美团推荐算法
一、为什么分类模型不适合用 MSE(均方误差)
1.1. 根据设计目标来看:概率分布 vs 数值距离
分类任务的目标是预测类别(如 0, 1, 2…),输出为概率分布,更关心的是预测概率是否集中在正确类别上。而交叉熵能更有效地衡量预测分布与真实分布(one-hot)的差异。
MSE(Mean Squared Error)适用于预测连续值(如温度、房价等)。模型的输出目标就是实际的温度、房价值。MSE 惩罚的是预测值和目标值之间的数值差距,而不是概率分布。
分类任务的目标是预测类别(如 0, 1, 2…),输出为概率分布
1.2. 梯度问题 & 收敛慢
- 二分类中若使用 sigmoid 输出,MSE 的梯度在靠近真实标签时会非常小,导致:梯度消失和网络训练变慢
- 交叉熵损失(Cross-Entropy)具有更稳定且更大的梯度,训练效率高,收敛更快。
我们以一个简单的二分类问题为例:
- 真实标签(采用 one-hot 编码):
y = [1, 0] - 模型预测输出(经过 softmax):
ŷ = [0.99, 0.01] - 损失函数:均方误差(MSE)
MSE 的计算公式为:MSE = (1/n) * Σ (ŷᵢ - yᵢ)²
带入:MSE = (1/2) * ((0.99 - 1)² + (0.01 - 0)²) = (1/2) * (0.0001 + 0.0001) = 0.0001
对预测输出的梯度公式为:∂MSE/∂ŷ = 2 * (ŷ - y) / n
带入:∂MSE/∂ŷ = (2/2) * ([0.99, 0.01] - [1, 0]) = [−0.01, 0.01]
梯度:[−0.01, 0.01] 非常接近 0,意味着模型权重更新非常缓慢。MSE 给出的梯度过小,导致学习变慢,甚至陷入停滞(即“梯度消失”)。 - 损失函数:交叉熵损失(Cross Entropy)
梯度公式:∂L/∂z = ŷ - y
∂L/∂z = [0.99, 0.01] - [1, 0] = [−0.01, 0.01]
二、在某些特征的场景和特定评估指标下行使用mse也有可能成立。
例如:
- Label 是整数(1~5),表示主观评分(如美学评分、满意度、打分等级)
- 评估指标是 MSE:说明你关心的是“预测值和实际评分之间的数值距离”
- 虽然 Label 离散,但本质上是有序的、连续感很强
2.1. 所以可以使用 MSE,前提是满足以下条件:
| 条件 | 是否满足 | 说明 |
|---|---|---|
| 标签有序 | ✅ | 比如 5 > 4 > 3,这是一种序等级 |
| 标签可被看作“数值” | ✅ | 预测 3.8 比预测 2.1 更接近标签 4 |
| 评估指标是回归型的(如 MSE、MAE) | ✅ | 不要求准确预测某个具体整数,而是越接近越好 |
- 把问题当作回归处理:
- 模型最后一层不使用 softmax,而是直接输出一个实数(通常用
ReLU或Sigmoid + 缩放保证范围) - 损失函数直接使用
MSELoss
- 模型最后一层不使用 softmax,而是直接输出一个实数(通常用
- 训练目标是尽量逼近真实评分值
- 预测结果可以是小数,比如 3.75、4.12 等
三、介绍一下soft label
Soft Label(软标签) 是一种标签表示方法,区别于传统的 Hard Label(硬标签),它使用一个概率分布来表示标签,而不是仅仅一个明确的类别。Soft Label 使得模型不仅关注某个类别的正确性,还能反映类别之间的模糊性和相似性。
3.1. Soft Label 的应用场景
3.1.1. 知识蒸馏(Knowledge Distillation)
- 使用教师模型的输出作为软标签,指导学生模型学习。教师模型的概率输出包含了更多关于类之间关系的信息,学生模型通过模仿这些概率输出来提高性能。
3.1.2. 马赛克数据增强(Mosaic Augmentation)
马赛克数据增强是一种在训练过程中使用的图像数据增强技术,特别用于 目标检测任务。它通过将多张不同的图像拼接在一起,创建出一个包含多个目标的新图像,从而增强模型的鲁棒性。它通常用于 YOLO系列 的模型中,目的是通过改变目标的布局和位置,提高模型的泛化能力。
在使用马赛克增强时,通常会将来自不同图像的多个目标组合到一起。这种数据增强会对目标的标签产生一定的影响:
- 原标签:每个目标原本都有明确的边界框和类标签。
- 拼接后标签:多个目标拼接在一起后,每个目标的类别和边界框信息依然需要保留,但有时这些目标会部分或完全重叠。因此,原本单一的标签变成了一个更复杂的标签结构,可能需要处理不确定性。此时 Soft Label 可以为该区域提供 多个类别的概率分布,而不是单一类别标签。
3.1.3. 标签不确定性
- 在标注不确定的任务中,如医疗诊断、情绪分析等,标签通常不能简单地用硬标签表示。软标签可以更好地反映标注者的模糊判断。
- 例如,多位医生对一个病例的诊断意见可能有所不同,软标签可以反映不同医生之间的意见分歧。
3.1.4. 类别相关性
- 在某些任务中,类别之间可能有相似性,例如在图像分类中,狗和狼是相似的,软标签可以表示这些相似性。
- 通过软标签,模型能够更好地理解类别间的关系,而不是仅仅“看作”完全不同的类别。
3.2. Soft Label 和 Label Smoothing 的区别
| 特点 | Soft Label | Label Smoothing |
|---|---|---|
| 来源 | 真实的不确定性或教师模型的输出 | 人为添加的扰动,通常用于避免过拟合 |
| 目的 | 更好表示类别间的模糊性与相似性 | 防止模型过于自信,减少过拟合 |
| 示例 | [0.1, 0.8, 0.1] 表示样本更可能属于类别 2 | 将 One-hot 标签修改为 [0.9, 0.1, 0.0] |
如何使用 Soft Label
标签平滑与交叉熵损失函数(Cross-Entropy Loss)
- 在使用 Soft Label 时,通常需要使用 KL 散度 或 交叉熵损失(Cross-Entropy Loss),而不是普通的
CrossEntropyLoss,因为后者通常要求硬标签。 - Soft Label 和硬标签的关键差别在于,Soft Label 允许类别之间有一个不确定性的分布,而硬标签则是明确指定一个类别。
- 在使用 Soft Label 时,通常需要使用 KL 散度 或 交叉熵损失(Cross-Entropy Loss),而不是普通的
应用损失函数:
KLDivLoss:可以用于计算 Soft Label 和模型输出的差异。CrossEntropyLoss:可以通过调整输入标签为软标签形式来使用。
四、为什么交叉熵能处理 Soft Label,为啥还要使用 KL 散度?
交叉熵(Cross-Entropy)和 KL 散度(Kullback-Leibler Divergence)都能在某些情况下处理 Soft Label,但它们的侧重点和应用场景有所不同。理解它们的区别和各自的优点,可以帮助我们更好地选择何时使用哪种方法。
4.1. 交叉熵与软标签
交叉熵损失本质上是在计算模型的预测概率分布与真实标签(soft label)之间的差异。对于分类任务,交叉熵 计算了模型预测的概率分布和目标分布之间的相似性,最小化交叉熵意味着模型将其预测值逼近真实分布。
公式:
CrossEntropy ( y , y ^ ) = − ∑ i y i ⋅ log ( y ^ i ) \text{CrossEntropy}(y, \hat{y}) = - \sum_i y_i \cdot \log(\hat{y}_i) CrossEntropy(y,y^)=−i∑yi⋅log(y^i)
其中:
- y i y_i yi 是 soft label 中第 i i i 类的概率。
- y ^ i \hat{y}_i y^i 是模型预测的第 i i i 类的概率。
交叉熵适用场景
- 直接优化分类任务:当我们需要一个损失函数来指导模型优化其预测结果时,交叉熵是一个常用选择。
- 常见的分类任务:无论是硬标签还是软标签,交叉熵都能够有效地处理。
4.2. KL 散度(Kullback-Leibler Divergence)
KL 散度 是一个衡量两个概率分布之间差异的指标,它不仅用于衡量模型的预测和实际标签之间的差异,还能够量化这两个分布的"相似性"。KL 散度通常用于训练模型时,尤其是在 知识蒸馏(Knowledge Distillation) 或其他需要衡量模型输出分布与目标分布之间差异的场景中。
公式:
D K L ( P ∣ ∣ Q ) = ∑ i P ( i ) ⋅ log ( P ( i ) Q ( i ) ) D_{KL}(P || Q) = \sum_i P(i) \cdot \log\left(\frac{P(i)}{Q(i)}\right) DKL(P∣∣Q)=i∑P(i)⋅log(Q(i)P(i))
其中:
- P ( i ) P(i) P(i) 是目标分布(例如软标签的真实概率)。
- Q ( i ) Q(i) Q(i) 是模型的预测概率分布。
KL 散度适用场景
- 知识蒸馏:
- 在知识蒸馏中,通常使用教师模型的输出概率(软标签)作为学生模型学习的目标。KL 散度可以用来度量学生模型的预测概率与教师模型的输出概率之间的差异。
- 度量两个分布的差异:
- KL 散度的另一个重要特点是它是 不对称的,即 D K L ( P ∣ ∣ Q ) ≠ D K L ( Q ∣ ∣ P ) D_{KL}(P || Q) \neq D_{KL}(Q || P) DKL(P∣∣Q)=DKL(Q∣∣P),因此它可以在一些任务中更好地反映 目标分布和预测分布 的方向性差异。
4.3. 交叉熵与 KL 散度的关系
实际上,交叉熵和 KL 散度有密切的联系。交叉熵损失可以被视为包含了 KL 散度的特殊情况。具体来说,当我们使用交叉熵损失时,可以将其重写为:
CrossEntropy ( y , y ^ ) = H ( y ) + D K L ( y ∣ ∣ y ^ ) \text{CrossEntropy}(y, \hat{y}) = H(y) + D_{KL}(y || \hat{y}) CrossEntropy(y,y^)=H(y)+DKL(y∣∣y^)
其中 H ( y ) H(y) H(y) 是目标分布 y y y 的 熵,它是一个固定的常数(因为它只依赖于真实标签), D K L ( y ∣ ∣ y ^ ) D_{KL}(y || \hat{y}) DKL(y∣∣y^) 则是衡量模型预测分布 y ^ \hat{y} y^ 与真实标签分布 y y y 之间差异的 KL 散度。
五、102. 二叉树的层序遍历
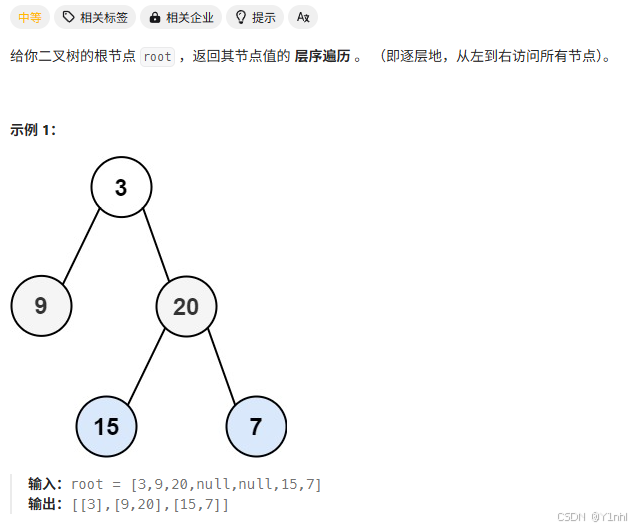
- 思路:使用一个队列保存每一层的元素。
- 代码:
class Solution:
def levelOrder(self, root):
if not root:
return []
res = []
queue = collections.deque()
queue.append(root)
while queue:
tmp_res = []
for _ in range(len(queue)):
node = queue.popleft()
tmp_res.append(node.val)
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
res.append(tmp_res)
return res