目录
蓝耘元生代:智算新势力崛起

在人工智能飞速发展的时代浪潮中,算力作为核心驱动力,正重塑着各个行业的发展格局。蓝耘科技,一家在信息技术领域深耕多年的企业,敏锐捕捉到这一发展趋势,凭借其前瞻性的战略眼光和强大的技术实力,推出了具有里程碑意义的 “元生代” 智算云平台,在人工智能领域迅速崛起,成为备受瞩目的智算新势力。
蓝耘科技的发展历程,是一部不断顺应时代潮流、积极创新变革的奋斗史。公司自成立以来,最初在信息系统集成领域辛勤耕耘,积累了丰富的技术经验和行业资源。随着云计算和大数据技术的兴起,公司创始人李健敏锐地洞察到人工智能时代即将来临,果断调整战略方向,开启了向 AI 算力领域的转型之路。从 2018 年开始,蓝耘科技大力投资建设自有算力基础设施,前瞻性地布局 GPU 硬件资源,为后续的发展奠定了坚实基础。截至目前,蓝耘已构建规模超万 P 的算力资源,在算力资源管理调度、性能调优及运维运营等方面具备了可复制的工程化能力,成功实现了从幕后到 AI 时代舞台中央的华丽转身。
2024 年 11 月 28 日,蓝耘科技在杭州隆重举行以 “智算蓝图,耘领未来” 为主题的战略与产品发布会,正式推出 “元生代” 智算云平台,这一举措在人工智能领域引起了广泛关注。“元生代” 智算云平台基于 Kubernetes 原生云设计,充分整合了大规模 GPU 算力资源,具有卓越的性能和强大的功能。它实现了从数据准备、代码开发、模型训练到推理部署等全场景覆盖,为用户提供了一站式的 AI 研发解决方案,能够高效赋能用户 AI 研发全流程,大大降低了 AI 开发的门槛,让中小开发者也能轻松接入与世界顶级 AI 巨头相媲美的算力服务 ,真正推动了人工智能技术的普及和应用。
在当今竞争激烈的人工智能市场中,蓝耘元生代凭借其独特的优势脱颖而出。它拥有强大的算力调度能力,无论是裸金属调度还是容器调度,都能满足不同用户的多样化需求。裸金属调度给予用户更多的自由发挥空间,使其能够根据自身需求灵活配置资源;容器调度则依托方便快捷的调度能力,帮助纳管伙伴闲置的算力资源,实现资源的高效利用,能够在分钟级打造一个自己品牌的算力平台,极大地提高了资源的利用率和运营效率。
元生代还搭建了丰富的应用市场,预集成了如 Stable Diffusion 等热门模型的容器化封装,方便开发者快速验证业务场景,加速项目的开发进程。同时,它支持用户自助上传镜像,为开发者在社区打造个人 IP、开辟变现渠道提供了便利条件,进一步激发了开发者的创新活力和创造力。其 AI 协作开发模块更是充分考虑了团队协作场景,通过前台、中台和后台的全面协同,帮助开发者高效完成从数据准备到模型训练与部署的全流程。前台为开发工程师集成了常用的开发套件、存储调用、镜像仓库及高灵活度的资源调度,并进行了一系列后台优化,如计算网络轨道调优、NUMA 亲和性调度、分布式缓存等,可实现将自定义任务运行于同一组 Leaf 交换机上,有效提高了训练效率;中台主要为用户的运维团队提供集群基础设施级别的监控指标,帮助运维人员更好地追踪训练任务各个阶段的资源使用水位线,进一步优化资源分配,提高训练效率;后台则为非技术人员提供运营和财务等相关功能,确保整个项目的顺利运营和管理。
蓝耘元生代在人工智能发展浪潮中占据着重要地位,其推出的 “元生代” 智算云平台为用户提供了强大的算力支持和一站式的 AI 研发解决方案,推动了人工智能技术的普及和应用。而在其品牌建设过程中,平台实现工作流(如 ComfyUI)的创建与云原生后端之间存在着紧密的联系,这种联系对于提升平台的性能、用户体验以及推动人工智能的发展具有重要意义,接下来我们将深入探讨它们之间的内在关联。
ComfyUI 工作流创建详解
ComfyUI 初印象
ComfyUI 是一款基于 Python 的图形界面工具,在 AI 绘图领域展现出独特魅力。它以直观的节点连接方式构建工作流,用户无需编写复杂代码,就能轻松实现各种 AI 绘图任务 ,大大降低了技术门槛,让更多艺术创作者和爱好者能够投身于 AI 绘画的奇妙世界。
与传统的 AI 绘图工具相比,ComfyUI 具有诸多优势。它的模块化设计极为灵活,将复杂的 AI 绘图流程拆解为一个个独立的节点,每个节点都有明确的功能,如加载模型、处理文本提示词、采样去噪等。用户可以像搭建积木一样,根据自己的需求自由组合这些节点,构建出个性化的工作流。这种高度自定义的特性,使得用户能够深入控制图像生成的每一个环节,实现更加精细和独特的创作效果。ComfyUI 还具有出色的效率表现。一旦用户确定了一个有效的工作流,就可以将其保存并重复使用,就像建立了一条高效的生产流水线,只需调整输入的文本提示词、参数等内容,就能快速生成一系列符合预期的图像,特别适合需要批量生成图像的场景,如游戏素材制作、插画创作等,极大地提高了工作效率。
蓝耘平台上搭建 ComfyUI 工作流
在蓝耘平台部署 ComfyUI 工作流,是开启高效 AI 绘图之旅的关键一步。具体操作流程如下:
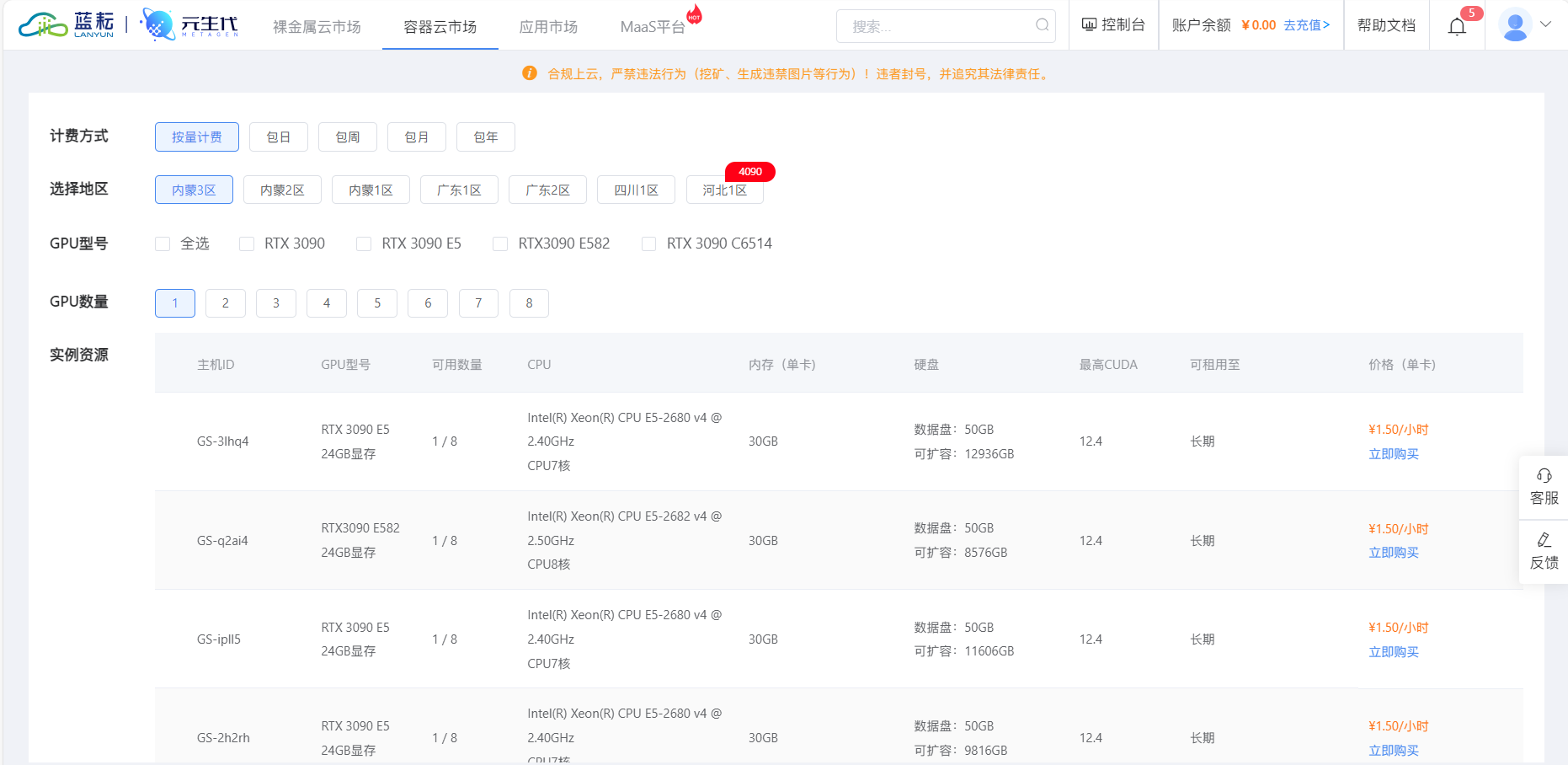
- 登录蓝耘平台:打开浏览器,访问蓝耘 GPU 智算云平台官网(https://cloud.lanyun.net//#/registerPage?promoterCode=0131 )。新用户需先进行注册,注册成功后即可享受免费体验 18 小时算力的优惠。登录后,用户将进入蓝耘平台的控制台,在这里可以看到丰富的功能模块,如容器云市场、应用市场等 。
- 部署 ComfyUI 镜像:在应用市场中,用户可以找到 SDcomfyUI 镜像,这是集成了 ComfyUI 的深度学习模型镜像。点击部署镜像,平台会提供多种计费方式供用户选择,用户可根据自身需求和预算进行挑选,选择完成后点击立即购买。随后,系统会跳转到工作台,用户只需耐心等待部署成功即可 。
- SSH 连接服务器:部署成功后,使用 Win+R 键打开命令行窗口,将平台提供的 SSH 命令复制粘贴到命令行中,并输入 SSH 密码(输入密码时屏幕不会显示,直接回车即可)。连接成功后,用户可以看到服务器的基本配置信息,这表明已经成功连接到部署了 ComfyUI 的服务器 。
- 启动 ComfyUI 应用:在成功连接服务器后,按照平台的提示信息,输入相应的命令启动 ComfyUI 应用。启动完成后,用户即可进入 ComfyUI 的操作界面。在这个界面中,用户可以通过按住鼠标左键拖动来全面查看每一个工作流,滚动鼠标滚轮来放大或缩小工作流视图,操作十分便捷 。


蓝耘平台采用了 @風吟 chenkin 老师精心制作的整合包,该整合包预先内置了众多丰富多样的大模型,涵盖了各种风格,从写实到卡通,从古风到现代,应有尽有,为用户的创作提供了广阔的素材库,用户无需再花费大量时间和精力去寻找和下载模型,即可轻松生成各式各样风格的图片 。
构建基础工作流实操
构建基础的 ComfyUI 工作流,是实现 AI 绘图的核心步骤,具体操作如下:
- 加载大模型:在 ComfyUI 操作界面的空白处单击鼠标右键,选择 Add Node(添加节点),在弹出的二级菜单中选择 loaders—Load Checkpoint,即可得到一个简易的 Checkpoint 加载器。长按鼠标左键拖动该加载器到合适位置,然后选择下方的大模型框,用户可以浏览到其中内置的多种不同风格的大模型,从中挑选出符合自己创作需求的模型 。
- 配置正负词 CLIP 文本编码器:再次单击鼠标右键,依次点击 Add Node—conditioning—CLIP Text Encode (Prompt),得到一个正负词提示框。使用快捷键 “ctrl C + ctrl V” 复制该提示框,这样就有了两个提示框,一个用于填写正向提示词,描述用户希望生成图像中包含的元素、风格、场景等内容;另一个用于填写负向提示词,用来排除不希望出现在图像中的元素,以更精准地控制图像生成方向 。
- 连接节点:将加载大模型的 CLIP 与正负词提示框对应的节点端口按颜色和名称匹配连接起来。就像连接电子设备的线路一样,只有正确连接节点,才能实现数据的流通和处理。连接完成后,这些节点就初步形成了一个数据处理的链条,为后续的图像生成奠定基础 。
- 添加 KSampler(K 采样器):点击鼠标右键,在 Sampling(采样)选项中找到 KSampler。KSampler 在 SDcomfyUI 中负责非常重要的采样去噪环节,它决定了图像生成过程中的噪声去除方式和采样策略,对最终生成图像的质量和细节有着关键影响 。
- 设置 KSampler 参数:在 KSampler 节点中,有许多重要参数需要设置。其中,control_after_generate 选项有 fixed、increment、derement、randomize 四个选项,用于控制生成图像后随机种子(seek)的变化方式。fixed 表示每次生成后 seek 固定不变,increment 表示每次生成后 seek 加 1,derement 表示每次生成后 seek 减 1,randomize 表示每次生成后 seek 随机变化 。CFG(Classifier Free Guidance)即无分类器指导,是一个与提示词引导强度相关的参数,该值越高,生成图像与提示词的贴合度越高,但图像质量可能会有所下降,一般该值不会超过 8 。采样器和调度器也有多种选择,不同的采样器和调度器组合适用于不同的图像生成需求。例如,euler 类采样器适用于二次元风格图像的生成,dpmpp_2m 类采样器搭配 karras 调度器,在生成写实摄影人像时表现出色,推荐迭代步数在 20 - 30 之间;dpmpp_sde 类采样器则对图片的细节部位处理非常到位 。步数(step)参数表示生成图像的过程中执行的步骤数量,理论上步数越多,生成的图像越清晰、越符合预期,但生成速度也会相应变慢 。
- 连接其他节点:将 KSampler 节点的闲置端口按照其含义和颜色与其他相关节点连接起来。此时,还剩下两个闲置端口,一个名为 modle,将其与最初创建的 Checkpoint 加载器相连接;另一个端口名为 Latent(潜空间),在空白处右键单击鼠标,在 Latent(潜空间)分类下找到 Empty Latent Image(空白潜空间图像)并点击创建,然后将它的端口与之前预留的空余端口相互连接起来,通过这个连接,用户可以控制生成图像的长宽比以及生成次数 。
- 添加保存图像节点:为了保存生成的图像,需要添加一个用于接收和保存图片的工作框(Save Images)。右键单击,在 Image 内找到并建立该节点。但此时会发现它的端口颜色与含义与前面所有工作框都对不上,这时就需要一个 “转接器”,即 VAE(变分自编码器)。将 VAE 的两个端口与相应的地方连接起来,完成整个工作流的搭建 。
完成上述步骤后,一个基础的 ComfyUI 工作流就搭建完成了。用户只需在相应的提示词框中输入想要生成图像的正负词,设置一些其他风格参数,然后点击右边的 Queue Prompt(添加提示词队列),就可以等待 ComfyUI 按照工作流的设定,逐步生成心仪的图片。在生成过程中,用户可以通过高亮的工作框,清晰地看到每个流程运转到的节点位置,直观了解图像生成的进度和过程 。
代码示例与原理剖析
在 ComfyUI 中,虽然用户主要通过图形界面进行工作流的搭建,但了解其背后的代码原理,有助于更深入地理解和优化工作流。以下是一个用 Python 伪代码展示如何定义一个简单的 ComfyUI 工作流节点的示例:
class WorkflowNode:
def __init__(self, name, inputs=None, outputs=None):
self.name = name
self.inputs = inputs or []
self.outputs = outputs or []
# 定义一个简单的图像生成器节点示例
node_example = WorkflowNode('Image Generator', ['prompt'], ['image'])在这个示例中,WorkflowNode类定义了一个工作流节点的基本结构。__init__方法用于初始化节点,接受节点名称name,以及输入inputs和输出outputs列表。inputs列表用于指定节点所需的输入数据,outputs列表用于指定节点产生的输出数据 。node_example是一个具体的节点实例,它被命名为 “Image Generator”,表示这是一个用于图像生成的节点。它的输入为['prompt'],意味着该节点需要接收一个文本提示词作为输入,以指导图像生成;输出为['image'],表示该节点最终会生成一张图像作为输出 。
云原生后端技术全景
云原生后端概念解析
云原生后端是一种基于云计算技术和理念构建的后端系统架构,其设计与运行紧密依托云计算环境,旨在充分挖掘云计算的潜力,实现应用程序的灵活部署、高效扩展和可靠运行 。在云原生后端架构中,应用程序及其依赖项被精心打包到容器中,这些容器就像是一个个独立的 “小盒子”,里面装着运行应用所需的一切,从代码、运行时环境到各类库和配置文件,确保应用在不同的环境中都能以一致的方式运行 。
以一个电商应用为例,传统的后端架构可能将所有功能模块紧密耦合在一起,部署在物理服务器上。当业务量突然增加时,很难快速扩展资源以应对高并发,而且不同环境(开发、测试、生产)之间的配置差异可能导致各种兼容性问题。而采用云原生后端架构,电商应用的各个功能模块,如商品管理、订单处理、用户服务等,会被拆分成独立的微服务,并分别打包成容器 。这些容器可以轻松地在不同的云环境中部署,无论是公有云、私有云还是混合云。当促销活动导致订单处理模块的流量激增时,云原生后端能够自动快速地增加该模块对应的容器实例数量,实现弹性伸缩,确保系统稳定运行,同时在不同环境中的一致性也极大地降低了开发和运维的难度 。
核心技术深度解读
1.容器化(Docker):容器化技术是云原生后端的基石,而 Docker 则是其中的佼佼者。Docker 通过 Linux 内核的 Namespaces 和 Cgroups 特性来实现资源的隔离和限制 。Namespaces 提供了进程、网络、挂载点、用户等资源的隔离,就像为每个容器打造了一个独立的小世界,容器内的进程无法感知到容器外的其他进程和资源,保证了容器之间的相互隔离 。Cgroups 用于限制、记录和隔离进程组所使用的物理资源,如 CPU、内存、磁盘 I/O 等,确保每个容器不会过度占用资源 。
在实际应用中,开发人员可以使用 Dockerfile 来定义镜像的创建过程。例如,对于一个基于 Python Flask 框架的 Web 应用,其 Dockerfile 可能如下:
# 使用Python官方镜像作为基础镜像
FROM python:3.10-slim
# 设置工作目录
WORKDIR /app
# 复制项目文件到容器内
COPY. /app
# 安装项目依赖
RUN pip install -r requirements.txt
# 暴露应用端口
EXPOSE 5000
# 定义容器启动时执行的命令
CMD ["python", "app.py"]通过这个 Dockerfile,开发人员可以轻松构建一个包含该 Web 应用及其所有依赖的 Docker 镜像。这个镜像可以在任何支持 Docker 的环境中运行,无论是开发人员的本地机器,还是生产环境的云服务器,都能保证应用的一致性运行 。
2. 微服务架构:微服务架构将应用程序拆分为多个小型、独立的服务单元,每个服务专注于执行特定的业务功能 。这些服务遵循单一职责原则,具有高度的自治性,它们之间通过轻量级的通信机制(如 HTTP API、消息队列等)进行交互 。以一个在线教育平台为例,它可以拆分为用户管理服务、课程管理服务、订单服务、直播服务等多个微服务 。用户管理服务负责处理用户的注册、登录、信息修改等功能;课程管理服务负责课程的添加、编辑、删除、展示等操作;订单服务处理用户购买课程的订单流程;直播服务则专注于实现课程直播的功能 。每个微服务都可以独立开发、测试、部署和扩展,不同的团队可以负责不同的微服务,提高了开发效率和系统的可维护性 。当某个微服务需要升级或修改时,不会影响其他服务的正常运行 。例如,如果课程管理服务需要添加新的课程类型,开发团队可以独立对该服务进行开发和部署,而不会对其他服务造成干扰 。
3. Kubernetes(K8s):Kubernetes 是业界标准的容器编排平台,犹如一个智能的指挥官,负责管理和调度容器集群,确保服务的高可用性和可扩展性 。它可以根据资源需求和负载情况,自动分配容器到合适的节点上运行 。Kubernetes 支持自动扩展、负载均衡和滚动更新等重要功能 。在一个大型的电商系统中,在促销活动期间,订单量会急剧增加,Kubernetes 可以根据预设的规则,自动快速地增加订单处理服务的容器副本数量,以应对高并发的订单处理需求 。当活动结束后,它又能自动减少容器副本数量,避免资源浪费 。在进行服务升级时,Kubernetes 的滚动更新功能可以逐步替换旧版本的容器为新版本,确保服务在升级过程中不中断,用户几乎感知不到服务的更新过程 。
4. 持续集成 / 持续部署(CI/CD):持续集成 / 持续部署通过自动化构建、测试和部署流程,实现快速迭代和持续交付,大大缩短了开发周期 。持续集成强调开发人员频繁地将代码合并到主干分支,每次合并都会触发自动构建和测试,确保代码的质量 。持续交付则是自动将通过测试的代码部署到预生产环境,准备随时发布到生产环境 。持续部署进一步自动化,将通过测试的代码直接部署到生产环境 。在一个移动应用开发项目中,开发人员每天多次提交代码到代码仓库,每次提交都会触发 CI 流程 。CI 工具(如 Jenkins、GitLab CI/CD 等)会自动拉取代码,进行编译、单元测试、集成测试等操作 。如果测试通过,代码会被自动部署到预生产环境进行进一步的测试和验证 。当一切准备就绪,通过 CD 流程,代码可以快速、可靠地部署到生产环境,让用户及时体验到新功能和修复的问题 。
蓝耘元生代中两者的紧密联系
工作流对云原生后端的需求
在蓝耘元生代的 AI 绘图业务场景中,ComfyUI 工作流的运行对云原生后端有着多方面的迫切需求。随着用户对 AI 绘图的热情不断高涨,蓝耘元生代平台上的绘图任务量呈爆发式增长,这就要求云原生后端具备强大的资源动态分配能力 。当大量用户同时发起复杂的 AI 绘图任务时,每个任务对计算资源(如 GPU、CPU、内存等)的需求各不相同,而且任务的执行时间也长短不一 。云原生后端需要能够实时监测这些任务的资源需求变化,像一位智能的资源管家,根据任务的优先级、复杂程度等因素,动态地为每个 ComfyUI 工作流分配最合适的资源 。对于一些紧急且资源需求大的商业项目绘图任务,云原生后端要优先保障其所需的 GPU 资源,确保任务能够高效完成,避免因资源不足而导致任务卡顿或失败 。
高并发处理能力也是云原生后端不可或缺的。在蓝耘元生代平台上,每天都有成千上万的用户同时使用 ComfyUI 工作流进行 AI 绘图,这就产生了极高的并发请求 。云原生后端需要像一座坚固的桥梁,能够稳定地承载这些高并发请求,确保每个用户的绘图任务都能得到及时响应 。它需要具备高效的网络通信机制,快速地接收和处理用户的请求数据,同时要合理地分配计算资源,避免因并发过高而导致系统崩溃 。如果云原生后端无法处理高并发,就会出现用户请求长时间等待、绘图任务无法及时启动等问题,严重影响用户体验 。
服务弹性扩展能力同样至关重要。当蓝耘元生代平台迎来流量高峰,如举办 AI 绘图比赛、推出热门绘图活动时,平台上的 ComfyUI 工作流数量会急剧增加 。此时,云原生后端需要像一个灵活的变形金刚,能够根据实际的工作负载,自动快速地扩展服务资源 。它可以通过增加容器实例的数量,为更多的 ComfyUI 工作流提供运行环境,确保平台在高负载情况下依然能够稳定运行 。当流量高峰过去,云原生后端又能自动缩减资源,避免资源的浪费,降低运营成本 。如果云原生后端不具备弹性扩展能力,在流量高峰时,平台就会出现运行缓慢、甚至无法响应的情况,导致用户流失 。
云原生后端对工作流的支撑
云原生后端通过多种关键技术,为 ComfyUI 工作流在蓝耘元生代平台上的高效稳定运行提供了坚实支撑 。
容器化部署 ComfyUI 是云原生后端的重要举措。通过将 ComfyUI 及其依赖项打包成 Docker 容器,实现了环境的一致性和隔离性 。每个容器就像是一个独立的小世界,里面包含了 ComfyUI 运行所需的所有组件,从 Python 运行环境、各种依赖库,到 ComfyUI 的代码和配置文件 。这样,无论在开发、测试还是生产环境中,ComfyUI 都能以相同的方式运行,避免了因环境差异而导致的兼容性问题 。在开发阶段,开发人员可以在本地的 Docker 容器中进行 ComfyUI 的开发和测试,确保代码在各种环境中的一致性 。当将 ComfyUI 部署到生产环境时,只需要将相同的 Docker 镜像推送到生产服务器上运行即可 。容器的隔离性还保证了不同的 ComfyUI 工作流之间不会相互干扰,一个工作流出现问题,不会影响其他工作流的正常运行 。
利用微服务架构优化工作流模块,也是云原生后端的一大优势。云原生后端将 ComfyUI 工作流中的各个功能模块,如模型加载、图像生成、后处理等,拆分成独立的微服务 。每个微服务都专注于实现一个特定的功能,具有高度的自治性 。这些微服务之间通过轻量级的通信机制(如 HTTP API、消息队列等)进行交互 。以模型加载微服务为例,它专门负责从存储中读取各种 AI 绘图模型,并将其加载到内存中,供其他微服务使用 。当图像生成微服务需要使用模型时,只需通过 HTTP API 向模型加载微服务发送请求,获取所需的模型即可 。这种微服务架构使得每个模块都可以独立开发、测试、部署和扩展,提高了开发效率和系统的可维护性 。如果需要优化图像生成微服务的算法,开发团队可以独立对其进行修改和部署,而不会影响其他微服务的正常运行 。
借助 Kubernetes 实现资源调度,是云原生后端保障 ComfyUI 工作流高效运行的关键。Kubernetes 就像是一个智能的指挥官,负责管理和调度容器集群 。它可以根据 ComfyUI 工作流的资源需求和负载情况,自动分配容器到合适的节点上运行 。当一个 ComfyUI 工作流需要大量的 GPU 资源进行图像生成时,Kubernetes 会根据集群中各个节点的 GPU 资源使用情况,将该工作流对应的容器调度到 GPU 资源充足的节点上 。Kubernetes 还支持自动扩展、负载均衡和滚动更新等重要功能 。在高并发情况下,Kubernetes 可以根据预设的规则,自动快速地增加 ComfyUI 工作流相关容器的副本数量,实现负载均衡,确保每个工作流都能得到及时处理 。在进行 ComfyUI 版本升级时,Kubernetes 的滚动更新功能可以逐步替换旧版本的容器为新版本,确保服务在升级过程中不中断,用户几乎感知不到服务的更新过程 。
代码层面的集成示例
在云原生环境中部署 ComfyUI 工作流,涉及到一系列的配置和代码实现,以下是一些关键的示例。
Kubernetes 配置文件是部署 ComfyUI 工作流的重要依据,以下是一个简单的 Kubernetes Deployment 配置文件示例:
apiVersion: apps/v1
kind: Deployment
metadata:
name: comfyui-deployment
spec:
replicas: 3
selector:
matchLabels:
app: comfyui
template:
metadata:
labels:
app: comfyui
spec:
containers:
- name: comfyui-container
image: your-comfyui-image:latest
ports:
- containerPort: 8080
resources:
requests:
memory: "512Mi"
cpu: "0.5"
limits:
memory: "1Gi"
cpu: "1"在这个配置文件中,apiVersion指定了 Kubernetes API 的版本 。kind表明这是一个 Deployment 资源,Deployment 用于定义和管理一组 Pod 的副本 。metadata.name为该 Deployment 指定了名称为comfyui - deployment 。spec.replicas设置为 3,表示期望创建 3 个 Pod 副本,以提高服务的可用性和处理能力 。spec.selector.matchLabels定义了选择器,用于选择与标签app: comfyui匹配的 Pod 。spec.template.metadata.labels则为 Pod 模板添加了相同的标签,确保 Pod 能够被正确选择 。在spec.template.spec.containers部分,定义了容器的相关信息 。name为容器指定了名称comfyui - container 。image指定了要使用的 ComfyUI Docker 镜像,这里假设镜像名为your - comfyui - image:latest,其中latest表示镜像的版本标签 。ports部分定义了容器要暴露的端口,这里将容器的 8080 端口暴露出来,以便外部可以访问 ComfyUI 服务 。resources.requests和resources.limits分别定义了容器对内存和 CPU 资源的请求量和限制量 。请求量表示容器期望获得的资源量,限制量则防止容器使用过多的资源,影响其他容器的正常运行 。这里请求 512Mi 内存和 0.5 个 CPU 核心,限制为 1Gi 内存和 1 个 CPU 核心 。
在云原生环境中,服务注册与发现是实现微服务之间通信的关键机制 。以使用 Consul 作为服务注册与发现工具为例,以下是一个简单的 Python 代码示例,展示如何在 ComfyUI 相关微服务中实现服务注册:
import consul
import time
# 初始化Consul客户端
c = consul.Consul()
# 服务名称和地址
service_name = 'comfyui - model - loader'
service_address = '10.0.0.10'
service_port = 8081
# 注册服务
try:
c.agent.service.register(
name=service_name,
address=service_address,
port=service_port,
check=consul.Check.tcp(service_address, service_port, '10s')
)
print(f'{service_name} 已成功注册到Consul')
except Exception as e:
print(f'服务注册失败: {e}')
# 保持服务运行
try:
while True:
time.sleep(1)
except KeyboardInterrupt:
# 注销服务
c.agent.service.deregister(service_name)
print(f'{service_name} 已从Consul注销')
在这段代码中,首先导入了consul库,用于与 Consul 服务器进行交互 。然后初始化了一个 Consul 客户端c 。接着定义了要注册的服务名称service_name、服务地址service_address和服务端口service_port 。在try块中,使用c.agent.service.register方法将服务注册到 Consul 服务器 。其中,check参数定义了一个健康检查,这里使用 TCP 检查,每 10 秒检查一次服务是否正常运行 。如果服务注册成功,会打印提示信息 。在while True循环中,使用time.sleep(1)让程序保持运行状态 。当用户通过键盘中断程序时,会进入except KeyboardInterrupt块,使用c.agent.service.deregister方法将服务从 Consul 服务器注销,并打印注销提示信息 。通过服务注册与发现,其他微服务(如图像生成微服务)可以通过 Consul 服务器轻松找到模型加载微服务的地址和端口,实现相互之间的通信和协作 。
总结
蓝耘元生代品牌建设中,ComfyUI 工作流与云原生后端的紧密联系是其在 AI 领域取得成功的关键因素之一。ComfyUI 工作流以其直观、灵活的特点,为用户提供了强大的 AI 绘图创作能力,降低了创作门槛,激发了用户的创造力。而云原生后端则凭借容器化、微服务架构、Kubernetes 等核心技术,为 ComfyUI 工作流提供了稳定、高效、可扩展的运行环境,确保了在高并发、大规模任务处理场景下的可靠性和性能。