目录
Java Virtual Machine Stacks(Java虚拟机栈)
Class装载到JVM的过程
我的理解是:虚拟机将Class文件加载到内存,并对数据进行校验,转化解析和初始化,形成虚拟机可以直接使用的Java类型,即java.lang.class
分析Java中单例6种实现方式时候,专门还对类文件到虚拟机的过程进行分析了,点击查看对应博客~
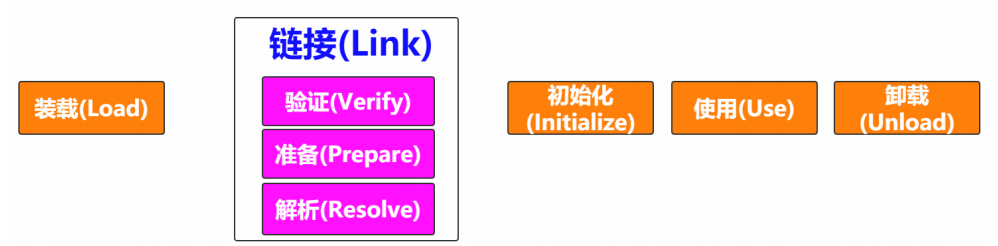
类加载机制是类的字节码文件的数据读入内存中,同时生成数据的访问入口的特殊机制,即类加载的最终产物是数据访问入口。
装载(load)——查找和导入class文件
Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口。在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口
通过一个类的全限定名获取定义此类的二进制字节流
将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
在Java堆中生成一个代表这个类的java.lang.Class对象,作为方法区中数据的访问入口
那么此时,JVM中内容:


正文-------------------
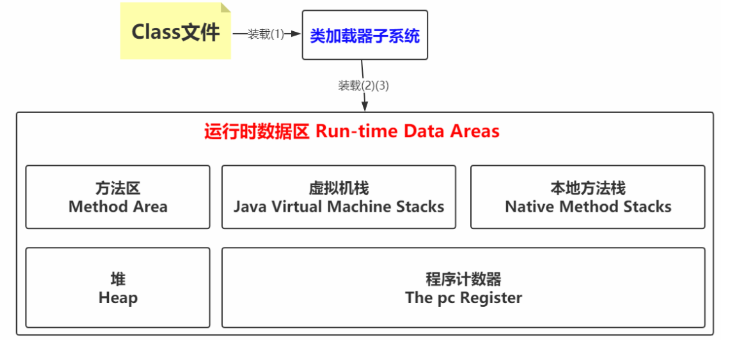
Run-time Data Areas 运行时数据区
可以理解为一种规范。具体的实现可以认为是Java内存模型。
在装载阶段的第(2),(3)步可以发现有运行时数据,堆,方法区等名词
将这个字节流所代表的静态存储结构转化为方法区的运行时数据结构
在Java堆中生成一个代表这个类的java.lang.Class对象,作为对方法区中这些数据的访问入口
说白了就是类文件被类装载器装载进来之后,类中的内容(比如变量,常量,方法,对象等这些数据得要有个去处,也就是要存储起来,存储的位置肯定是在JVM中有对应的空间)

Method Area 方法区
JVM运行时数据区是一种规范,真正的实现在JDK 8中就是Meta Space,在JDK6或7中就是Perm Space
方法区是各个线程共享的内存区域,在虚拟机启动时创建。
The Java Virtual Machine has a method area that is shared among all Java Virtual Machine threads. The method area is created on virtual machine start-up.
虽然Java虚拟机规范把方法区描述为堆的逻辑部分,但是它的别名却是非堆,与Java堆区区分。
Although the method area is logically part of the heap,......
用于存储已经被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
It stores per-class structures such as the run-time constant pool, field and method data, and the code for methods and constructors, including the special methods (§2.9) used in class and instance initialization and interface initialization.
当方法区无法满足内存分配的需求时候,将会抛出OutOfMemoryError异常。
If memory in the method area cannot be made available to satisfy an allocation request, the Java Virtual Machine throws an OutOfMemoryError.

Heap 堆
Java堆是Java虚拟机所管理的内存中最大的一块,在虚拟机启动时创建,被所有的线程共享。
Java对象实例以及数组在堆上分配
The Java Virtual Machine has a heap that is shared among all Java Virtual Machine threads. The heap is the run-time data area from which memory for all class instances and arrays is allocated.
The heap is created on virtual machine start-up.
装载中,在Java堆中生成一个代表这个类的java.lang.Class对象,作为方法区中数据的访问入口——>堆呢
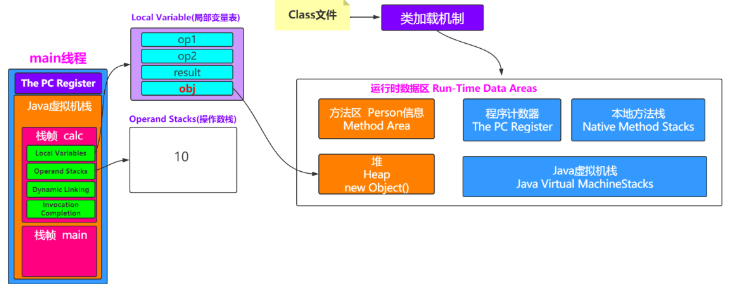
Java Virtual Machine Stacks(Java虚拟机栈)
虚拟机栈是一个线程执行的区域,保存着一个线程中方法的调用状态。换句话说,一个Java线程的运行状态,由一个虚拟机栈来保存,所以虚拟机栈肯定是线程私有的,独有的,随着线程的创建而创建。
Each Java Virtual Machine thread has a private Java Virtual Machine stack, created at the same time as the thread.
每一个被线程执行的方法,为该栈中的栈帧,即每个方法对应一个栈帧。即调用一个方法,就会向栈中压入一个栈帧;一个方法调用完成就会把栈帧从栈中弹出。
A new frame is created each time a method is invoked. A frame is destroyed when its method invocation completes.
栈帧:每个栈帧都对应一个调用的方法,可以理解为一个方法的运行空间。
每个栈帧包括局部变量表、操作数栈、指向运行时常量区的引用、方法返回地址和附加信息。
局部变量表:方法中定义的局部变量以及方法参数存放在这张表。
操作数栈:以压栈、出栈的方式来存储操作数
动态链接:每个栈帧都包含一个指向运行时常量池中该栈帧所属方法的引用,持有这个引用是为了支持方法的调用过程中的动态连接。
方法返回地址:当一个方法开始执行后,只有两种方式可以退出,一种是遇到方法返回的字节码指令,一种是遇到异常时,并且这个异常没有在方法体内得到处理。
The PC Register 程序计数器
线程正在执行Java方法,则计数器记录正在执行的虚拟机字节码指令的地址。
正在执行的是native方法,那么计数器为空
Navtive Mehod Stacks 本地方法栈
如果当前线程执行的方法是Navtive类型,这些方法就会在本地方法栈中执行。
如果在Java方法执行的时候调用native方法,会进行动态链接
其他-------
栈指向堆
如果栈中有个变量,引用类型,如Object a=new Object,这就是典型的栈中元素指向堆中对象。
方法区指向堆
方法区存放静态变量,常量等数据。
private static Object obj=new Object(); 典型从方法区指向栈中对象
堆指向方法区
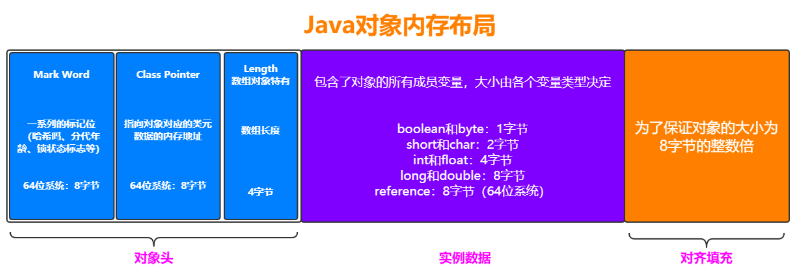
方法区中包括类的信息、堆中对象。如何知道对象是由哪个类创建的?这与Java对象的内存布局有关。
Java中内存布局
内存模型设计之–Class Pointer
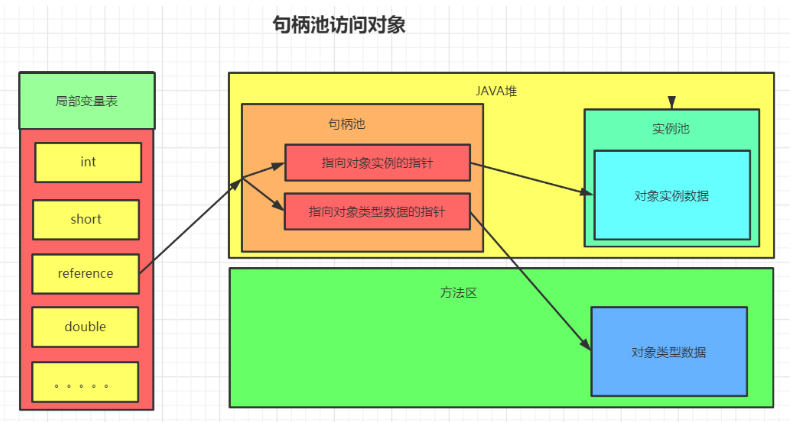
句柄池:
使用句柄访问对象,会在堆中开辟一块内存作为句柄池,句柄中储存了对象实例数据(属性值结构体) 的内存地址,访问类型数据的内存地址(类信息,方法类型信息),对象实例数据一般也在heap中开辟,类型数据一般储存在方法区中。
优点 :reference存储的是稳定的句柄地址,在对象被移动(垃圾收集时移动对象是非常普遍的行为) 时只会改变句柄中的实例数据指针,而reference本身不需要改变。
缺点 :增加了一次指针定位的时间开销。
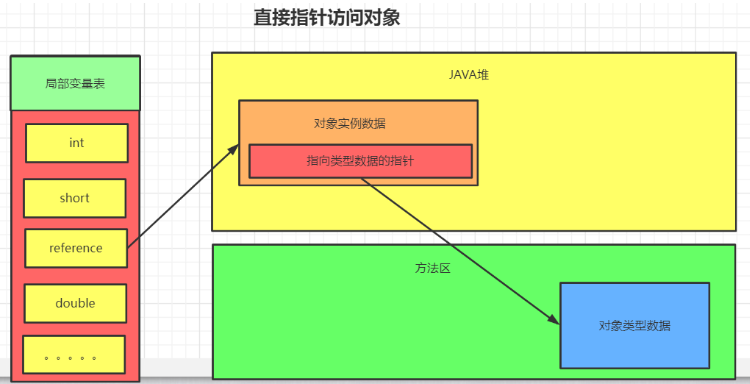
直接访问:
直接指针访问方式指reference中直接储存对象在heap中的内存地址,但对应的类型数据访问地址需要 在实例中存储。
优点 :节省了一次指针定位的开销。
缺点 :在对象被移动时(如进行GC后的内存重新排列),reference本身需要被修改
内存模型设计之–指针压缩
指针压缩的目的:
为了保证CPU普通对象指针(oop)缓存
为了减少GC的发生,因为指针不压缩是8字节,这样在64位操作系统的堆上其他资源空间就少了。 64位操作系统中, 内存 > 4G 默认开启指针压缩技术,内存< 4G,默认是32位系统默认不开启。内存 > 32G 指针压缩失效。所以我们通常在部署服务时,JVM内存不要超过32G,因为超过32G就无法开启 指针压缩了。 内存 > 32G 指针压缩失效的原因是:4G 8 = 32G 32位系统的CPU 最大支持2^32 = 4G ,如果是64位系统,最大支持 2^64, 但是对其填充是按照8字节进行填充,指针压缩可以理解为在32位系统在64位上面使用,因为32位系统的CPU寻址空间最大支持4G,对其填充8 = 32G,这就是内存>32G指针压缩失效的原因。 关闭指针压缩 : -XX:-UseCompressedOops
内存模型设计之–对齐填充
对齐填充的意义是 提高CPU访问数据的效率 ,主要针对会存在该实例对象数据跨内存地址区域存储的情况。
例如:在没有对齐填充的情况下,内存地址存放情况如下:

因为处理器只能0x00-0x07,0x08-0x0F这样读取数据,所以当我们想获取这个long型的数据时,处理 器必须要读两次内存,第一次(0x00-0x07),第二次(0x08-0x0F),然后将两次的结果才能获得真正的数值。
那么在有对齐填充的情况下,内存地址存放情况是这样的:

现在处理器只需要直接一次读取(0x08-0x0F)的内存地址就可以获得我们想要的数据了。
当我们的策略为0时,这个时候我们的排序是 基本类型>填充字段>引用类型
当我们策略为1时,引用类型>基本类型>填充字段;策略为2时,父类中的引用类型跟子类中的引用类型放在一起 父类采用策略0 子类采用策略1,
这样操作可以降低空间的开销。