生成对抗网络(GAN)原理详解
1. 背景
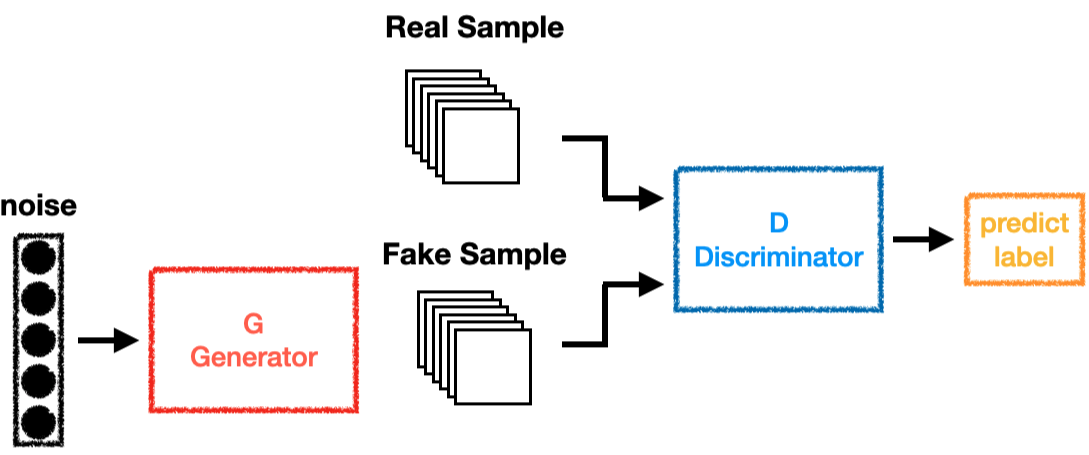
生成对抗网络(Generative Adversarial Network, GAN)由 Ian Goodfellow 等人于 2014 年提出,是一种通过对抗训练生成高质量数据的框架。其核心思想是让两个神经网络(生成器 G G G 和判别器 D D D)在博弈中共同进化:生成器试图生成逼真的假数据,而判别器试图区分真实数据与生成数据。这种对抗过程最终使生成器能够生成与真实数据分布高度接近的样本。
2. 数学推导
GAN 的目标函数是一个极小极大博弈(minimax game):
min G max D V ( D , G ) = E x ∼ p data ( x ) [ log D ( x ) ] + E z ∼ p z ( z ) [ log ( 1 − D ( G ( z ) ) ) ] \min_G \max_D V(D, G) = \mathbb{E}_{x \sim p_{\text{data}}(x)}[\log D(x)] + \mathbb{E}_{z \sim p_z(z)}[\log (1 - D(G(z)))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x)]+Ez∼pz(z)[log(1−D(G(z)))]
- 生成器 G G G:输入噪声 z ∼ p z ( z ) z \sim p_z(z) z∼pz(z),输出生成样本 G ( z ) G(z) G(z),目标是让 D ( G ( z ) ) D(G(z)) D(G(z)) 接近 1(欺骗判别器)。
- 判别器 D D D:输入真实数据 x x x 或生成数据 G ( z ) G(z) G(z),输出概率 D ( x ) ∈ [ 0 , 1 ] D(x) \in [0,1] D(x)∈[0,1],目标是最大化对真实数据和生成数据的区分能力。
优化过程:
- 固定 G G G,优化 D D D:通过梯度上升最大化 V ( D , G ) V(D, G) V(D,G)。
- 固定 D D D,优化 G G G:通过梯度下降最小化 V ( D , G ) V(D, G) V(D,G)。
3. 与 KL 散度的关系
当判别器达到最优时(即 D ( x ) = p data ( x ) p data ( x ) + p g ( x ) D(x) = \frac{p_{\text{data}}(x)}{p_{\text{data}}(x) + p_g(x)} D(x)=pdata(x)+pg(x)pdata(x)),生成器的目标等价于最小化 JS 散度(Jensen-Shannon Divergence):
JSD ( p data ∥ p g ) = 1 2 ( KL ( p data ∥ p data + p g 2 ) + KL ( p g ∥ p data + p g 2 ) ) \text{JSD}(p_{\text{data}} \| p_g) = \frac{1}{2} \left( \text{KL}\left(p_{\text{data}} \| \frac{p_{\text{data}} + p_g}{2}\right) + \text{KL}\left(p_g \| \frac{p_{\text{data}} + p_g}{2}\right) \right) JSD(pdata∥pg)=21(KL(pdata∥2pdata+pg)+KL(pg∥2pdata+pg))
JS 散度是对称化的 KL 散度,避免了 KL 散度的不对称性。但若 p data p_{\text{data}} pdata 和 p g p_g pg 的支撑集不重叠,JS 散度为常数 log 2 \log 2 log2,导致梯度消失。
推导过程如下:
固定生成器G后,判别器D的最优解通过对每个x独立优化以下表达式得到:
f ( D ( x ) ) = p data ( x ) log D ( x ) + p g ( x ) log ( 1 − D ( x ) ) . f(D(x)) = p_{\text{data}}(x) \log D(x) + p_g(x) \log(1 - D(x)). f(D(x))=pdata(x)logD(x)+pg(x)log(1−D(x)).
对 D ( x ) D(x) D(x)求导并令导数为零:
p data ( x ) D ( x ) − p g ( x ) 1 − D ( x ) = 0 ⟹ D ∗ ( x ) = p data ( x ) p data ( x ) + p g ( x ) . \frac{p_{\text{data}}(x)}{D(x)} - \frac{p_g(x)}{1 - D(x)} = 0 \implies D^*(x) = \frac{p_{\text{data}}(x)}{p_{\text{data}}(x) + p_g(x)}. D(x)pdata(x)−1−D(x)pg(x)=0⟹D∗(x)=pdata(x)+pg(x)pdata(x).
将最优判别器 D ∗ ( x ) D^*(x) D∗(x)代入目标函数 V ( D ∗ , G ) V(D^*, G) V(D∗,G):
V ( D ∗ , G ) = E x ∼ p data [ log p data p data + p g ] + E x ∼ p g [ log p g p data + p g ] . V(D^*, G) = \mathbb{E}_{x \sim p_{\text{data}}} \left[ \log \frac{p_{\text{data}}}{p_{\text{data}} + p_g} \right] + \mathbb{E}_{x \sim p_g} \left[ \log \frac{p_g}{p_{\text{data}} + p_g} \right]. V(D∗,G)=Ex∼pdata[logpdata+pgpdata]+Ex∼pg[logpdata+pgpg].
展开后得到:
∫ p data log p data p data + p g d x + ∫ p g log p g p data + p g d x . \int p_{\text{data}} \log \frac{p_{\text{data}}}{p_{\text{data}} + p_g} dx + \int p_g \log \frac{p_g}{p_{\text{data}} + p_g} dx. ∫pdatalogpdata+pgpdatadx+∫pglogpdata+pgpgdx.
令 M = p data + p g 2 M = \frac{p_{\text{data}} + p_g}{2} M=2pdata+pg,则上式可改写为:
∫ p data ( log p data 2 M ) d x + ∫ p g ( log p g 2 M ) d x . \int p_{\text{data}} \left( \log \frac{p_{\text{data}}}{2M} \right) dx + \int p_g \left( \log \frac{p_g}{2M} \right) dx. ∫pdata(log2Mpdata)dx+∫pg(log2Mpg)dx.
进一步分解:
∫ p data log p data M d x ⏟ KL ( p data ∥ M ) − log 2 + ∫ p g log p g M d x ⏟ KL ( p g ∥ M ) − log 2. \underbrace{\int p_{\text{data}} \log \frac{p_{\text{data}}}{M} dx}_{\text{KL}(p_{\text{data}} \| M)} - \log 2 + \underbrace{\int p_g \log \frac{p_g}{M} dx}_{\text{KL}(p_g \| M)} - \log 2. KL(pdata∥M)
∫pdatalogMpdatadx−log2+KL(pg∥M)
∫pglogMpgdx−log2.
合并后得到:
KL ( p data ∥ M ) + KL ( p g ∥ M ) − 2 log 2. \text{KL}(p_{\text{data}} \| M) + \text{KL}(p_g \| M) - 2\log 2. KL(pdata∥M)+KL(pg∥M)−2log2.
根据JS散度的定义:
JSD ( p data ∥ p g ) = 1 2 ( KL ( p data ∥ M ) + KL ( p g ∥ M ) ) , \text{JSD}(p_{\text{data}} \| p_g) = \frac{1}{2} \left( \text{KL}(p_{\text{data}} \| M) + \text{KL}(p_g \| M) \right), JSD(pdata∥pg)=21(KL(pdata∥M)+KL(pg∥M)),
因此目标函数可表示为:
2 ⋅ JSD ( p data ∥ p g ) − 2 log 2. 2 \cdot \text{JSD}(p_{\text{data}} \| p_g) - 2\log 2. 2⋅JSD(pdata∥pg)−2log2.
由于常数项不影响优化方向,生成器G的最小化目标等价于最小化JS散度。
不重叠时的特性:
当 ( p ) 和 ( g ) 不重叠时,对于所有 ( x ):
- 若 ( p(x) > 0 ),则 ( g(x) = 0 ),此时 ( M(x) = \frac{p(x)}{2} );
- 若 ( g(x) > 0 ),则 ( p(x) = 0 ),此时 ( M(x) = \frac{g(x)}{2} )。
计算KL散度:
- 对于 ( \text{KL}(p \parallel M) ),在 ( p ) 的支撑集上:
[
\text{KL}(p \parallel M) = \sum p(x) \log \frac{p(x)}{M(x)} = \sum p(x) \log \frac{p(x)}{p(x)/2} = \sum p(x) \log 2 = \log 2.
] - 同理,( \text{KL}(g \parallel M) = \log 2 )。
JS散度的结果:
- 代入JS散度公式:
[
\text{JS}(p \parallel g) = \frac{1}{2} \log 2 + \frac{1}{2} \log 2 = \log 2.
]
4. 损失函数的直观理解
- 判别器损失:最大化对真实样本的置信度( log D ( x ) \log D(x) logD(x))和对生成样本的否定( log ( 1 − D ( G ( z ) ) ) \log (1 - D(G(z))) log(1−D(G(z))))。
- 生成器损失:最小化 log ( 1 − D ( G ( z ) ) ) \log (1 - D(G(z))) log(1−D(G(z))),即让生成样本被判别器判定为真实。
关键直觉:生成器和判别器在动态博弈中互相提升。生成器逐渐逼近真实分布,而判别器被迫提升鉴别能力,最终达到纳什均衡。
5. 生成高质量数据的原因
- 对抗训练的自我强化:生成器必须不断改进以欺骗判别器,而判别器的提升反过来推动生成器更精细地拟合真实分布。
- 隐式分布匹配:GAN 直接学习从噪声到数据分布的映射,避免了显式概率密度估计(如 VAE),更适合复杂分布。
6. GAN 的问题及原因
模型崩溃(Mode Collapse)
- 现象:生成器仅生成少数几种样本,缺乏多样性。
- 原因:生成器找到一种能欺骗当前判别器的模式后,停止探索其他区域。判别器未能提供足够梯度迫使生成器覆盖全部真实分布。
训练不稳定性
- 梯度消失:当判别器过于强大时,生成器的梯度 ∇ z log ( 1 − D ( G ( z ) ) ) \nabla_z \log (1 - D(G(z))) ∇zlog(1−D(G(z))) 趋近于零,导致无法更新。
- 模式不重叠:若 ( p_{\text{data}} ) 和 ( p_g ) 的支撑集不重叠,JS 散度无法提供有效梯度(理论缺陷)。
- 平衡难以维持:生成器和判别器的能力需同步提升,否则一方压倒另一方会导致训练震荡。
判别器过强导致梯度消失的推导**
注:模式不重叠导致的梯度消失推导在上面- 损失函数 在原始GAN中,生成器的目标是最小化以下损失函数:
L G = E z ∼ p ( z ) [ log ( 1 − D ( G ( z ) ) ) ] . \mathcal{L}_G = \mathbb{E}_{z \sim p(z)} \left[ \log(1 - D(G(z))) \right]. LG=Ez∼p(z)[log(1−D(G(z)))].
对应的梯度为:
∇ θ G L G = E z ∼ p ( z ) [ − D ′ ( G ( z ) ) 1 − D ( G ( z ) ) ⋅ ∇ θ G G ( z ) ] . \nabla_{\theta_G} \mathcal{L}_G = \mathbb{E}_{z \sim p(z)} \left[ \frac{-D'(G(z))}{1 - D(G(z))} \cdot \nabla_{\theta_G} G(z) \right]. ∇θGLG=Ez∼p(z)[1−D(G(z))−D′(G(z))⋅∇θGG(z)]. - 完美判别器 当判别器过于强大时,对生成样本的判别结果 D ( G ( z ) ) D(G(z)) D(G(z)) 会趋近于0(即判别器几乎确信生成样本是假的)。此时:
- 分子分析: D ′ ( G ( z ) ) D'(G(z)) D′(G(z)) 是判别器对生成样本的梯度,当判别器在真实样本附近饱和(例如使用Sigmoid激活函数),其梯度 D ′ ( G ( z ) ) D'(G(z)) D′(G(z)) 会趋近于0。
- 分母分析: 1 − D ( G ( z ) ) 1 - D(G(z)) 1−D(G(z)) 趋近于1,看似不影响梯度,但由于分子 D ′ ( G ( z ) ) D'(G(z)) D′(G(z)) 已趋近于0,整体梯度仍然趋近于0。 - 直观解释
- 判别器的“压倒性优势”:如果判别器完美区分真假样本( D ( G ( z ) ) → 0 D(G(z)) \to 0 D(G(z))→0),生成器的任何微小改进都无法改变判别器的判断,导致梯度缺乏方向性信息。
- 损失函数平坦化:当 log ( 1 − D ( G ( z ) ) ) \log(1 - D(G(z))) log(1−D(G(z))) 接近0时,损失函数的“地形”变得平坦,梯度消失,优化过程停滞。
- 损失函数 在原始GAN中,生成器的目标是最小化以下损失函数:
改进方法:
- 修改生成器损失函数:
将生成器的目标从 min log ( 1 − D ( G ( z ) ) ) \min \log(1 - D(G(z))) minlog(1−D(G(z))) 改为 max log ( D ( G ( z ) ) ) \max \log(D(G(z))) maxlog(D(G(z)))(即反转标签),避免梯度饱和。根据链式规则, ∇ θ G L G = ∇ G L G ⋅ ∇ θ G \nabla_{\theta_G}\mathcal{L}_G=\nabla_G \mathcal{L}_G \cdot \nabla_\theta G ∇θGLG=∇GLG⋅∇θG。当 D ( G ( z ) ) → 0 D(G(z))\to 0 D(G(z))→0, ∇ G l o g ( 1 − D G ( z ) ) = − D ′ G ( z ) 1 − D G ( z ) → 0 \nabla_G log(1-DG(z))=-\frac{D'G(z)}{1-DG(z)}\to 0 ∇Glog(1−DG(z))=−1−DG(z)D′G(z)→0, D ′ G ( z ) D'G(z) D′G(z)在 D G ( z ) → 0 时趋于 s i g m o i d 饱和 DG(z)\to 0时趋于sigmoid饱和 DG(z)→0时趋于sigmoid饱和,而 ∇ G l o g ( D G ( z ) ) = 1 D G ( z ) → ∞ \nabla_G log(DG(z))=\frac{1}{DG(z)}\to \infty ∇Glog(DG(z))=DG(z)1→∞ - 使用Wasserstein GAN(WGAN):
通过Wasserstein距离设计损失函数,其梯度在判别器较强时仍能保持稳定。且使用 Wasserstein 距离(Earth-Mover 距离)替代传统的 JS 散度或 KL 散度,支撑集不重叠时仍能提供有效的梯度。后续详细介绍WGAN,其数学推导也很优美 - 控制判别器的训练强度:
避免过度训练判别器(例如限制判别器的更新频率或使用梯度惩罚) - 添加噪声:向真实数据或生成数据注入噪声(如高斯噪声),扩大两者的支撑集,使其部分重叠。
- 修改生成器损失函数:
7. 总结
GAN 通过对抗训练实现了数据生成领域的突破,但其成功依赖于生成器与判别器的动态平衡。模型崩溃和训练不稳定源于目标函数的理论缺陷(如 JS 散度的局限性)及优化过程的敏感性。后续改进(如 WGAN 使用 Wasserstein 距离)通过设计更合理的距离度量缓解了这些问题,但核心挑战仍存。
以上内容由 AI 生成,仅供参考,不代表开发者的立场。
8. 代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
import numpy as np
# 超参数设置
batch_size = 64
latent_dim = 100 # 潜在向量维度
img_dim = 28*28 # 图像维度(MNIST为28x28)
epochs = 200 # 训练轮数
lr = 0.0002 # 学习率
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
'''
数据加载和预处理
'''
# 数据预处理:归一化到[-1, 1]范围,并转换为Tensor
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,)) # 单通道
])
# 加载MNIST数据集
dataset = datasets.MNIST(
root='./data',
train=True,
download=True,
transform=transform
)
# 创建数据加载器
dataloader = DataLoader(
dataset,
batch_size=batch_size,
shuffle=True,
num_workers=4 # 多线程加载
)
'''
生成器网络定义
'''
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
# 全连接网络结构
self.model = nn.Sequential(
nn.Linear(latent_dim, 256), # 输入:潜在向量 (batch, 100)
nn.LeakyReLU(0.2, inplace=True), # LeakyReLU防止梯度消失
nn.Linear(256, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(512, 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Linear(1024, img_dim), # 输出:展平的图像 (batch, 784)
nn.Tanh() # 输出范围[-1, 1],与预处理匹配
)
def forward(self, z):
return self.model(z).view(-1, 1, 28, 28) # 重塑为图像形状 (batch, 1, 28, 28)
'''
判别器网络定义
'''
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
# 全连接网络结构
self.model = nn.Sequential(
nn.Linear(img_dim, 1024), # 输入:展平的图像 (batch, 784)
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3), # Dropout防止过拟合
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1), # 输出:判别概率 (batch, 1)
nn.Sigmoid() # 映射到[0,1]
)
def forward(self, img):
img_flat = img.view(-1, img_dim) # 展平图像
return self.model(img_flat)
'''
模型初始化和优化器
'''
# 初始化生成器和判别器
generator = Generator().to(device)
discriminator = Discriminator().to(device)
# 定义损失函数(二元交叉熵)
criterion = nn.BCELoss()
# 定义优化器(Adam优化器)
optimizer_G = optim.Adam(generator.parameters(), lr=lr)
optimizer_D = optim.Adam(discriminator.parameters(), lr=lr)
'''
训练循环
'''
# 固定潜在向量用于生成示例图像
fixed_z = torch.randn(16, latent_dim).to(device)
for epoch in range(epochs):
for i, (real_imgs, _) in enumerate(dataloader):
batch_size = real_imgs.size(0)
real_imgs = real_imgs.to(device)
# ========================
# 训练判别器(最大化对数似然)
# ========================
optimizer_D.zero_grad()
# 真实图像的损失
real_labels = torch.ones(batch_size, 1).to(device) # 真实标签为1
real_output = discriminator(real_imgs)
real_loss = criterion(real_output, real_labels)
# 生成图像的损失,目标是最小化 log(1 - D(G(z))),但实际优化 log(D(G(z)))(更稳定)
z = torch.randn(batch_size, latent_dim).to(device)
fake_imgs = generator(z)
fake_labels = torch.zeros(batch_size, 1).to(device) # 生成标签为0
fake_output = discriminator(fake_imgs.detach()) # 阻止梯度流向生成器
fake_loss = criterion(fake_output, fake_labels)
# 总损失反向传播
d_loss = real_loss + fake_loss
d_loss.backward()
optimizer_D.step()
# ========================
# 训练生成器(最小化判别器对生成图像的判别误差)
# ========================
optimizer_G.zero_grad()
# 生成器的目标:让判别器认为生成图像为真
gen_labels = torch.ones(batch_size, 1).to(device) # 欺骗标签为1
gen_output = discriminator(fake_imgs) # 注意此处不detach
g_loss = criterion(gen_output, gen_labels)
g_loss.backward()
optimizer_G.step()
# 打印训练进度
if i % 200 == 0:
print(f"[Epoch {epoch}/{epochs}] [Batch {i}/{len(dataloader)}] "
f"D Loss: {d_loss.item():.4f} G Loss: {g_loss.item():.4f}")
# 每轮结束后生成示例图像
if epoch % 10 == 0:
with torch.no_grad():
fake_imgs = generator(fixed_z).cpu()
grid = torchvision.utils.make_grid(fake_imgs, nrow=4, normalize=True)
plt.imshow(np.transpose(grid, (1, 2, 0)))
plt.axis('off')
plt.savefig(f'gan_generated_epoch_{epoch}.png')
plt.close()