在人工智能(AI)快速发展的今天,理解AI工作流和AI智能体之间的区别对于有效利用这些技术至关重要。本文将深入探讨AI工作流的类型,解析AI智能体的概念,并重点比较二者的关键差异。
1. 智能体 vs 工作流
关于“智能体”的定义众说纷纭。有些客户将其视为完全自主的系统,能够长期独立运行,并使用多种工具完成复杂任务;而另一些人则用它来描述遵循预设工作流的规范性实现。
在Anthropic,我们将这些统称为智能体系统,但明确区分了工作流和智能体:
- 工作流是通过预定义代码路径协调LLM和工具的系统。
- 智能体则是LLM动态指导自身流程和工具使用的系统,保持对任务完成方式的控制权。
用烹饪来比喻:工作流就像严格按食谱一步步操作;智能体则像一位厨师,根据食材和口味即时决定如何烹制菜肴。
以下是二者差异的简单可视化:
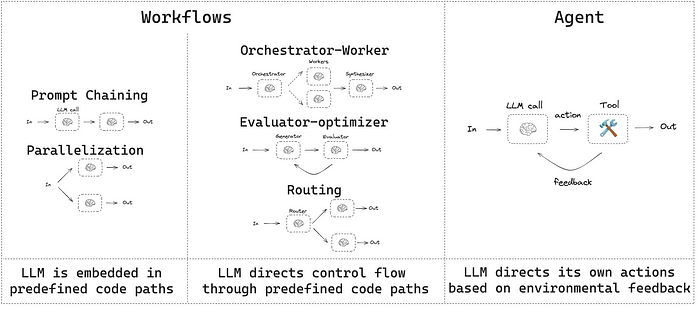
来源:LangChain
1.1 何时(以及何时不)使用智能体
开发LLM应用时,应从最简单的解决方案入手,仅在必要时引入复杂性。有时这意味着完全避免使用智能体系统。这些系统通常以更高的延迟和成本换取任务性能的提升,因此需权衡是否值得。
当需要更高复杂度时,工作流为结构明确的任务提供可预测性和一致性,而智能体更适合需要灵活性和规模化模型驱动决策的场景。但对许多应用而言,通过检索和上下文示例优化单个LLM调用通常已足够。
1.2 何时以及如何使用框架
许多框架能简化智能体系统的实现,例如:
这些框架简化了调用LLM、定义和解析工具、链式调用等底层任务,便于快速上手智能体系统。但它们常引入额外的抽象层,可能掩盖底层提示和响应,增加调试难度,甚至在不必要时鼓励复杂化。
建议开发者先直接使用LLM API,许多模式仅需几行代码即可实现。若选择框架,请务必深入理解底层代码,因为对其内部逻辑的错误假设是常见错误来源。
2. 构建模块
本节将探讨生产中常见的智能体系统模式。我们从基础模块——增强型LLM开始,逐步增加复杂度,从简单组合工作流到自主智能体。
2.1 设置
可使用支持结构化输出和工具调用的聊天模型。以下展示为Anthropic设置API密钥并测试结构化输出/工具调用的过程。
import os
import getpass
from langchain_anthropic import ChatAnthropic
def _set_env(var: str):
if not os.environ.get(var):
os.environ[var] = getpass.getpass(f"{
var}: ")
_set_env("ANTHROPIC_API_KEY")
llm = ChatAnthropic(model="claude-3-5-sonnet-latest")
2.2 增强型LLM
智能体系统的基础模块是具备检索、工具和记忆等增强功能的LLM。当前模型能主动使用这些能力——生成搜索查询、选择合适工具、决定保留哪些信息。
实现时建议关注两点:定制这些功能以适应具体用例,并确保为LLM提供简洁易用的接口。虽然实现方式多样,但可通过我们近期发布的模型上下文协议(MCP)来集成第三方工具生态系统,其客户端实现简单易用。
后文假设每次LLM调用均可访问这些增强功能。
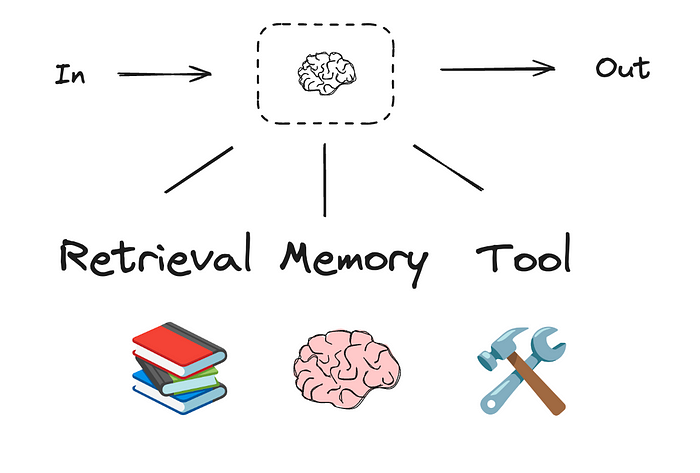
来源:LangChain
# 结构化输出的模式
from pydantic import BaseModel, Field
class SearchQuery(BaseModel):
search_query: str = Field(None, description="优化后的网络搜索查询。")
justification: str = Field(
None, description="该查询与用户请求的相关性说明。"
)
# 为LLM添加结构化输出模式
structured_llm = llm.with_structured_output(SearchQuery)
# 调用增强型LLM
output = structured_llm.invoke("钙CT评分与高胆固醇有何关联?")
# 定义工具
def multiply(a: int, b: int) -> int:
"""乘法工具"""
return a * b
# 为LLM绑定工具
llm_with_tools = llm.bind_tools([multiply])
# 触发工具调用的输入
msg = llm_with_tools.invoke("2乘以3是多少?")
# 获取工具调用
msg.tool_calls
3. 工作流
3.1 提示链
在提示链中,每个LLM调用处理前一个调用的输出。
如Anthropic博客所述:
提示链将任务分解为一系列步骤,每个LLM调用处理前一步的输出。可在任何中间步骤添加程序化检查(见下图中的“门控”),确保流程不偏离正轨。
适用场景:任务能清晰拆分为固定子任务时。主要目标是通过简化每个LLM调用的任务,以延迟换取更高准确率。
典型用例:
- 生成营销文案后翻译为其他语言;
- 编写文档大纲→检查是否符合标准→基于大纲撰写文档。
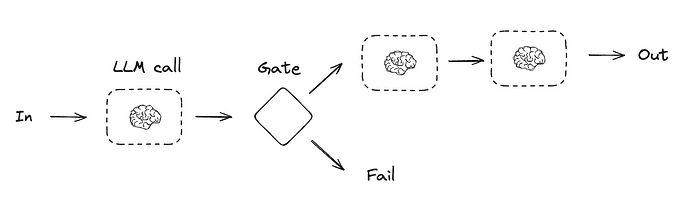
来源:LangChain
from typing_extensions import TypedDict
from langgraph.graph import StateGraph, START, END
from IPython.display import Image, display
# 图状态
class State(TypedDict):
topic: str # 主题
joke: str # 笑话
improved_joke: str # 改进版笑话
final_joke: str # 最终笑话
# 节点
def generate_joke(state: State):
"""首次LLM调用:生成初始笑话"""
msg = llm.invoke(f"写一个关于{
state['topic']}的短笑话")
return {
"joke": msg.content}
def check_punchline(state: State):
"""门控函数:检查笑话是否有包袱"""
# 简单检查——是否包含"?"或"!"
if "?" in state["joke"] or "!" in state["joke"]:
return "Fail"
return "Pass"
def improve_joke(state: State):
"""二次LLM调用:改进笑话"""
msg = llm.invoke(f"通过双关语让笑话更有趣:{
state['joke']}")
return {
"improved_joke": msg.content}
def polish_joke(state: State):
"""三次LLM调用:最终润色"""
msg = llm.invoke(f"为笑话添加意外转折:{
state['improved_joke']}")
return {
"final_joke": msg.content}
# 构建工作流
workflow = StateGraph(State)
# 添加节点
workflow.add_node("generate_joke", generate_joke)
workflow.add_node("improve_joke", improve_joke