目录

并查集是什么
其实,并查集就是一个或者多个集合的一个总称
举一个例子,我们现在在学校中参加了一个活动,而活动的现场有很多同学,那么其中一部分是你认识的,另外的都是你不认识的,这样你就会优先选择和自己认识的人组成一个圈子
这样的事情对别人来说同样如此,所以到最后,就会形成一个一个的小圈子,这里所有的圈子,就叫做并查集,图示如下:
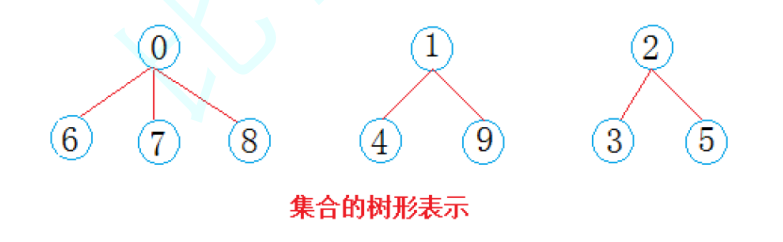
但是树是并不真实存在的,这只是一个抽象的表示,其底层还得是 vector,所以我们就可以这样子来表示
如果这个位置的节点不是根的话,那么我们就记录他的父节点的下标,这样就能循环遍历找到根节点
而我们最开始的vector里面全是 -1,当一个节点有一个子节点,那么根节点就会加上子节点的值,代表的是这个根节点的下面有多少个子节点
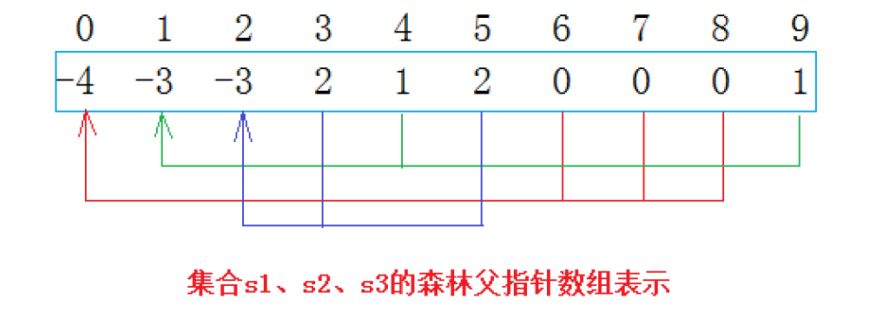
我们可以看到,其中有三个三个节点是负数1,这代表他们下面的节点数量(绝对值)
而其他的都是正数,代表的是,他们的父节点是多少,当然如果是路劲压缩的话,那么下面存的可能就直接是根节点,这是后话了,我们会在下面讲
代码实现
并查集的代码实现,十分简单,真的!!
首先是成员,他只有一个vector作为成员
接着就是主要的函数了:
- 构造函数,全部初始化为 -1 即可
- 找根节点的函数,用一个循环,只要我们找到了一个树小于 0,那么这个位置就是根节点,由于我们每一个元素下面存的都是父节点的下标,所以一个while循环就行了
- 两个根结合的函数,因为我们的朋友圈是会变化的,就好比我们可能会认识新的朋友,所以我们的并查集也要发生相应的结合,而我们的做法其实非常简单,就是找到两个不同集合的根节点,接着我们直接让其中一个根作为另一个根的孩子即可,这样的意义在于,我们将这两个集合变成了一个,他们的根节点就都是一样的了
代码如下:
class UnionFindSet
{
public:
UnionFindSet(int n)
{
_ufs.resize(n, -1);
}
int FindRoot(int x)
{
int root = x;
while (root >= 0)
root = _ufs[root];
// 路径压缩
while (_ufs[x] >= 0)
{
int parent = _ufs[x];
_ufs[x] = root;
x = parent;
}
return root;
}
void Union(int x1, int x2)
{
int root1 = FindRoot(x1);
int root2 = FindRoot(x2);
if (root1 == root2) return;
if (abs(_ufs[root1]) < abs(_ufs[root2]))
swap(root1, root2);
_ufs[root1] += _ufs[root2];
_ufs[root2] = root1;
}
bool InSet(int x1, int x2)
{
return _ufs[x1] == _ufs[x2];
}
size_t SetSize()
{
size_t size = 0;
for (size_t i = 0; i < _ufs.size(); ++i)
if (_ufs[i] < 0) size++;
return size;
}
private:
vector<int> _ufs;
};如果函数中有看不懂的部分,可以看看最后一个部分,也就是路径压缩
最后我们来讲一下,SetSize 和 InSet 函数
第一个就是看我们有几个集合,由于我们的根节点的数量就是集合的数量,而我们的根节点又都是负数,因为其绝对值代表的就是节点数量,所以我们直接遍历一遍数组,只要是负数就代表遍历到了一个集合,计数器加加即可
第二个是判断两个位置是否在同一个集合里面,我们直接找到根节点,根节点一样就代表在一个集合里
路径压缩
最后我们来讲讲路径压缩
为什么会出现这个东西呢,原因是,如果我们的数据量特别大,那么我们最后会结合的集合会非常多,我们要找的话只能一个一个往上找,集合的次数越多,我们要找的次数就越多,才能找得到根节点
这时候,路径压缩就来了,我们在找根节点的时候,和联合两个集合的时候都可以
首先是找根节点,首先我们需要先把根节点找到,接着我们每找到一个节点,我们就将这个节点的父节点设为根节点,这样做的正确点就是,根节点已经是所有节点的数量了,所以我们不需要担心这个,然后我们在后续找根节点的时候,我们就不用一个一个往上找了,直接就找到了,不管多少节点,我们都能一次找到
int FindRoot(int x)
{
int root = x;
while (root >= 0)
root = _ufs[root];
// 路径压缩
while (_ufs[x] >= 0)
{
int parent = _ufs[x];
_ufs[x] = root;
x = parent;
}
return root;
}接着就是联合两个节点的时候
其实这也不算路径压缩,就是一个小优化,当我们找到根节点的时候,我们并不知道哪个根节点的孩子数量多,如果直接相连的话,那我们可能会将100个孩子的集合作为5个孩子的集合
所以我们比较一下就好了,让数量少的做多的的孩子
结语
这篇文章到这里就结束啦!!~( ̄▽ ̄)~*
如果觉得对你有帮助的,可以多多关注一下喔