H.265/HEVC系列文章:
3、音视频之H.265/HEVC预测编码
预测编码是视频编码中的核心技术之一。对于视频信号来说,一幅图像内邻近像素之间有着较强的空间相关性,相邻图像之间也有很强的时间相关性。因此,先进的视频编码往往采用帧内预测和帧间预测的方式,使用图像内已编码像素预测邻近像素,或利用己编码图像预测待编码图像,从而有效去除视频空域和时域的相关性。视频编码器对预测后的残差而不是原始像素值进行变换、量化、熵编码,由此大幅提高编码效率。
自差分编码被应用于视频压缩以来,预测编码一直是视频编码标准的重要内容。新一代的H.265/HEVC标准采用了大量编码新方法,其中有很多属于预测编码范畴。
一、视频预测编码技术:
1、预测编码的原理:
预测编码(Prediction Coding)是指利用己编码的一个或几个样本值,根据某种模型或方法,对当前的样本值进行预测,并对样本真实值和预测值之间的差值进行编码。例如图像中相邻像素之间有较强的相关性,当前像素的灰度值与其相邻像素在很大概率上是接近的。因此,可以利用已编码的邻近像素预测当前像素值,并将真实值与预测值的差值进行编码,这样可以大大提高视频信号的压缩效率。
有记忆信源:
视频信号是一个在空间及时间上排列的三维信号,同一时刻采集的在空域分布的像素样本构成了一幅图像,不同时刻采集的图像按照时间顺序排列构成了视频序列。如果将视频中的每一个像素看成一个信源符号,它通常与空域上或时域上邻近的像素均具有较强的相关性,因此视频是一种有记忆信源。
联合编码和条件编码是两种有记忆信源的有效编码方式。
联合编码:
联合编码通常将图像分割成固定大小的块,将一个块作为一个信源符号来考察,对每一个块内的像素进行联合编码。
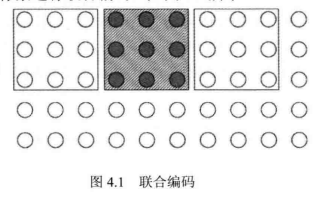
联合编码充分利用一个块内像素间的相关性,但未能利用相邻块之间的相关性。
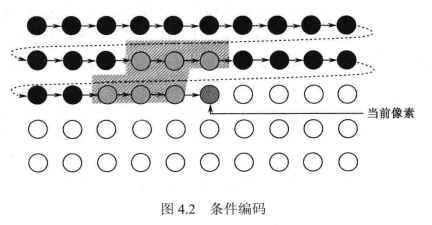
条件编码:
条件编码如图4.2,当前像素的编码依赖于邻近已编码像素(图中灰色区域),各像素将以滑动窗口的形式进行条件编码,这种方式改善了联合编码的缺陷,图像内邻近像素之间的相关性得到了充分利用。
预测编码技术大体实现:
预测编码技术通过预测模型消除像素间的相关性,得到的差值信号可以认为没有相关性,或相关性很小,因此可以作为无记忆信源进行编码。预测编码技术可以理解为一种特定的条件编码,其利用特定的预测模型反映像素间的依赖关系。如在图4.2中,当前像素依赖于其左方及上方的已编码像素,可以利用这一简单的依赖关系直接根据参考像素得到预测值,然后将当前像素真实值与预测值相减,再对差值进行编码。
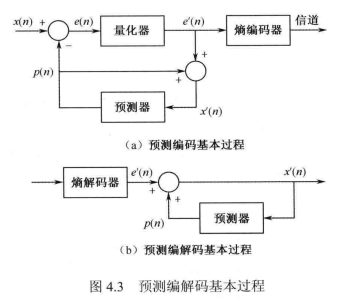
预测编码基本过程:
预测编码的基本过程如图4.3(a)所示,对于当前输入像素值x(m)首先利用己编码像素的重建值得到当前像素的预测值P(m),然后对二者的差值e(n)进行量化、编码,同时利用量化后的残差e(n)与预测值P(n)得到当前像素的重建值x(n),用于预测之后待编码的像素。对应的解码基本过程如图4.3(b)所示,经过解码可得到当前像素预测误差的重建值e'(n),将其与预测值P(n)相加即可得到当前像素的重建值x'(n) 。
视频预测编码的主要思想:
主要思想是通过预测来消除像素间的相关性。根据参考像素位置的不同,视频预测编码技术主要分为两大类:
- 帧内预测,即利用当前图像内已编码像素生成预测值:
- 帧间预测,即利用当前图像之前已编码图像的重建像素生成预测值。
2、帧内预测编码:
帧内预测编码是指利用视频空间域的相关性,使用当前图像已编码的像素预测当前像素,以达到去除视频空域冗余的目的,然后将预测残差作为后续编码模块的输入,进行下一步编码处理。
假设当前像素值为f(x,y),(x,y)为其水平和垂直位置的坐标,其由已编码的重建值f(k,I)进行预测:
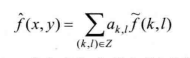
其中a.为二维预测系数,Z为参考像素所在的区域,k,l为参考像素的坐标。当前像素真实值与预测值的差值称为预测误差e(x,y):
![]()
帧内预测技术是消除视频空间冗余的主要技术之一,尤其是当间预测被限制使用时,帧内预测是保证视频压缩效率的主要手段。
像素进行加权平均
Harrison首先在图像编码中研究了帧内预测方法,其方法是用先前已编码的像素进行加权平均作为当前像素的预测值。该方法简单易行,但缺点是难以获得较高的压缩率。
离散余弦变换(DCT)
随着离散余弦变换(DCT)在图像、视频编码中的广泛应用,帧内预测转为在频域进行,如相邻块 DC系数的差分编码等,许多早期的图像、视频编码标准都使用了这种方法,如JPEG、H.261、MPEG-1、MPEG-2和 H.263等。
由 DCT的性质可知,DC系数仅能反映当前块像素值的平均大小,因此上述频域中基于 DC 系数的帧内预测无法反映出视频的纹理信息,这在很大程度上限制了频域帧内预测的发展。
空域帧内预测方法
H.264/AVC标准规定了若干种预测模式,每种模式都对应一种纹理方向(DC模式除外),当前块预测像素由其预测方向上相邻块的边界重建像素生成。该方法使得编码器能够根据视频内容特征自适应地选择预测模式。
拉格朗日率失真优化(RDO)
为了选择出最适合的帧内预测模式,H.264/AVC使用拉格朗日率失真优化(RDO)进行模式选择。它为每一种模式计算其拉格朗日代价:
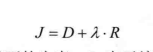
其中,D表示当前预测模式下的失真,R表示编码当前预测模式下所有信息(如变换系数、模式信息、宏块划分方式等)所需的比特数。需要说明的是,最优的预测模式不一定满足残差最小,而应指残差信号经过其他编码模块(如变换、量化、熵编码等)后最终的编码性能最优。
H.264中的预测模式:
H.264/AVC标准及后来的FRExt扩展层一共规定了3种大小的亮度帧内预测块:4x4、8x8及16x16。其中4x4和8x8块包含9种预测模式,16x16块包含4种预测模式。色度分量的帧内预测都是基于8x8大小的块进行的,也有4种预测模式。
a、亮度分量帧内 16x16 模式:
帧内16x16模式包含4种预测模式:垂直式、水平模式、DC模式和 Plane 模式,如图 4.5 所示。
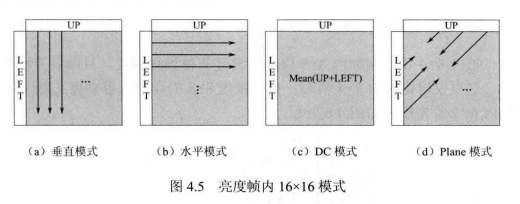
- 垂直模式(VerticalMode0),当前块预测像素由上方相邻块重建像素产生,计算如下:
![]()
其中![]() 表示当前块预测值,
表示当前块预测值,![]() 表示参考像素重建值,下同。
表示参考像素重建值,下同。
- 水平模式(HorizontalMode1),当前块预测像素由左侧相邻块重建像素产生,计算如下:
![]()
- DC模式(DC Mode2),当前块预测像素都为其所有参考像素的平均值,计算如下:
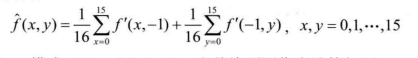
- Plane 模式(Plane Mode3),当前块预测像素计算如下:
![]()
其中:
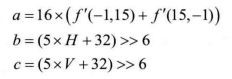
b,c中的H和V分别计算如下:
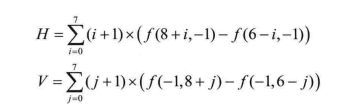
b、亮度分量帧内 4x4 模式:
帧内4x4模式和帧内8x8模式都含有9种预测模式,且两者方法类似。这里仅讨论帧内4x4情形。
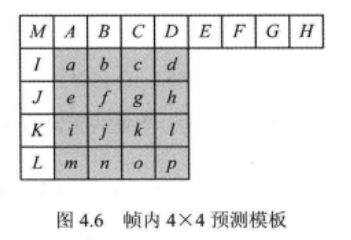
帧内4x4的9种预测模式包含了8种不同的预测方向以及DC模式为了方便介绍,下面以像素f为例给出其在9种预测模式下预测值的计算方法。
- 垂直模式(Vertical Mode 0):
![]()
- 水平模式(Horizontal Mode1):
![]()
- DC模式(DC Mode 2):
![]()
- 左下对角线模式(Diagonal-Down-Left Mode 3):
![]()
- 右下对角线模式(Diagonal-Down-Right Mode 4):
![]()
- 垂直向右模式(Vertical-Right Mode 5):
![]()
- 水平向下模式(Horizontal-Down Mode 6):
![]()
- 垂直向左模式(Vertical-Left Mode 7):
![]()
- 水平向上模式(Horizontal-Up Mode 8):
![]()
c、8x8 色度帧内预测模式
色度帧内预测包含4种模式:DC模式(模式0)、水平模式(模式1)、垂直模式(模式2)和Plane模式(模式3)。其预测方法与亮度16x16情形类似(需要注意二者模式编号顺序不同)。
最新的H265/HEVC 标准对其进行了进一步发展。一方面,H.265/HEVC 使用了更多大小的预测块,以适应高清视频的内容特征;另一方面,H.265/HEVC规定了更多种预测模式,对应于更多种不同的预测方向,以适应更加丰富的纹理。
3、H.264/AVC帧间预测编码:
帧间预测是指利用视频时间域的相关性,使用邻近已编码图像像素预测当前图像的像素,以达到有效去除视频时域几余的目的。由于视频序列通常包括较强的时域相关性,因此预测残差通常是“平坦的”,即很多残差值接近于“0”。将残差信号作为后续模块的输入进行变换、量化、扫描及熵编码,可实现对视频信号的高效压缩。
帧间预测编码原理:
目前主要的视频编码标准帧间预测部分都采用了基于块的运动补偿技术,如下图4.7所示。其主要原理是为当前图像的每个像素块在之前已编码图像中寻找一个最佳匹配块,该过程称为运动估计(Motion Estimation,ME)。其中用于预测的图像称为参考图像(Reference Frame),参考块到当前像素块的位移称为运动向量(Motion Vector,MV),当前像素块与参考块的差值称为预测残差(Prediction Residual)。
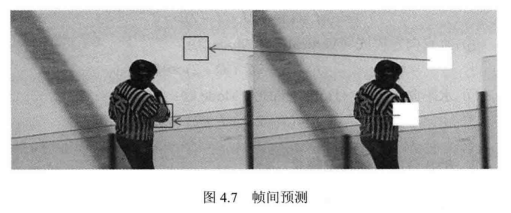
I图像帧内预测编码及P图像帧间预测编码:
早期的视频编码标准 H.261定义了两种类型的图像——I图像和P图像。其中I图像仅能使用帧内编码,而P图像可以利用帧间预测编码。H.261规定运动补偿块的大小为16x16(即一个宏块的大小)。此外,为去除相邻块运动向量之间的相关性,H.261对MV进行了差分编码。
![]()
式中 ![]() 和
和![]() ,分别表示当前块和前一个已编码块的 MV,MVD 为二者的差值(在大多数情况下MVD值接近于0)。
,分别表示当前块和前一个已编码块的 MV,MVD 为二者的差值(在大多数情况下MVD值接近于0)。
在H.261标准中,P图像的预测方式必须是由前一幅图像预测当前图像,这种方式称为“前向预测”(Forward Prediction)。但实际场景中往往会产生不可预测的运动和遮挡,因此当前图像的某些像素块可能无法从之前的图像中找到匹配块,而在其之后的图像中可以很容易地找到匹配块。
B图像的前向预测、后向预测及双向预测:
在MPEG-1标准定义了第三类图像--B图像,并规定B图像可以使用3种预测方式:前向预测、后向预测(Backward Prediction)以及双向预测。这样,B图像中的一个宏块可对应两个MV:一个由前向预测得来,另一个由后向预测得来。此外,由于实际场景中物体运动的距离不一定是像素尺寸的整数倍,因此为了提高运动估计精度,MPEG-1首次使用了半像素精度的运动估计。其半像素位置的参考像素值可由双线性差值(Bilinear Interpolation)方法产生,如图4.8所示,A,B,C,D为整像素位置,半像素位置a,b,c像素值可计算如下:
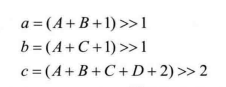
帧图像中的顶场(TopField)和底场(BottomField):
面向数字广播电视的标准 MPEG-2首次支持了隔行扫描视频。在隔行扫描视频中,一帧图像包含了两个“场”——顶场(Top Field)和底场(Bottom Field)。为了适应这种情况,每个帧图像的宏块需要被拆分成两个16x8的块分别进行预测。H.263标准沿用了MPEG-1的双向预测与半像素精度运动估计,并进一步发展了MPEG-2中将一个宏块分成更小的块进行预测的思想。标准规定将一个16x16的宏块分成4个8x8的小块分别进行运动补偿。这样做能够使运动估计和补偿更加精细,更好地适应了“一个宏块内包含了两种不同运动形式的物体”的情形。此外,H.263改进了MV的预测机制--用当前块左方、上方及右上方块的3个MV的中值来预测当前块的MV。如图4.9所示,当前块MV预测值为

H.264/AVC标准中帧间预测:
H.264/AVC标准在继承以往标准帧间预测成熟技术和框架的同时,对其进行了进一步细化和改善,并增加了一些新的技术和方法。为了尽量提高运动补偿的精度,H.264/AVC规定了7种大小的运动补偿块,分别为16x16、16x8、8x16、8x8、8x4、4x8、4x4,并且一个宏块内部允许存在不同大小块的组合。编码器可以根据视频内容自适应地选择块大小,例如对于多细节运动区域以及两个具有不同运动形式的不规则物体的边界处可以使用小块,而静止区域或大面积共同运动区域可以使用较大的块。图4.10给出了H.264/AVC间预测块划分方式。此外H.264/AVC还使用了1/4像素精度运动估计(色度为1/8像素精度)、多参考图像预测、加权预测以及空域/时域MV预测等。
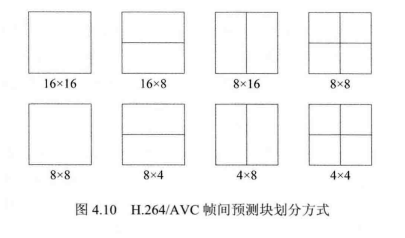
4、H.264/AVC帧间预测编码的关键技术:
运动估计:
在大多数视频序列中,相邻图像内容非常相似,其背景画面变化极小,因此不需要对每幅图像的全部信息都进行编码,而只需要将当前图像中运动物体的运动信息传给解码器。此时,解码器利用前一图像的内容以及当前图像的运动信息即可恢复当前图像。通过这种方式能有效地减少视频传输所需的带宽。所谓运动估计(ME)就是指提取当前图像运动信息的过程。
由于在图像中准确分割出运动物体和背景是很困难的,目前大多数运动估计算法都是基于像素值进行的。这一类方法中,最直接的方式是为每个像素指定一个运动向量,称为基于像素的运动表示法。该方法普遍适用,但是它需要估计出大量的未知量,而且其解通常并不能反映场景中物体真实的运动情况。此外,该方法需要为每一个像素附加传送一个 MV,数据量很高。
对于包含多个运动物体的场景,更适用的方法是把一幅图像分为多个区域,使得每个区域恰好表征了一个完整的运动物体,这称为基于区域的运动表示法,每个区域中的像素具有相同的运动形式。然而,由于运动物体的形状往往是不规则的,因此区域划分需要大量的信息来表征,而且准确的划分方式需要大量的计算才能确定,因而基于区域的表示法在实际中较少使用。
为了降低基于区域的运动表示法的复杂度,可以将图像分为不同大小的像素块,只要块大小选择合适,则各个块的运动形式可以看成是统一的,同时每个块的运动参数可以独立地进行估计,这就是常用的基于块的运动表示法。这种方法兼顾了运动估计精度和复杂度,在二者之间进行了一个较好的折中,因此该方法是视频编码国际标准的核心技术基于块的运动估计方法,有下面几个核心问题。
运动估计准则:
运动估计的目的是为当前块在参考图像中寻找一个最佳匹配块,因此需要一个准则来判定两个块的匹配程度。常用的匹配准则主要有最小均方误差(Mean Square Error,MSE)、最小平均绝对误差(Mean Absolute Difference,MAD)和最大匹配像素数(Matching-PixelCount,MPC)等为了简化计算,一般用绝对误差和(SumofAbsolute Diference,SAD)来代替 MAD。此外,最小变换域绝对误差和(Sum of Absolute Transformed Diference,SATD)也是一种性能优异的匹配准则。
假设块大小为MxN,![]() 和
和![]() 分别表示当前图像和参考图像的像素值,x,y表示MV的水平分量和垂直分量。
分别表示当前图像和参考图像的像素值,x,y表示MV的水平分量和垂直分量。
- MSE 准则:
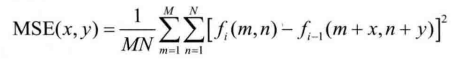
- SAD准则:
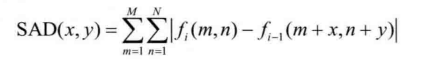
- MPC准则:
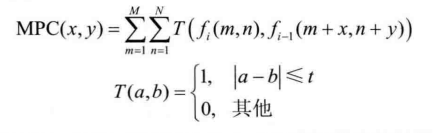
其中,t为一定阀值。MPC 表示两个块中对应位置像素值差异小于一定阈值的个数。
搜索算法:
在某些应用环境下,视频编码传输对实时性要求较高,而运动估计的运算复杂度通常较高,因此寻找高性能、低复杂度的运动搜索算法显得尤为重要。
常用的搜索算法有:全搜索算法、二维对数搜索算法、三步搜索算法等。全搜索算法是指对搜索窗内所有可能的位置计算两个块的配误差,所得的最小匹配误差对应的 MV 一定为全局最优 MV。然而,全搜索算法复杂度极高,无法满足实时编码。除全搜索算法外,其余算法统称为快速搜索算法,快速搜索算法具有搜索速度快的优点,但其搜索过程中容易落入局部最优点,从而无法找到全局最优点。为了尽量避免这一现象发生,需要在搜索算法的每一个步骤尽量搜索更多的点,相关搜索算法有H.264/AVC官方测试编码器JM20所使用的UMHexagonS算法以及H.265/HEVC官方测试编码器HM所使用的TZSearch 算法等。
亚像素精度运动估计:
由于自然界物体运动具有连续性,因此相邻两图像之间物体的运动不一定是以整像素为基本单位的,而有可能以半像素、1/4像素甚至1/8像素为单位。此时若仅使用整像素精度运动估计会出现匹配不准确的问题,导致运动补偿残差幅度较大,影响编码效率。而应将运动估计的精度提升到亚像素级别,这可以通过对参考图像像素点进行插值来实现。 1/4像素精度相比于1/2像素精度时的编码效率有明显的提高,但是1/8像素精度相比于1/4像素精度时的编码效率除了高码率情况以外并没有明显的提升,而且1/8像素精度运动估计更为复杂。因此现有标准H.264/AVC 以及 H.265/HEVC 都使用 1/4像素精度运动估计。
亚像素精度运动估计意味着需要对参考图像进行插值,好的插值方法能够大幅改善运动补偿的性能。应用更多的邻近像素点进行插值能够明显提高运动补偿精度。因此H.264/AVC 标准在半像素内插时未使用以往标准(MPEG-1等)规定的双线性内插法,而是使用了一种6抽头滤波器;为了控制复杂度,对于14像素精度,H.264/AVC使用了两点邻近像素内插方法。
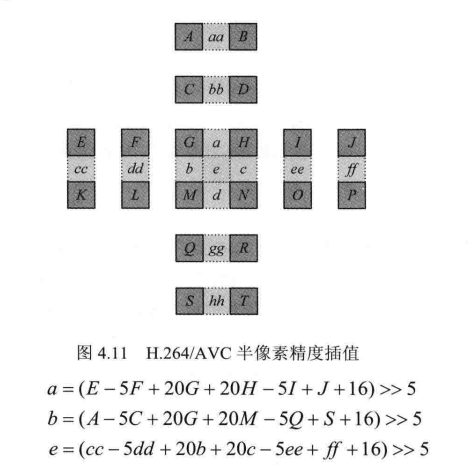
- 半像素精度插值。
H.264/AVC中半像素精度插值使用了一种6抽头滤波器,抽头系数为(1/32,-5/32,20/32,20/32,-5/32,1/32)。如图 4.11所示,A-T表示整像素位置,a-e、aa-hh表示半像素位置,则a,b,e的值分别计算如下:
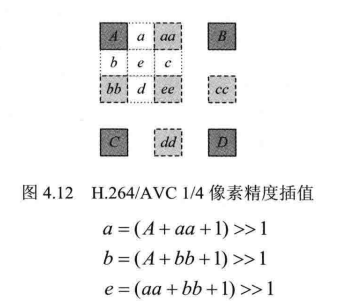
- 1/4 像素精度插值。
H.264/AVC中,当所有的半像素都插值完成后,1/4像素可由邻近的两个像素平均得到。如图4.12所示,4.B.C,D为整像素位置,aa-ee为半像素位置,a-e为1/4像素位置,则a,b,e的值分别计算如下:
MV预测:
在大多数图像和视频中,一个运动物体可能会覆盖多个运动补偿块,因此空间域相邻块的运动向量具有较强的相关性。若使用相邻已编码块对当前块 MV进行预测,将二者差值进行编码,则会大幅节省编码MV所需的比特数。同时,由于物体运动具有连续性,因此相邻图像同一位置像素块的MV也具有一定相关性。H.264/AVC使用了空域和时域两种MV的预测方式。
MV空域预测:
如图4.13所示,设为当前运动补偿块,A在E的左侧,B在E的上方,且A、B与E紧邻,C在E的右上方。在H.264/AVC中,若E的左侧对应多个块,则选择最上方的块作为A;又若E的上方对应多个块则选择最左边的块作为B。运动补偿块E的预测MV(用MVP表示)可分以下几种情况来确定。
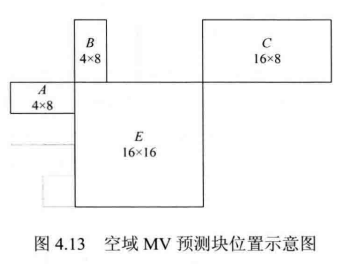
- 若E的大小不是16x8和8x16,则MVP为A、B和C三者MV的中值。
- 若E被划分为两个16x8的块,则上方16x8块MVP为B的MV,下方16x8块MVP为A的MV。
- 若E被划分为两个8x16的块,则左侧8x16块MVP为A的MV右侧8x16块的MVP为C的MV。
- 若E为Skip宏块,则其MVP与16x16情形一样,为4、B和C三者MV的中值。
MV时域预测:
在H.264/AVC中,MV时域预测主要是针对B片(Bslice)的。主要有以下两种形式。
- 当B图像的两个MV都来自同一个方向时(都来自当前图像之前的参考图像或之后的参考图像),其中的一个MV可用另一个MV来预测。预测方法如下。
设两参考图像ref0和ref1与当前图像的距离分别为l0和l1,二者MV分别为 MV0和MV1,则MV1可由下式来预测:
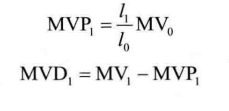
编码器只需要传输MVD1,解码器可以按照相同的规则产生MV1。
- 直接模式 MV 预测。
H.264/AVC为B片提供了一种直接模式(Direct Mode)。在该模式下,运动向量可直接预测得出,无须传送运动向量差值。预测的方式有时域和空域两种,空域预测与图4.13中的方法相同,时域预测介绍如下。
设当前图像的两个参考图像为ref0和ref1,分别位于当前图像的前方和后方,二者与当前图像的距离分别为l0和l1,且ref1中与当前块对应位置块有一个指向ref0的MV,则当前图像的两个MV可计算如下:
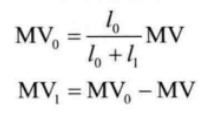
MV 时域预测主要运用了自然界物体匀速运动的思想,间隔数幅图像的两幅图像之间的运动向量一旦确定,则其间每一幅图像的运动向量预测值都能利用与当前图像与两端参考图像的距离计算得出。
多参考图像及加权预测
对于某些场景,如物体周期性变化等,多参考图像可以大幅提高预测精度。如图4.14所示,若使用第1幅图像预测第3幅图像,第2幅图像预测第4幅图像,则预测效果会比用相邻图像预测好得多。
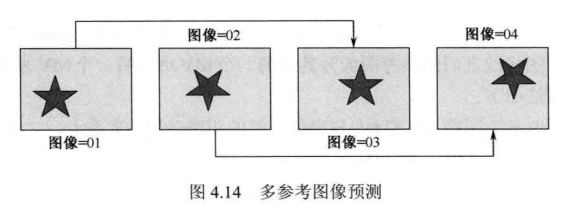
早期的视频编码标准只支持单个参考图像,H.263+开始支持多参考图像预测技术,而H.264/AVC标准最多支持15个参考图像。随着参考图像数目的增加,编码性能也随之提高,但提高的速度逐渐减慢。因此,为了权衡编码效率与编码时间,一般情况下都采用4~6个参考图像。
此外,H.264/AVC还使用了加权预测技术。加权预测表示预测像素可以用一个(适用于P Slice情形)或两个(适用于B Slice情形)参考图像中的像素通过与加权系数相乘得出,如下:
![]()
其中![]() 和
和![]() 分别表示参考图像1和参考图像2的重建值,
分别表示参考图像1和参考图像2的重建值,![]() 和
和![]() 分别表示二者的权值。加权预测适用于两图像之间像素值整体变化且有相同变化规律的情形,如淡入、淡出等效果。H.264/AVC规定了以下两种形式的加权方法。
分别表示二者的权值。加权预测适用于两图像之间像素值整体变化且有相同变化规律的情形,如淡入、淡出等效果。H.264/AVC规定了以下两种形式的加权方法。
- explicit 加权预测:加权系数ω由编码器确定并将写入码流传入解码端。该方法同时适用于P片及B片。
- implicit 加权预测:加权系数@可以由两个参考图像与当前图像的距离关系自行计算得出(距离越远加权系数越小)。该方法仅适用于B片。
二、H.265/HEVC帧内预测:
H.265/HEVC帧内预测模式:
1、亮度帧内预测模式:
H.265/HEVC 亮度分量帧内预测支持5种大小的PU:4x4、8x8、16x16、32x32和64x64,其中每一种大小的PU 都对应 35 种预测模式包括 Planar 模式、DC 模式以及 33 种角度模式。所有预测模式都使用相同的模板,如图4.15所示。其中R,表示相邻块的像素重建值,用做参考像素,Pxy,表示当前块像素的预测值。
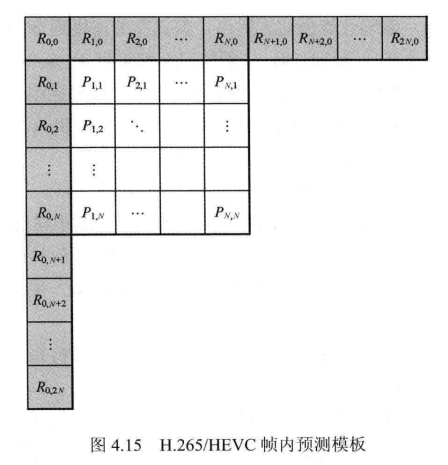
从图4.15中可以看出,与H.264/AVC相比,H.265/HEVC 增加使用了左下方块的边界像素作为当前块的参考。这是由于H.264/AVC以固定大小的宏块为单元进行编码,在对当前块进行帧内预测时,其左下方块很有可能尚未进行编码,无法用于参考;而H.265/HEVC四叉树形的编码结构使得这一区域成为可用像素。此外,这一区域像素的使用也提供了更多可能的预测方向,在某些情形下(如倾斜向上方向的纹理等)能够大幅提高预测精度。
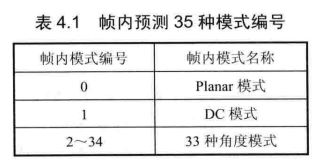
表4.1给出了35种预测模式的编号,模式0为Planar模式,模式1为DC模式,模式2~34为33种角度模式。图4.16给出了33种角度模式的预测方向,其中模式 2~17称为水平类模式,模式18~34称为垂直类模式。
- Planar 模式。
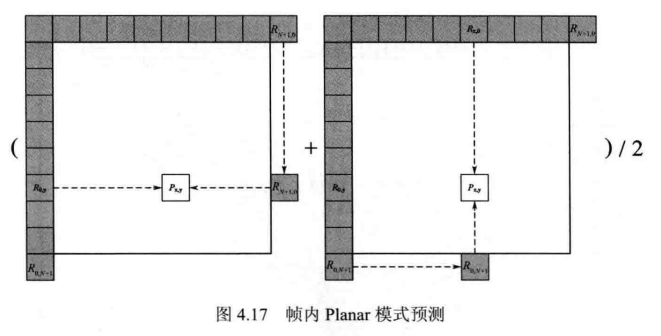
Planar 模式是由 H.264/AVC 中的Plane 模式发展而来的,它适用于像素值缓慢变化的区域。如图4.17所示,Planar模式使用水平和垂直方向的两个线性滤波器,并将二者的平均值作为当前块像素的预测值。这一做法能够使预测像素平缓变化,与其他模式相比能够提升视频的主观质量。
- DC 模式。
DC 模式适用于大面积平坦区域,其做法与H.264/AVC基本相同。当前块预测值可由其左侧和上方(注意不包含左上角、左下方和右上方)参考像素的平均值得到,即图4.15 中的R.,…,R,R.,…,Ro的平均值。
- 角度模式。
H.264/AVC 使用了8种不同的预测方向(4x4大小),H.265/HEVC则进一步细化了这些预测方向,规定了33种角度预测模式,以更好地适应视频内容中不同方向的纹理。

图4.16给出了这33 种角度模式的具体方向,其中V0(模式26)和H0(模式10)分别表示垂直和水平方向,其余模式的预测方向都可以看成在垂直或水平方向上做了一个偏移,该偏移角的大小可由模式下方的数字计算得出。设某垂直类模式偏移值为V+x,则当前模式偏移角度为:

![]() 为正表示预测方向向左偏移,
为正表示预测方向向左偏移,![]() 为负表示预测方向向右偏移;对于水平类模式,
为负表示预测方向向右偏移;对于水平类模式,![]() 为正表示预测方向向上偏移,
为正表示预测方向向上偏移,![]() 为负表示预测方向向下偏移。例如,对于模式23,其偏移值为V - 9,则其偏移角为:
为负表示预测方向向下偏移。例如,对于模式23,其偏移值为V - 9,则其偏移角为:

即垂直向右偏移15.7度。
对于模式 11~25,当前块的预测需要同时用到上方及左侧的参考像素。为了能够使用一种统一的形式来计算预测像素值,H.265/HEVC标准采用了一种“投影像素”的方法,对于模式18~25(垂直类模式),须将左侧参考像素按给定方向投影至上方参考像素的左侧(水平排列):而对于模式11~17(水平类模式),须将上方参考像素按给定方向投影至左侧参考像素的上方(垂直排列)。
2、亮度模式的编码:
在图像和视频中,相邻块之间往往具有较强的相关性,因此相邻块的帧内预测模式相同或相似的概率较大。此时若将每个PU的预测模式独立进行编码则会带来不必要的冗余。H.265/HEVC标准在对帧内预测模式进行编码时,充分利用了相邻块模式信息之间的相关性。
H.265/HEVC标准建立了一个帧内预测模式候选列表 candModeist,表中有3个候选预测模式,用于存储相邻PU的预测模式。相邻PU的位置如图4.18所示:
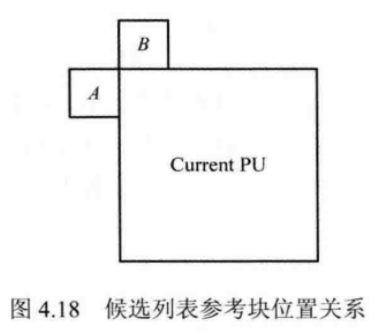
设A的预测模式为Mode4,B的预测模式为 ModeB.候选列表具体建立过程如下。
- 若Mode4与ModeB相同,则分以下两种情况进行。
若ModeA和ModeB 都为Planar或 DC 模式,则:
candModeList[0]为 Planar 模式;
candModeList[1]为 DC 模式。
candModeList[2]为模式 26(垂直模式)。
若Mode4和 ModeB 都为角度模式,则:
candModeList[0]为 Mode4;
candModeList[1]和 candModeList[2]为与 ModeA 相邻的两个模式。
需要注意的是模式2与模式3和模式33相邻,模式34与式33和模式3相邻。
- 若ModeA与ModeB不同,则:
candModeList[0]为 ModeA;
candModeList[1]为 ModeB;
candModeList[2]分以下几种情况决定。
①. 若 Mode 和 ModeB 都不是 Planar 模式,则 candModeList[2]为Planar 模式。
②. 当a不满足时,若Mode4和ModeB都不是DC模式,则candModeList[2]为 DC 模式。
③ . 当①、②都不满足时,candModeList[2]为模式 26(垂直模式)。
当candModeList建立完成后,可利用该列表对当前P模式信息进行编码,具体如下。
若当前PU最优模式(记为ModeC,下同)在candModeList中出现,则只需要编码ModeC在candModeList中的位置即可。
若ModeC未在 candModeList中出现,则按以下步骤编码 ModeC。
①将 candModeList 中的候选模式按从小到大的顺序重新排列。
②遍历重新排列后的3个候选模式,分别与ModeC进行比较,若
ModeC>candModeList[i]
则令 ModeC 自减1。遍历结束后对 ModeC最终的值进行编码。
3、色度模式的编码:
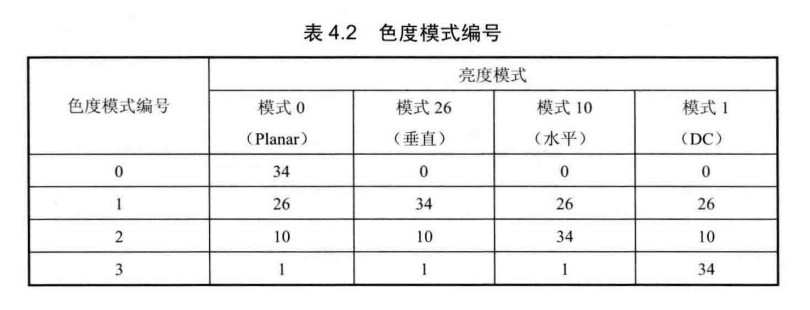
H.265/HEVC色度分量帧内预测一共有5种模式:Planar模式、垂直模式、水平模式、DC 模式以及对应亮度分量的预测模式。若对应亮度预测模式为前4种模式中的一种,则将其替换为角度预测中的模式34。
H.265/HEVC直接对色度模式编号进行编码,具体方法如下。
- 若对应亮度预测模式不是前4种模式中的一种,则直接对模式编号进行编码。模式编号如下。
模式 0:Planar 模式。
模式1:垂直模式(角度式26)。
模式2:水平模式(角度模式10)。
模式 3:DC 模式。
模式4:对应亮度分量模式。
- 若对应亮度预测模式是前4种模式中的一种,则分以下两种情况进行。
①若最优色度模式与亮度模式相同,则色度模式为模式4。
若①不满足,则按表 4.2中的不同的组合推断出色度模式编号,2)例如,当色度最优模式为垂直模式(角度模式26),而对应亮度分量为Planar模式(模式0)时,当前色度模式编号为1;当色度最优模式为角度模式34,而对应亮度分量为Planar模式(模式0)时,当前色度模式编号为0。
4、相关语法元素:
下面介绍与 H.265/HEVC帧内预测相关的语法元素。
SPS中strong_intra_smoothing_enabled_flag语法元素决定是否使用帧内预测参考像素强滤波技术,
CU层prev_intra_luma_pred_flag、mpm_idx 和rem_intra_luma_pred_mode3个语法元素共同决定亮度帧内预测模式,intra_chroma_pred_mode语法元素决定色度帧内预测模式。
H.265/HEVC帧内预测过程:
在H.265/HEVC中,35种预测模式是在PU的基础上定义的,而具体帧内预测过程的实现则是以TU为单位的。标准规定PU 可以以四叉树的形式划分TU,且一个PU内的所有TU 共享同一种预测模式。H.265/HEVC 帧内预测可分为以下3个步骤:
- 判断当前TU相邻参考像素是否可用并做相应的处理;
- 对参考像素进行滤波;
- 根据滤波后的参考像素计算当前TU的预测像素值。
1、相邻参考像素的获取
如图4.19所示,当前TU大小为NxN,其参考像素按区域可分为5部分:左下(A)、左侧(B)、左上(C)、上方(D)和右上(E),一共4N+1个点。若当前TU位于图像边界,或Slice、Tile的边界(H.265/HEVC规定在帧内编码中,相邻Slice或Tile不能相互参考),则相邻参考像素可能会不存在或不可用。另外,在某些情形下A或E所在的块可能尚未进行编码,此时这些参考像素也是不可用的。
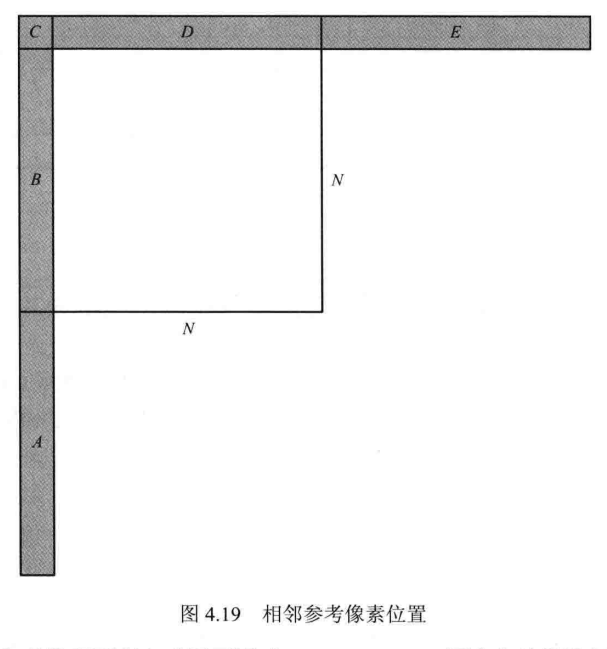
当参考像素不存在或不可用时,H.265/HEVC标准会使用最邻近的像素进行填充。例如,若区域A的参考像素不存在,则区域A所有参考像素都用区域B最下方的像素进行填充;若区域E的参考像素不存在,则区域E所有参考像素都用区域D最右侧的像素进行填充。需要说明的是,若所有区域参考像素都不可用,则参考像素都用固定值填充,该固定值大小为:
![]()
例如,对于8比特像素,该预测值为128:对于10比特像素,其值为 512。
2、参考像素的滤波:
H.264/AVC 在帧内预测时对某些模式下的参考像素进行了滤波,以更好地利用邻近像素之间的相关性,提高预测精度。H.265/HEVC 沿用了这一做法并对其进行了发展:一方面,H.265/HEVC针对不同大小的TU选择了不同数量的模式进行滤波;另一方面,在H.264/AVC 滤波方法的基础上,H.265/HEVC增加使用了一种强滤波方法。现分别介绍如下。
- 不同大小TU 需要进行参考像素滤波的模式。
DC 模式以及 4x4 大小的TU 都不需要进行参考像素滤波。其他情形介绍如下。
32x32TU:除模式10(水平)、模式26(垂直)之外的所有角度模式以及 Planar 模式。
16x16TU: 在 32x32 TU的基础上进一步除去最接近水平和垂直方向的4个模式--模式9、11、25 和 27。
8x8TU:仅对3个45°倾斜方向的模式(模式2、18、34)以及 Planar模式进行参考像素滤波。
- 常规滤波与强滤波方法。
常规滤波方法与 H.264/AVC中的方法相同,滤波器抽头系数为[0.250.5,0.25]。参照图4.15中的模板,![]() 为滤波前的像素,则滤波后的值为
为滤波前的像素,则滤波后的值为
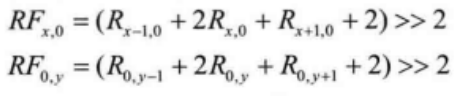
其中x,y=1,2,…,2N-1。对于![]() ,滤波后的值为
,滤波后的值为
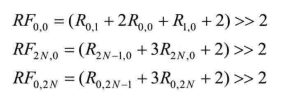
强滤波对应于 SPS 中的语法元素strong_intra_smoothing_enabled_flag该方法只针对 32x32 TU 进行,且需要满足两个条件。如图 4.20所示,
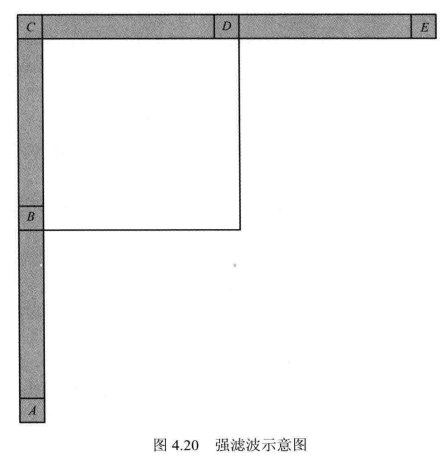
A,B,C,D,E分别为相应位置的参考像素,若满足
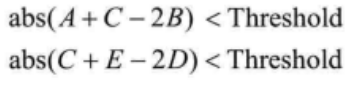
则需要对当前TU的参考像素进行强滤波。其中
![]()
例如,对于8比特像素,其值为8;对于10比特像素,其值为32。
强滤波分两个方向进行,分别为C-E方向和C-A方向。具体做法可以描述为:C-E(或C-A)方向的每个像素滤波后的值都由C和E(或A)加权平均得到,权值大小与当前像素与C和E(或)的距离有关,距离越大,权值越小。参照图4.15中的模板,滤波后的像素值为:
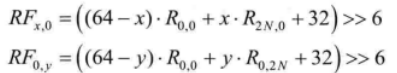
其中x,y=1,2,…,2N-1,![]() 不需要进行滤波。
不需要进行滤波。
3、预测像素的计算:
下面参照图4.15中的模板说明在不同模式下参考像素的计算方式。
- Planar 模式。
如图 4.15所示,在Planar 模式下,预测像素Px,y可以看成是水平、垂直两个方向预测值的平均值。具体计算方法如下:
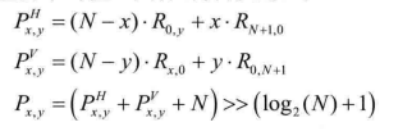
其中,x,y=1,2,…,N。需要说明的是,对于4x4TU,参考像素不需要进行滤波:而在其他情况下,参考像素都需要进行滤波。
- DC模式。
DC 模式需要首先计算出当前TU左侧及上方参考像素的平均值,记为dcValue,计算如下:
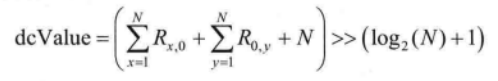
对于色度分量以及大于16x16的亮度分量,所有像素预测值都为dcValue;对于其他情形(TU尺寸小于或等于16x16的亮度分量),可分以下4种情况计算预测像素值。
左上角像素:
![]()
第一行像素(左上角像素除外):
![]()
第一列像素(左上角像素除外):
![]()
其他像素:
![]()
- 角度模式:
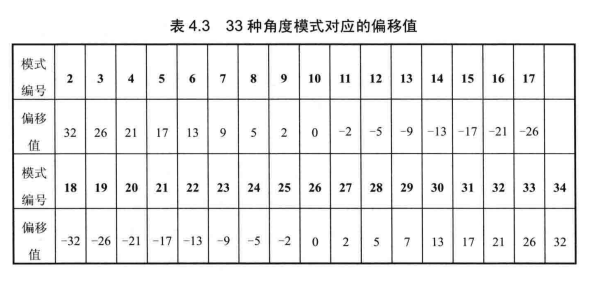
33种角度预测可分为水平类模式(2~17)和垂直类模式(18~34),每一种角度模式都相当于在水平或垂直方向上做了一个偏移,不同角度对应的偏移值(offset)见表4.3。
下面以垂直类模式为例给出预测像素的计算步骤(水平类模式计算过程与之类似)。
对于给定垂直类模式 M,使用“投影像素”法将其需要用到的参考像素映射为一维形式,记为Ref。具体方法如下。
若模式 M对应的角度偏移值offset[M]<0,则需要将当前TU左侧的像素值按照模式M对应的方向投影到上方参考像素的左侧。Ref可由式(4-1)计算得出:
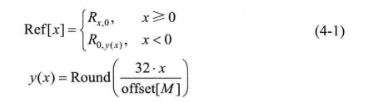
其中,Round(·)表示四舍五入。
若 ofset[M]≥0,则只需要用到当前 TU 上方的参考像素。Ref由下式计算:
![]()
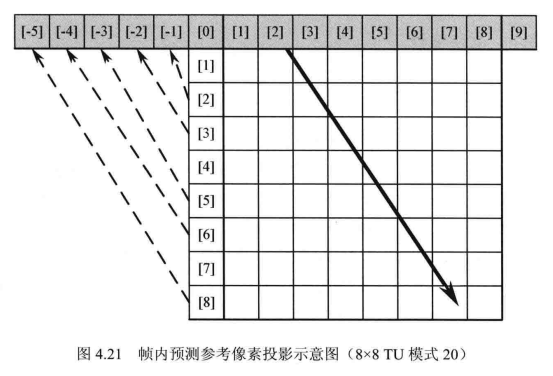
例如,对于一个8X8TU,模式20(ofset=-21)对应的投影方式可计算如下:
y(-1)=2,(-2)=3,y(-3)=5,y(-4)=6,y(-5)=8
如图 4.21所示,
有
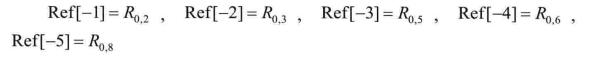
计算当前像素对应参考像素在Ref中的位置,记为pos:
![]()
计算当前像素对应参考像素的加权因子ω:
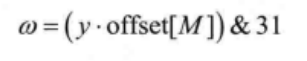
其中,&表示按位与运算。
计算当前像素的预测值:
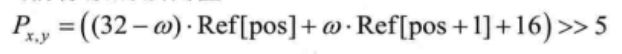
需要注意的是,对于模式26(垂直模式),预测像素值改由下式计算:
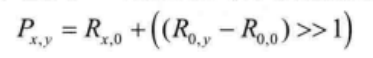
对于上式可以解释为,![]() 值的大小可以反映出垂直方向上像素值的变化趋势。若该值为负,即像素值在垂直方向上有减小的趋势,则相应地
值的大小可以反映出垂直方向上像素值的变化趋势。若该值为负,即像素值在垂直方向上有减小的趋势,则相应地![]() 需要在
需要在![]() 的基础上做一定程度的减小;反之亦然。
的基础上做一定程度的减小;反之亦然。
三、 H.265/HEVC帧间预测:
运动估计:
搜索算法:
在基于块运动补偿的视频编码框架中,运动搜索是最为重要的环节之一,同时也是编码端最耗时的模块。H.265/HEVC官方测试编码器HM10.0给出了两种搜索算法:一种是全搜索算法,另一种是TZSearch算法:
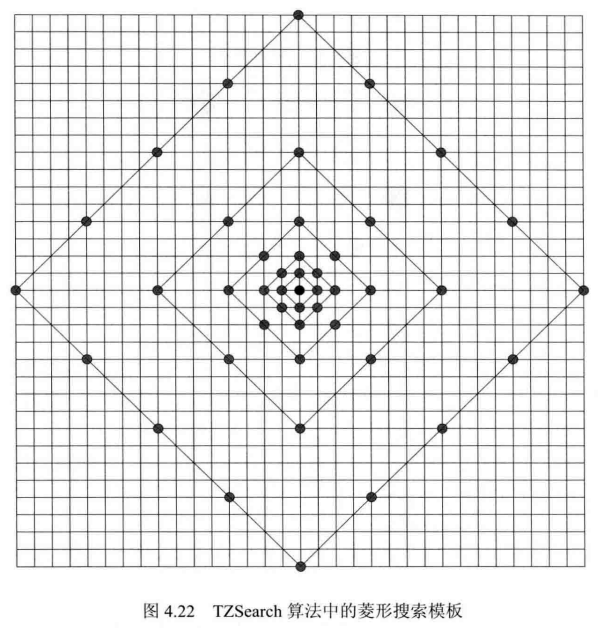
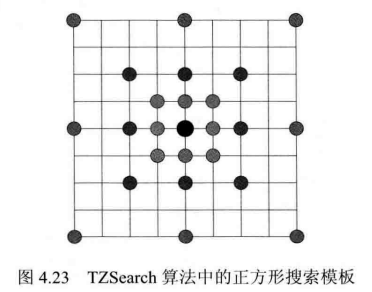
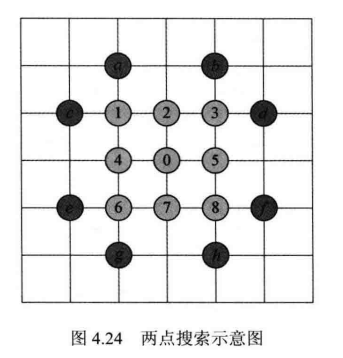
TZSearch算法是H.265/HEVC中出现的新技术,它包含下列步骤:
- 确定起始搜索点。H.265/HEVC采用AMVP技术来确定起始搜索点,AMVP会给出若干个候选预测MV,编码器从中选择率失真代价最小的作为预测MV,并用其所指向的位置作为起始搜索点。
- 以步长1开始,按照图4.22所示的菱形模板(或图4.23所示的正方形模板)在搜索范围内进行搜索,其中步长以2的整数次幂的形式递增,选出率失真代价最小的点作为该步骤的搜索结果。
- 若步骤②中得到的最优点对应的步长为1,则需要在该点周围做两点搜索,其主要目的是补充搜索最优点周围尚未搜索的点。如图4.24所示,若步骤②使用的是菱形模板,则最优点可能为2、4、5、7;若步骤②使用正方形模板,则最优点可能为1~8。两点搜索将会搜索图中与当前最优点距离最近的两个点。例如,若最优点为2,则会搜索a,b两个点;若最优点为6,则会搜索e,g两个点。
- 若步骤②中得到的最优点对应的步长大于某个阈值,则以该最优点为中心,在一定范围内做全搜索(搜索该范围内的所有点),选择率失真代价最小的作为该步骤的最优点。
- 以步骤④得到的最优点为新的起始搜索点,重复步骤②~④,细化搜索。当相邻两次细化搜索得到的最优点一致时停止细化搜索。此时得到的 MV 即为最终 MV。
表 4.4 给出了采用全搜索算法和TZSearch 算法的编码性能以及运动搜索时间比较结果。
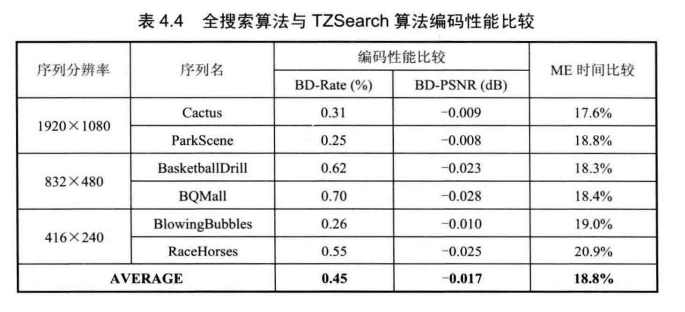
在表4.4中,编码性能的比较使用了BD-Rate 和BD-PSNR。BD-Rate表示PSNR相同时,TZSearch与全搜索算法相比编码比特率的增加量,该值为正表示编码性能有所降低。BD-PSNR表示编码比特率相同时,TZSearch与全搜索算法相比PSNR的增加量,该值为正表示编码性能有所提升。运动搜索时间用下式进行比较:

其中![]() 和
和![]() 分别表示 TZSearch 和全搜索算法耗费的时间。从表中的数据可以看出,TZSearch算法与全搜索算法相比,性能上略有降低(同PSNR下比特率平均仅增加了0.45%),而运动搜索时间仅为全搜索算法的 1/5。
分别表示 TZSearch 和全搜索算法耗费的时间。从表中的数据可以看出,TZSearch算法与全搜索算法相比,性能上略有降低(同PSNR下比特率平均仅增加了0.45%),而运动搜索时间仅为全搜索算法的 1/5。
亚像素精度运动估计:
在实际场景中,由于物体运动的距离并不一定是像素的整数倍,因此需要将运动估计的精度提升到亚像素级别。H.265/HEVC沿用了上一代标准H.264/AVC所使用的1/4像素精度运动估计,并进一步发展了其亚像素插值算法。相比于H.264/AVC中的6抽头滤波器(用于半像素精度)以及两点内插(用于1/4像素精度)方法,H.265/HEVC使用了更多的邻近像素点进行亚像素精度插值。
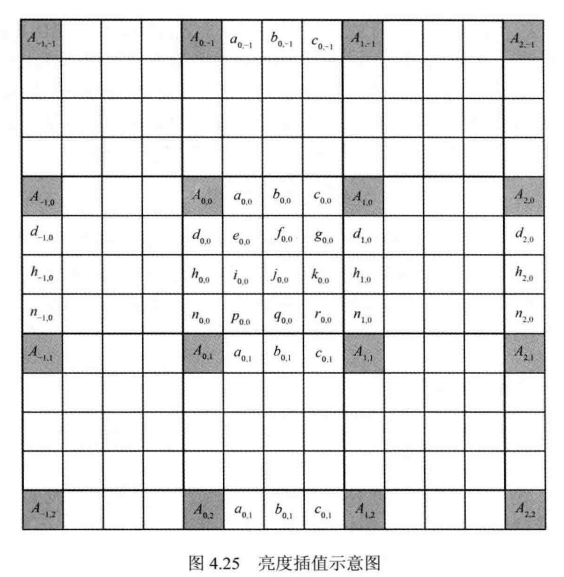
- 亮度分量插值算法。
半像素和1/4像素模板如图4.25所示,![]() 为整像素点,
为整像素点,![]() 等为半像素点,
等为半像素点,![]() 等为1/4像素点,
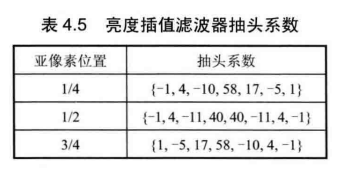
等为1/4像素点,![]() 等为3/4像素点,H.265/HEVC标准规定,亮度分量半像素位置的值由基于离散余弦变换的8抽头滤波器生成,1/4和3/4像素位置的值由基于离散余弦变换的7抽头滤波器生成。抽头系数由表 4.5 给出。
等为3/4像素点,H.265/HEVC标准规定,亮度分量半像素位置的值由基于离散余弦变换的8抽头滤波器生成,1/4和3/4像素位置的值由基于离散余弦变换的7抽头滤波器生成。抽头系数由表 4.5 给出。
下面参照图4.25中的模板详细说明亚像素插值的过程,主要可分为两个步骤:
①对整像素所在的行或列进行插值。以![]() 附近的亚像素点为例,满足条件的有
附近的亚像素点为例,满足条件的有 ![]() 其中
其中![]() 值可用水平方向的整像素点计算得出,
值可用水平方向的整像素点计算得出,![]() 值用垂直方向上的整像素点计算得出,计算如下:
值用垂直方向上的整像素点计算得出,计算如下:
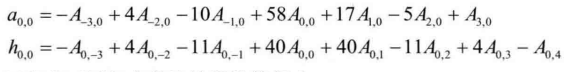
其余位置像素可用相应的滤波器计算得出。
②对剩余亚像素位置进行插值,对于不在整像素行或列位置的像素,如 ![]() 需要使用第一步中得到的整像素行的亚像素值(a,b,c位置)来计算得出,计算如下:
需要使用第一步中得到的整像素行的亚像素值(a,b,c位置)来计算得出,计算如下:
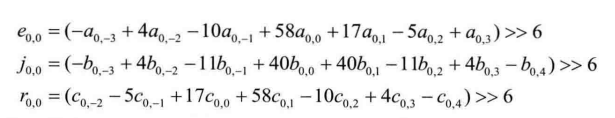
其余位置像素可用相应的滤波器计算得出
需要注意的是,经过亚像素插值后,所有像素值都被放大为原来的64倍,其主要目的是在中间过程保持一定的精度。而在后续的加权预测环节,所有放大后的像素值都会被还原。
色度分量插值算法:
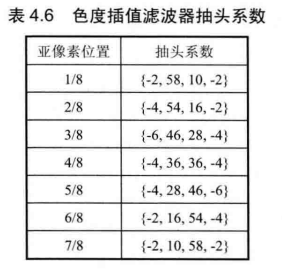
由于亮度分量运动估计达到了1/4像素精度,因此色度分量运动搜索需要达到 1/8 精度(对于 YCbCr 4:2:0而言)。色度分量亚像素插值模板如图4.26所示,其中![]() 为整像素点,其余都为亚像素点。标准规定色度亚像素插值使用基于离散余弦变换的4抽头滤波器,具体见表4.6.
为整像素点,其余都为亚像素点。标准规定色度亚像素插值使用基于离散余弦变换的4抽头滤波器,具体见表4.6.
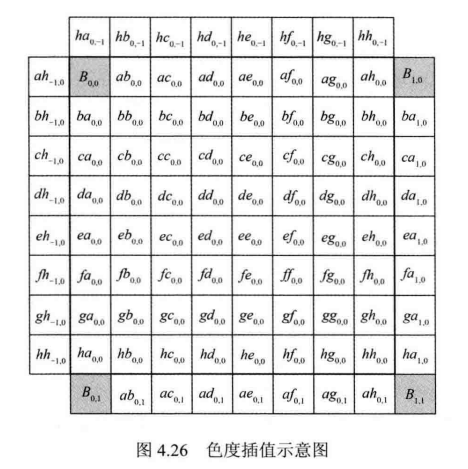
色度分量亚像素插值方法与亮度分量类似,也是先对整像素所在的行或列进行插值,再利用其结果对其余位置进行插值。例如,图4.26中的 ![]() 分别计算如下:
分别计算如下:
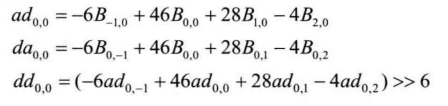
MV预测技术:
空域上相邻块的MV具有较强的相关性;同时,MV在时域上也具有一定的相关性。若利用空域或时域上相邻块的MV对当前块 MV 进行预测,仅对预测残差进行编码,则能够大幅节省 MV 的编码比特数。H.265/HEVC在MV的预测方面提出了两种新的技术--Merge技术和 AMVP 技术。
Merge和AMVP技术都使用了空域和时域MV预测的思想,通过建立候选MV列表,选取性能最优的一个作为当前PU的预测MV。二者区
别主要表现在以下两个方面。
- Merge 可以看成一种编码模式,在该模式下,当前PU的MV直接由空域(或时域)上邻近的PU预测得到,不存在MVD;而AMVP可以看成一种 MV 预测技术,编码器只需要对实际 MV与预测 MV的差值进行编码,因此是存在 MVD的。
- 二者候选 MV 列表长度不同,构建候选 MV 列表的方式也有所区别。下面详细介绍Merge和AMVP技术。
Merge模式:
Merge模式会为当前PU建立一个MV候选列表,列表中存在5个候选MV(及其对应的参考图像)。通过遍历这5个候选MV,并进行率失真代价的计算,最终选取率失真代价最小的一个作为该Merge模式的最优 MV。若编/解码端依照相同的方式建立该候选列表,则编码器只需要传输最优MV在候选列表中的索引即可,这样大幅节省了运动信息的编码比特数。
Merge 模式建立的MV 候选列表中包含了空域和时域两种情形;而对于BSlice,还包含组合列表的方式,分别介绍如下。
- 空域候选列表的建立。
空域MV候选列表的建立如图4.27所示,图中A1表示当前PU左侧最下方的PU,B1表示当前PU上方最右侧的PU,B0和A0分别表示当前PU右上方和左下方距离最近的PU,B2表示当前PU左上方距离最近的PU。H.265/HEVC标准规定,空域最多提供4个候选MV,即最多使用上述5个候选块中4个候选块的运动信息,列表按照A1→B1→B0→A0→(B2)的顺序建立,其中B为替补,即当A1,B1,B0,A0中有一个或多个不存在时,则需要使用B2的运动信息。
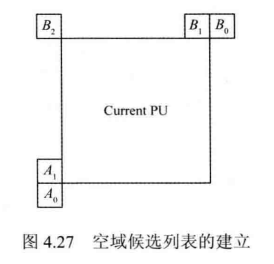
需要注意的是,对于图4.28所示的矩形划分方式中的PU,其候选列表的建立方式需要做特殊处理,具体如下。

对于图4.28(a)中的情形(CU划分方式为Nx2N、nLx2N或 nRx2N),PU1的候选列表中不能存在A1的运动信息。这是由于PU2一旦使用了A1(即 PU1)的信息,则会使PU1和PU2的 MV 一致,这与 2Nx2N划分方式无异。
同理,对于图4.28(b)中的情形(CU分方式为2NxN、2NxnU或2NxnD),PU2的候选列表中不能存在B1的运动信息。
- 时域候选列表的建立:
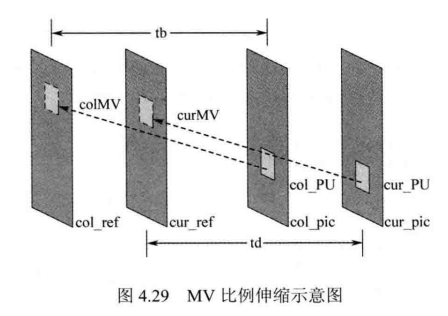
时域MV候选列表的建立利用了当前PU在邻近已编码图像中对应位置PU(即同位PU)的运动信息。与空域情形不同,时域候选列表不能直接使用候选块的运动信息,而需要根据与参考图像的位置关系做相应的比例伸缩调整,具体介绍如下。
如图4.29所示,cur_PU表示当前PU,col_PU 为其同位PU,td 和tb分别表示当前图像cur_pic、同位图像col_pic与二者参考图像 cur_ref、col_ref之间的距离。则当前PU的时域候选 MV可由式(4-2)计算:
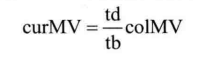
其中colMV 为同位 PU的 MV。
H.265/HEVC规定,时域最多只提供1个候选MV,由图4.30中H位置同位 PU的MV经伸缩得到。若位置同位PU不可用,则用C3位置的同位 PU 进行替换。
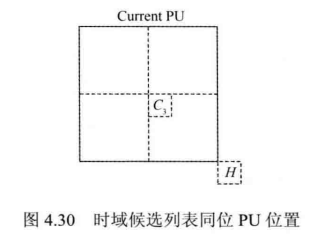
需要注意的是,若当前MV候选列表中候选MV的个数达不到5个时,需要使用(0,0)进行填补以达到规定的数目。
- 组合列表的建立:
对于B Slice中的PU而言,由于存在两个MV,因此其MV候选列表也需要提供两个预测 MV。H.265/HEVC标准将MV候选列表中的前4个候选MV进行两两组合,产生了用于B Slice的组合列表,见表4.7。
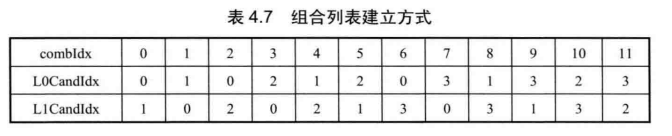
表4.7中combdx为组合列表中候选MV对的序号,L0Candldx和L1Candldx分别表示两个候选MV在原MV候选列表中的序号。需要注意的是,一个候选 MV对的两个 MV 不能相同。
AWVP技术:
高级运动向量预测(Advanced Motion Vector Prediction,AMVP)利用空余、时域上运动向量的相关性,为当前PU建立了候选预测MV列表。编码器从中选出最优的预测MV,并对MV进行差分编码;解码端通过建立相同的列表,仅需要运动向量残差(MVD)与预测MV在该列表中的序号即可计算出当前PU的MV。
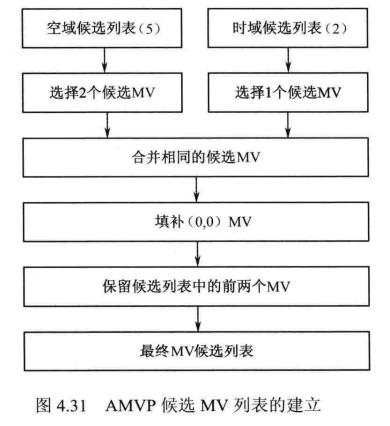
类似于Merge模式,AMVP候选MV列表也包含空域和时域两种情形,不同的是 AMVP 列表长度仅为2。
- 空域列表的建立:
AMVP空域MV候选列表的建立如图4.27所示,当前PU左侧和上方各产生一个候选预测MV,左侧选择顺序为A0→A1→scaled A1→scaled A1,上方选择顺序为B0→B1→B2,(→scaled B0→scaled B1→scaled B2)。其中,scaled A0表示将A0的MV进行比例伸缩[具体方法见式(4-2)],然而对于上方3个PU,其MV的比例伸缩只有在左侧两个PU都不可用或都是帧内预测模式时才会进行。当左侧(或上方)检测到第一个“可用的MV时,直接使用该MV作为当前PU的候选预测MV,而不再进行剩余的步骤。需要注意的是,只有当候选MV对应的参考图像与当前PU相同时,该候选MV才能被标记为“可用”;否则,需要对该候选 MV进行相应的比例伸缩。
- 是域列表的建立:
AMVP时域MV候选列表的建立方法与Merge 模式相同,读者可参考 Merge 技术中的相关内容。类似于Merge 模式,若最终 MV 候选列表长度不足2,需要用(0,0)进行填补。综上,AMVP的MV候选列表建立过程可用图 4.31 表示。
相关语法元素:
Merge和AMVP技术相关的语法元素:
- SPS:sps_temporal_mvp_enable_flag:该语法元素指明当前序列是否使用时域MV预测技术(即MV候选列表中是否存在时域候选 MV)。
- Slice 层:slice_temporal_mvp_enable_flag:该语法元素指明当前Slice 是否使用时域 MV 预测技术。five_minus_max_num_merge_cand:该语法元素指定当前Slice中Merge 模式 MV 候选列表的长度,范围为1~5。
- PU层:merge_flag:该语法元素指明当前PU是否使用了Merge 技术;merge_idx:该语法元素表示当前PU的运动信息在Merge 候选列表中的序号。mvp_10_flag和mvp_1l_flag:这两个语法元素分别表示当前PU的预测MV在两个参考图像队列(List0和List1)所对应 AMVP 列表中的位置。
加权预测:
加权预测原理:
加权预测可用于修正PSice或BSlice中的运动补偿预测像素,H.265/HEVC标准规定了两种加权预测方法:默认(Default)加权预测以及 Explicit 加权预测。下面详细介绍这两种加权预测方法。
- 默认加权预测:
默认加权预测方法较为简单,它未使用权值![]() 。根据参考图像队列的不同,可分为以下3种情况。
。根据参考图像队列的不同,可分为以下3种情况。
a、 仅使用参考图像队列List0。预测像素计算如下:
predSamples=(predSamplesL0+32)>>6
b、 仅使用参考图像队列 List1。预测像素计算如下:
predSamples =(predSamplesL1 + 32)>> 6
c、参考图像队列List0和List1 都使用。预测像素计算如下:
predSamples=(predSamplesL0+ predSamplesL1 + 64)>> 7
其中,predSamplesL0和predSamplesL1分别表示参考图像队列List0和List1中相应参考图像的重建像素值。需要注意的是,此处的>>操作对应于亚像素精度运动补偿过程中对预测像素值的放大。
- Explicit 加权预测。
对于Explicit加权预测,其权值![]() 由编码器决定,并需要传送至解码端。类似地,Explicit加权预测也可分为以下3种情况。
由编码器决定,并需要传送至解码端。类似地,Explicit加权预测也可分为以下3种情况。
a、仅使用参考图像队列 List0。预测像素计算如下:
![]()
b、仅使用参考图像队列List1。预测像素计算如下:
![]()
c、参考图像队列List0和List1都使用。预测像素计算如下:

其中,![]() 和
和![]() 为权值,offset0和offset1表示相应的偏移量,这4个值都可以在码流中获得。
为权值,offset0和offset1表示相应的偏移量,这4个值都可以在码流中获得。
相关语法元素:
加权预测相关的语法元素:
- PPS:weighted_pred_flag:该语法元素指明P Slice 是否使用加权预测。weighted_bipred_flag:该语法元素指明BSlice 是否使用加权预测。
- Slice 层:
luma_log2_weight_denom:为了避免浮点运算,标准规定在加权预测过程中全部使用整数。该语法元素表示亮度加权因子整数化时放大的倍数(即亮度加权因子的分母),范围为1~128。
delta_chroma_log2_weight_denom:该语法元素用于计算色度加权因子整数化时放大的倍数(即色度加权因子的分母)。
luma_weight _10_flag[i]:该语法元素指明List0队列中的第i个参考图像是否存在亮度加权因子。
chroma_weight_10_flag[i]:该语法元素指明 List0队列中的第i个参考图像是否存在色度加权因子
delta_luma_weight_10[i]:该语法元素用于计算 List0队列中的第i个参考图像的亮度加权因子。
luma_ofset_10[i]:该语法元素表示List0队列中的第i个参考图像亮度加权预测偏移值。
delta_chroma_weight _10[i][j]:该语法元素用于计算 List0 队列中的第i个参考图像的色度加权因子,j可取0和1,表示两个色度分量。
delta_chroma ofset 10[i][j]:该语法元素表示 List0队列中的第i个参考图像色度加权预测偏移值。
语法元素luma_weight_1l _flag[i],chroma_weight _11_flag[i], deltaluma_weight_1l[i], luma_offset_ 1l[i], delta_chroma_weight_1l[i][j], delta_chroma_offset_11[i][j]是针对参考图像队列 List1 而言的,含义同上。
四、H.265/HEVC的PCM模式
PCM模式 :
H.265/HEVC中有一种特殊的编码模式--PCM模式。在该模式下,编码器直接传输一个CU 的像素值,而不经过预测、变换等其他操作。同样地,解码端可以直接恢复当前CU的像素值,而不需要进行其他处理。
对于一些特殊的情况,例如当图像的内容极不规则或量化参数(Quantization Parameter,QP)非常小时,该模式与传统的“帧内一变换-量化一熵编码”相比,编码效率可能会更高。此外,PCM模式还适用于无损编码情形。
相关语法语义:
- SPS:
pcm_enabled_flag:该语法元素指明当前视频序列是否使用PCM模式。
pcm_sample_bit_depth_luma_minusl:该语法元素用于计算表示PCM模式亮度像素值所需的比特数。
pcm_sample_bit_depth_chroma_minusl:该语法元素用于计算表示PCM 模式色度像素值所需的比特数。
log2_min_pcm_luma_coding_block_size_minus3:该语法元素规定了使用 PCM 模式编码单元的最小尺寸。
log2_diff_max_min_pcm_luma_coding_block_size:该语法元素表示使用 PCM 模式编码单元最大最小尺寸的差异。
pcm_loop_filter_disabled_fag:该语法元素表示是否对使用了PCM模式的CU进行去块效应滤波和采样点自适应补偿(SAO)技术。
- CU层:
pcm_flag:该语法元素表示当前CU使用了PCM模式。
pcm_sample_luma和pcm_sample_chroma:这两个语法元素分别表示PCM 模式亮度和色度像素值。
参考资料:
《新一代高效视频编码 H.265/HEVC 原理、标准与实现》——万帅 杨付正 编著