人与人最大的差距就是勇气和执行力,也是唯一的差距
—— 25.4.16
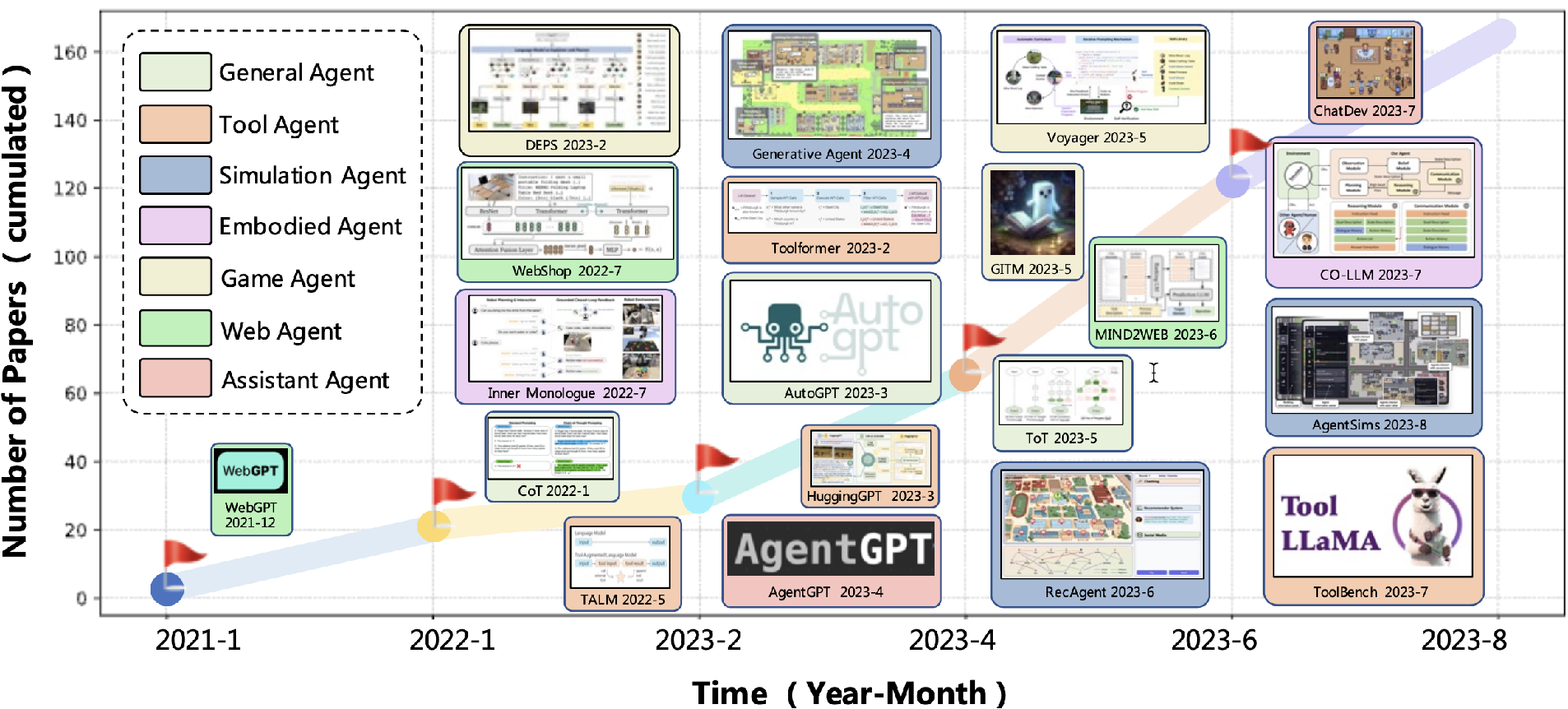
一、Agent 相关工作
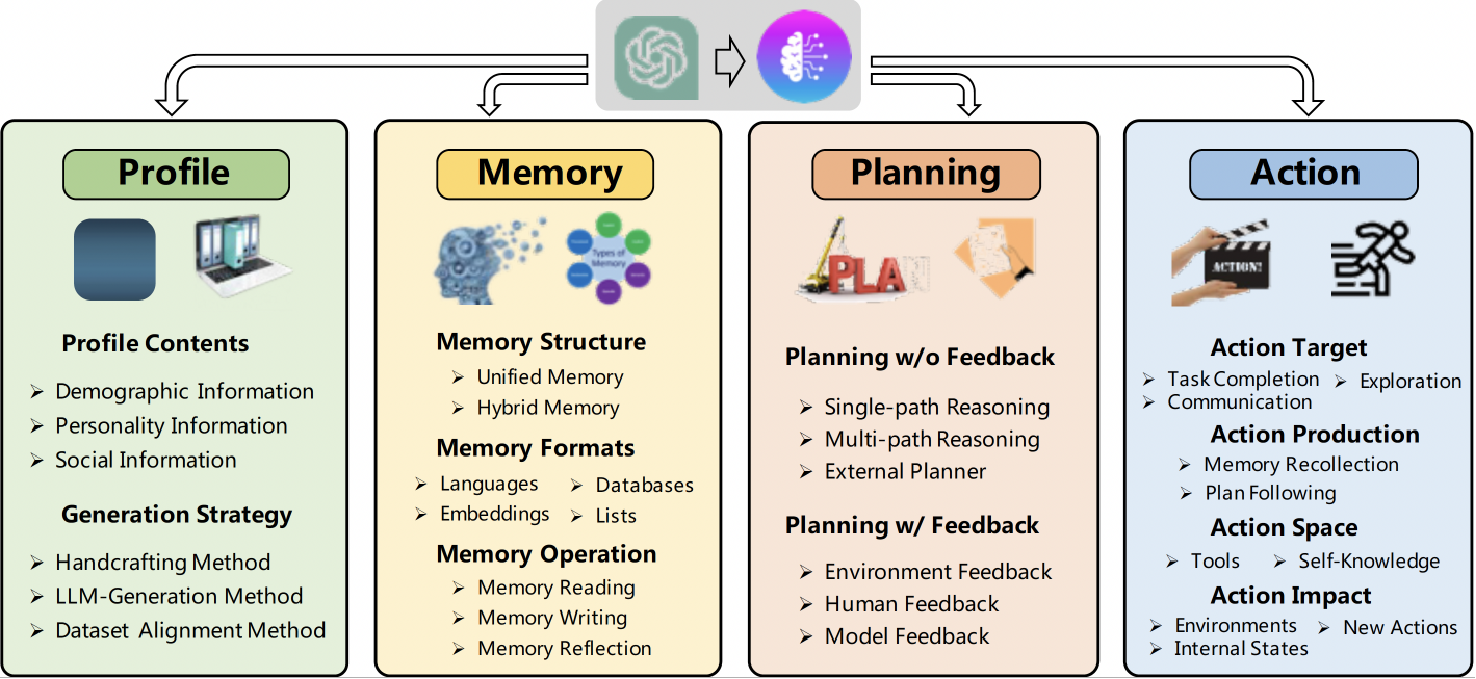
二、Agent 特点
核心特征:
1.专有场景(针对某个垂直领域)
2.保留记忆(以一个特定顺序做一些特定任务,记忆当前任务的前后信息)
3.任务规划(根据任务,制定计划,把大任务拆分为小任务,分为多步进行)
4.使用工具(查找本地知识库、调用API、执行代码、操作页面)
联网搜索的RAG也可以看作是一种Agent(由模型自己判断是否使用RAG可以看作是一种简单的规划)
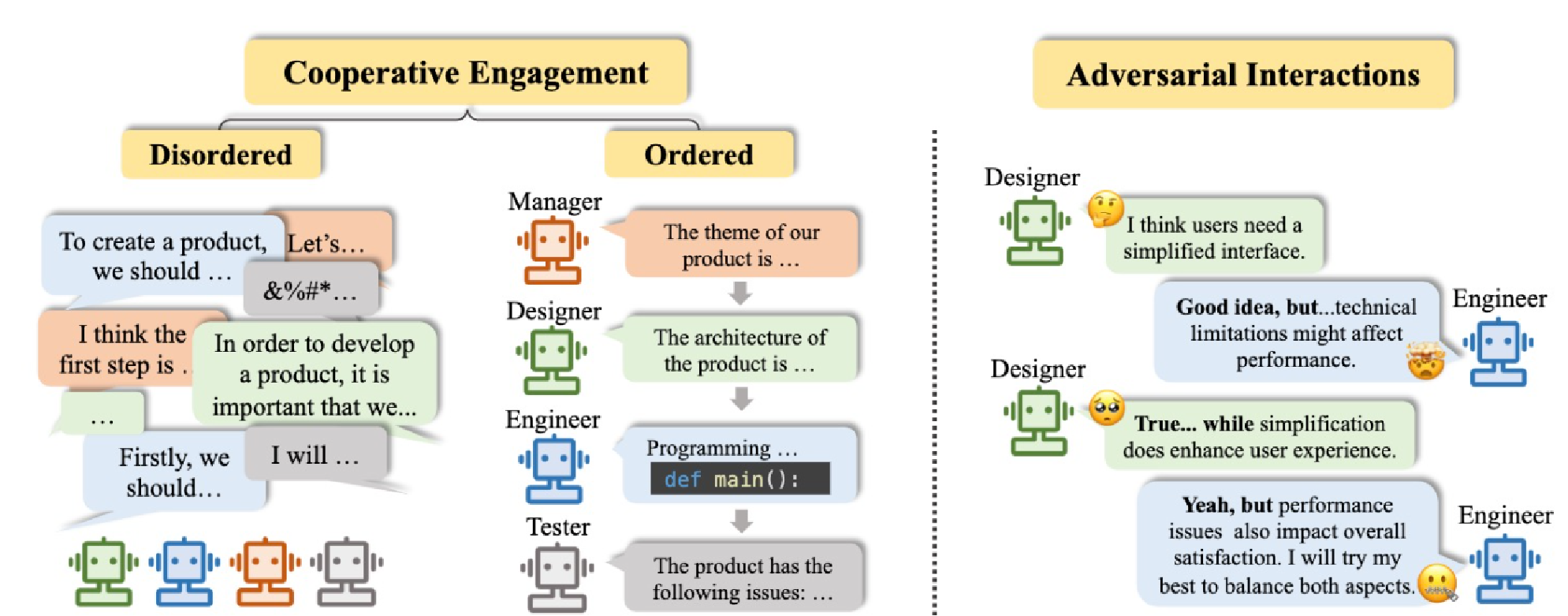
三、Agent之间协作
多个Agent之间互相合作/讨论,进行解决一个问题;可以有多个Agent,不同的Agent负责不同板块的功能,Agent之间合作的方式可以是串行的,也可以是并行的执行任务;不同的Agent可以是同一个大语言模型,只是传入他们的提示词不同
Agent还可以与人、环境进行交互
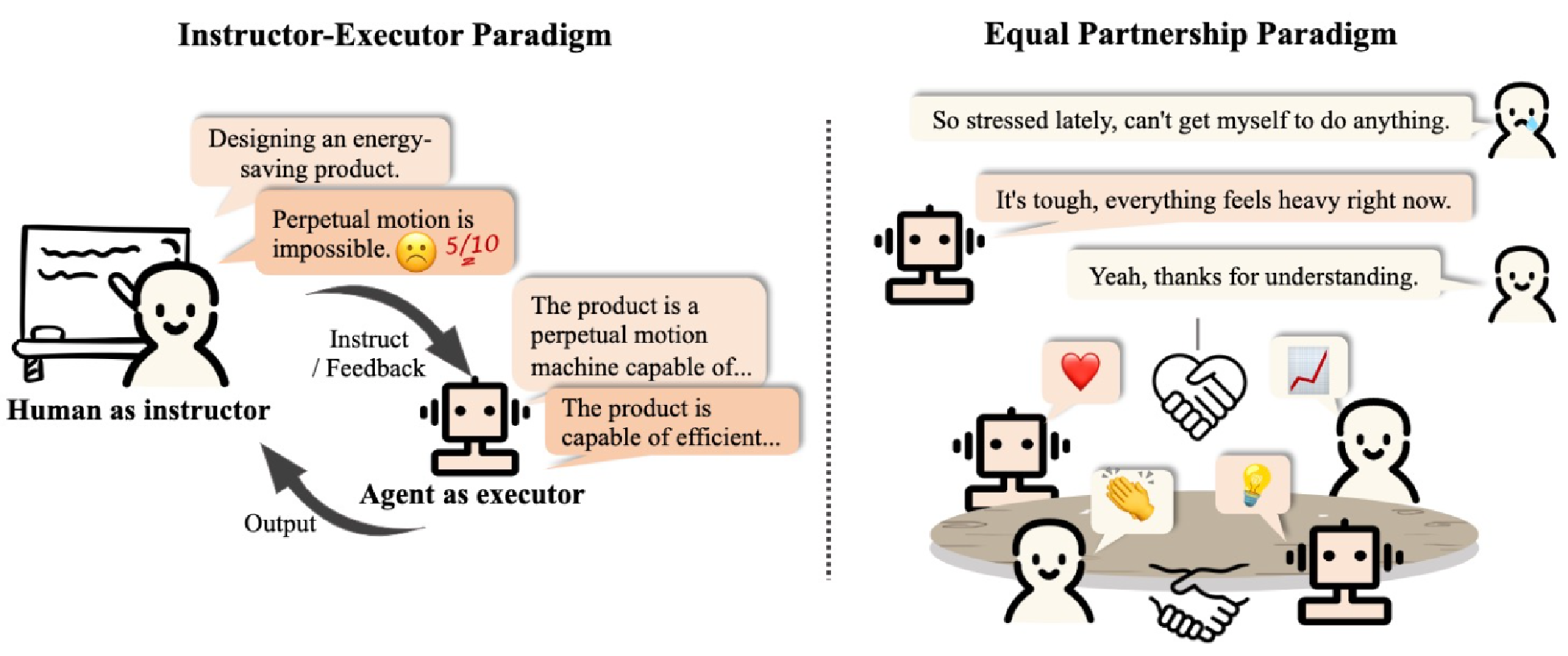
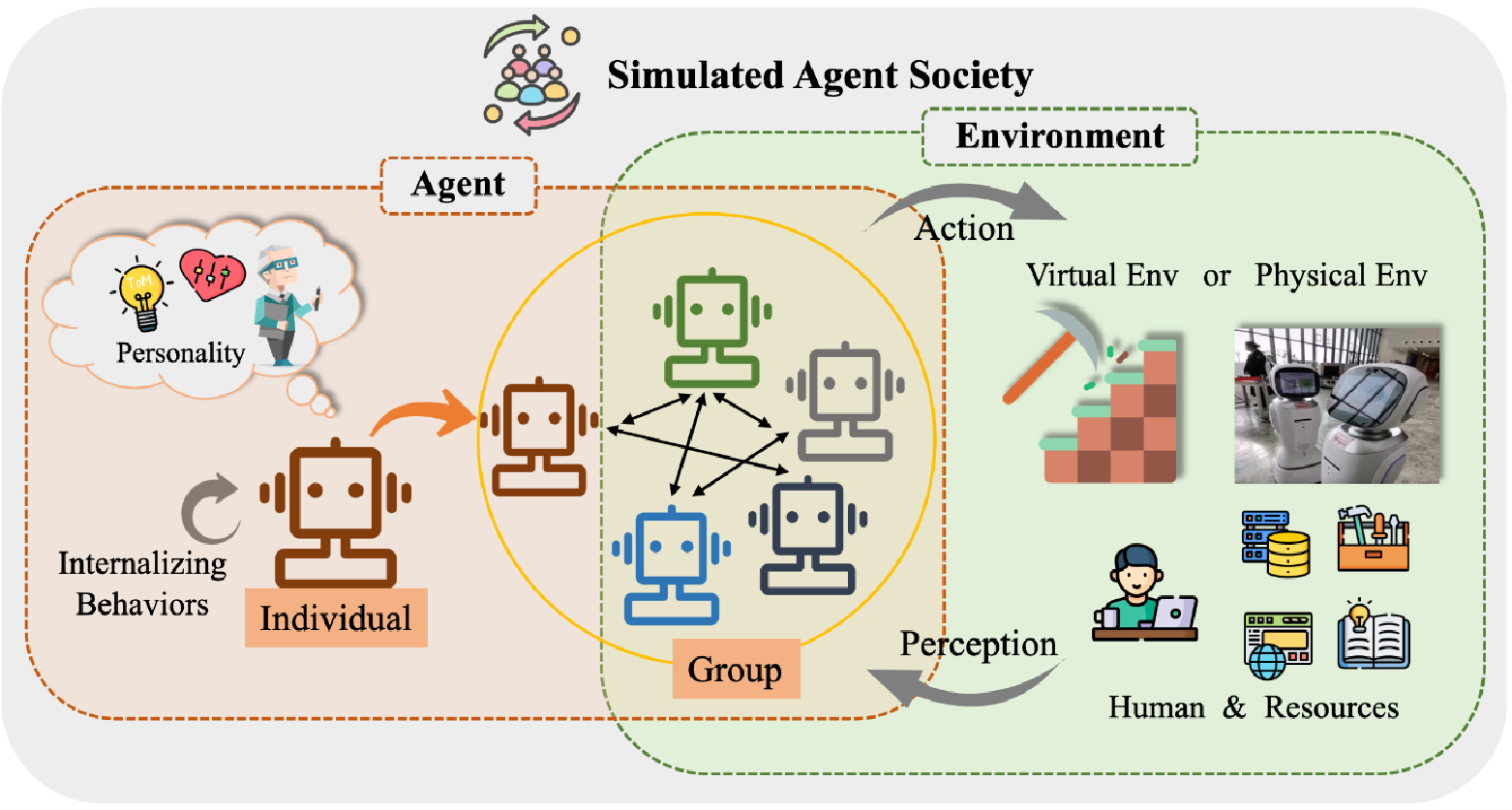
四、Agent应用示例
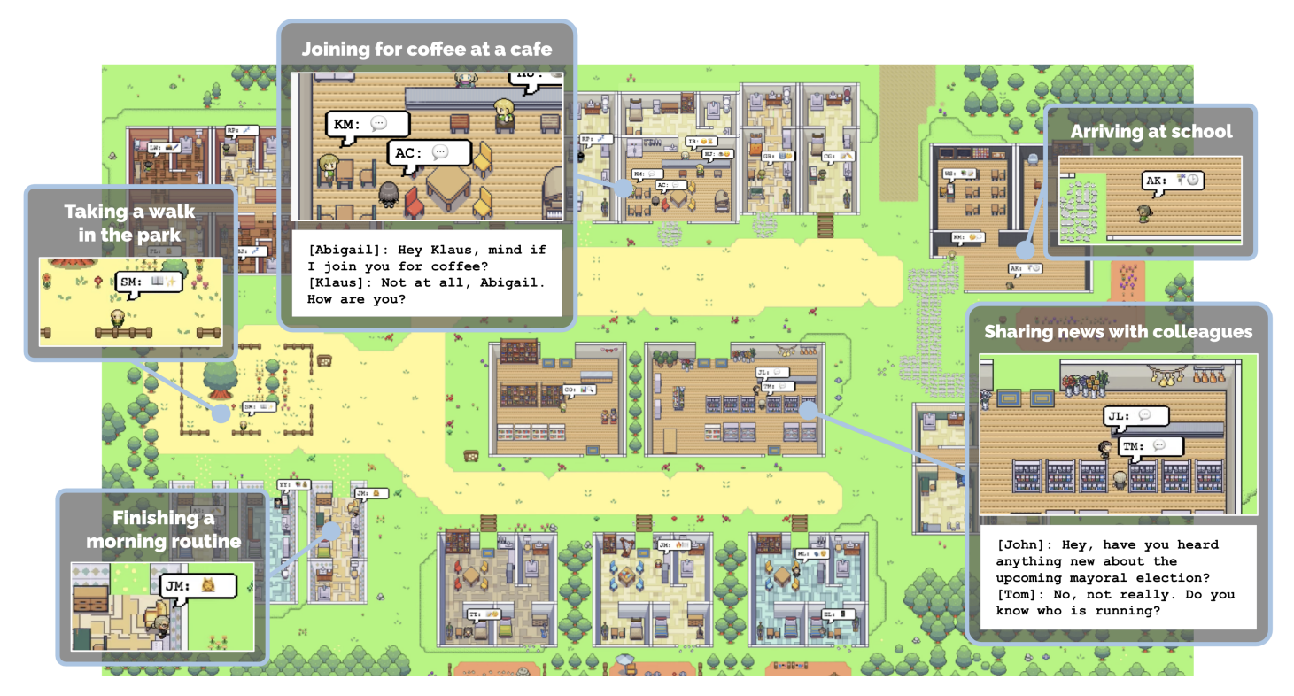
1.Agents模仿人类社群
核心设计理念:
用Agents模仿人类社群,设置一个虚拟场景,在场景中放置一些人物,以提示词的方式给人物一些背景设定;将这些所谓的虚拟人物扔在我们设置的这个虚拟场景中,让人物在这个虚拟场景内做一定的任务,不同的人物可以看作是不同的Agent,不同人物通过环境的改变,修改提示词,然后由大语言模型执行对应的动作
项目旨在借助生成式智能体技术,创造能模拟可信人类行为的计算智能体,构建虚拟人类社群。通过赋予智能体记忆、反思和计划能力,使其在虚拟环境中的互动和行为更接近真实人类,提升人工智能交互的真实感和沉浸感。
核心技术与方法:
智能体模型整合了记忆流、反思机制和计划生成功能。记忆流记录智能体经历,反思机制将短期记忆整理为长期记忆并形成见解,计划生成功能依据记忆和目标制定行动。大语言模型(LLMs)是智能体的决策和对话基础,通过特定提示工程,让智能体基于自身知识和记忆回答问题、规划行动。对智能体角色进行明确分工,不同角色专注特定领域任务,提升大模型输出质量;
2.AutoGPT:帮你在线完成任务
工作原理:
用户输入目标后,AutoGPT 将其分解为子任务,为每个子任务生成提示并执行。在执行过程中,不断根据结果反馈调整策略,直至完成目标。期间会利用自身的短期和长期记忆(借助向量数据库实现)来存储和调用信息,还可通过插件访问网络和其他应用获取实时数据 。
功能特性:
高度自主性:能根据设定目标自动规划执行步骤,在任务执行中动态调整行为,无需外部干预。例如设定 “制定一个一周的健身计划”,它可自主收集信息、规划每天的锻炼内容和时间安排。
任务分解与执行:将复杂任务拆解为多个子任务,逐个执行并根据反馈优化操作,以此处理多步骤复杂任务。如生成一份市场调研报告时,会依次完成确定调研主题、收集数据、分析数据、撰写报告等子任务 。
自我反馈优化:执行任务时评估当前结果,据此调整后续行动,逐步提升任务处理表现,使任务执行更高效准确。
多任务处理能力:支持同时处理多个独立任务,具备良好的上下文切换能力。比如同时进行文案创作和数据分析任务。
自然语言交互:支持自然语言输入,用户可用日常语言描述需求,它能理解并转化为操作指令。
外部交互拓展:可通过 API 与外部系统交互,获取数据、执行网络查询、调用其他应用等,拓展应用场景。例如访问互联网获取实时信息,调用绘图工具生成图表 。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
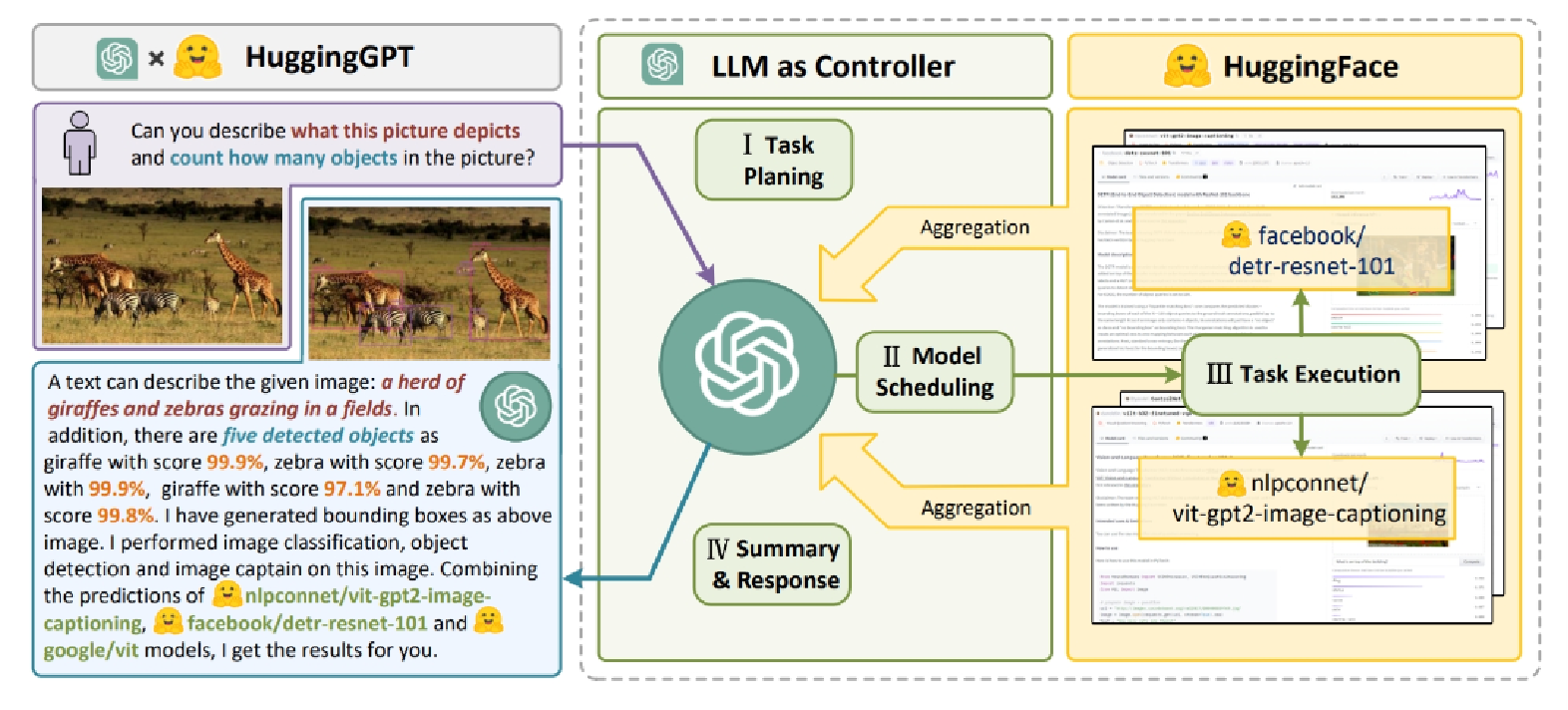
3.HuggingGPT:由agent根据任务决定去HuggingFace上使用哪个模型
工作原理:
利用大型语言模型(LLM)连接机器学习社区(如 HuggingFace)中各种 AI 模型,以解决复杂 AI 任务的系统。它以语言为通用接口,LLM 作为控制器,管理众多专家模型协同工作。
工作流程:
任务规划:接收到用户请求后,ChatGPT 等 LLM 解析请求,将其分解为多个子任务,并规划任务顺序和依赖关系。例如,若用户请求 “分析一张图片中不同物体,并生成一段描述”,ChatGPT 会将其分解为目标检测、图像描述等子任务,并确定目标检测需先执行,因为图像描述依赖检测出的物体信息。
模型选择:针对每个子任务,ChatGPT 根据 HuggingFace 中模型的功能描述,选择合适的专家模型。例如,在目标检测任务中,可能选择在该领域表现出色的 YOLO 系列模型。
任务执行:被选定的专家模型在推理端点上执行分配到的任务,完成后将执行信息和推理结果记录回 LLM。比如图像描述模型完成对图片的描述后,将结果反馈给 ChatGPT。
响应生成:ChatGPT 汇总执行过程日志和推理结果,整合成完整答案返回给用户。例如,将目标检测出的物体信息和图像描述结合,形成符合用户需求的回复。
项目地址:https://github.com/microsoft/JARVIS

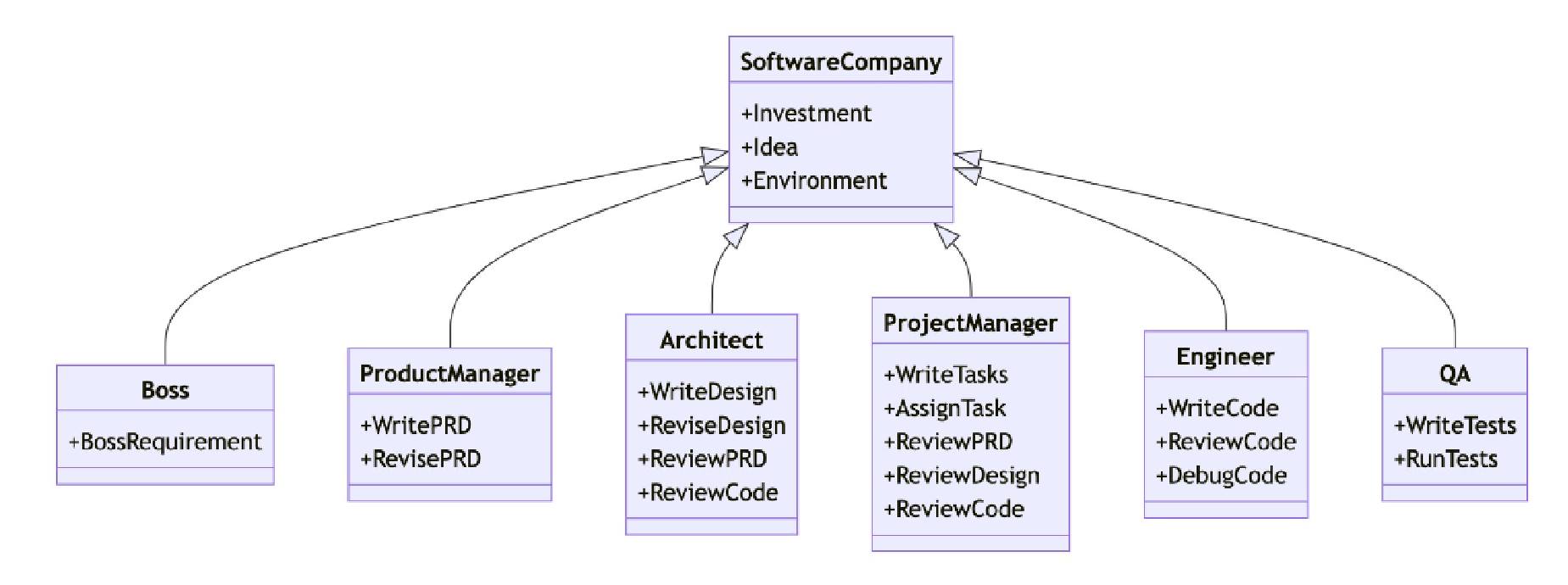
4.MetaGPT:多agent协作代码开发
核心技术与工作原理:
基于大语言模型(LLM)构建,模拟虚拟软件团队协作。框架包含产品经理、架构师、项目经理、工程师、质量工程师等多种角色智能体,每个智能体有各自的 LLM、观察、思考、行动和记忆能力。借助标准作业程序(SOP),智能体明确分工与协作流程,保障系统有序高效运作。例如,接到软件开发需求,产品经理智能体分析需求、撰写产品需求文档,架构师据此设计系统架构,工程师依架构编写代码 。
功能特点:
自然语言编程:允许用户用自然语言描述任务,降低编程门槛,非专业人员也能实现软件开发或数据处理。比如输入 “开发一个简单的待办事项管理小程序”,MetaGPT 能理解并生成相应代码。
多智能体协作:各智能体协同工作,依据 SOP 高效沟通,共同完成复杂任务,提高工作效率和准确性。在大型项目开发中,不同角色智能体各司其职,紧密配合。
数据解释器:可自动解析自然语言指令,生成代码或执行数据分析任务。用户输入 “分析销售数据并生成趋势图”,它能快速处理 。
项目地址:https://github.com/geekan/MetaGPT/tree/main
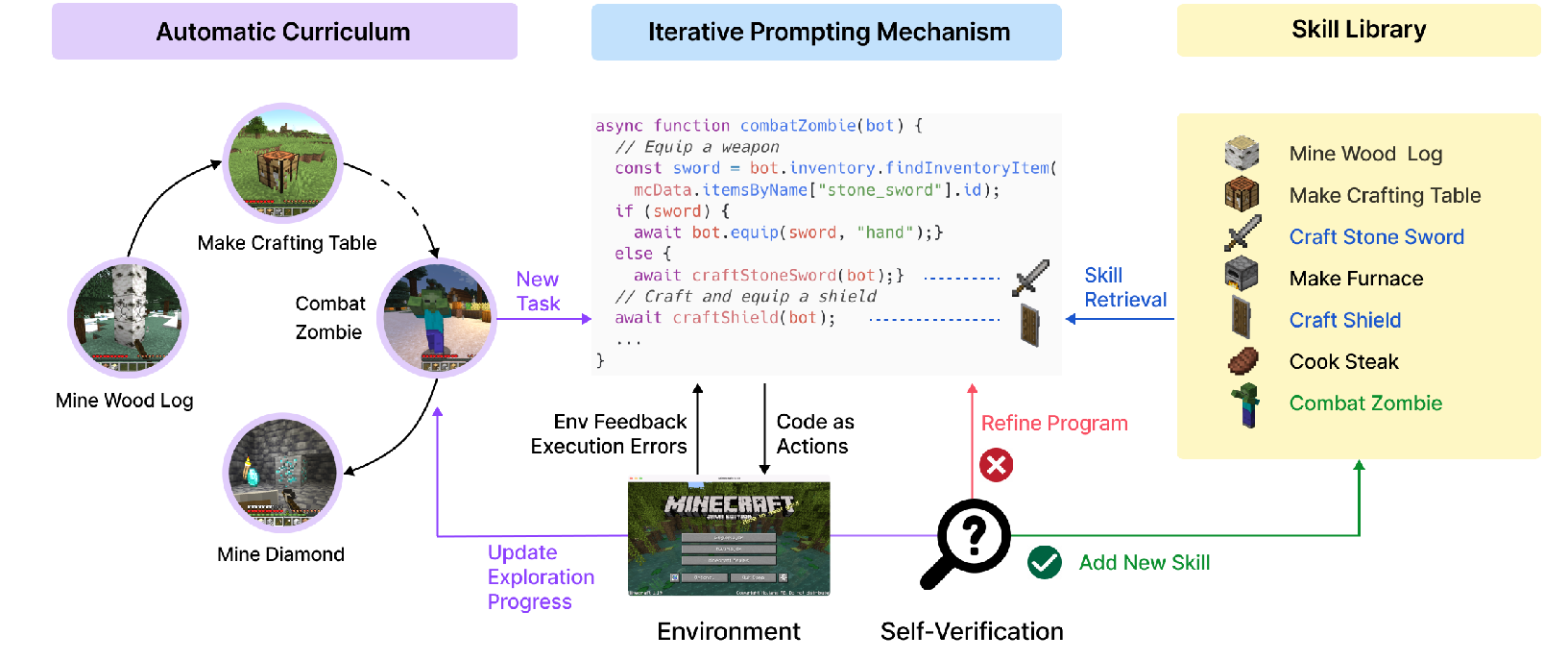
5.Voyager:用agent学习玩Minecraft游戏
核心技术与运行机制自动课程生成:
设定 “尽可能发现更多不同事物” 为总体目标,由 GPT-4 基于游戏进程和智能体状态生成自动课程。课程难度循序渐进,引导 Voyager 探索游戏世界。比如在游戏前期,会生成像 “收集木材”“建造简单房屋” 这类基础任务;随着游戏进展,任务会逐渐变为 “开采钻石”“建造红石机关” 等更具挑战性的内容。
技能库构建与检索:
Voyager 使用流行的 Javascript Minecraft 操作库(Mineflayer),让 GPT-4 根据任务需求生成游戏操作代码,如 “combatZombie”(对抗僵尸)。每次 GPT-4 生成并验证新技能代码后,先用 GPT-3.5 为代码生成详细注释,再将注释做 Embedding 保存到向量数据库 Chroma 中,形成不断增长的技能库。当接到新任务时,先由 GPT-3.5 根据游戏环境给出任务操作说明,再将其做 Embedding 去技能库检索前 5 个最匹配的操作代码,最后由 GPT-4 决定是调用已有代码还是编写新代码,以尽可能重用已有技能。
迭代提示机制:
执行生成的程序后,从游戏模拟中获取观察结果(如玩家的生命值、饥饿值、物品库存、周围环境信息等)和代码执行错误信息;将这些反馈合并到 GPT-4 的提示中,进行新一轮代码优化;不断重复该过程,直到自我验证模块确认任务完成,此时将程序提交到技能库。比如在尝试制作钻石镐时,若代码执行提示 “缺少钻石材料”,则反馈给 GPT-4,让其调整代码,先去获取钻石。
项目地址:https://github.com/MineDojo/Voyager/tree/main
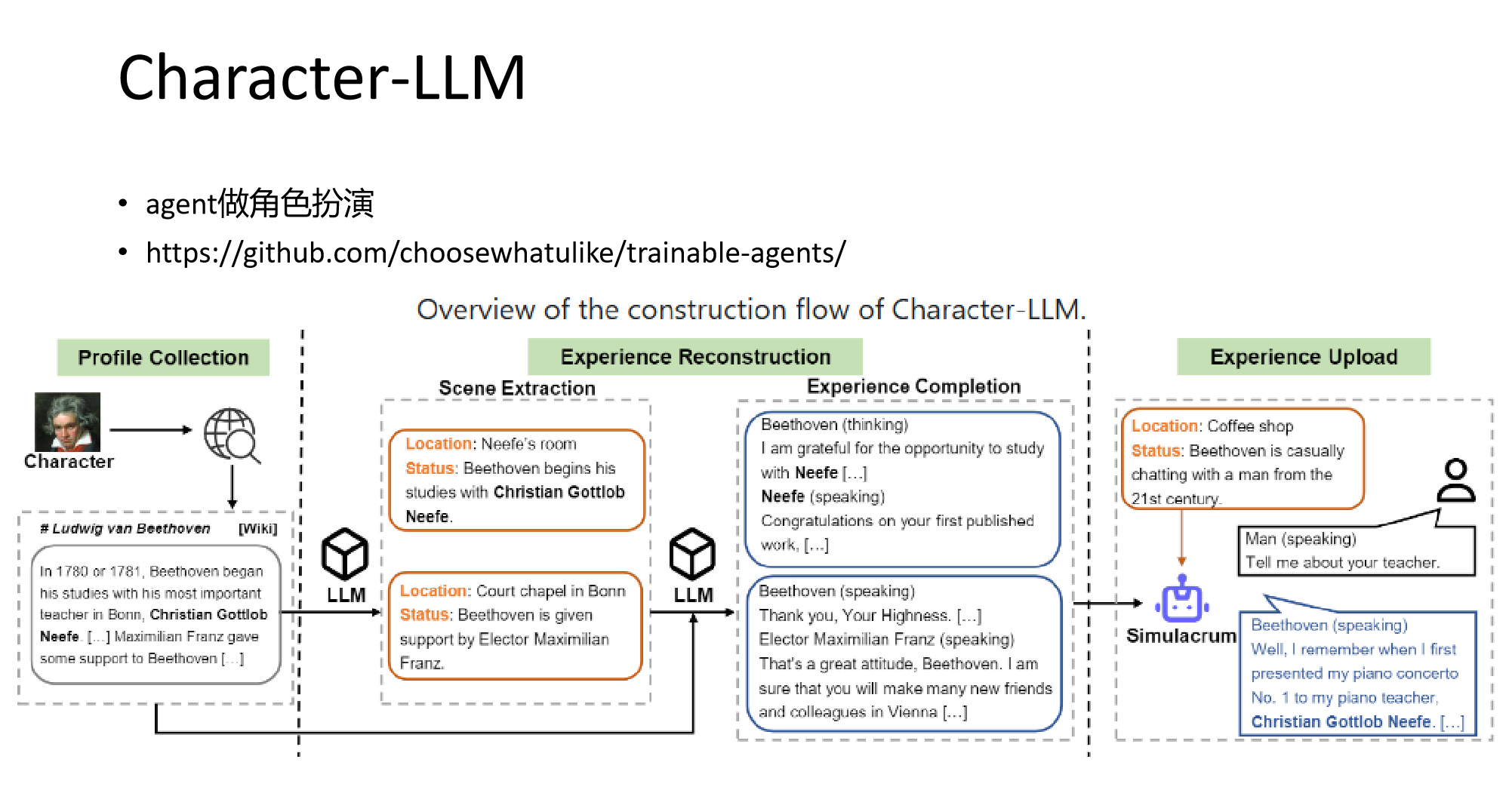
6.Character-LLM agent做角色扮演
可训练角色扮演 Agent:区别于普通提示驱动的代理,Character-LLM 通过训练学习特定角色的经历、特征和情感,能以特定人物(如贝多芬、凯撒等)的身份进行对话,无需额外提示或参考文档。
经验重建数据生成:提出经验重建(Experience Reconstruction)方法,生成详细多样的角色经验数据用于训练,涵盖角色生活场景、对话等内容,让模型学习角色的行为模式和知识体系。
项目地址:https://github.com/choosewhatulike/trainable-agents/
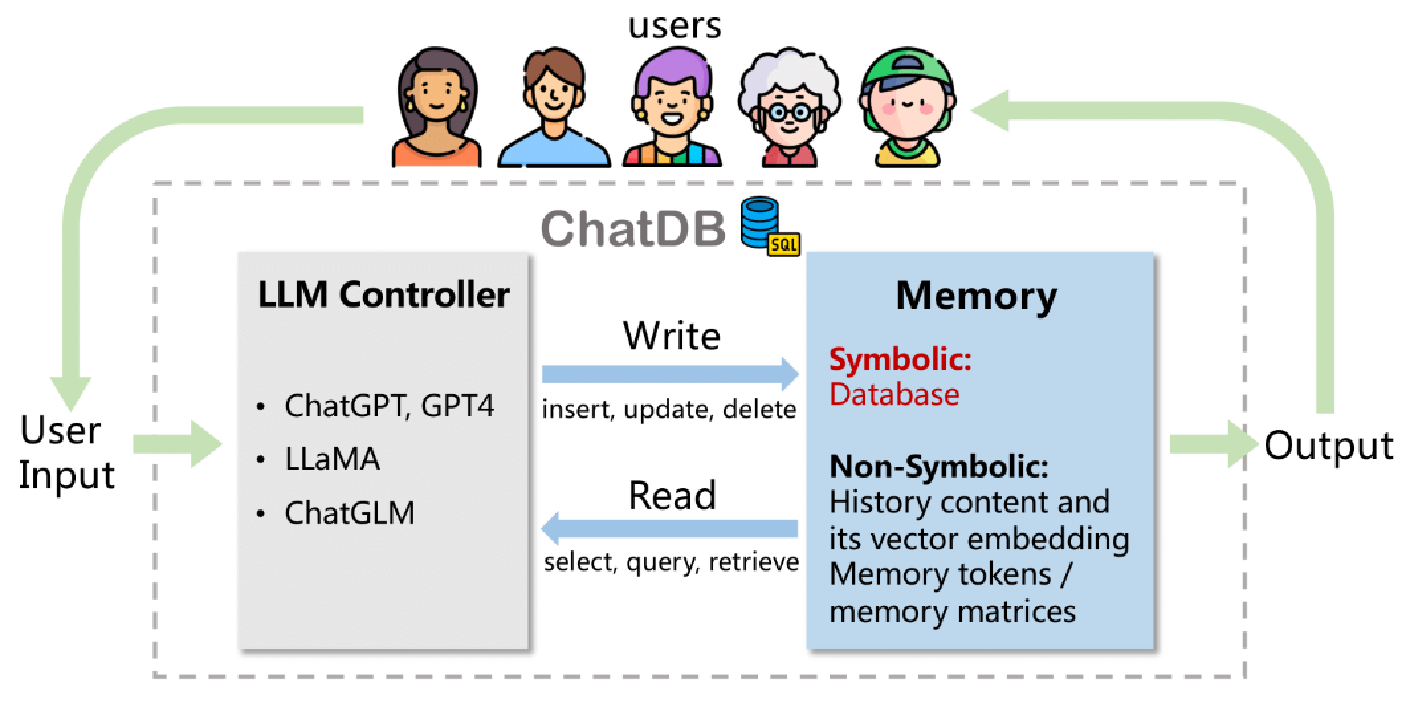
7.ChatDB Agent与数据库交互
项目地址:https://github.com/huchenxucs/ChatDB
Character-LLM 是一个利用大语言模型(LLM)实现人类行为模拟的角色扮演项目,其核心在于让 AI 模型基于人的记忆、反思和行动来扮演角色,在研究和应用领域有独特价值。
项目核心思想与目标:
受到斯坦福小镇的启发,该项目旨在解决简单的 LLM API 提示词无法满足涉及人类深层次思考和体验的问题。它通过构建一套架构,让 AI 模型模拟人类体验时间、感受情感并记住与他人的互动,以此训练角色代理(agent),进而实现更真实、深入的角色扮演。
项目实现流程
profile 收集:主要从维基百科等渠道收集人物资料,梳理出人物在特定时间段内发生的事件,为后续的角色塑造提供基础信息。例如收集贝多芬的生平事迹,包括他师从哪些老师、何时发表第一部作品等。
场景提取:从给定的经验描述中抽取多样化、高质量的场景,涵盖聊天、辩论、讨论、演讲等类型。场景描述简洁且注重背景,像描述贝多芬与老师学习音乐的场景,会突出时间、地点和人物关系,略去细节 。
对话抽取:结合人物背景信息和提取的场景,借助大模型模拟编剧的角色,生成丰富的对话内容。在生成对话时,要求模型忠实于人物的愿望和要求,充分考虑角色的情感和思维能力,想象角色在特定场景下的言行。比如模拟贝多芬在获得资助时与资助者的对话。
保护性经验生成:为减少角色的幻觉现象,当遇到超出角色能力范围的问题时,模型学会表示缺乏相关知识。通过这种方式,让角色在面对特定问题时的表现更符合设定,避免出现不符合角色设定的回答。