核心内容:
1. 基础开发流程
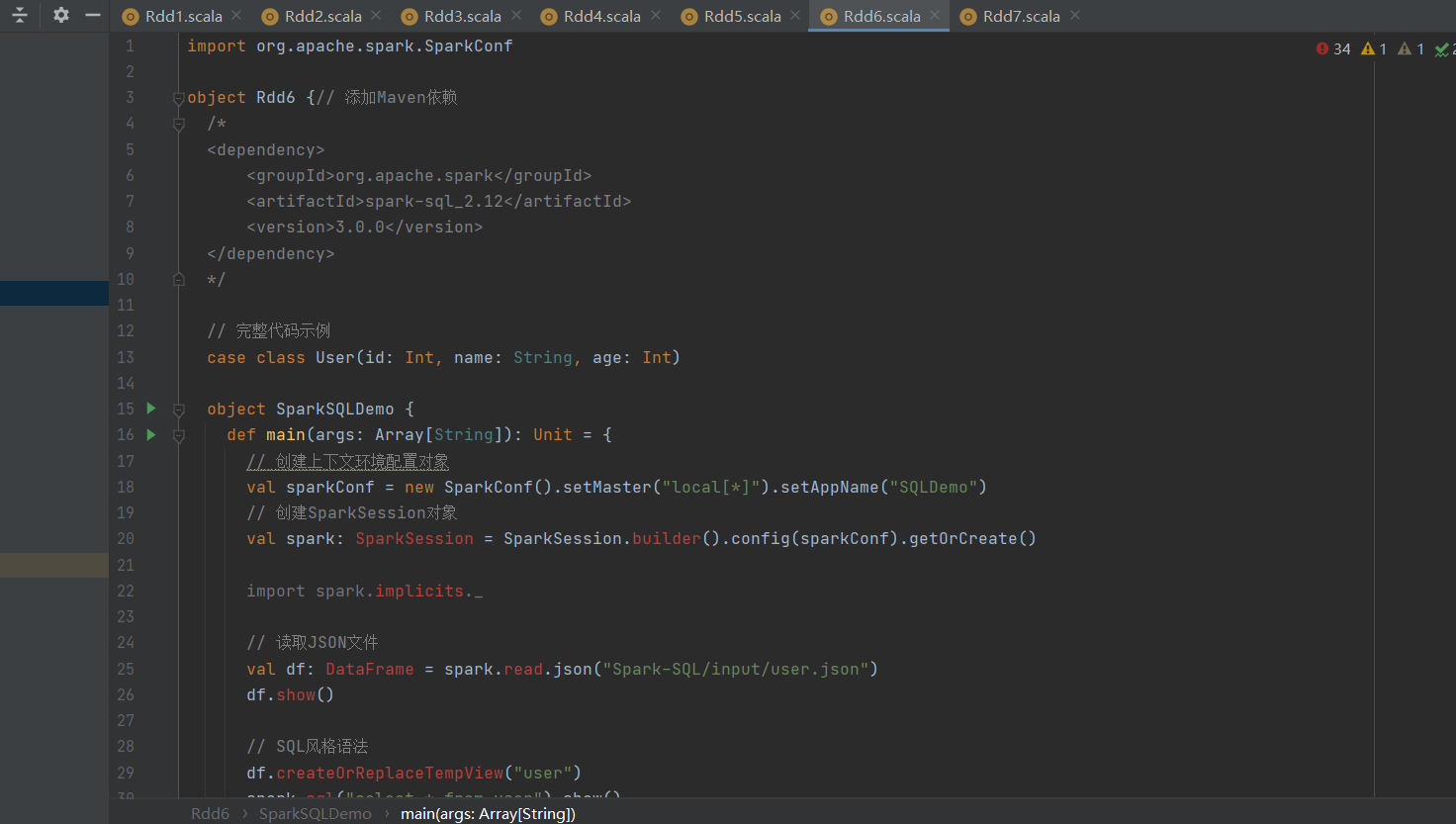
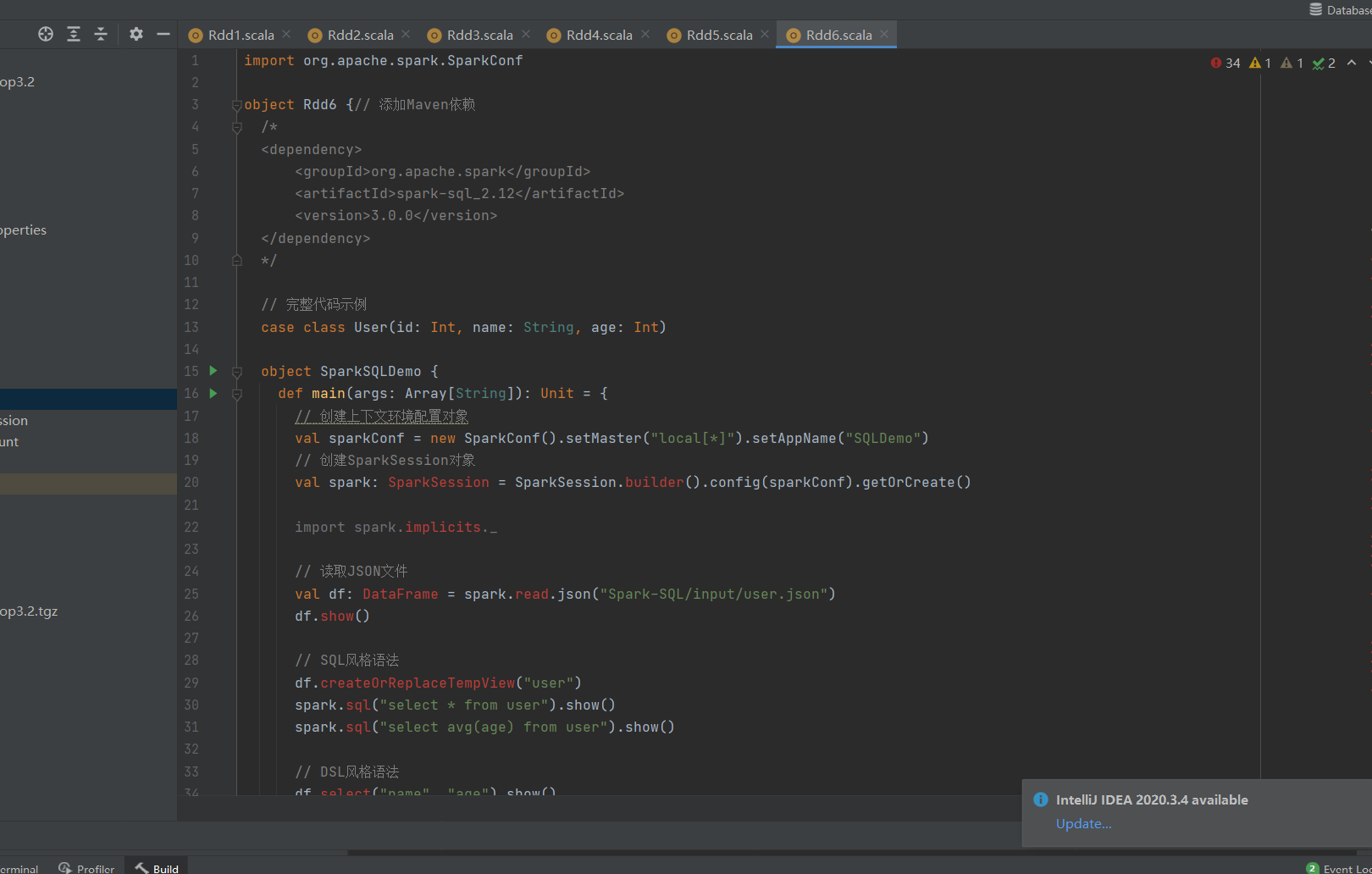
使用IDEA创建Spark-SQL模块,添加Maven依赖(`spark-sql_2.12`)。
通过`SparkSession`初始化Spark环境,配置本地模式(`local[*]`)。
2. 数据操作
数据读取:从JSON文件加载数据到DataFrame,并展示(`spark.read.json` + `show()`)。
查询方式:
SQL风格:注册临时视图(`createOrReplaceTempView`)后执行SQL语句(如`SELECT avg(age)`)。
DSL风格:使用DataFrame API(如`select("name", "age")`)。
数据转换:
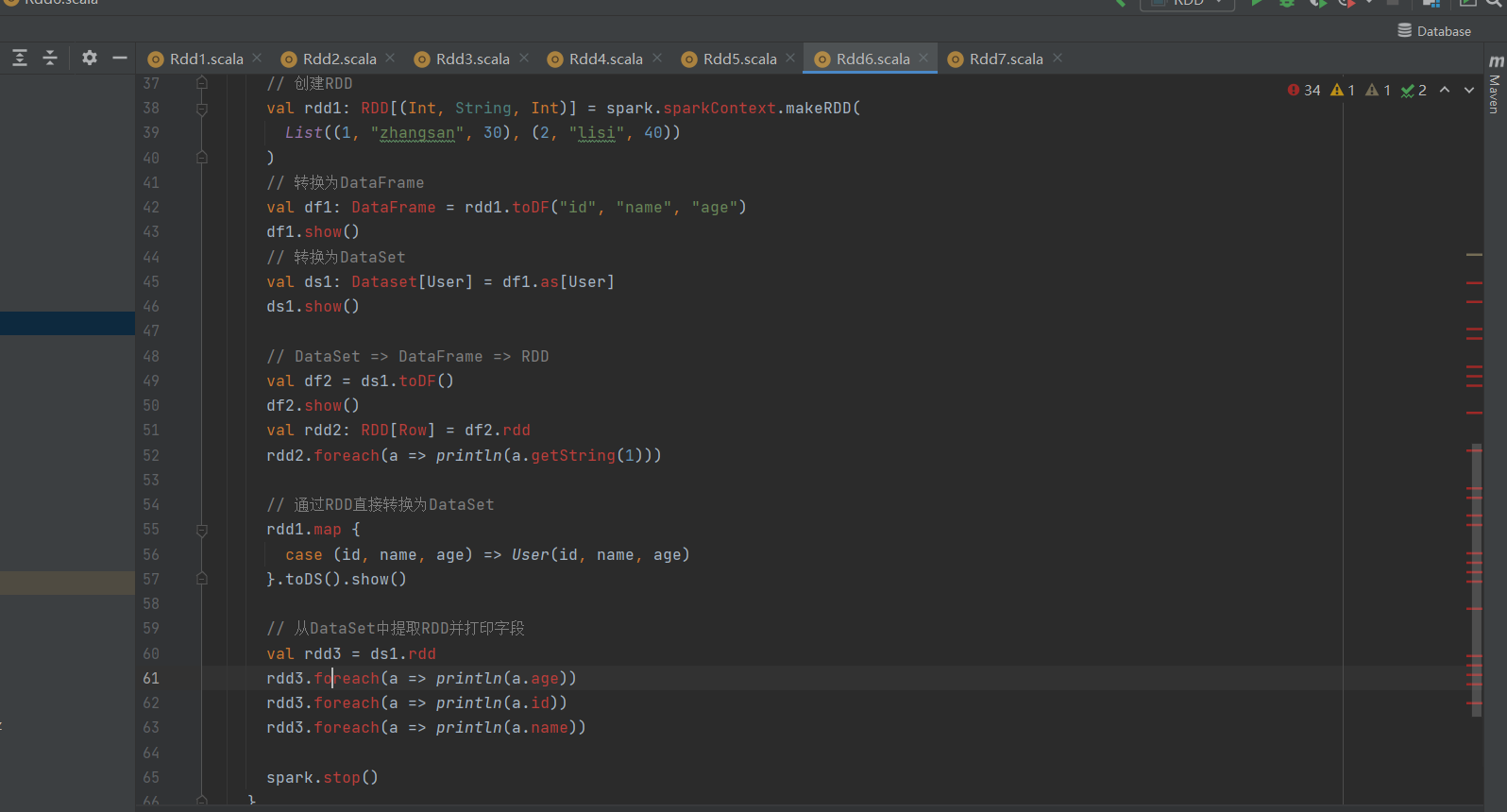
RDD ↔ DataFrame ↔ DataSet:
RDD转DataFrame(`toDF("列名")`)、DataFrame转DataSet(`as[User]`)。
DataSet转RDD(`.rdd`)并访问字段(如`a.age`)。
3. 关键类与概念
`User`样例类:用于DataSet的强类型操作。
`SparkSession`:统一入口,替代旧版`SQLContext`和`SparkContext`。
核心内容:
1. 自定义函数(UDF)
UDF:简单的列级别转换(如添加前缀)。
注册:`spark.udf.register("addName", (x: String) => "Name:" + x)`。
调用:通过SQL语句(`SELECT addName(name)`)。
2. 自定义聚合函数(UDAF)
实现方式对比:
RDD方式:手动计算总和与计数(`map` + `reduce`),适合灵活但冗长的逻辑。
弱类型UDAF(旧版):继承`UserDefinedAggregateFunction`,需定义输入/缓冲/输出结构(已过时)。
强类型UDAF(Spark 3.0+):继承`Aggregator[IN, BUF, OUT]`,更安全且支持Catalyst优化:
核心方法:`zero`(初始化)、`reduce`(分区内聚合)、`merge`(跨分区合并)、`finish`(最终计算)。
编码器:通过`bufferEncoder`和`outputEncoder`指定序列化方式。
3. 代码示例
UDF:字符串处理(如`addName`)。
强类型UDAF:计算平均工资,使用`Buff`类存储中间状态(`sum`和`cnt`)。
注册与调用:`spark.udf.register("avgSalary", functions.udaf(myAverage))`。