生活打不败一个大口吃饭的人!
—— 25.4.13
一、模型幻觉问题
模型幻觉(AI Hallucination)是指人工智能模型(尤其是大语言模型)生成看似合理但实际不准确、虚构或与事实不符内容的现象。其本质是模型基于统计概率“编造”信息,而非通过逻辑推理或真实理解生成结果。
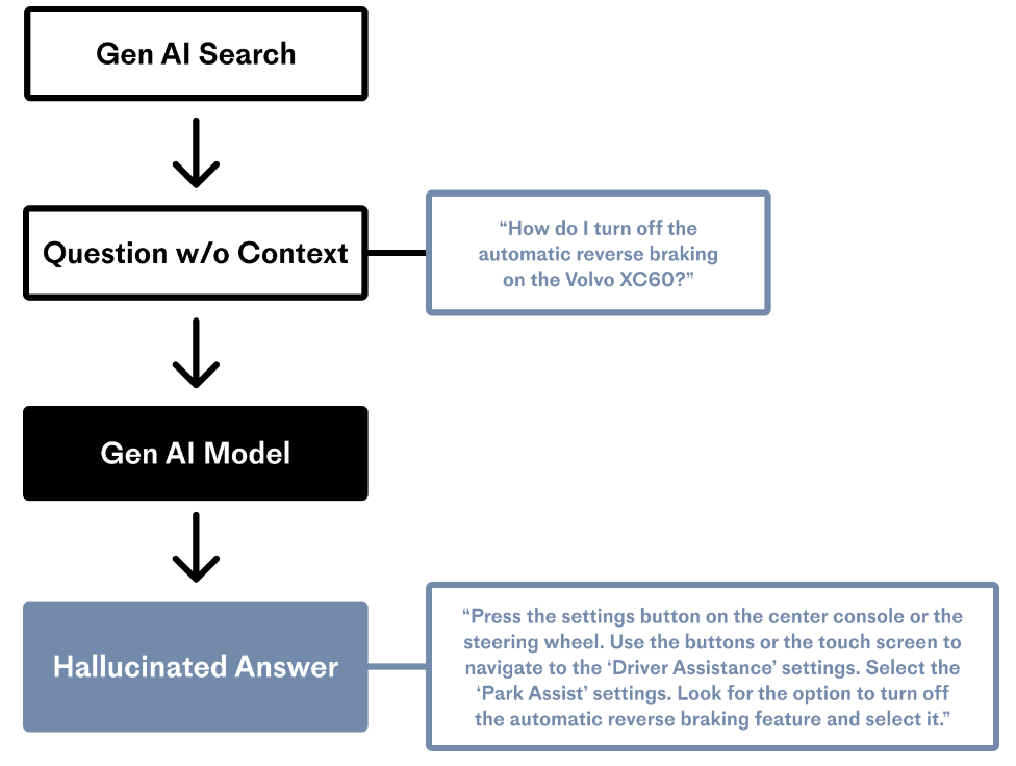
二、RAG(Retrieval Augmented Generation) 检索增强生成
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合检索和生成的混合方法,常用于问答、对话等任务。其核心思想是:在生成答案时,先从外部知识库检索与问题相关的文档,再基于检索结果生成更准确的答案。
1.步骤:
Ⅰ、从可信的来源准备多个文档
Ⅱ、将文档分为多个块或多个文件
Ⅲ、将每一块作为一个素材存在某一个库中
Ⅳ、当用户输入一个真实问题时,我们设计一种方法,从这个素材库中召回一个与这个问题相关的片段
Ⅴ、将这个片段和这个问题一起送入大语言模型进行推理
Ⅵ、大语言模型相当于同时拿到了问题和相关的片段,对二者进行整合
Ⅶ、将上一步二者整合出一个答案,进行生成最终的答案(其实是大语言模型从相关文档中进行转述出的结果),提高回答准确率
核心步骤
Ⅰ、文档检索:根据输入问题,从知识库中检索相关文档片段
Ⅱ、答案生成:将检索到的文档和问题一起输入生成模型,生成最终答案
RAG 关键组件详解
| 组件 | 作用 | 常用工具/模型 |
|---|---|---|
| 检索器 | 从知识库中查找相关文档 | BM25、DPR、FAISS |
| 生成器 | 基于检索结果生成自然语言答案 | BART、T5、GPT-2/3 |
| 知识库 | 存储结构化/非结构化数据 | Wikipedia、自定义数据库 |
2.流程图
流程图 Ⅰ
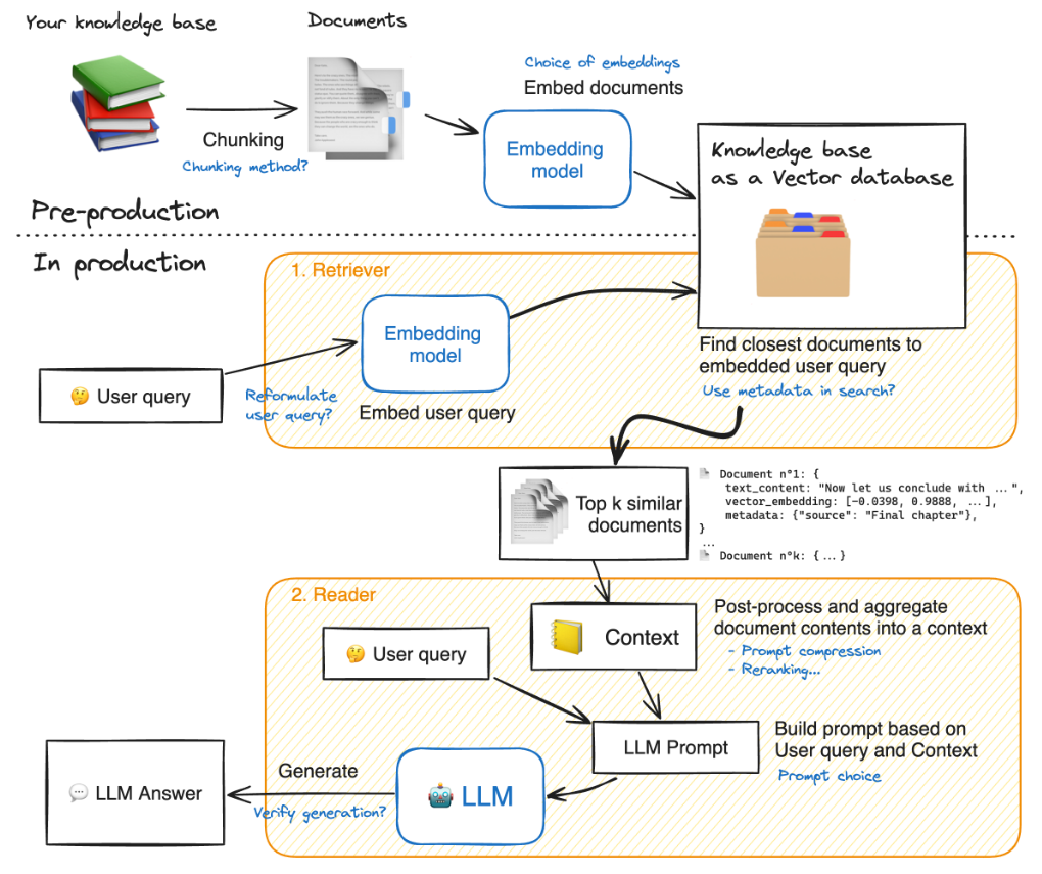
流程图 Ⅱ
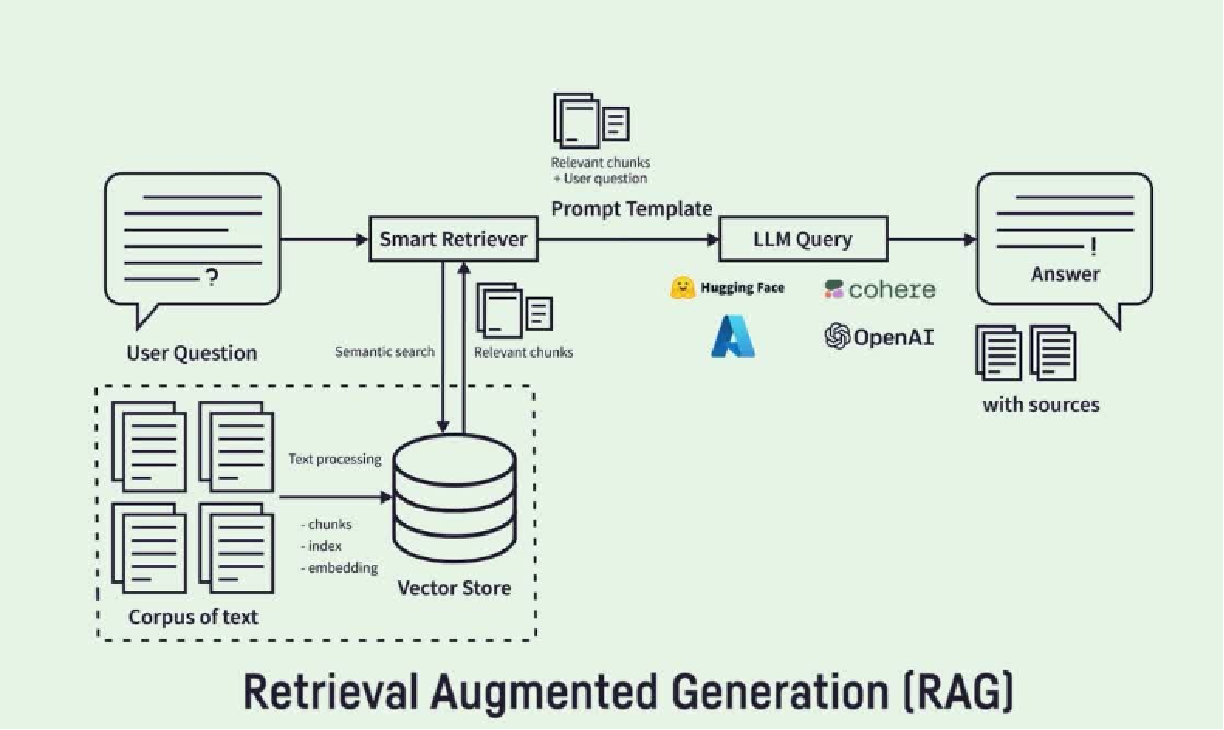
流程图 Ⅲ
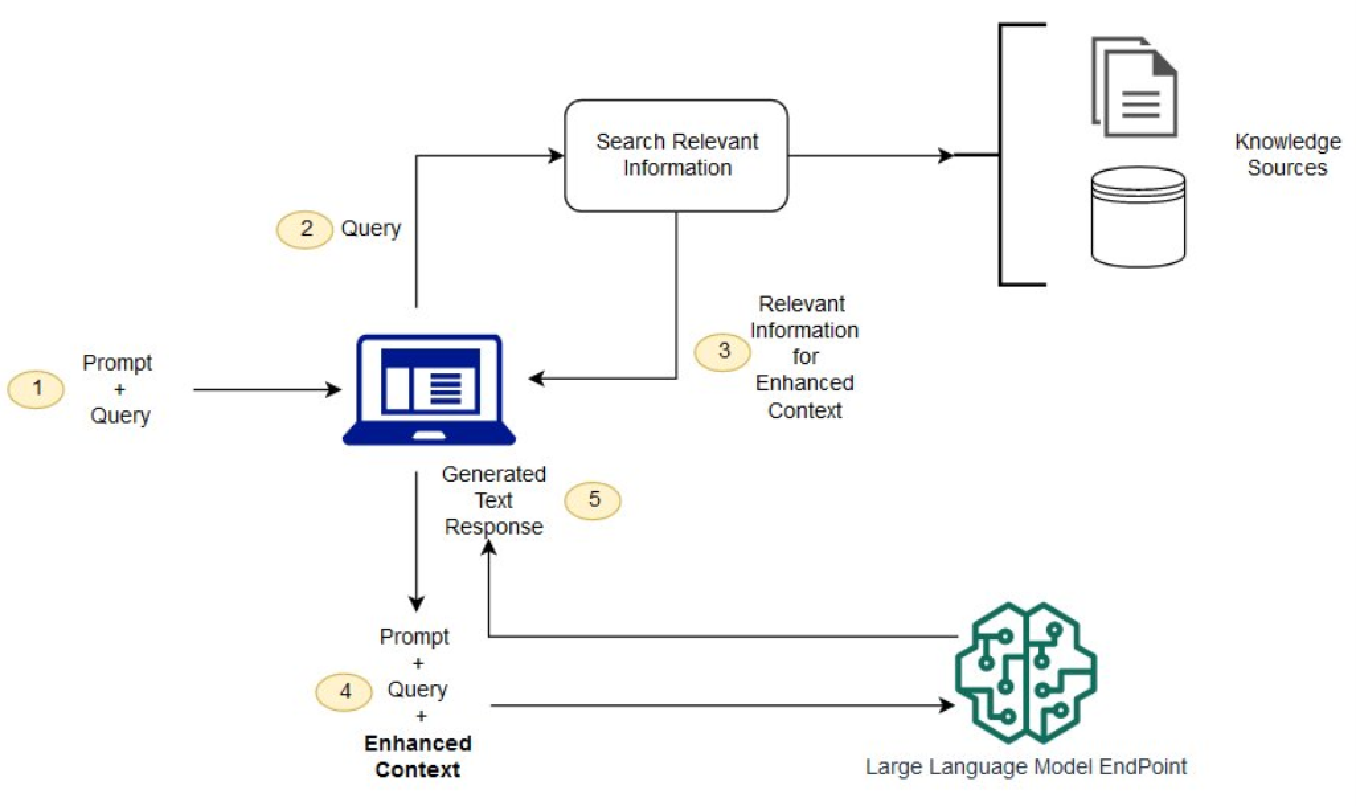
三、RAG优势
(1)可扩展性:减少模型大小和训练成本,并能够快速扩展知识。
(2)准确性:模型基于事实进行回答,减少幻觉的发生。
(3)可控性:允许更新和定制知识。
(4)可解释性:检索到的相关信息作为模型预测中来源的参考。
(5)多功能性:RAG能够针对多种任务进行微调(提示词)和定制(),如QA、Summary、Dialogue等。
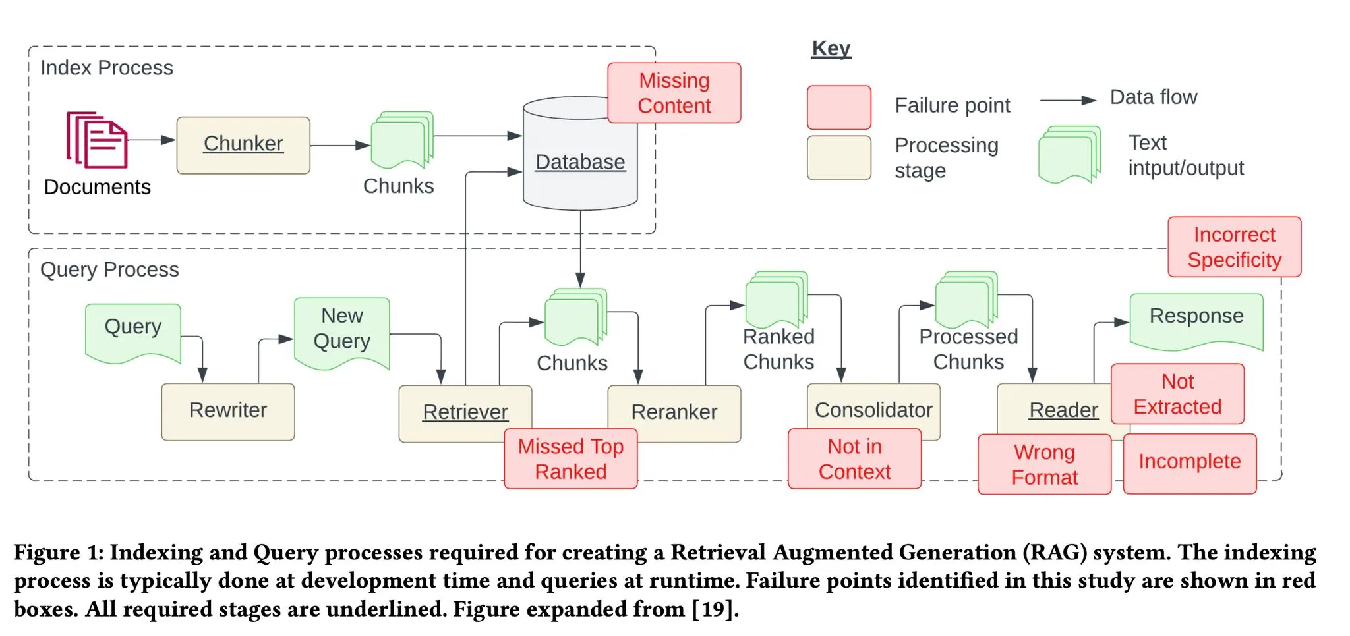
四、RAG难点
1.Missing Content:数据库中缺少相关的问题
2.Missed Top Ranked:没有取到正确的文章(检索系统的问题)
3.Not in Context:必要信息流失
4.Wrong Format:输出格式错误
5.Incomplete:输出内容不完整(检索系统的问题)
6.Not Extracted:模型没有回答出正确答案(大模型能力的要求)
7.incorrect specificity:模型在处理某些特定情况时不够精确,导致错误或异常。
五、RAG的延伸
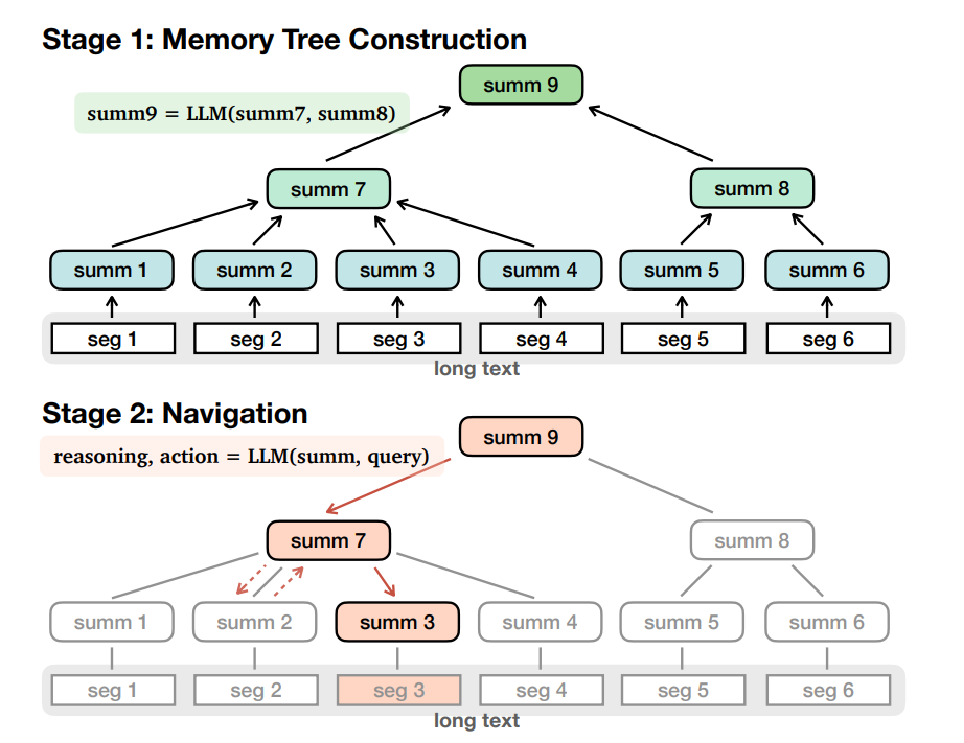
1.MemWalker
Ⅰ、先按照段落区分
Ⅱ、利用大模型的摘要能力,按照段落生成一个每一个段落对应的总结
Ⅲ、将每个段落的总结放在一起进行总结,生成总结的总结
Ⅳ、循环生成总结的总结,最终形成一个树形结构
Ⅴ、从根节点寻找,哪个子节点的总结与问题更加接近,就逐层寻找其子节点总结与问题的相似度
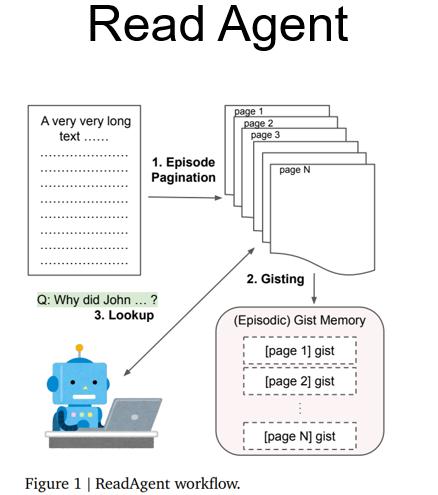
2.Read Agent
思路:把RAG中检索的任务也交给大模型去做
Ⅰ、输入一段文本输入到大模型中
Ⅱ、让模型决定这段文本在哪里可以断句
Ⅲ、经过第Ⅱ步,这篇文章被断成了几段,对于每段文本再送入大模型让模型对其进行一些摘要
Ⅳ、在查找时,传入每段文本的摘要,通过摘要的内容,让模型决定需不需要展开看到整段文本
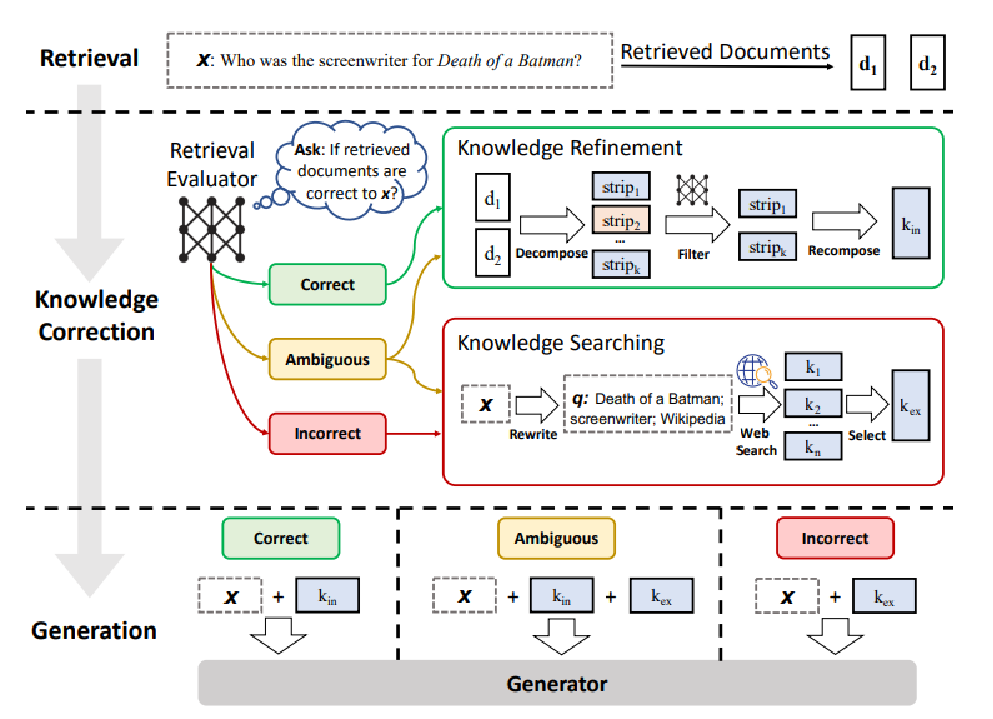
3.Corrective RAG
思路:输入一个问题先进行检索,检索出文章后让大模型回答是否输入的问题与检索的文章之间存在相关性。如果模型认为有相关性【Correct】:则直接使用本地知识库进行回答;如果模型认为没有相关性【Incorrect】:则模型会进行网络检索的过程,不依赖本地知识库;如果模型认为有一定相关性【Ambiguous】:则会同时在本地知识库和网络中同时查找;
4.self RAG
思路:输入一个问题,先判断一下是否需要做召回;如果需要做召回,就去本地知识库中做检索,再由大语言模型预测答案是否与问题相关;如果不需要做召回,就直接在网络查找输入答案,大模型最终再判断校验自己输入的答案是否有意义;
