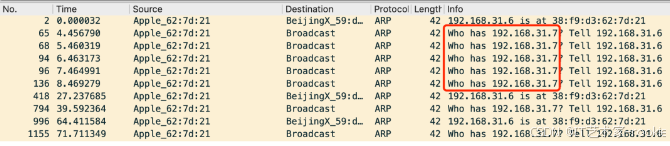
为什么会发ARP请求?
应用层执行connect过后,会通过socket层,操作系统接口,进程会从用户态进入到内核态,此时进入 传输层,因为是TCP第一次握手,会加入TCP头,且置SYN标志。
然后进入网络层,我想要连的是 192.168.31.7 ,虽然它是我瞎编的,但IP头还是得老老实实把它加进去。
重点介绍的是邻居子系统,它在网络层和数据链路层之间。可以通过ARP协议将目的IP转为对应的MAC地址,然后数据链路层就可以用这个MAC地址组装帧头。
- 先到本地ARP表查一下有没有 192.168.31.7 对应的 mac地址,有的话就返回,这里显然是不可能会有的。
可以通过 arp -a 命令查看本机的 arp表都记录了哪些信息
$ arp -a
? (192.168.31.1) at 88:c1:97:59:d1:c3 on en0 ifscope [ethernet]
? (224.0.0.251) at 1:0:4e:0:1:fb on en0 ifscope permanent [ethernet]
? (239.255.255.250) at 1:0:3e:7f:ff:fb on en0 ifscope permanent [ethernet]
看下 192.168.31.7 跟本机IP 192.168.31.6
在不在一个局域网下。如果在的话,就在局域网内发一个 arp 广播,内容就是 前面提到的 “谁是 192.168.31.7,告诉一下 192.168.31.6”。如果目的IP跟本机IP
不在同一个局域网下,那么会去获取默认网关的MAC地址,这里就是指获取家用路由器的MAC地址。然后把消息发给家用路由器,让路由器发到互联网,找到下一跳路由器,一跳一跳的发送数据,直到把消息发到目的IP上,又或者找不到目的地最终被丢弃,这种情况会有第一次握手。第2和第3点都是
本地没有查到 ARP 缓存记录的情况,这时候会把SYN报文放进一个队列(叫unresolved_queue)里暂存起来,然后发起ARP请求;等ARP层收到ARP回应报文之后,会再从缓存中取出 SYN 报文,组装 MAC 帧头,完成刚刚没完成的发送流程。
如果经过 ARP 流程能正常返回 MAC 地址,那皆大欢喜,直接给数据链路层,经过 ring buffer 后传到网卡,发出去。但因为现在这个IP是瞎编的,因此不可能得到目的地址 MAC ,所以消息也一直没法到数据链路层。整个流程卡在了ARP流程中。而抓包是在数据链路层之后进行的,因此 TCP 第一次握手的包一直没能抓到,只能抓到为了获得 192.168.31.7 的MAC地址的ARP请求。
连一个 IP 存在,端口存在的主机时,握手过程是怎样的
- 不管目的IP是回环地址还是局域网内外的IP地址,目的主机的传输层都会在收到握手消息后,发现端口不正确,发出
RST消息断开连接。 - 当然如果
目的机器设置了防火墙策略,限制他人将消息发到不对外暴露的端口,那么这种情况,发送端就会不断重试第一次握手。
FIN一定要程序执行close()或shutdown()才能发出吗?
一般情况下,通过对socket执行 close() 或 shutdown() 方法会发出FIN。但实际上,只要应用程序退出,不管是主动退出,还是被动退出(因为一些莫名其妙的原因被kill了), 都会发出 FIN。
如果机器上FIN-WAIT-2状态特别多,是为什么?
因此当机器上FIN-WAIT-2状态特别多,那一般来说,另外一台机器上会有大量的 CLOSE_WAIT。需要检查有大量的 CLOSE_WAIT的那台机器,为什么迟迟不愿调用close()关闭连接。
主动方在close之后收到的数据,会怎么处理
Close()的含义是,此时要同时关闭发送和接收消息的功能。
第二第三次挥手之间,不能传输数据吗?
前面提到Close()的含义是,要同时关闭发送和接收消息的功能。
那如果能做到只关闭发送消息,不关闭接收消息的功能,那就能继续收消息了。
这种 half-close 的功能,通过调用shutdown() 方法就能做到。
int shutdown(int sock, int howto);
其中 howto 为断开方式。有以下取值:
- SHUT_RD:
关闭读。这时应用层不应该再尝试接收数据,内核协议栈中就算接收缓冲区收到数据也会被丢弃。 - SHUT_WR:
关闭写。如果发送缓冲区中还有数据没发,会将将数据传递到目标主机。 - SHUT_RDWR:
关闭读和写。相当于close()了。
对于被动方,被动方内核协议栈会把数据发给主动关闭方。
- 如果上一次主动关闭方调用的是
shutdown(socket_fd, SHUT_WR)。那此时,主动关闭方不再发送消息,但能接收被动方的消息。 - 如果上一次主动关闭方调用的是
close()。那主动方在收到被动方的数据后会直接丢弃,然后回一个RST。
被动方内核协议栈收到了RST,会把连接关闭。但内核连接关闭了,应用层也不知道(除非被通知)。
此时被动方应用层接下来的操作,无非就是读或写。
如果是读,则会返回RST的报错,也就是我们常见的Connection reset by peer。
如果是写,那么程序会产生SIGPIPE信号,应用层代码可以捕获并处理信号,如果不处理,则默认情况下进程会终止,异常退出。
如果此时被动方执行两次 send()。
第一次send(), 一般会成功返回。
第二次send()时。如果主动方是通过 shutdown(fd, SHUT_WR) 发起的第一次挥手,那此时send()还是会成功。如果主动方通过 close()发起的第一次挥手,那此时会产生SIGPIPE信号,进程默认会终止,异常退出。不想异常退出的话,记得捕获处理这个信号。
总结一下,当被动关闭方 recv() 返回EOF时,说明主动方通过 close()或 shutdown(fd, SHUT_WR) 发起了第一次挥手。
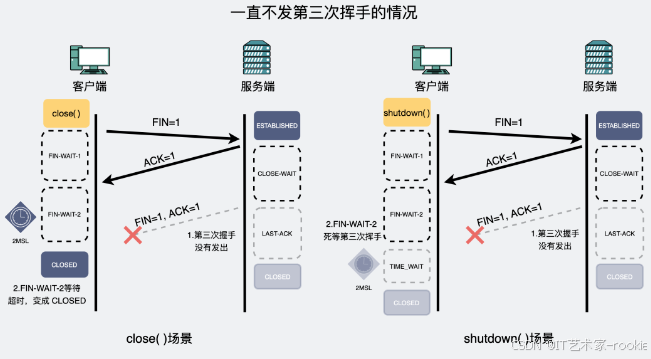
如果被动方一直不发第三次挥手,会怎么样
这时候,主动方会根据自身第一次挥手的时候用的是 close() 还是 shutdown(fd, SHUT_WR) ,有不同的行为表现。
- shutdown(fd, SHUT_WR) ,
说明主动方其实只关闭了写,但还可以读,此时会一直处于 FIN-WAIT-2,死等被动方的第三次挥手。 - close(), 说明主动方读写都关闭了,这时候会
处于 FIN-WAIT-2一段时间,这个时间由net.ipv4.tcp_fin_timeout控制,一般是60s,这个值正好跟2MSL一样 。超过这段时间之后,状态不会变成TIME-WAIT,而是直接变成CLOSED。
# cat /proc/sys/net/ipv4/tcp_fin_timeout
60
没收到第四次挥手请求,服务端会一直等待吗?
如果第四次挥手服务端一直没收到,那服务端会认为是不是自己的第三次挥手丢了,于是服务端不断重试发第三次挥手(FIN).重发次数由系统的tcp_orphan_retries参数控制。重试多次还没成功,服务端直接断开链接。所以结论是服务端不会一直等待第四次挥手。
# cat /proc/sys/net/ipv4/tcp_orphan_retries
0
当然
如果服务端重试发第三次挥手FIN的过程中,还是同样的端口和IP,起了个新的客户端,这时候服务端重试的FIN被收到后,客户端就会认为是不正常的数据包,直接发个RST给服务端,这时候两端连接也会断开。
链接关闭
RST
什么是RST: RST 就是用于这种情况,一般用来异常地关闭一个连接。它是一个TCP包头中的标志位。
正常情况下,不管是发出,还是收到置了这个标志位的数据包,相应的内存、端口等连接资源都会被释放。从效果上来看就是TCP连接被关闭了。而接收到 RST的一方,一般会看到一个 connection reset 或 connection refused 的报错。
收到RST的应用层表现:
当本端收到远端发来的RST后,内核已经认为此链接已经关闭。此时如果本端应用层尝试去执行 读数据操作,比如recv,应用层就会收到 Connection reset by peer 的报错,意思是远端已经关闭连接。
如果本端应用层尝试去执行写数据操作,比如send,那么应用层就会收到 Broken pipe 的报错,意思是发送通道已经坏了。
收到RST的场景
对端的端口不可用 和 socket提前关闭。
TCP三次挥手(可能的)
被动方没有数据要发给主动方
第三次挥手的目的是为了告诉主动方,“被动方没有数据要发了”。
所以,在第一次挥手之后,如果被动方没有数据要发给主动方。第二和第三次挥手是有可能合并传输的。这样就出现了三次挥手。
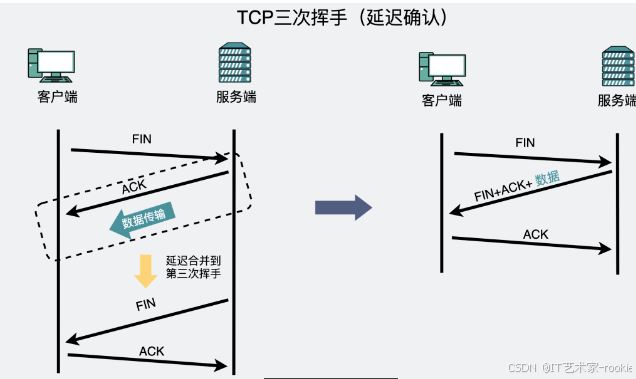
被动方有数据要发给主动方(延迟确认)
TCP中还有个特性叫延迟确认。可以简单理解为:接收方收到数据以后不需要立刻马上回复ACK确认包。
在此基础上,不是每一次发送数据包都能对应收到一个 ACK 确认包,因为接收方可以合并确认。而这个合并确认,放在四次挥手里,可以把第二次挥手、第三次挥手,以及他们之间的数据传输都合并在一起发送。因此也就出现了三次挥手。
TCP两次挥手
正常情况下TCP连接的两端,是不同IP+端口的进程。
但如果TCP连接的两端,IP+端口是一样的情况下,那么在关闭连接的时候,也同样做到了一端发出了一个FIN,也收到了一个 ACK,只不过正好这两端其实是同一个socket 。
同一个socket确实可以自己连自己,形成一个连接。
TCP自连接
通过nc命令可以很简单的创建一个TCP自连接
# nc -p 6666 127.0.0.1 6666
上面的 -p 可以指定源端口号。也就是指定了一个端口号为6666的客户端去连接 127.0.0.1:6666 。
# netstat -nt | grep 6666
tcp 0 0 127.0.0.1:6666 127.0.0.1:6666 ESTABLISHE
相同的socket,自己连自己的时候,握手是三次的。挥手是两次的。

一端第一次挥手后,又收到第一次挥手的包,TCP连接状态会怎么变化?
第一次挥手过后,一端状态就会变成 FIN-WAIT-1。正常情况下,是要等待第二次挥手的ACK。但实际上却等来了 一个第一次挥手的 FIN包, 这时候连接状态就会变为CLOSING。
// net/
static void tcp_fin(struct sock *sk)
{
switch (sk->sk_state) {
case TCP_FIN_WAIT1:
tcp_send_ack(sk);
// FIN-WAIT-1状态下,收到了FIN,转为 CLOSING
tcp_set_state(sk, TCP_CLOSING);
break;
}
}
CLOSING 很少见,除了出现在自连接关闭外,一般还会出现在TCP两端同时关闭连接的情况下。
处于CLOSING状态下时,只要再收到一个ACK,就能进入 TIME-WAIT 状态,然后等个2MSL,连接就彻底断开了。这跟正常的四次挥手还是有些差别的。大家可以滑到文章开头的TCP四次挥手再对比下。
自连接的解决方案
在连接建立完成之后判断下IP和端口是否一致,如果遇到自连接,则断开重试。
UDP
Socket 缓冲区
UDP socket 也是 socket,一个socket 就是会有收和发两个缓冲区。跟用什么协议关系不大。
udp_sendmsg函数
int udp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg, size_t len) {
if (用到了MSG_MORE的功能) {
lock_sock(sk);
// 加入到发送缓冲区中
release_sock(sk);
} else {
// 不加锁,直接发送消息
}
}
用到MSG_MORE就加锁,否则不加锁将传入的msg作为一整个数据包直接发送。
一般也用不到 MSG_MORE.
- MSG_MORE :它可以通过上面提到的sendto函数最右边的flags字段进行设置。大概的意思是告诉内核,待会还有其他更多消息要一起发,先别着急发出去。此时内核就会把这份数据先用发送缓冲区缓存起来,待会应用层说ok了,再一起发。
不走MSG_MORE分支还是线程安全的,不用lock_sock(sk)加锁,单纯是因为没必要。开启MSG_MORE时多个线程会同时写到同一个socket_fd对应的发送缓冲区中,然后再统一一起发送到IP层,因此需要有个锁防止出现多个线程将对方写的数据给覆盖掉的问题。而不开启MSG_MORE时,数据则会直接发送给IP层,就没有了上面的烦恼。
但是也不建议多线程读取,这种场景一般对程序压力大,UDP不可靠,会容易丢包
以下是关于UDP的普通模式和连接模式的详细解释及Go代码示例:
普通模式和连接模式
一、UDP的两种模式核心区别
| 特性 | 普通模式 | 连接模式 |
|---|---|---|
| 地址绑定 | 每次发送需指定目标地址 | 预先通过Connect()绑定目标地址 |
| 数据接收 | 可接收任意来源的数据包 | 仅接收已绑定目标地址的数据包 |
| 发送方法 | WriteToUDP() |
Write() |
| 接收方法 | ReadFromUDP() |
Read() |
| 适用场景 | 多播、广播或需动态切换目标的场景 | 固定单一目标的长连接通信 |
二、代码示例(Go实现)
1. 普通模式 (Unconnected UDP)
// 服务端:接收所有来源的UDP数据包
func unconnectedServer() {
addr, _ := net.ResolveUDPAddr("udp", ":8080")
conn, _ := net.ListenUDP("udp", addr)
defer conn.Close()
buffer := make([]byte, 1024)
for {
n, clientAddr, _ := conn.ReadFromUDP(buffer)
fmt.Printf("普通模式收到消息 [%s]: %s\n", clientAddr, string(buffer[:n]))
}
}
// 客户端:每次发送需指定目标地址
func unconnectedClient() {
serverAddr, _ := net.ResolveUDPAddr("udp", "127.0.0.1:8080")
conn, _ := net.DialUDP("udp", nil, serverAddr)
defer conn.Close()
// 发送到预先绑定的地址
conn.Write([]byte("普通模式消息"))
}
2. 连接模式 (Connected UDP)
// 服务端:仅接收来自绑定地址的数据包(需配合客户端连接模式)
func connectedServer() {
addr, _ := net.ResolveUDPAddr("udp", ":8081")
conn, _ := net.ListenUDP("udp", addr)
defer conn.Close()
buffer := make([]byte, 1024)
for {
n, _, _ := conn.ReadFromUDP(buffer) // 来源地址被忽略
fmt.Printf("连接模式收到消息: %s\n", string(buffer[:n]))
}
}
// 客户端:通过Connect绑定目标地址
func connectedClient() {
serverAddr, _ := net.ResolveUDPAddr("udp", "127.0.0.1:8081")
conn, _ := net.DialUDP("udp", nil, serverAddr)
defer conn.Close()
// 绑定目标地址(连接模式)
conn.Connect(serverAddr)
// 发送无需指定地址
conn.Write([]byte("连接模式消息"))
}
三、运行方式及输出
- 启动服务器:
func main() { go unconnectedServer() // 监听8080端口 go connectedServer() // 监听8081端口 time.Sleep(time.Hour) // 保持运行 } - 运行客户端:
func main() { unconnectedClient() // 发送到普通模式服务端 connectedClient() // 发送到连接模式服务端 } - 输出结果:
普通模式收到消息 [127.0.0.1:随机端口]: 普通模式消息 连接模式收到消息: 连接模式消息
四、关键行为分析
发送目标固定性
• 普通模式:客户端可随时更换目标地址(如动态切换服务器)。
• 连接模式:目标地址在Connect()后固定,调用Write()无需重复指定。数据接收过滤
• 普通模式服务端:接收所有客户端的消息。
• 连接模式服务端:若服务端也调用Connect(),则仅接收来自该地址的数据(但通常服务端不主动Connect)。错误处理差异
• 普通模式:发送到无效地址可能导致数据静默丢失。
• 连接模式:Write()会返回错误(如目标不可达)。
五、适用场景建议
普通模式适用场景:
• 广播/多播(如服务发现协议SSDP)。
• 需要动态切换目标的场景(如负载均衡探测)。连接模式适用场景:
• 客户端与固定服务器持续通信(如游戏心跳包)。
• 简化代码逻辑(避免重复指定地址)。
六、注意事项
连接模式不保证可靠性
UDP的Connect()仅绑定地址,不建立实际连接,仍需处理丢包和乱序。端口复用冲突
多个进程绑定同一端口时需设置SO_REUSEADDR(Go默认允许)。NAT穿透问题
连接模式在NAT环境下可能需要额外处理(如STUN协议)。
服务端要发送数据给客户端呢,又有什么区别
当服务端需要主动向客户端发送数据时,UDP的普通模式和连接模式在实现方式、地址管理和代码逻辑上有显著区别。以下是详细对比及Go代码示例:
一、核心区别总结
| 特性 | 普通模式 | 连接模式 |
|---|---|---|
| 发送方法 | 必须显式指定客户端地址(WriteToUDP) |
使用Write,无需每次指定地址(已绑定目标地址) |
| 地址管理 | 服务端需自行维护客户端地址列表 | 通过Connect绑定固定客户端地址 |
| 多客户端支持 | 天然支持向不同地址发送数据 | 需为每个客户端创建独立的连接Socket |
| 接收过滤 | 可接收所有客户端的消息 | 仅接收已绑定客户端的消息(若服务端调用Connect) |
二、代码示例(Go实现)
1. 普通模式:服务端主动发送数据
// 服务端:接收客户端地址后主动发送响应
func unconnectedServer() {
addr, _ := net.ResolveUDPAddr("udp", ":8080")
conn, _ := net.ListenUDP("udp", addr)
defer conn.Close()
buffer := make([]byte, 1024)
for {
// 1. 接收消息并记录客户端地址
n, clientAddr, _ := conn.ReadFromUDP(buffer)
fmt.Printf("普通模式收到客户端 [%s] 消息: %s\n", clientAddr, buffer[:n])
// 2. 主动向该客户端发送数据(需指定地址)
response := []byte("服务端回复: " + string(buffer[:n]))
_, _ = conn.WriteToUDP(response, clientAddr)
}
}
// 客户端:接收服务端响应
func unconnectedClient() {
conn, _ := net.ListenUDP("udp", &net.UDPAddr{IP: net.IPv4zero, Port: 0}) // 随机端口
defer conn.Close()
// 向服务端发送消息
serverAddr, _ := net.ResolveUDPAddr("udp", "127.0.0.1:8080")
conn.WriteToUDP([]byte("普通模式请求"), serverAddr)
// 接收服务端响应
buffer := make([]byte, 1024)
n, _, _ := conn.ReadFromUDP(buffer)
fmt.Println("客户端收到响应:", string(buffer[:n]))
}
2. 连接模式:服务端绑定客户端地址
// 服务端:为每个客户端创建独立的连接Socket
func connectedServer() {
addr, _ := net.ResolveUDPAddr("udp", ":8081")
baseConn, _ := net.ListenUDP("udp", addr)
defer baseConn.Close()
for {
// 1. 接收初始消息以获取客户端地址
buffer := make([]byte, 1024)
n, clientAddr, _ := baseConn.ReadFromUDP(buffer)
fmt.Printf("连接模式收到客户端 [%s] 消息: %s\n", clientAddr, buffer[:n])
// 2. 创建专用连接Socket并绑定该客户端地址
conn, _ := net.DialUDP("udp", nil, clientAddr)
defer conn.Close()
// 3. 通过专用Socket发送数据(无需指定地址)
response := []byte("服务端回复: " + string(buffer[:n]))
conn.Write(response)
}
}
// 客户端:使用连接模式通信
func connectedClient() {
// 连接服务端
serverAddr, _ := net.ResolveUDPAddr("udp", "127.0.0.1:8081")
conn, _ := net.DialUDP("udp", nil, serverAddr)
defer conn.Close()
// 发送请求
conn.Write([]byte("连接模式请求"))
// 接收响应
buffer := make([]byte, 1024)
n, _ := conn.Read(buffer)
fmt.Println("客户端收到响应:", string(buffer[:n]))
}
三、运行方式及输出
- 启动服务端:
func main() { go unconnectedServer() // 监听8080 go connectedServer() // 监听8081 select{} // 阻塞主线程 } - 运行客户端:
# 普通模式客户端 go run client.go -mode=unconnected # 连接模式客户端 go run client.go -mode=connected - 输出结果:
# 普通模式 服务端: 普通模式收到客户端 [127.0.0.1:52345] 消息: 普通模式请求 客户端: 客户端收到响应: 服务端回复: 普通模式请求 # 连接模式 服务端: 连接模式收到客户端 [127.0.0.1:62321] 消息: 连接模式请求 客户端: 客户端收到响应: 服务端回复: 连接模式请求
四、关键行为分析
1. 普通模式
• 服务端逻辑:
◦ 使用ReadFromUDP获取客户端地址,通过WriteToUDP主动发送数据。
◦ 天然支持多客户端,但需自行管理地址列表(如用map存储活跃客户端)。
• 客户端逻辑:
◦ 每次通信可能使用不同随机端口(除非显式绑定)。
2. 连接模式
• 服务端逻辑:
◦ 需为每个客户端创建独立Socket并调用Connect,否则绑定地址后无法接收其他客户端消息。
◦ 资源消耗较高(每个客户端一个Socket),但发送更高效。
• 客户端逻辑:
◦ 使用固定端口与服务端通信(DialUDP自动绑定本地端口)。
五、适用场景建议
| 场景 | 推荐模式 | 原因 |
|---|---|---|
| 服务端需广播通知所有客户端 | 普通模式 | 可遍历客户端地址列表逐个发送 |
| 一对一实时通信(如游戏对战) | 连接模式 | 减少地址解析开销,提升发送效率 |
| 客户端地址动态变化(如NAT) | 普通模式 | 连接模式的Connect在客户端IP/端口变化后会失效 |
| 服务端需长期维护客户端状态 | 混合模式 | 主Socket用普通模式接收新连接,为每个客户端创建连接模式Socket进行后续通信 |
六、注意事项
连接模式的服务端限制
• 若服务端直接对主监听Socket调用Connect,将无法接收其他客户端的消息。
• 正确做法:为每个客户端创建独立Socket(如示例中的conn, _ := net.DialUDP(...))。NAT穿透问题
• 客户端在NAT后时,服务端看到的地址是NAT转换后的公网IP和端口,需保持映射一致性。错误处理
• 连接模式下的Write可能返回ENOTCONN错误(如客户端主动关闭)。资源泄漏
• 连接模式中为每个客户端创建Socket时,需注意及时关闭(示例中defer conn.Close())。
TCP发数据的过程
1. 建立连接:三次握手(快递确认收货地址)
• 场景:你(客户端)要给朋友(服务端)寄快递,首先需要确认对方的地址有效且愿意接收。
• 技术细节:
• 第一次握手:你发送一个“你好,我要给你发数据”的请求(SYN包)。
• 第二次握手:朋友回复“好的,我准备好了”(SYN-ACK包)。
• 第三次握手:你再次确认“那我开始发了”(ACK包)。
• 结果:TCP连接建立,双方确认通信可靠。
2. 发送数据包:从用户空间到网卡(打包快递并交给物流)
步骤1:用户空间 → 内核空间(填写快递单)
• 用户空间:你在聊天软件(用户空间程序)输入消息,点击发送。
• 内核空间:操作系统(内核)接管消息,就像快递员来你家取包裹。
• 关键概念:
◦ 用户空间 vs 内核空间:用户程序(如微信)和操作系统内核有权限隔离,数据需要从用户程序的内存复制到内核管理的区域。
步骤2:传输层(给包裹贴运输标签)
• TCP协议:内核将你的消息拆分成多个小包裹(数据段),每个包裹贴上标签:
• 源端口和目标端口(类似寄件人和收件人的电话号码)。
• 序列号和确认号(用于确保包裹顺序正确,防止丢失)。
• 校验和(检查包裹是否损坏)。
步骤3:网络层(规划快递路线)
• IP协议:在TCP数据段外再包一层IP头,写上:
• 源IP和目标IP(寄件人和收件人的地址)。
• 确定数据包下一站该发到哪个路由器(通过路由表查找)。
步骤4:数据链路层(交给本地物流公司)
• MAC地址:数据包被封装成帧,添加源MAC地址(你的网卡)和目标MAC地址(下一跳路由器的网卡)。
• 流控(qdisc):类似物流公司的流量控制。如果快递太多,仓库会暂时存放包裹(缓冲队列),避免爆仓(网络拥塞)。
• RingBuffer:网卡上的一个环形队列,临时存放待发送的数据包,像物流公司的装货区。
步骤5:物理层(快递装车发货)
• 网卡:数据包被转换成电信号或光信号,通过网线或Wi-Fi发出,就像快递装车运往分拣中心。
3. 网络传输:经过路由器和交换机(快递中转站)
• 路由器:根据IP地址决定包裹下一站(类似分拣中心按地址分拣)。
• 交换机:根据MAC地址将包裹送到正确的局域网设备(小区快递柜按电话号码投递)。
• 跳转:数据包可能经过多个路由器和交换机,直到抵达目标服务器所在的网络。
4. 接收数据包:从网卡到用户空间(收快递并拆包)
步骤1:网卡收包(快递车到达收件人小区)
• DMA(直接内存访问):网卡收到数据包后,直接通过DMA将数据写入内存的RingBuffer,无需CPU参与(快递员直接把包裹放进你家邮箱,不用敲门)。
• 硬中断:网卡通知CPU“有快递到了!”(类似按门铃提醒你取件)。
步骤2:内核处理包裹(拆快递并检查)
• 软中断:CPU触发一个低优先级的任务(ksoftirqd线程),让它在后台处理数据包(你听到门铃后,先忙手头的事,稍后再拆包裹)。
• 协议栈解包:
• 物理层 → 数据链路层:校验MAC地址,确认是发给本机的。
• 网络层 → 传输层:校验IP和端口,组装TCP数据段。
• 内核空间 → 用户空间:将完整数据从内核缓冲区复制到聊天软件的内存。
步骤3:应用层显示消息(阅读快递内容)
• 聊天软件:数据被还原成文字、图片等,显示在聊天窗口中。
关键概念总结
| 概念 | 类比 | 作用 |
|---|---|---|
| 用户空间/内核空间 | 你家 vs 快递公司仓库 | 数据需从应用交给操作系统处理 |
| TCP三次握手 | 确认对方地址和接收意愿 | 建立可靠连接 |
| 流控(qdisc) | 物流公司限流 | 防止网络拥塞,缓冲数据包 |
| RingBuffer | 物流公司的临时装货区 | 网卡收发数据的缓冲区 |
| DMA | 快递员直接放包裹到邮箱 | 网卡直接读写内存,减少CPU负担 |
| 硬中断/软中断 | 门铃提醒 vs 稍后处理 | 高效通知CPU处理数据包 |
| ksoftirqd | 专门处理快递的后台人员 | 内核线程,负责处理网络软中断任务 |
为什么需要这么多步骤?
• 可靠性:TCP保证数据包顺序正确、不丢失(快递保价+物流跟踪)。
• 效率:DMA和中断机制减少CPU占用(快递员不打扰你工作)。
• 分层管理:各层协议各司其职,像物流公司的不同部门协作(分拣、运输、投递)。
DMA和硬中断是什么关系
DMA(直接内存访问)和硬中断(Hardware Interrupt)是计算机系统中两个紧密协作的机制,它们的关系可以用“搬砖工人”和“监工”来类比。DMA负责高效搬运数据,而硬中断负责通知CPU“数据搬完了,该处理了”。下面用更技术化的方式解释它们的协作关系:
1. DMA的作用:解放CPU,直接搬运数据
• 核心功能:允许硬件设备(如网卡、磁盘)直接访问内存,无需CPU参与数据拷贝。
• 类比:DMA像一个专业的搬砖工人,CPU只需要告诉它“把砖从A搬到B”,之后CPU可以去处理其他任务,搬砖过程不需要CPU盯着。
• 场景:
• 网卡收到数据包时,DMA会直接将数据从网卡的缓存(硬件寄存器)搬运到内存中的RingBuffer(接收缓冲区)。
• 整个过程不需要CPU参与数据搬运,极大减少CPU负担。
2. 硬中断的作用:通知CPU“任务完成”
• 核心功能:硬件设备(如网卡)通过硬中断通知CPU“有事件需要处理”。
• 类比:搬砖工人(DMA)搬完砖后,监工(硬中断)会大喊一声:“搬完了!快来处理!”
• 场景:
• 当网卡的DMA完成数据搬运(数据已存入内存的RingBuffer),网卡会触发一个硬中断。
• CPU收到硬中断后,会暂停当前任务,优先处理这个中断。
3. DMA和硬中断的协作流程
以网卡接收数据包为例:
DMA搬运数据:
• 网卡收到数据包后,直接通过DMA将数据写入内存的RingBuffer。
• 此时CPU完全不需要参与数据搬运(省去了CPU逐字节拷贝的时间)。硬中断通知CPU:
• 当DMA完成数据搬运后,网卡触发一个硬中断,告诉CPU:“数据已经放到内存了,快来处理!”
• CPU收到硬中断后,会立即暂停当前工作(例如正在运行的应用程序),进入中断处理程序。CPU响应中断:
• CPU执行中断处理程序(通常是一个简短的函数),可能做两件事:
◦ 记录中断事件(例如“有数据包到达”)。
◦ 触发软中断(SoftIRQ),让内核的ksoftirqd线程后续从RingBuffer中取出数据包,交给协议栈处理。
• 中断处理程序执行完毕后,CPU回到原来的任务继续工作。
4. 为什么需要DMA和硬中断配合?
• 效率:如果不用DMA,CPU需要亲自搬运数据,浪费大量时间在拷贝操作上。
• 实时性:如果不用硬中断,CPU只能轮询(Polling)检查数据是否到达,效率极低。
• 分工协作:
• DMA负责“体力活”(数据搬运),解放CPU。
• 硬中断负责“通知”,让CPU及时处理事件,避免轮询等待。
5. 技术对比:DMA vs 硬中断
| 特性 | DMA | 硬中断 |
|---|---|---|
| 角色 | 数据搬运工 | 通知机制(监工) |
| 操作对象 | 内存和硬件设备之间的数据传输 | CPU的中断控制器 |
| CPU参与度 | 无需CPU参与数据搬运 | 需要CPU响应中断 |
| 触发时机 | 由硬件设备发起(如网卡收到数据) | 由硬件设备发起(如DMA完成搬运) |
| 性能影响 | 减少CPU负担 | 中断过多会导致CPU频繁切换任务 |
6. 扩展:硬中断 vs 软中断
• 硬中断(Hardware Interrupt):
• 由硬件设备触发(如网卡、磁盘)。
• CPU必须立即响应(高优先级)。
• 处理时间必须极短,否则会影响系统实时性。
• 软中断(SoftIRQ):
• 由内核触发(例如在硬中断处理程序中触发)。
• 延迟执行,优先级较低,由内核线程ksoftirqd处理。
• 用于处理耗时任务(如协议栈解析、数据包组装)。
总结
• DMA和硬中断的关系:DMA负责高效搬运数据,硬中断负责通知CPU“数据已到位”,两者配合实现高效的数据传输和及时的处理。
• 类比:就像搬家时,搬家公司(DMA)负责搬东西,搬完后打电话(硬中断)通知你:“东西搬完了,快来验收!”。你不用全程盯着搬家过程(CPU被解放),只需在完成后处理验收(协议栈处理)。
【参考】小白debug