1、向量(Vector)的概念
(1)、向量的定义
- 向量:在计算机科学中,向量是一组同类型数据的有序集合,例如一个包含多个数值的数组。在数据库中,向量通常指批量数据(如一列数据的多个值组成的集合)。
理解:Java中的一个int数组或String列表等都算一个向量。
示例:
向量 A = [1, 2, 3, 4, 5]
- 向量化(Vectorization):通过单条指令同时对多个数据元素进行操作的技术,例如用一条指令对一个向量中的所有元素执行加法运算。
(2)、向量的特点
- 同质性:向量中的所有元素都属于同一数据类型。
- 连续性:向量中的数据在内存中是连续存储的,这使得访问和操作非常高效。
- 批量处理:可以一次性对整个向量进行操作,而不是逐条处理单个元素。
(3)、向量在ClickHouse中的具体形式
数据块(Block):
ClickHouse将数据按列式存储,每个列的数据被划分为多个数据块(Block)。每个块包含固定数量的行(如8192行),形成一个向量。
示例:
列 “age” 的数据块可能包含 [25, 30, 35, 40, …](默认:8192个值)。SIMD寄存器:
CPU的SIMD(Single Instruction Multiple Data)寄存器(如SSE、AVX)可以同时存储多个数据元素,例如一个 128 位寄存器可存储4个32位整数。向量化执行时,数据块会被加载到这些寄存器中,通过一条指令并行处理多个元素。
2、向量化执行的实现方式
(1)、向量化执行的核心思想
传统行式执行(Row-wise)逐行处理数据,而向量化执行以数据块(向量)为单位处理数据,减少循环次数和函数调用开销。
对比示例:
传统行式方式:循环处理每行 → 处理10000行需要10000次循环;
for i in range(len(data)):
result[i] = data[i] * data[i]
向量化方式:每次处理一个块(如8192行) → 仅需2次循环。
result = [x * x for x in data]
解释:
向量化执行通过SIMD指令(如SSE4.2、AVX)对向量中的多个数据同时执行相同操作,一次可以执行8192个数据,所以只需要2次执行即可。
(2)、ClickHouse的向量化执行流程
- 数据加载:
列式数据从磁盘加载到内存,按固定大小(如8192行)划分为数据块。 - 批量运算:
对每个数据块执行操作(如过滤、聚合、计算),利用SIMD指令并行处理多个元素。 - 结果合并:
各数据块的中间结果合并为最终结果。
(3)、向量化与列式存储的结合
- 列式存储:
数据按列存储,天然适合批量读取和处理(如只读取需要的列)。 - 缓存优化:
连续的列数据块更易被CPU缓存命中,减少内存访问延迟。
3、向量化执行与传统执行方式的对比
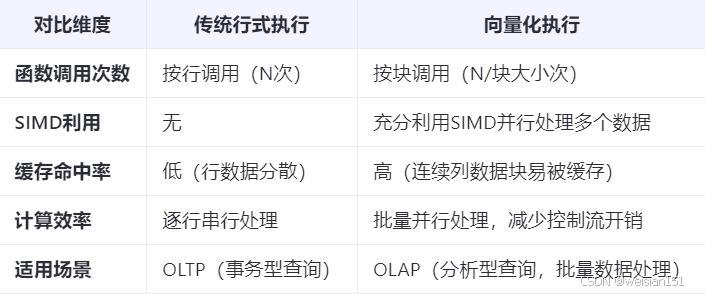
(1)、传统行式执行(Row-wise)的局限
(2)、具体性能提升示例
过滤操作:
传统方式:遍历每行,判断 WHERE age > 30 → 循环次数多。
向量化方式:对数据块 age 列的8192个值同时比较 → 一条指令完成。聚合操作:
传统方式:逐行累加SUM(age) → 8192次加法。
向量化方式:将数据块分成多个SIMD向量,每个向量并行累加 → 减少到约2048次加法。
4、向量化执行的核心优势
(1)、减少函数调用开销
- 传统方式:每行调用函数 → 函数调用次数与行数线性相关。
- 向量化:按块调用 → 函数调用次数减少 块大小 倍。
(2)、提升CPU缓存效率
- 连续列式数据块加载到缓存,减少内存带宽占用和延迟。
- 列式存储结合向量化,可减少I/O和CPU周期。
(3)、利用SIMD并行计算
- 一条指令处理多个数据元素,例如:
- SSE4.2:128位寄存器可同时处理4个32位整数。
- AVX-512:512位寄存器可处理16个32位整数。
(4)、降低控制流开销
- 传统方式:在逐行执行中,条件判断(如if语句)可能导致分支预测失败,破坏CPU流水线,进而引入性能开销。
- 向量化:向量化执行可以通过批量处理避免频繁的分支判断,降低了分支预测失败的概率。
5、总结
向量是一组连续存储的同类型数据,可以看作是一维数组。它是批量处理实现的基础。
向量化执行是一种对整个向量(而非单个元素)进行操作的计算方式。它通过减少指令开销、利用SIMD指令集、提高缓存命中率等手段,显著提升了查询性能。
向量化执行是ClickHouse实现高性能的核心技术,其核心思想是批量处理数据并利用SIMD指令并行计算。通过将数据划分为向量(数据块),ClickHouse显著减少了函数调用次数、优化了CPU缓存使用,并充分利用了现代CPU的SIMD能力。与传统行式执行相比,向量化在分析型查询(如过滤、聚合、排序)中性能提升可达 10-100倍,尤其适用于海量数据的OLAP场景。
关键点:
- 向量 = 数据块 + SIMD并行
- 优势 = 减少开销 + 缓存优化 + 硬件加速
- 适用场景 = 列式存储 + 分析查询
逆风翻盘,Dare To Be!!!