目录
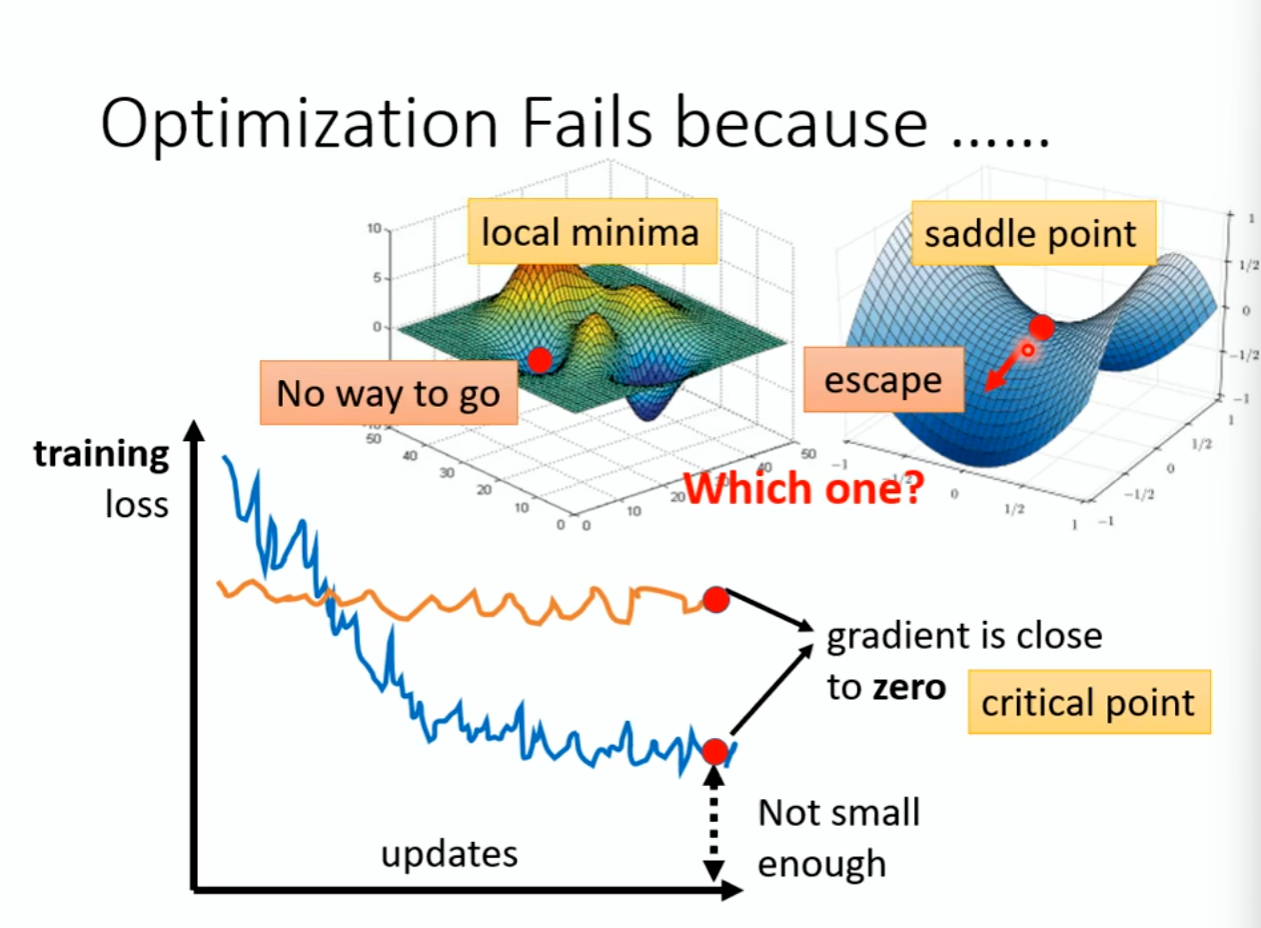
Optimization Fails because local minima or saddle point(最佳匹配失败)
局部最小值Local和鞍点saddle point:
local minima:四周都是最低, 他是图像的山谷。No Way To Go
saddle point:旁边有路可以走
利用泰勒展开,计算出θ0处的θ

怎么判断?利用泰勒公式,看是否是最高点?最低点?平常点?计算H矩阵的特征值的正负性即可 。
示例:y=(1-w1*w2*x)²
H是二次微分的那个矩阵
H等于【【0,-2】,【-2,0】】
特征值为±2,说明为Saddle point
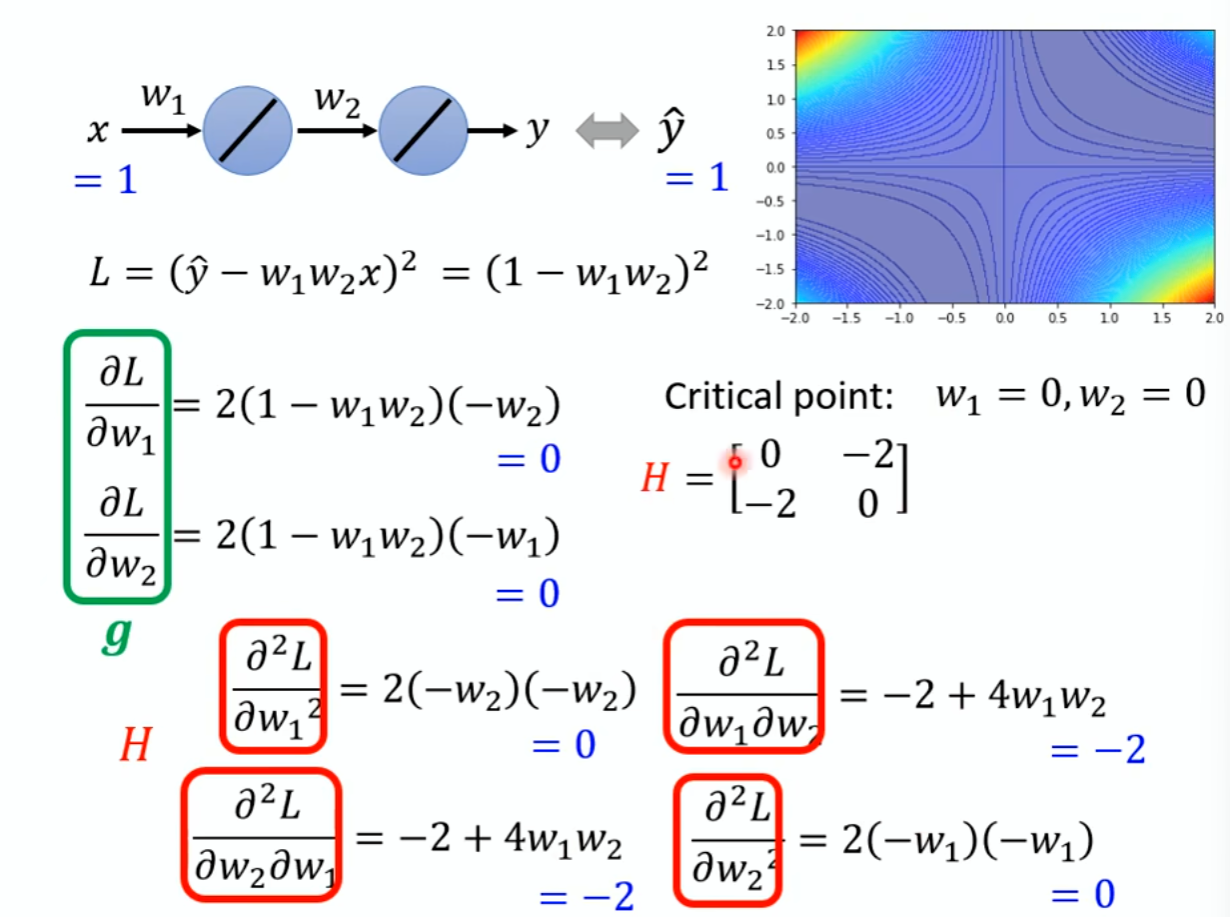
出现这种情况怎么办?用特征向量带进去,求出数值,带进去,即沿着特征向量的方向走,会让Loss变小。逃离你的Seddle Point。
批次Batch和动量momentum:
Batch:所有的data分成一个一个Batch,Batch的规模在初步增加的时候消耗的时间不会有很多的增长.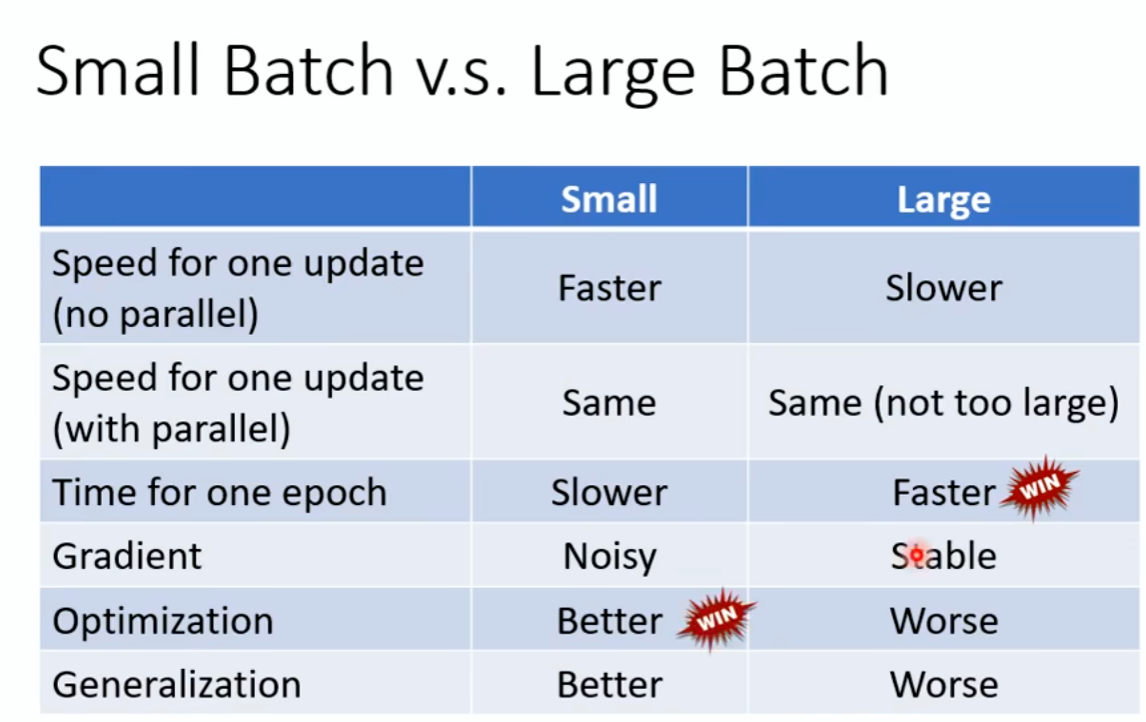
Momentum:计算出Gradient和前一步的方向,来计算出下一步应该走的方向。
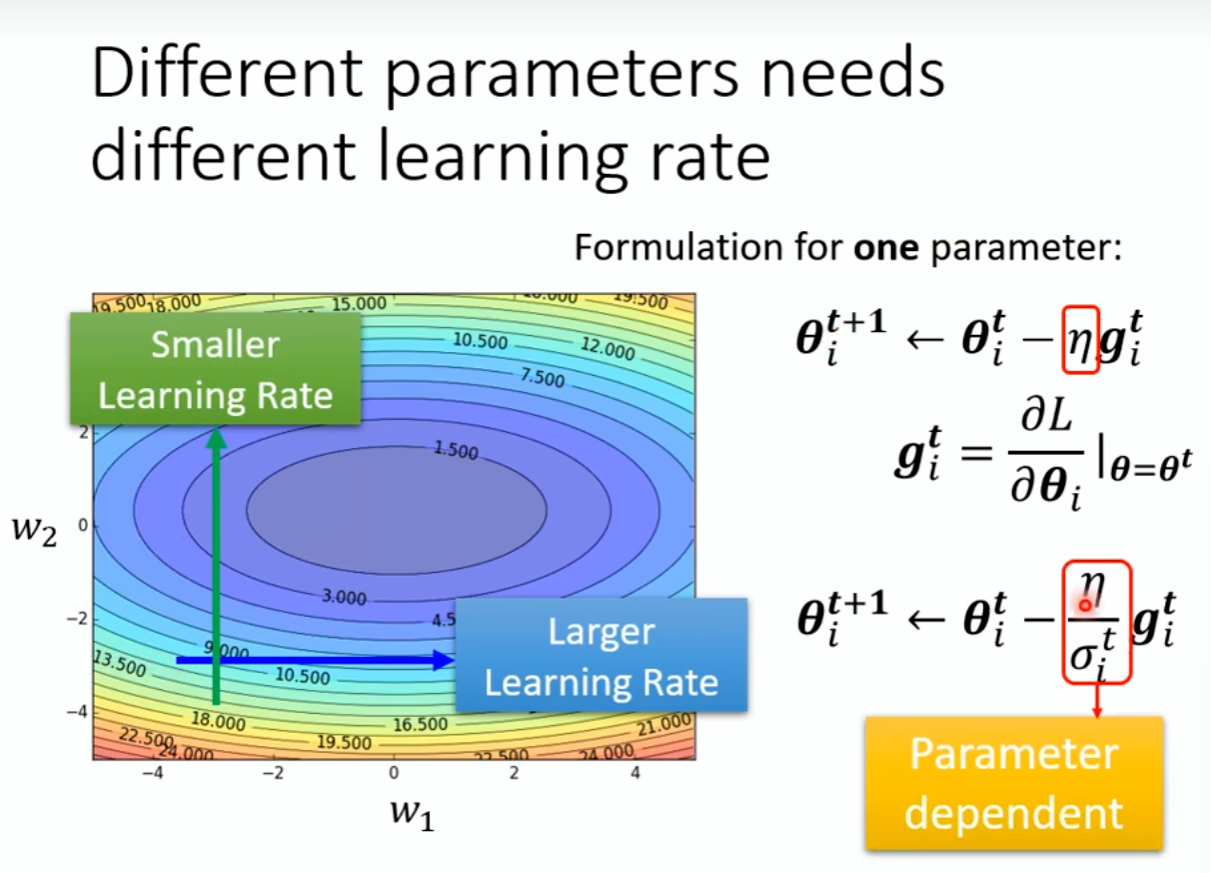
自动调整学习Learning Rate:
深度学习时Loss保持不变了,可能是在Local Minima的左右两边震荡,实际上并没有找到最低点。理想状态下如果在某一个方向上坡度特别的缓慢,要让Learning Rate大一点,如果很陡峭,就要让Learning Rate小一点,客制化Learning Rate。
Root Mean Square算法:
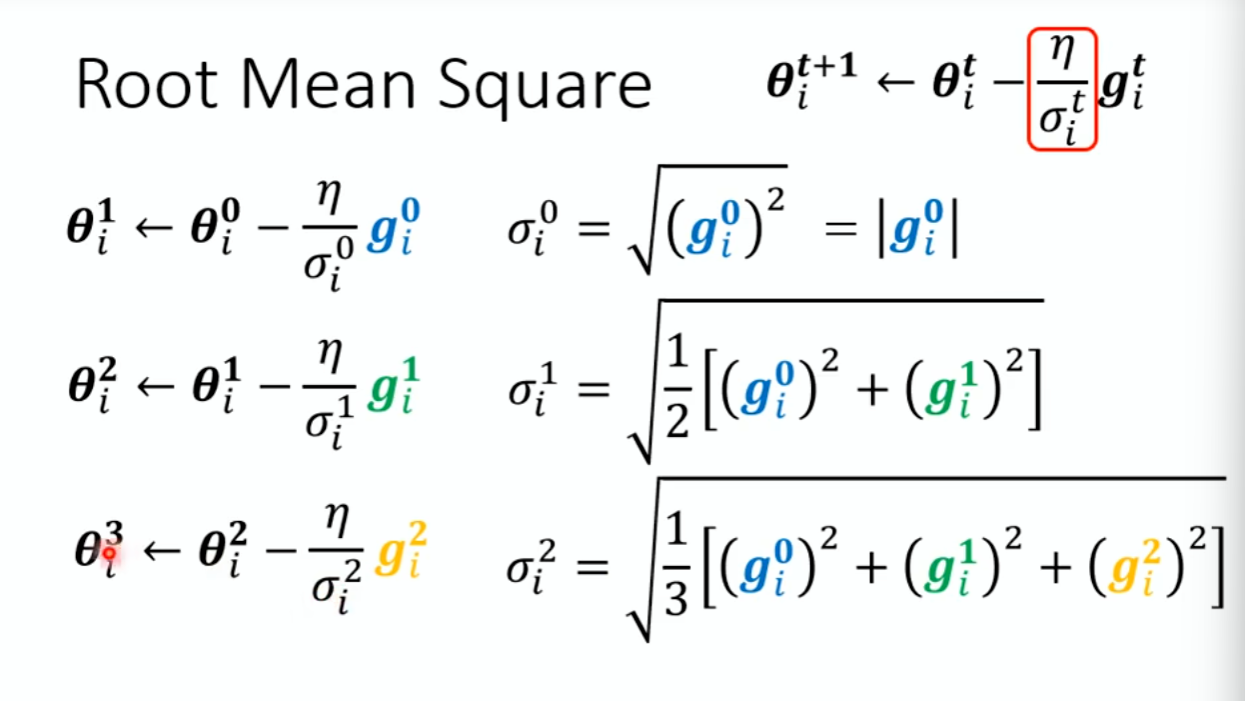
坡度小的时候算出来的g比较小。
也可以用RMSProp算法:主要是可以调整每个g的权重,但是会出现一种问题,当 δ很小的时候,η分数除一下会出现一个无穷大,会发生一次很大的震荡。但是震荡后会修正回来。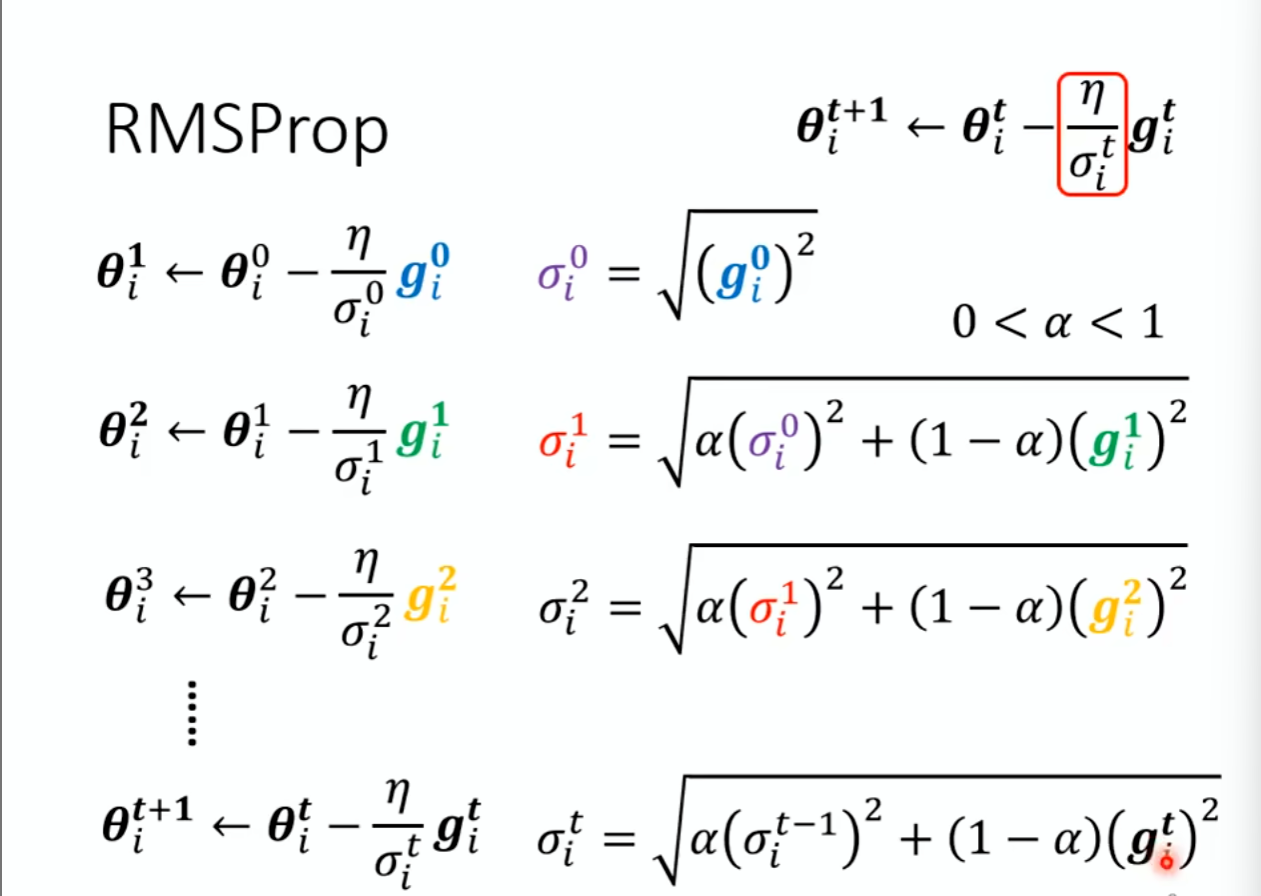
损失函数Loss可能也会有影响:
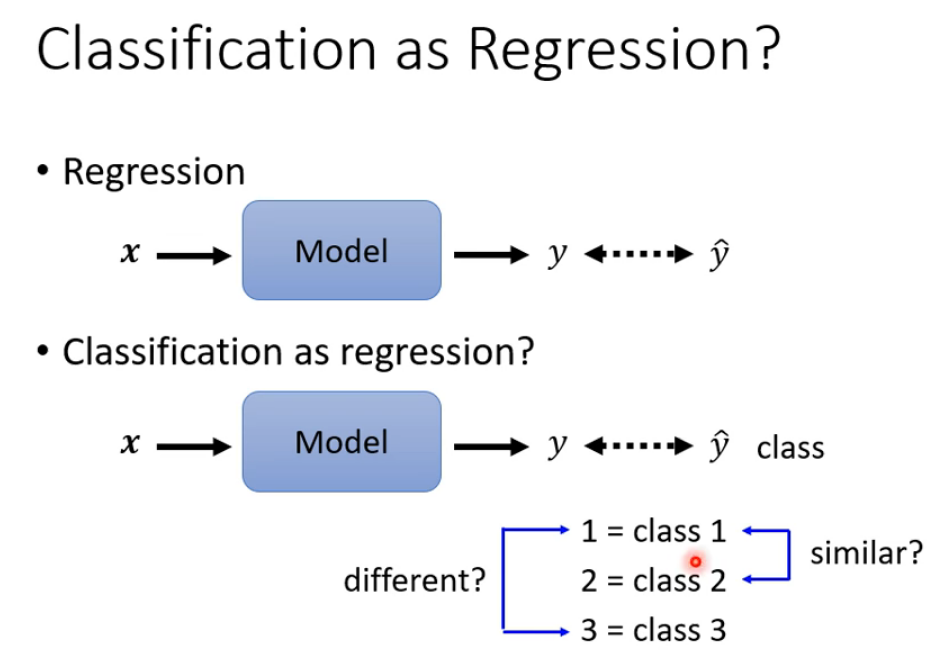
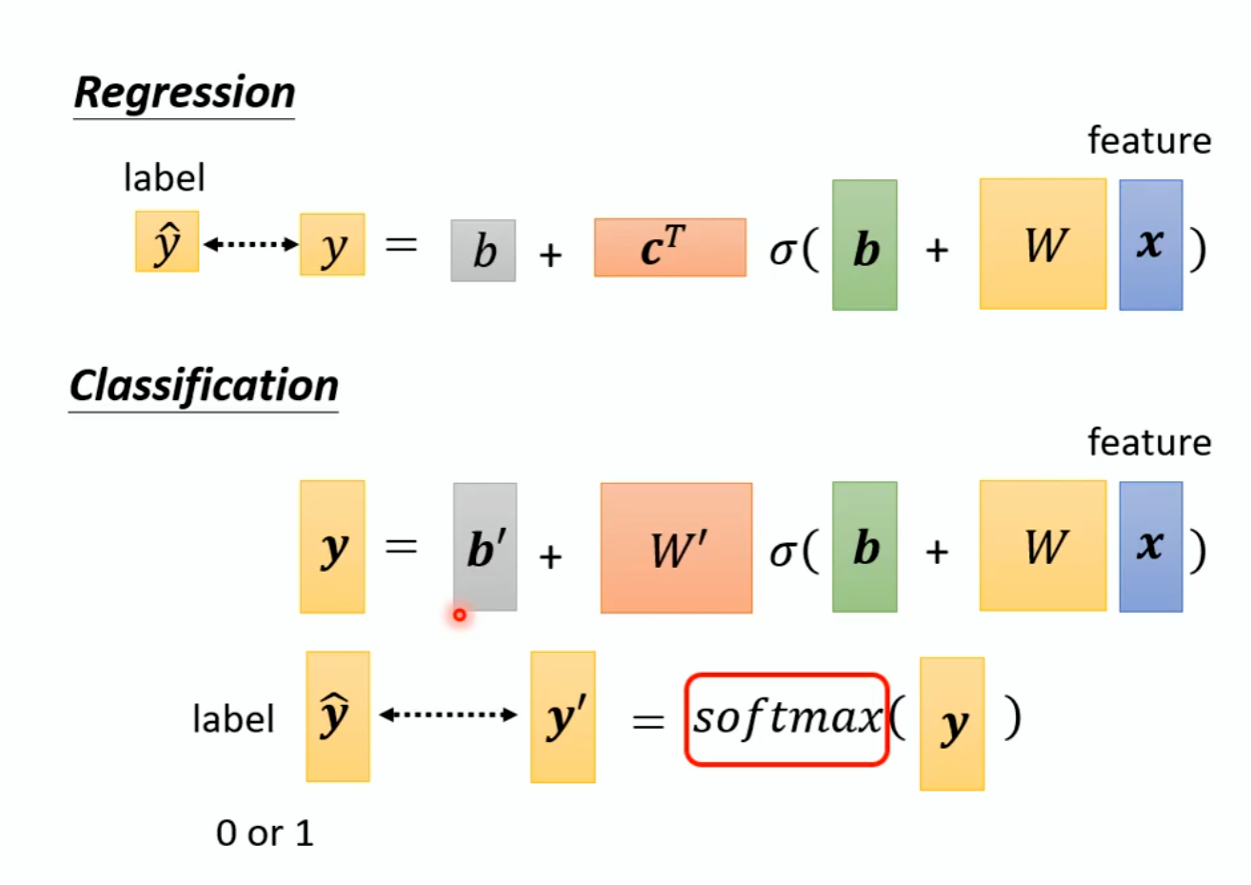
Classifica:
Regression:输入一个x通过一个模型的计算得出y与正确的y进行比较。
Classification:输入一个x通过一个模型的计算得出y class与正确的y class进行比较。
但是分类可能比较接近,可以把类别用向量表示。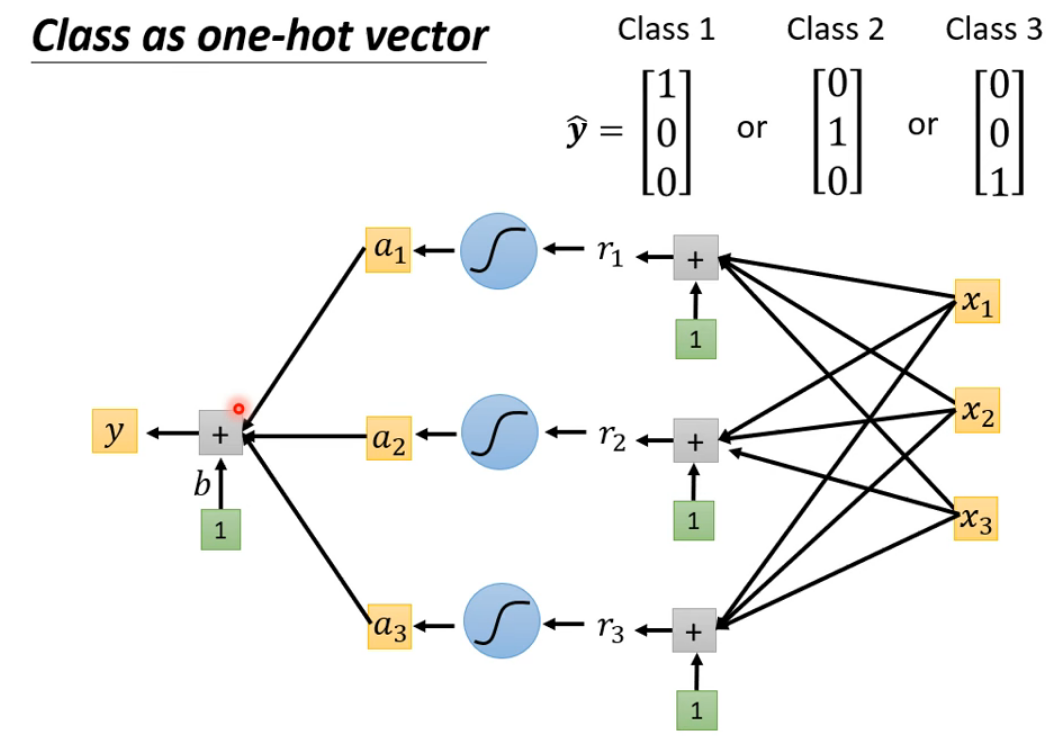
 Batch Normalization批次标准化:
Batch Normalization批次标准化:
把error surface的山铲平,更好的Optimization。如果Loss对于w1和w2的斜率很高。用一个巨大的network计算很多资料,求出平均值。
识别宝可梦还是数码宝贝:
定义Function:图片线条化,计算线条复杂程度,复杂程度大于h是数码宝贝,复杂程度小于h是宝可梦。现在要计算这个h。h属于{1,2,......,10 000}。|H|有10 000个选择表示h的复杂程度。
定义Loss:x为图片,y为分类。L(h,D)h表示参数,D表示测试集。用输出表示正确、输出1表示错误。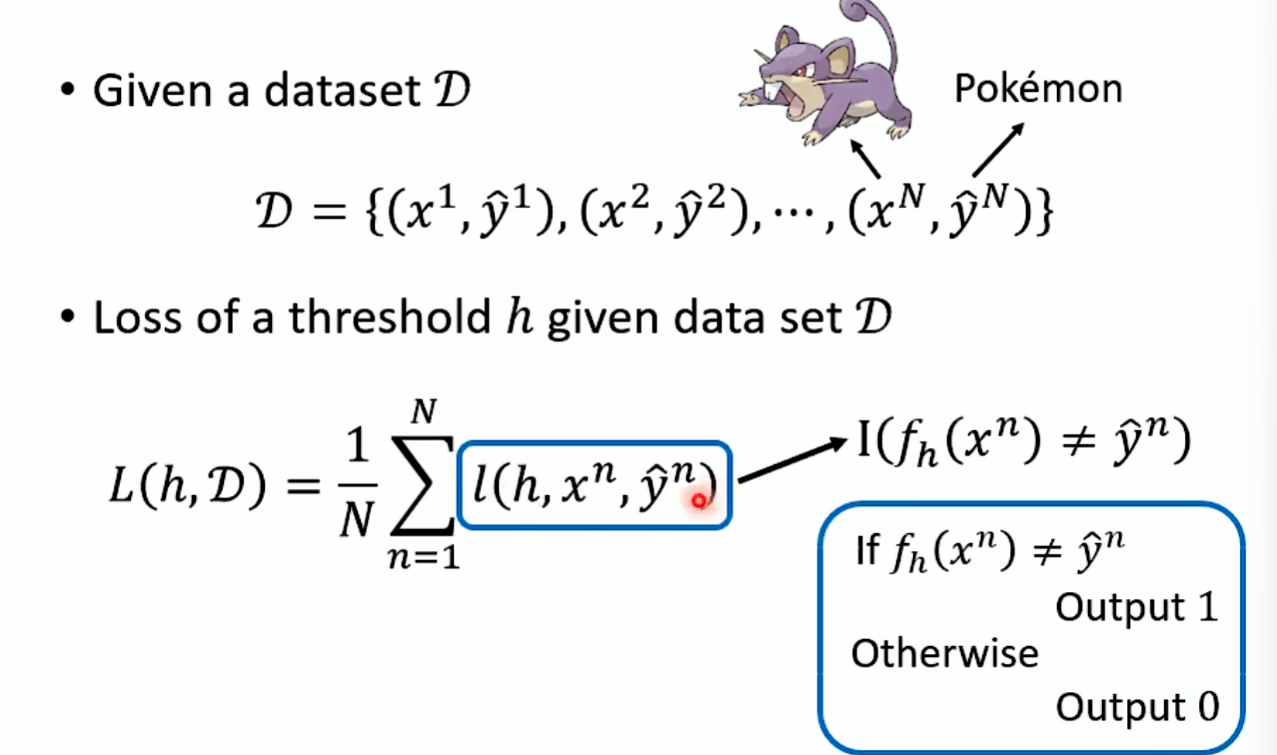
Training Examples:假设能找到世界上所有的宝可梦和数码宝贝进行测试,测试后H all=argminL(h,D all)求得了H all为理想状况。
但是实际上我们只有sample,D train要求iid(independently and identically distributed)独立同分布。求出了一个h要求值越小越好。![]() 。H all表示的是在这个数据集上测试的最佳结果,即理想值,他一定是最小的。那我们要找一个什么样的h?如下:我们需要找一个理想和现实接近的D train。
。H all表示的是在这个数据集上测试的最佳结果,即理想值,他一定是最小的。那我们要找一个什么样的h?如下:我们需要找一个理想和现实接近的D train。

那么找到一组好的训练资料的概率有多大呢?不好的训练资料意思是找不到任何一个h,让训练资料和全部资料的训练结果都很小。那么把每个h对应的坏的资料集用框圈起来,这个资料被那个h弄坏了,所有h的几率union起来,就是资料集是差的几率。
能不能算出某个 h会被他弄坏的某些D train出现及几率?如下所示: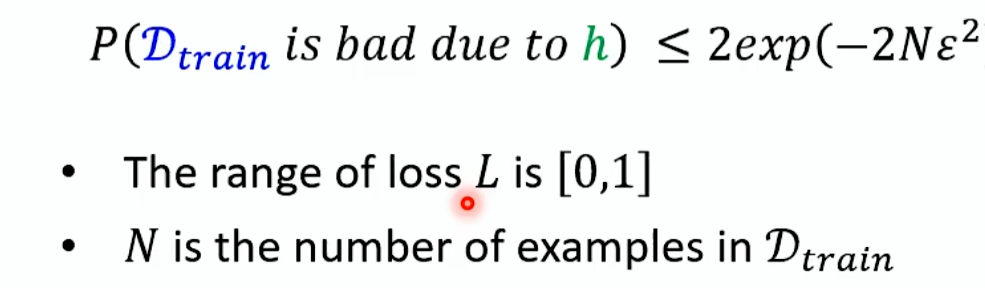
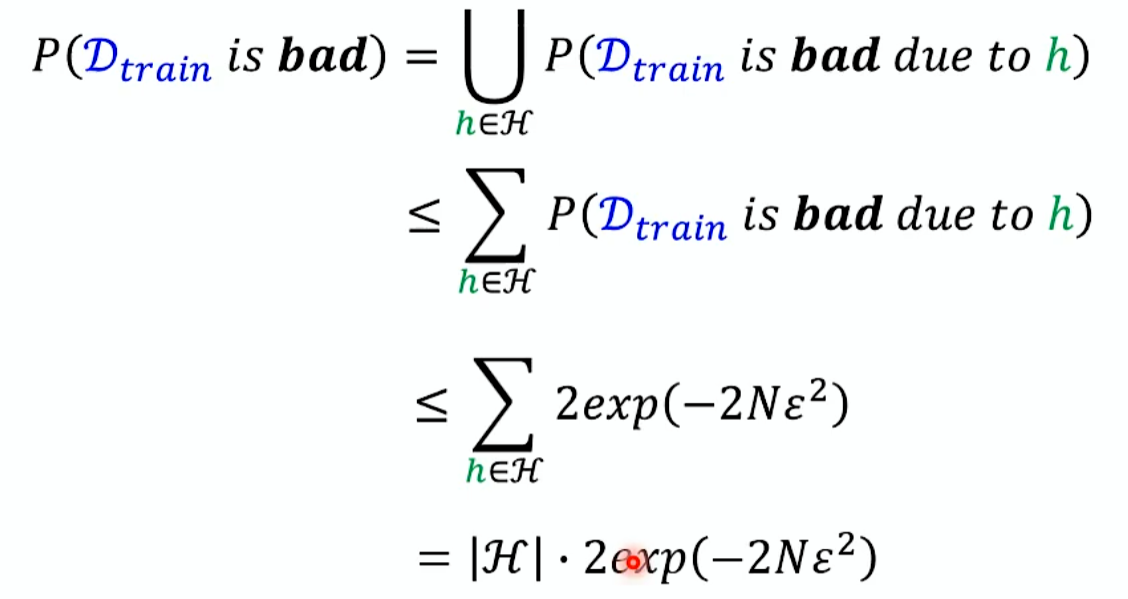
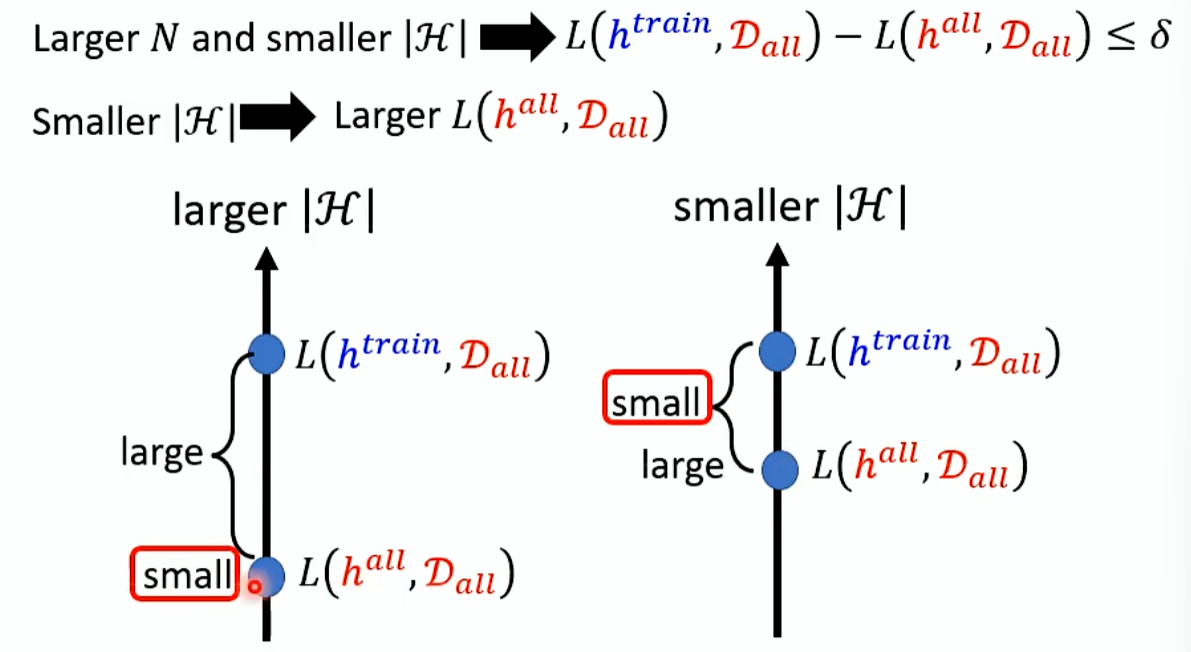
怎么让D train的几率更小的?
N要更大,|H|要更小。
|H|如果很小,理想会崩坏,理想和显示直接差距很大,很难拟合现实。