0x00 线程
线程是一个执行单位,是在一个进程里面的,是共享进程里面的提供的内存等资源,使用多个线程时和使用多个进程相比,多个线程使用的内存等资源较少。进程像一座“房子”(独立资源),线程是房子里的“房间活动”(共享资源但独立执行)。
进程是一个资源单位,比如说各种运行的应用程序,每个应用程序就是一个进程。
多进程会占用较多的内存资源,一般适用cpu密集型操作,如图像处理,视频编码等,这里不做介绍了。
下面的代码是一个单线程运行的
import requests
url=''
requests.get(url)
多线程的使用
import threading
def task(a):
print(f"a子线程")
if __name__ == '__main__':
s=threading.Thread(target=task, kwargs={"a":"bbb"})#通过字典传递函数的参数
s.run()
print("aaa")
创建一个线程为50的线程池
from concurrent.futures import ThreadPoolExecutor
def task():
for i in range(1,1000):
print(i)
if __name__ == '__main__':
#创建一个50线程的
with ThreadPoolExecutor(50) as t:
t.submit(task)
实例爬取菜价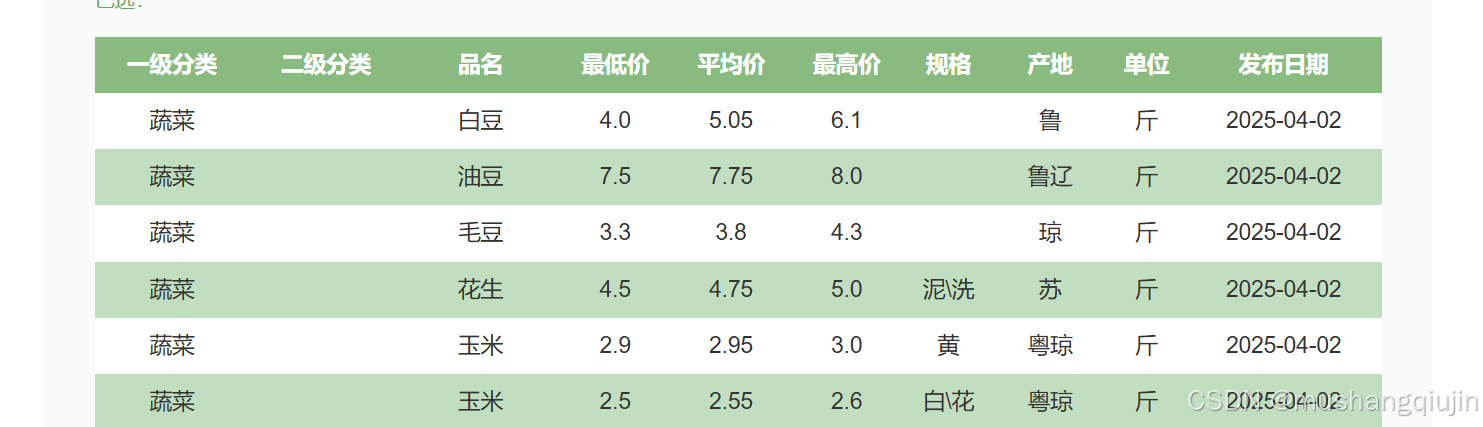
通过分析,发现源码里面并没有,network 格式选择xhr,找到了最终的数据,通过分析发现是post提交的数据,current等于几就是第几页
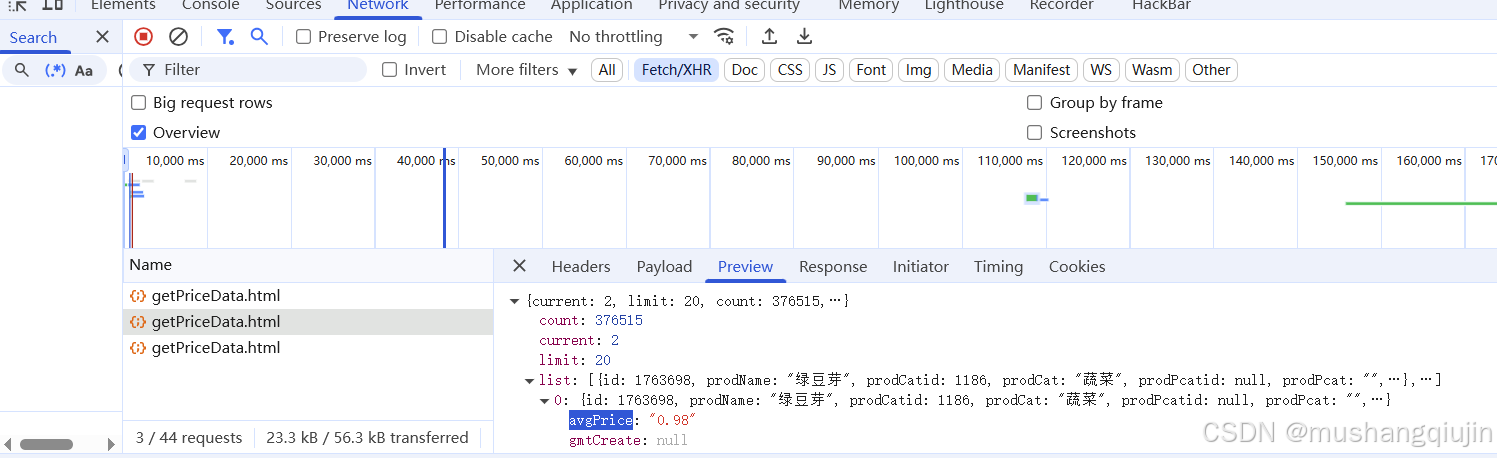
from concurrent.futures import ThreadPoolExecutor
import requests
url='http://www.xinfadi.com.cn/getPriceData.html'
def download(count):
data={"current":count,"limit":"20"}
rep=requests.post(url=url,data=data)
dic=rep.json()
for i in range(0,20):
#注意这里是字典夹杂着列表
name=dic['list'][i ]['prodName']
price=dic['list'][i]['avgPrice']
with open("4.csv","a+") as f:
f.write(f"菜名:{name}")
f.write(f"平均价:{price}")
f.write("\n")
if __name__ == '__main__':
with ThreadPoolExecutor(50) as t:
for i in range(1,50):
t.submit(download,count=i)
0x01协程
协程(Coroutine) 是一种用户态的轻量级线程,通过协作式多任务实现高效并发,一般多用于io密集型操作,网络请求、文件读写等。
多线程:通过操作系统调度多个线程并行执行,属于并发的一种形式。
异步:单线程内通过事件循环调度多个任务,属于并发模型,特点是单线程高并发。
#定义协程
import asyncio
async def fetch_data():
print("发起请求...")
await asyncio.sleep(1) # 模拟异步I/O
time.sleep(1)#同步错误用法
print("数据返回")
return {"data": 42}
案列爬取小说
分析网页,发现内容都在源代码中,这里选用xpath解析器,将小说内容保存到txt文件中去
import aiohttp
import asyncio
from lxml import etree
import os
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
}
async def fetch(url):
async with aiohttp.ClientSession() as session:
async with session.get(url, headers=headers) as response:
response.encoding = "utf-8"
return await response.text()
async def parse_down(url):
text = await fetch(url)
html=etree.HTML(text)
title=html.xpath("//h1/text()")
contents=html.xpath("//div[@id='chaptercontent']/text()")
os.makedirs("novels", exist_ok=True)
filename = f"{title[0]}.txt"
filepath = os.path.join("novels", filename)
with open(filepath,"w+",encoding='utf-8') as f:
f.write(title[0]+'\n\n')
for content in contents:
f.write(content.strip().replace("请收藏本站:https://www.bibie.cc。笔趣阁手机版:https://m.bibie.cc", "")+'\n')
async def main():
tasks = []
for i in range(1, 517):
url = f'https://www.bibie.cc/html/229506/{i}.html'
tasks.append(parse_down(url))
await asyncio.gather(*tasks)
print("爬取完成")
if __name__ == '__main__':
try:
asyncio.run(main())
except Exception as e:
print("")
