上回说到,红黑树是提升了动态数据集中频繁插入或删除操作的性能。而哈希表(Hash Table),则是解决了传统数组或链表查找数据必须要遍历的缺点。

哈希表
哈希表的特点就是能够让数据通过哈希函数存到表中,哈希函数能够将数据处理为表中位置的索引(这个就叫映射),然后将其存入。这样一来,我们查找数据的时候只要一通过哈希函数就可以得到该数据的索引,然后进行操作。
哈希函数有很多种实现方法。
1、直接定址法
数据本身就直接作为哈希地址(即位置索引)然后进行存放,好处就是不会产生哈希冲突。
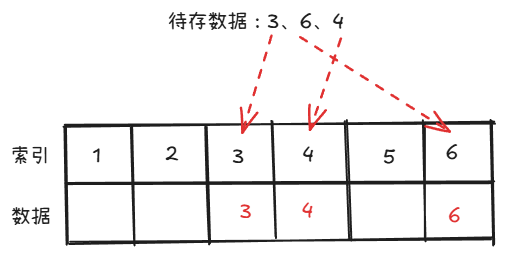
可以看到我们的存入的数据是分散在表中的,只有3个数却占用了6个位置。这也是为什么哈希表又叫散列表。这种方法只适合数据集中的情况。
2、除留余数法
这是最经典的方法。通过指定一个除数,将我们的数据进行相除来得到哈希地址。
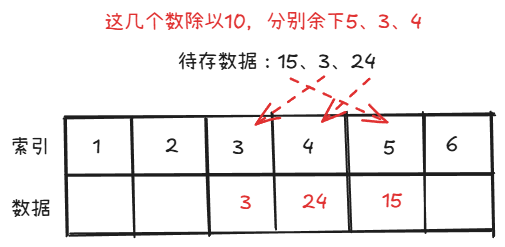
这种方法可以有效地减少空间浪费,将数据集中起来。但是如果像2、22这样的数就会产生哈希冲突。其解决方法之后会讲到。
3、平方取中法
这个通过将数据平方计算后,根据哈希表的大小取中间的几位数,这样更有机会让数据随机均匀分布在哈希表中。
如1234的平方为1522756,哈希表的大小是100,那么去中间3位,存入227的地址中。
现在谈谈如何解决哈希冲突,一般有两种方法。
1、开放寻址法(闲散列)
顾名思义就是让空地址向发生冲突的新数据开放,让其存进去。比如线性探测和二次探测。线性探测是指按照顺序将新数据排在原本哈希地址的后面,先+1,不行+2,依次类推。而二次探测就是把这些数进行了平方再加,向前后两方进行。
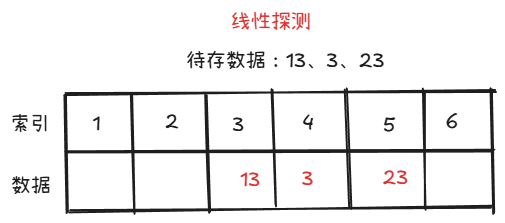
那我们如果一直发生冲突,导致哈希表大小不够用了怎么办?这里需要引入“负载因子”的概念。负载因子是一个比例,表示当哈希表中的数据比哈希表的大小超过负载因子时,哈希表需要扩容,一般为0.7。
2、链地址法(开散列)
哈希桶法,拉链法一般都是指这个。
就是把每个位置作为一个链表的头,如果发生冲突,就将其作为后继节点连接在该位置下面。
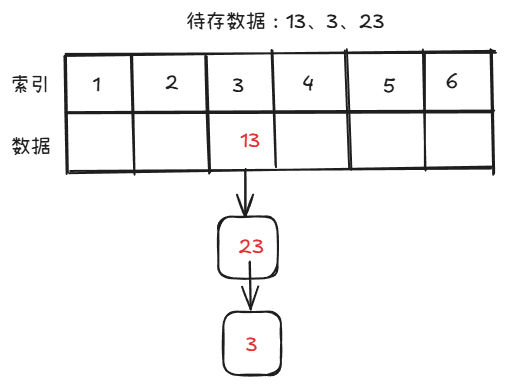
虽然这样的负载因子可以大于一(即不用扩容),但因为要存储指针,会造成更多的空间开销。
我们讨论哈希表时常常会谈到“键值对”。这里的“键 Key”就是钥匙的意思,可以通过键来获取哈希地址。所以我们上文所操作的所有数据,都可以叫做键,关键码值常常也说的是这个。而另一个“值 Value”指的是与键关联的数据,其存在真正赋予了哈希表以灵活性与实用性,因为键一旦在哈希表中确认就不便更改了,而值可以随便的更新删除。所以键更像成为了值的索引,从而适应常用的操作。
之前上文中介绍的都是值为空、只有键的情况,这可以称为是哈希表实现的“集合 Set”,而包含键值对的情况称为哈希表实现的“映射 Map”。

上文提到的哈希桶,就是指储存了键值对的一个位置。“哈希桶法”就是因为一个桶下面连着挂着好几个桶而得名的。
C++中的set与map
现在终于到了追本溯源的时候了。C++的STL库中,分别有着用红黑树实现的<set><map>,还有着用哈希表实现的<unordered_set><unordered_map>,这两种结构下最显著的区别就是其有序性了,红黑树默认是升序排列的。
上次讲到红黑树的查找删除操作时间复杂度都是O(logn),而哈希表是O(1)(平均复杂度,最坏情况O(n),持续哈希冲突),可以说是这种结构最大的优势了,但其需要预分派桶数组,拉链法还有存新链表,造成更多的空间占用。那么<unordered_set>和<unordered_map>大多会用在不关心顺序,追求快速操作的场景,其他情况都用<set><map>即可。
除了STL容器的通用方法以外,集合和映射还有这些用法。
//集合
set<int> s1 = { 1, 3, 2 };
unordered_set<int> s2 = { 1, 3, 2 };
s1.count(1);//在set中由于不重复性,可用于检测存在否
s2.count(1);//返回0或1
//对于有序的set
cout << *s1.lower_bound(1) << endl;//找到大于等于目标值的数迭代器
cout << *s1.upper_bound(1) << endl;//找到大于目标值的数迭代器
//对于无序的unordered_set
int num = s2.bucket_count();//桶的数量
cout << num << endl;
cout << s2.load_factor() << endl;//查看负载因子
s2.rehash(11);//设置桶的数量,重哈希,这个过程也包含对照负载因子扩容
num = s2.bucket_count();
cout << num << endl;
//映射
map<int, int> m1 = { {1, 3}, {2, 9}, {3, 4} };//前为key后为value
unordered_map<int, int> m2 = { {1, 3}, {2, 9}, {3, 4} };
m1.count(1);//检测存在否
m2.count(1);
//插入键值对,若键已存在则不覆盖
m1.emplace(2, 1);
m2.emplace(2, 1);
m1.insert({ 4, 6 });//这个返回迭代器
m2.insert({ 4, 6 });
//通过[key]访问value
cout << m1[1] << endl;
cout << m2[4] << endl;
//对于有序的map //用first和second访问key和value
cout << m1.lower_bound(1)->first << endl;//找到key大于等于目标值的数迭代器
cout << m1.upper_bound(1)->second << endl;//找到key大于目标值的数迭代器
//对于无序的unordered_map
cout << m2.bucket(3) << endl;//返回key3的桶编号
m2.reserve(10);//预分配空间正好,一道名为“数组的度”的题就是用哈希表解决的,就在这里练练手吧!
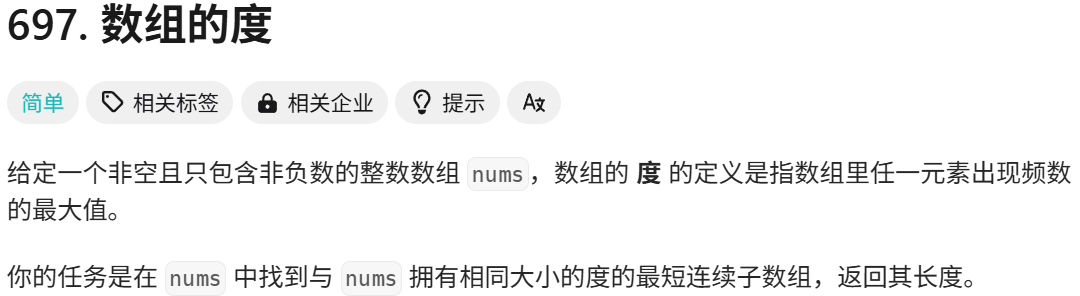
int findShortestSubArray(vector<int>& nums) {
//key用来记录对应的数,vector用来记录索引
unordered_map<int, vector<int>> m;
//第一次记录
for(int i = 0; i < nums.size(); i++){
if(!m.count(nums[i])){
//分别是 出现次数、头索引、尾索引
m[nums[i]] = {1, i, i};
}else{
//增加次数,更新尾索引
m[nums[i]][0]++;
m[nums[i]][2] = i;
}
}
//寻找出现次数最大的
int num = 0, minLength = 0;
//注意,获取的每一个是键值对类型pair<T1, T2>
for(pair<int, vector<int>> it : m){
if(num < it.second[0]){
num = it.second[0];
minLength = it.second[2] - it.second[1] + 1;
}else if(num == it.second[0]){
if(minLength > it.second[2] - it.second[1] + 1){
minLength = it.second[2] - it.second[1] + 1;
}
}
}
return minLength;
} 小结
最近笔者还真抽不出时间好好学习游戏开发有关的知识,七七八八的事情挺多。不过瓜熟蒂落,水到渠成,把事情都梳理顺畅,再着手沉淀也不晚。

如有补充纠正欢迎留言。