2022 年夏,居家办公时,第一次接手 mptcp 就觉得它不靠谱,以至于我后来搞了 mpudp for DC,再后来我调研了很多 mptcp-based 方案,发现它们都是向善而来,最终灰头土脸而终。mptcp 实则一个坑,业内并没有普遍部署,也没有任何值得借鉴的经验,但筚路蓝缕,终究不会让所有启程变归途。
5.6 内核前的 MPTCP v0 实现非常丝滑,让我想起 task_struct,跟 task_struct 摇身一变成了主线程一样,socket 也摇身一变更换了一些 sock operations 回调后变成了 meta sock,但和进程中多个 task_struct 可在多个 CPU 并行不同,MPTCP v0 多个 subflow 却不能在多路径上同时收发数据,这显然与它的名字所体现的意义相违背。
看 mptcp 与 task_struct 何等相似,再看看为什么 v0 吞吐性能低下,以及 v1 是如何解决的:

task_struct 作为一个可执行代码的容器将共享互斥权力交给了代码本身,而 mptcp 本身即包含传输控制逻辑,因此它需要将锁拆分到更细的粒度,确保只有直接接触的彼此才需要互斥,即谁接触谁抢锁。
v0 版本显然只是一个最简实现版本,借用巧妙的结构体替换以最小代价实现了 mptcp,但如果 v0 版本显示不出 mptcp 该有的特性和优势,又如何吸引人们有动力去部署并迭代 v1 呢。哪怕是一团烂泥,先跑起来再说,这显然忽略了不是谁都有的试错成本,这是句毒鸡汤,烂话。
看下 mptcp v0 的实现:
// MPTCP 写回调,由 meta_sock 调用,持有 meta_sock 锁
bool mptcp_write_xmit(struct sock *meta_sk, unsigned int mss_now, int nonagle,
int push_one, gfp_t gfp)
{
while ((skb = mpcb->sched_ops->next_segment(meta_sk, &reinject, &subsk,
&sublimit))) {
mptcp_skb_entail(subsk, skb, reinject);
}
mptcp_for_each_sub(mpcb, mptcp) {
subsk = mptcp_to_sock(mptcp);
// 调用 subflow_sock 原始的 tcp_write_xmit 将数据包发往 subflow
__tcp_push_pending_frames(subsk, mss_now, TCP_NAGLE_PUSH);
}
}
// MPTCP 接收,LOCK 住整个 meta_sock
int tcp_v4_rcv(struct sk_buff *skb)
{
// 检索到 subflow_sock
sk = __inet_lookup_skb(&tcp_hashinfo, skb, __tcp_hdrlen(th), th->source,
th->dest, sdif, &refcounted);
if (mptcp(tcp_sk(sk))) {
// 锁住整个 meta_sock
meta_sk = mptcp_meta_sk(sk);
bh_lock_sock_nested(meta_sk);
if (sock_owned_by_user(meta_sk))
mptcp_prepare_for_backlog(sk, skb);
} else {
meta_sk = sk;
bh_lock_sock_nested(meta_sk);
}
if (!sock_owned_by_user(meta_sk)) {
ret = tcp_v4_do_rcv(sk, skb);
} else if (tcp_add_backlog(meta_sk, skb)) {
goto discard_and_relse;
}
bh_unlock_sock(meta_sk);
}
看了以上的 “问题代码”,解法就很自然,mptcp_write_xmit 和 tcp_v4_rcv 分别锁 subflow_sock,注意到 softirq 中的 rcv 逻辑并不触动发送缓冲区,因此仅在 mptcp_data_ready 时才锁 meta_sock。
如果不把 mptcp 看作淋浴喷头,看作在线订单配送系统也是合适的,虽然配送员要从同一处排队领单,但多个配送员独立配送显然可以提高系统吞吐。
再看 mptcp subflow 调度逻辑,这仍是一个并行编程问题,如何设计一个好的调度算法和如何将一个问题拆分为可并行执行的子问题完全一致。一个简单的求和问题,1 + 2 + 3 + 4 + … + 100,两个人一起算,一个人算 1 + 2,另一个人算 2 + 3 还是 3 + 4 呢,显然都不合适,因为这样的的话他们需要频繁交流同步,而 mptcp 采用的就是这种不合适的策略。众所周知,小高斯的策略更胜一筹,他聪明地分割了问题,这个问题用现代多核处理器上的多线程程序来做,即使最拙劣的程序员想到的依然还是小高斯的策略。
以上这段的意思就是我前面文章提到的调度策略,给出了一个 subflow 从数据开头顺序发送,另一个 subflow 从数据末尾逆序发送的理由,这样一来,它们只需在碰头时同步一次。这个想法来自于小学工程队修路这类应用题。
但 3 条及以上的 subflow 怎么办?
这引出一个很棒(至少我以为)的调度策略,即最小交互策略,它主要通过破除人们对启发式的执念来起作用。意思是说,想要高性能,能静态就不要动态,算不准就不要猜,因为动态的,启发式策略除了它们本身的复杂性成本外,还有猜错了后的补偿成本,只要信息量不足,必然由猜错的时候。而最小交互策略连 subflow 间的同步成本也尽可能省掉了:
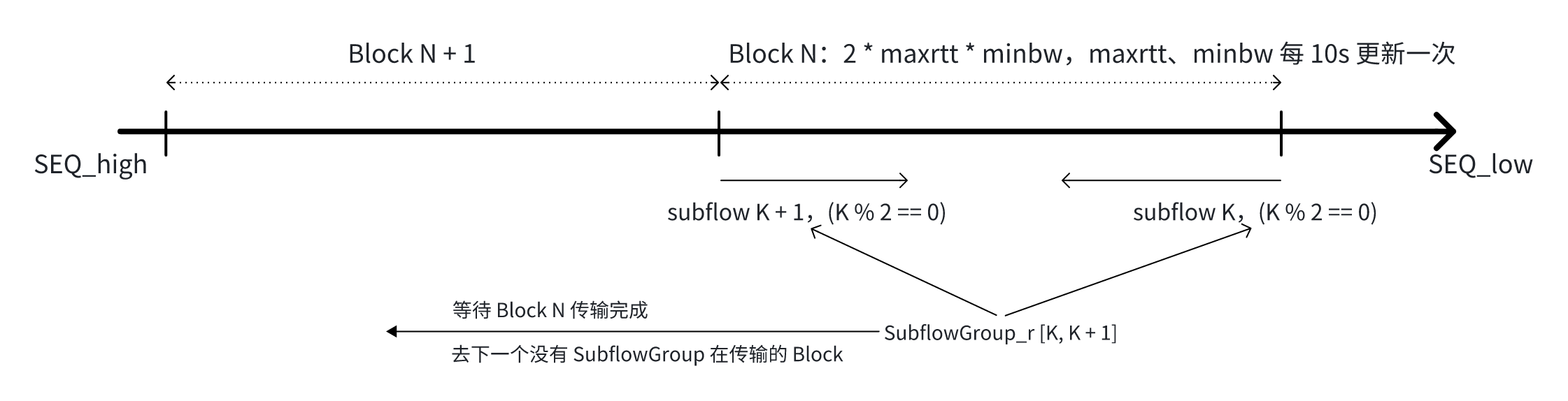
成本没了,剩下的全是性能了。
继续基于并发,并行的概念审视 mptcp:
- 并发视角:将多条路径视作池化资源,提高资源利用率,RFC6356 原则 3;
- 并行视角:将多条路径视作可并行资源,提高吞吐,降低时延,受 RFC6356 原则 2 约束 。
两个视角带来了不同的优化理念。
站在并发视角,优先要做的是将流量调度到相对空闲链路,避免带宽浪费,但不要将流量调度到繁忙链路,避免拥塞,主要 concern 调度算法;而站在并行视角,则需要更关注传输任务本身的分解,与并行编程的 concern 完全一致。我将多路径看作并行资源,我希望带宽能叠加,RFC6356 原则 2 约束了做这件事的底线狠度。
原则是一回事,实现是一回事,即便是 mptcp v1,仍不能完全避免串行化,因为本质上 TCP 就是一个串行流,多个 subflow 从 meta_sock 取数据发送或接收完数据重组拼接时,仍然要抢 meta_sock 锁,这意味着 mptcp 永远也无法实现多路径吞吐的满叠加,有趣的是,文初描述 mptcp v0 的 meta sock 串行锁竟然直接实现了 6356 原则 2,让你即使想叠加带宽而不能为之。
串行流的并行化很难,除非将思路转向我上面提到的那种策略,固定分割数据,在流序列号空间上让 subflow 们彻底无关(最多一个 bitmap 操作甚至一个原子操作),就不必在时间上争抢锁,这也正是很多多路径自研新协议的思路了。
至于人们对启发式,自适应的执念,和所谓通用系统的普适性执念说的是一个意思,还是那句话,要性能就别自适应,要通用就别调参。那么说说 Linux 自带的 mptcp 通用算法。所有的逻辑都在 net/mptcp/protocol.c 中的 mptcp_subflow_get_send 这一个函数里,简单讲就是两个逻辑:
- 在所有 subflow 里冒泡一个 key = local_write_queue_len / pacing_rate 最小的 subflow,记为 R;
- 将 global_write_queue 中的约 64kB 数据 queue 到 R 的 local_write_queue_len。
本着以上的论述,这个算法如何再 “优化” 呢?来试试看。
虽然前文我已经驳斥了这种对 “乱序发,顺序到达” 的执念在现实中多么不靠谱,但若要尽量让算法看起来好看些,还是要有论证。
要顺序到达,就要精确预测 sender global_write_queue 中每一个报文在不同 subflow 中到达 receiver 的时间,由于 RTT 本质上不准,说白了还得靠猜,这就是所谓启发式。
这个到达时间由两部分构成,一部分包括在 subflow 的 local_write_queue 中排队时间,另一部分则是单程时延,即 RTT 的一半:
T a r r i v e = T w a i t + R T T 2 = L o c a l Q u e u e L e n D e l i v e r y R a t e + R T T 2 T_{\mathrm{arrive}}=T_{\mathrm{wait}}+\dfrac{\mathrm{RTT}}{2}=\dfrac{\mathrm{LocalQueueLen}}{\mathrm{DeliveryRate}}+\dfrac{\mathrm{RTT}}{2} Tarrive=Twait+2RTT=DeliveryRateLocalQueueLen+2RTT
按 Tarrive 冒泡看上去就比 Linux 自带的那个算法高尚,至少是看上去不错。其实 Linux 自带算法也就缺个 RTT / 2,大致意思没变。看下 Linux mptcp 调度算法的注释:
/* According to the blest algorithm, to avoid HoL blocking for the
* faster flow, we need to:
* - estimate the faster flow linger time
* - use the above to estimate the amount of byte transferred
* by the faster flow
* - check that the amount of queued data is greter than the above,
* otherwise do not use the picked, slower, subflow
* We select the subflow with the shorter estimated time to flush
* the queued mem, which basically ensure the above. We just need
* to check that subflow has a non empty cwin.
*/
冒泡算法已经 “优化” 好了,接下来看第二个问题,一次性发多少呢?Linux 硬编码了约 64kB,但更好看的应该是一个 BDP,不细说了。
最后,若换一个角度,从 “最佳效能” 考虑,就应该把所有不确定的工作尽量推给 receiver,配置极大的接收 buffer 供它乱序重组,sender 便可按照 key = BW / RTT 冒泡最大值来调度 subflow,总之,成本核算的活必须要干,问题是谁干。
重新捋一下上面的 “优化”,我始终没有让丢包率参与进来,这是因为它已经包含在 DeliveryRate 里了,如果丢包率变高,吞吐一定会下降。一定要让且仅让正交变量参与,而不是搞一大堆复杂的公式故弄玄虚,让人不明觉厉。
结束之前,回忆一下往事。
我从 mptcp 想到了 Linux 的进程,线程结构体 tast_struct,于是我用包括 Google 在内搜索引擎搜我在十几年前写的文章,结果全是转载,最后我是通过本地记录找到了时间,然后在 CSDN 匹配时间找到了这篇:朴素的 UNIX 之进程/线程模型,里面有个模糊的图:
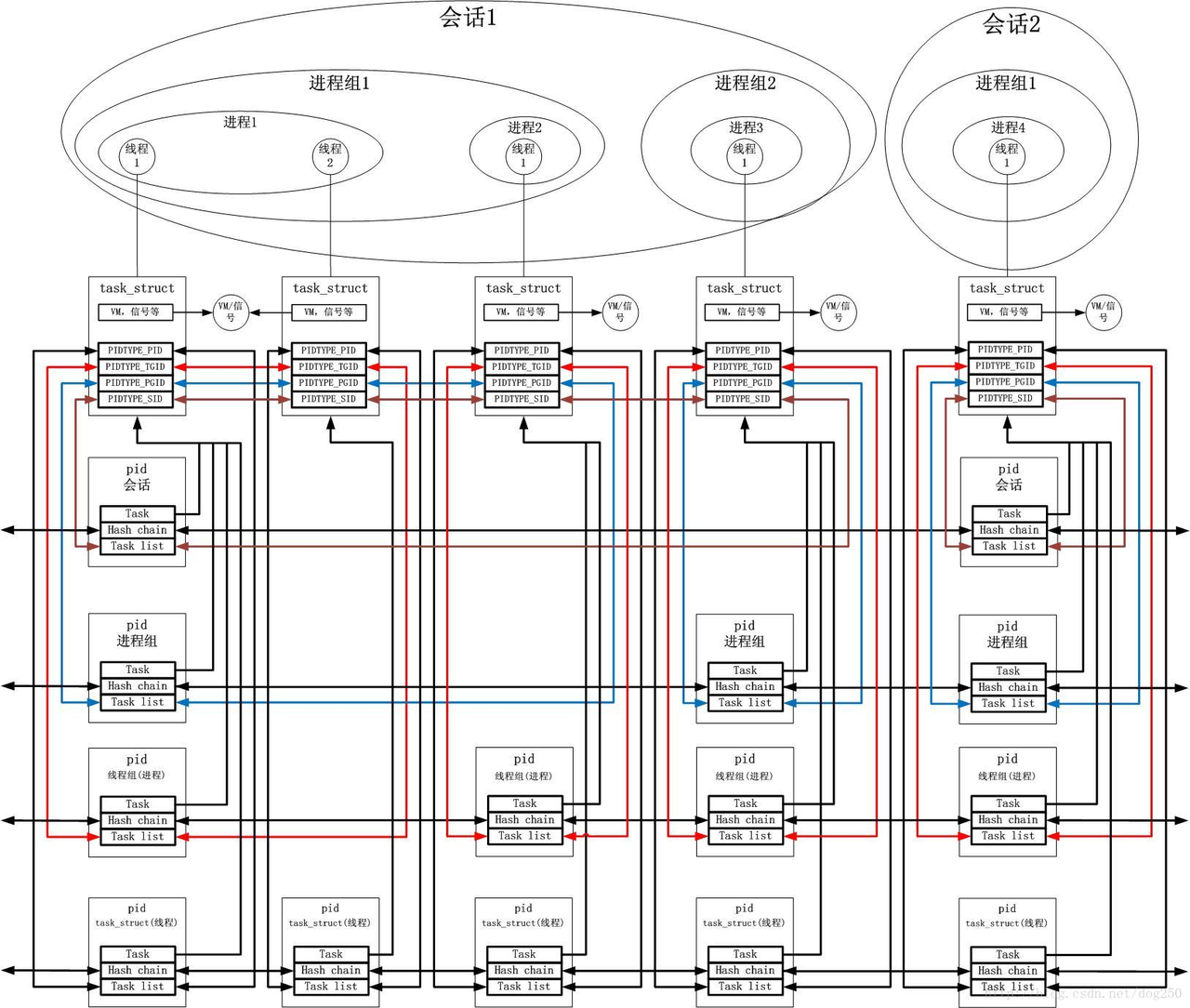
浙江温州皮鞋湿,下雨进水不会胖。