目录
在Hadoop HDFS中,NameNode(NN) 是核心元数据管理节点,其单点故障会导致整个集群不可用。为了解决这一问题,HDFS引入了 Failover Controller(故障转移控制器,简称FC),配合ZooKeeper实现NameNode的自动故障转移(High Availability, HA)。
1 Failover Controller的角色职责
Failover Controller是HDFS HA架构中的关键组件,主要负责:
- 监控NameNode健康状态:通过心跳检测判断Active NN是否存活
- 协调主备切换:在Active NN故障时,自动将Standby NN提升为Active
- 防止脑裂(Split-Brain):通过ZooKeeper的分布式锁机制确保同一时刻只有一个Active NN
- 状态同步管理:确保Standby NN的元数据与Active NN保持同步(基于QJM或NFS)
2 Failover Controller的运行原理
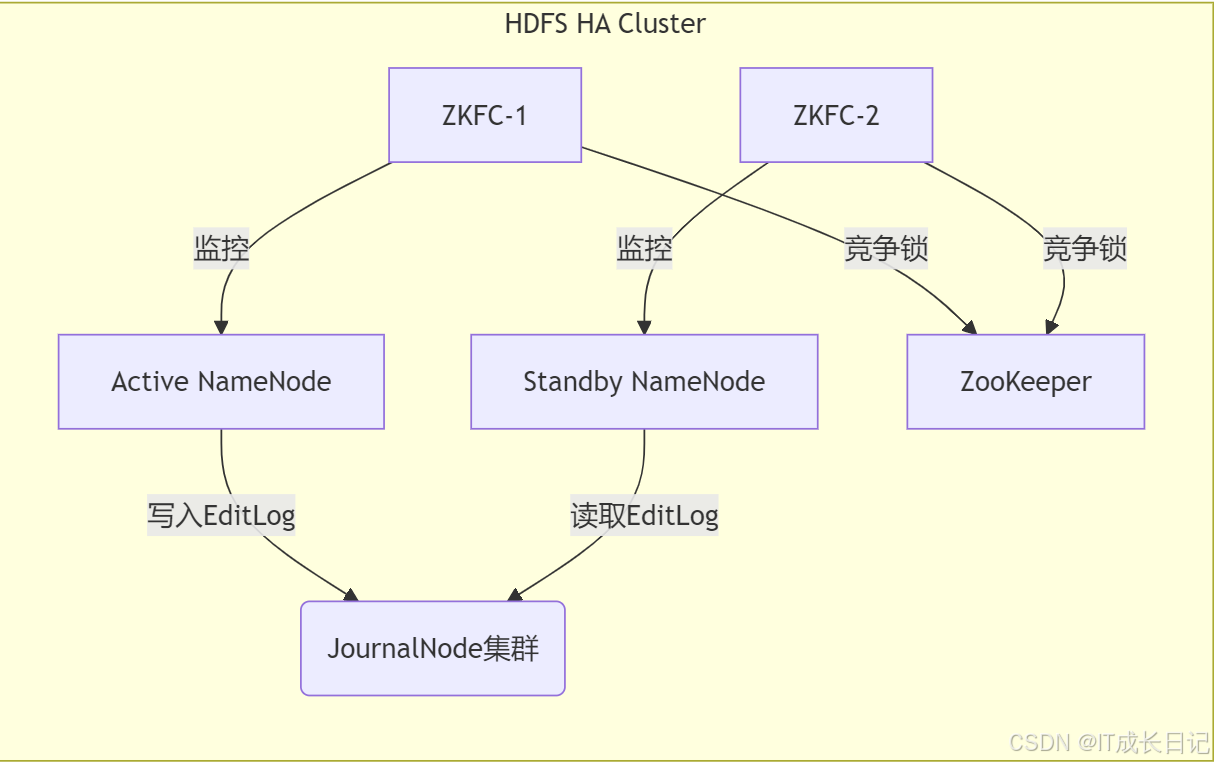
2.1 核心组件依赖
- ZooKeeper(ZK):提供分布式协调服务,用于选举和锁管理
- JournalNode(JN):存储EditLog,确保主备NN元数据一致性(基于QJM方案)
- ZKFC(ZK Failover Controller):独立进程,运行在每个NameNode节点上,负责具体故障转移逻辑
2.2 高可用架构图
3 故障转移机制详解
3.1 正常状态下的工作流程
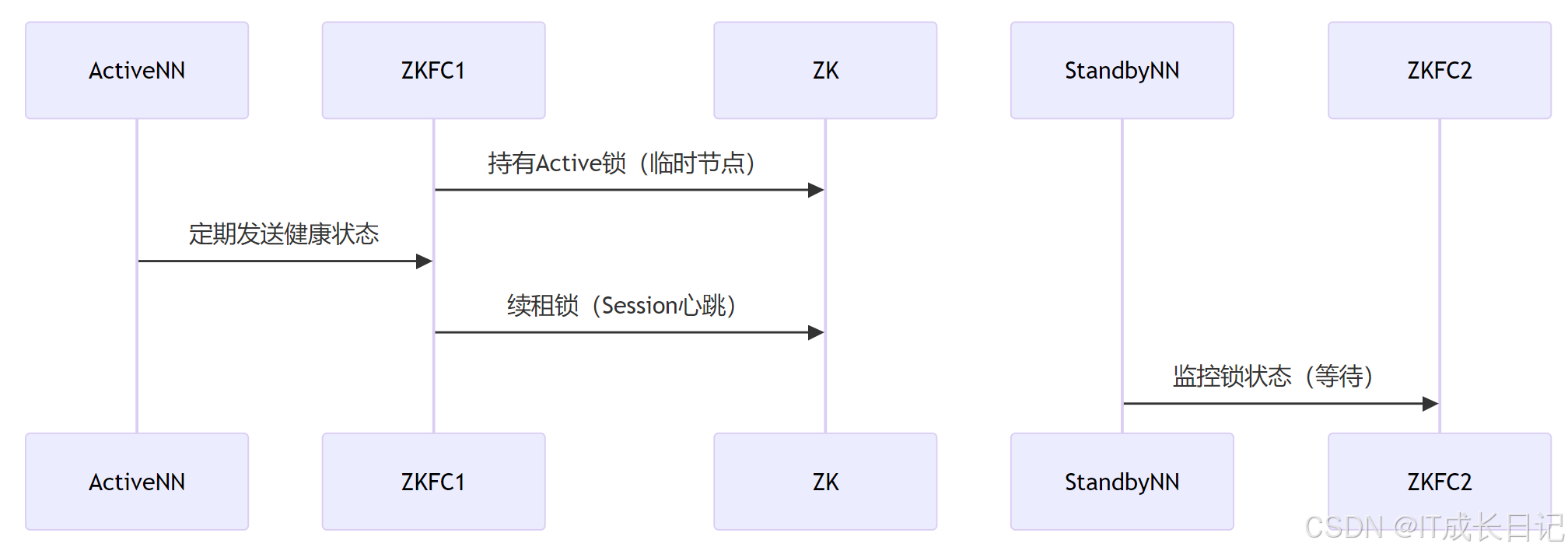
- Active NN的ZKFC通过ZooKeeper临时节点持有锁,表示其处于Active状态
- Standby NN的ZKFC持续监听该锁,准备接管
3.2 故障触发切换流程
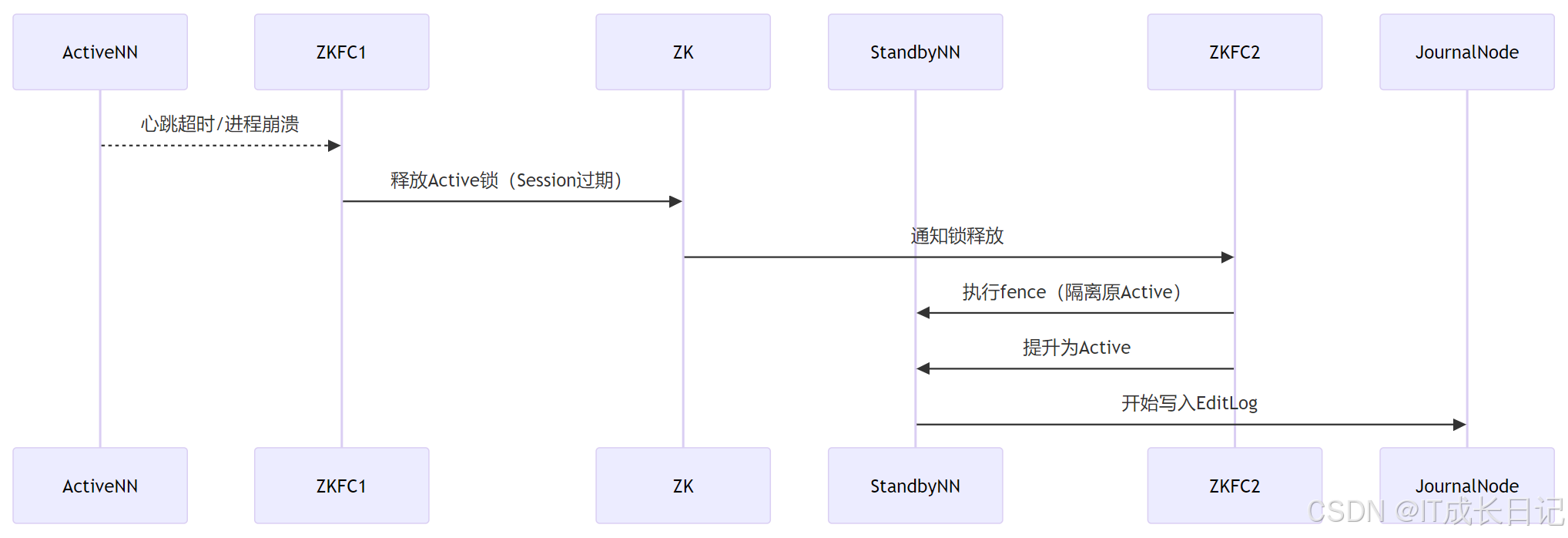
- 检测故障:ZKFC发现Active NN无响应(心跳超时或进程退出)
- 释放锁:ZooKeeper因Session过期自动删除临时节点
- 隔离原Active:通过SSH或Shell命令强制终止旧Active NN(防止脑裂)
- 提升新Active:Standby NN接管锁并开始服务
4 关键机制与技术挑战
4.1 防止脑裂(Fencing)
- SSH Fencing:通过SSH登录故障节点执行kill -9
- Shell Fencing:调用自定义脚本隔离故障节点(如断电)
- 存储级Fencing:确保旧Active NN无法写入共享存储(QJM/NFS)
4.2 元数据同步
方案 |
原理 |
优缺点 |
QJM |
基于Paxos协议,由JournalNode集群管理EditLog |
高可靠,但需要至少3个JN节点 |
NFS |
共享NAS存储EditLog |
简单,但存在单点故障风险 |
4.3 ZKFC的选举逻辑
- 依赖ZooKeeper的临时节点(Ephemeral Node)和Watcher机制
- 切换时需满足:
- 原Active NN确认不可用(心跳超时+手动隔离)
- 新Active NN的元数据完全同步
5 最佳实践
- 部署建议
- 至少部署3个JournalNode(QJM方案)
- ZooKeeper集群建议5节点(容忍2节点故障)
- 监控指标
- NameNode进程状态(jps)
- ZooKeeper锁状态
- EditLog同步延迟(HDFS Metrics)
- 调优参数
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>ha.zookeeper.session-timeout.ms</name>
<value>5000</value>
</property>6 总结
Failover Controller是HDFS高可用的核心组件,通过ZooKeeper选主+QJM元数据同步+隔离机制实现了NameNode的自动故障转移。理解其原理有助于:
- 快速定位HA集群故障
- 优化切换速度和可靠性
- 避免脑裂导致的数据不一致