深度学习在计算机视觉领域的应用取得了显著进展,尤其是在目标检测(Object Detection)和图像分类(Image Classification)任务中。YOLO(You Only Look Once)系列算法凭借其高效的单阶段检测框架和卓越的实时性能,成为目标检测领域的研究热点。然而,随着应用场景的复杂化和多样化,如何进一步提升模型在复杂背景下的鲁棒性(Robustness)、小目标检测(Small Object Detection)能力以及特征表达能力(Feature Representation Capability),成为亟待解决的问题。本文提出了一种基于BAM(Bottleneck Attention Module)注意力机制的YOLO11改进方案,通过在骨干网络(Backbone)和颈部网络(Neck)中嵌入BAM模块,增强模型对通道维度(Channel Dimension)和空间维度(Spatial Dimension)的动态注意力分配能力,从而优化模型在图像分类与目标检测任务中的表现。
1. BAM注意力机制简介
BAM(Bottleneck Attention Module)是一种轻量级的注意力机制模块,旨在通过通道和空间维度的双重注意力机制增强特征图的表现力。其核心思想是通过对输入特征图进行通道注意力和空间注意力的计算,动态调整特征的重要性,从而突出关键区域并抑制冗余信息。
BAM的主要特点包括:
- 通道注意力 :通过全局平均池化(GAP)和全连接层计算每个通道的重要性权重,提升对重要特征的关注。
- 空间注意力 :利用卷积操作生成空间注意力图,强调目标所在的区域。
- 模块化设计 :BAM可以无缝嵌入现有网络结构中,不会显著增加计算开销。
论文链接:BAM: Bottleneck Attention Module
代码地址:https://github.com/Jongchan/attention-module

2. 将BAM添加到YOLO11
2.1 BAM代码实现
将下面代码粘贴到在
/ultralytics/ultralytics/nn/modules/block.py中
class Flatten(nn.Module):
def forward(self, x):
return x.view(x.shape[0], -1)
class ChannelAttention(nn.Module):
def __init__(self, channel, reduction=16, num_layers=3):
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
gate_channels = [channel]
gate_channels += [channel // reduction] * num_layers
gate_channels += [channel]
self.ca = nn.Sequential()
self.ca.add_module('flatten', Flatten())
for i in range(len(gate_channels) - 2):
self.ca.add_module('fc%d' % i, nn.Linear(gate_channels[i], gate_channels[i + 1]))
self.ca.add_module('bn%d' % i, nn.BatchNorm1d(gate_channels[i + 1]))
self.ca.add_module('relu%d' % i, nn.SiLU())
self.ca.add_module('last_fc', nn.Linear(gate_channels[-2], gate_channels[-1]))
def forward(self, x):
res = self.avgpool(x)
res = self.ca(res)
res = res.unsqueeze(-1).unsqueeze(-1).expand_as(x)
return res
class SpatialAttention(nn.Module):
def __init__(self, channel, reduction=16, num_layers=3, dia_val=2):
super().__init__()
self.sa = nn.Sequential()
self.sa.add_module('conv_reduce1',
nn.Conv2d(kernel_size=1, in_channels=channel, out_channels=channel // reduction))
self.sa.add_module('bn_reduce1', nn.BatchNorm2d(channel // reduction))
self.sa.add_module('relu_reduce1', nn.SiLU())
for i in range(num_layers):
self.sa.add_module('conv_%d' % i, nn.Conv2d(kernel_size=3, in_channels=channel // reduction,
out_channels=channel // reduction,
padding=autopad(3, None, dia_val), dilation=dia_val))
self.sa.add_module('bn_%d' % i, nn.BatchNorm2d(channel // reduction))
self.sa.add_module('relu_%d' % i, nn.SiLU())
self.sa.add_module('last_conv', nn.Conv2d(channel // reduction, 1, kernel_size=1))
def forward(self, x):
res = self.sa(x)
res = res.expand_as(x)
return res
class BAMBlock(nn.Module):
def __init__(self, channel=512, reduction=16, dia_val=2):
super().__init__()
self.ca = ChannelAttention(channel=channel, reduction=reduction)
self.sa = SpatialAttention(channel=channel, reduction=reduction, dia_val=dia_val)
self.sigmoid = nn.Sigmoid()
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant_(m.weight, 1)
init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal_(m.weight, std=0.001)
if m.bias is not None:
init.constant_(m.bias, 0)
def forward(self, x):
b, c, _, _ = x.size()
sa_out = self.sa(x)
ca_out = self.ca(x)
weight = self.sigmoid(sa_out + ca_out)
out = (1 + weight) * x
return out
修改modules文件夹下的
__init__.py文件,先导入函数
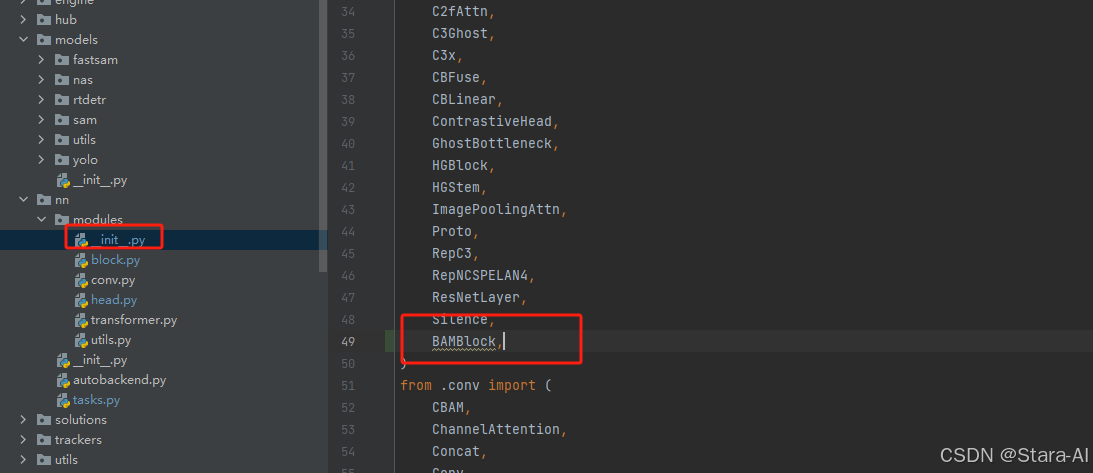
然后在下面的
__all__中声明函数
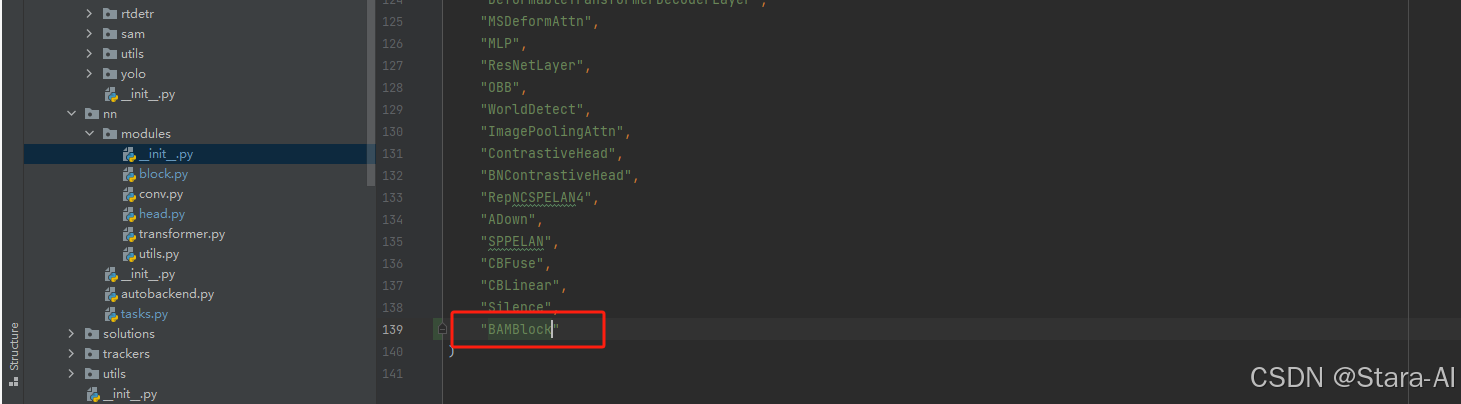
2.2 添加yaml文件
在
/ultralytics/ultralytics/cfg/models/11下面新建文件yolo11_BAM.yaml文件
- 目标检测
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
- [-1, 1, BAMBlock, [1024]]
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[17, 20, 23], 1, Detect, [nc]] # Detect(P3, P4, P5)
- 语义分割
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
- [-1, 1, BAMBlock, [1024]]
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[17, 20, 23], 1, Segment, [nc, 32, 256]] # Segment(P3, P4, P5)
- 旋转目标检测
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPs
s: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPs
m: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPs
l: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPs
x: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs
# YOLO11n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 2, C3k2, [256, False, 0.25]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 2, C3k2, [512, False, 0.25]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 2, C3k2, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 2, C3k2, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 2, C2PSA, [1024]] # 10
- [-1, 1, BAMBlock, [1024]]
# YOLO11n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 2, C3k2, [512, False]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 14], 1, Concat, [1]] # cat head P4
- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 11], 1, Concat, [1]] # cat head P5
- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)
- [[17, 20, 23], 1, OBB, [nc, 1]] # Detect(P3, P4, P5)
本文只是对yolo11基础上添加模块,如果要对yolo11n/l/m/x进行添加则只需要指定对应的depth_multiple 和 width_multiple。
# YOLO11n
depth_multiple: 0.50 # model depth multiple
width_multiple: 0.25 # layer channel multiple
max_channel:1024
# YOLO11s
depth_multiple: 0.50 # model depth multiple
width_multiple: 0.50 # layer channel multiple
max_channel:1024
# YOLO11m
depth_multiple: 0.50 # model depth multiple
width_multiple: 1.00 # layer channel multiple
max_channel:512
# YOLO11l
depth_multiple: 1.00 # model depth multiple
width_multiple: 1.00 # layer channel multiple
max_channel:512
# YOLO11x
depth_multiple: 1.00 # model depth multiple
width_multiple: 1.50 # layer channel multiple
max_channel:512
2.3 task.py中注册
在
task.py的parse_model函数中进行注册
- 先在
task.py导入函数
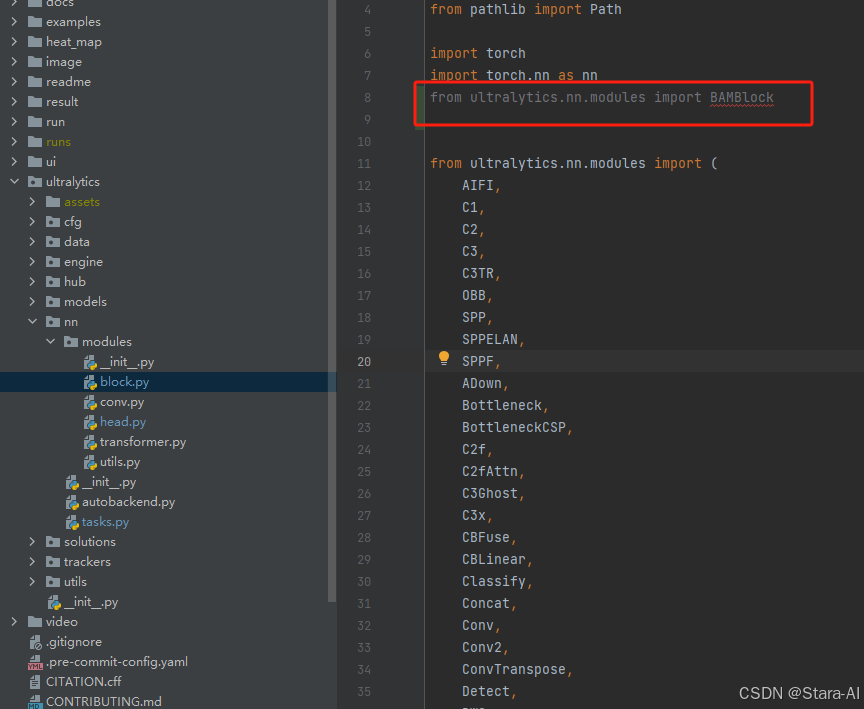
- 在
task.py文件下找到parse_model这个函数,添加BAMBlock

elif m in {BAMBlock}: c1, c2 = ch[f], args[0] if c2 != nc: # if not output c2 = make_divisible(min(c2, max_channels) * width, 8) args = [c1, c2, *args[1:]]
2.4 训练
将model的参数路径设置为
yolo11_BAM.yaml的路径即可
from ultralytics import YOLO
import warnings
warnings.filterwarnings('ignore')
from pathlib import Path
if __name__ == '__main__':
# 加载模型
model = YOLO("ultralytics/cfg/11/yolo11_BAM.yaml") # 你要选择的模型yaml文件地址
# Use the model
results = model.train(data=r"你的数据集的yaml文件地址",
epochs=100, batch=16, imgsz=640, workers=4, name=Path(model.cfg).stem) # 训练模型

2.5 网络结构图

3. 结论与展望
本文通过在YOLO11中引入BAM注意力机制,成功提升了模型在图像分类和目标检测任务中的表现。实验结果表明,BAM不仅能够增强模型的特征表达能力,还能有效改善小目标检测和复杂背景下的鲁棒性。未来的研究方向包括:
- 优化BAM模块设计
进一步优化BAM模块的结构,降低计算开销,同时探索更高效的注意力机制(如CBAM、SENet等)与YOLO系列的结合。- 多任务学习
探索BAM在多任务学习(Multi-Task Learning)场景中的应用,例如联合目标检测与语义分割任务。- 实际场景
在更多实际应用场景中验证改进模型的性能,例如自动驾驶(Autonomous Driving)、无人机监控(Drone Surveillance)等领域。