概述
自2023年在线广告行业估计花费了7403亿美元以来,很容易理解为什么广告公司会投入大量资源进行这一特定领域的计算机视觉研究。
尽管这个行业通常较为封闭和保守,但偶尔也会在arxiv等公共存储库中发布一些研究,这些研究暗示了更先进的专有工作,涉及面部和眼神识别——包括年龄识别,这是人口统计分析的核心内容:

这些研究很少出现在公共存储库中,它们以合法招募的参与者为基础,通过人工智能驱动的分析来确定观众在多大程度以及以何种方式与广告互动。

人类视觉本能
在这方面,广告行业自然对确定误报(分析系统错误解读受试者行为的情况)感兴趣,并希望明确界定观看广告时观众没有全神贯注的标准。
就屏幕广告而言,研究通常集中在两种环境中的两个问题上。这两种环境分别是“桌面”和“移动”,每种环境都有其特定的特征,需要定制的跟踪解决方案;而从广告商的角度来看,这两个问题分别是猫头鹰行为和蜥蜴行为——观众倾向于不全神贯注地观看面前的广告。

如果你将整个头部转向广告之外,这就是“猫头鹰”行为;如果你头部姿势保持静止,但眼睛却从屏幕上移开,这就是“蜥蜴”行为。在分析和测试新广告的受控条件下,系统能够捕捉到这些行为至关重要。
SmartEye收购Affectiva后的一篇新论文解决了这些问题,提出了一种架构,利用多个现有框架提供涵盖所有必要条件和可能反应的组合特征集,并能够判断观众是否无聊、专注,或者以某种方式远离广告商希望他们观看的内容。
论文指出:
“有限 研究关注了在线广告期间的注意力监测。这些研究专注于估算头部姿势或注视方向以识别注意力转移的实例,但忽略了诸如设备类型(桌面或移动)、相机相对于屏幕的放置以及屏幕尺寸等关键参数。这些因素对注意力检测有着显著影响。”
“在本文中,我们提出了一种注意力检测架构,涵盖检测各种干扰因素,包括‘猫头鹰’和‘蜥蜴’行为(注视屏幕外)、说话、困倦(通过打哈欠和长时间闭眼)以及屏幕无人看管等情况。”
“与以往方法不同,我们的方法将设备特定特征(如设备类型、相机放置、桌面设备的屏幕尺寸以及移动设备的相机方向)与原始注视估算相结合,以提高注意力检测的准确性。”
方法和数据
由于这类系统的保密性和闭源性质,新论文并未将作者的方法与竞争对手直接进行比较,而是仅以消融研究的形式呈现其发现;此外,论文总体上也未遵循计算机视觉文献的常规格式。因此,我们将按照论文的呈现方式来审视这项研究。
作者强调,只有少数研究专门针对在线广告背景下的注意力检测。在AFFDEX SDK中,它提供实时多面孔识别,注意力仅从头部姿势推断,如果参与者的头部角度超过定义的阈值,则被标记为不专注。

在2019年的合作研究《Automatic Measurement of Visual Attention to Video Content using Deep Learning》中,一个包含约28000名参与者的数据库被标注了各种不专注行为,包括看向别处、闭眼或从事不相关活动,并训练了一个CNN-LSTM模型,用于从面部外观随时间检测注意力。

然而,作者指出,这些早期的努力并未考虑设备特定因素,例如参与者是使用桌面设备还是移动设备;也没有考虑屏幕尺寸或相机放置。此外,AFFDEX系统仅专注于识别注视转移,而忽略了其他分心来源,而2019年的研究尝试检测更广泛的不专注行为集合——但论文指出,其使用的单一浅层卷积神经网络可能不足以完成这项任务。
作者观察到,这一领域的部分热门研究并未针对广告测试进行优化,广告测试的需求与驾驶或教育等领域不同——在驾驶或教育领域,相机放置和校准通常会提前固定,而广告测试依赖于未校准的设置,并且操作在桌面和移动设备的有限注视范围内。
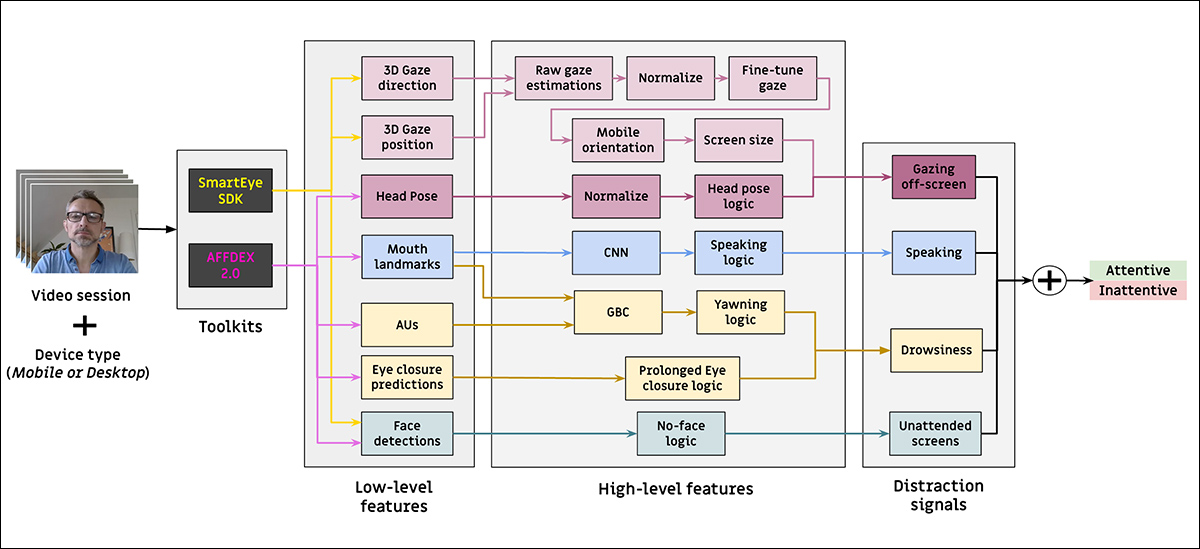
因此,他们设计了一种用于检测在线广告期间观众注意力的架构,利用两个商业工具包:AFFDEX 2.0和SmartEye SDK。

这些先前的工作提取了低级特征,如面部表情、头部姿势和注视方向。这些特征随后被处理以产生高级指标,包括屏幕上的注视位置;打哈欠;以及说话。
该系统识别四种分心类型:屏幕外注视;困倦;说话;以及无人看管的屏幕。它还根据观众是使用桌面设备还是移动设备调整注视分析。
数据集:注视
作者使用了四个数据集来驱动和评估注意力检测系统:其中三个分别专注于注视行为、说话和打哈欠,第四个则来自真实广告测试会话,包含多种分心类型的混合。
由于工作的特定需求,为每个类别创建了定制数据集。所有策划的数据集都来自一个包含数百万次记录会话的专有存储库,这些会话记录了参与者在家庭或工作场所环境中观看广告的情况,使用基于网络的设置,并在获得知情同意的情况下进行——但由于这些同意协议的限制,作者表示新研究的数据集无法公开。
为了构建注视数据集,参与者被要求跟随屏幕上不同位置(包括边缘)的移动点,并在四个方向(上、下、左、右)上将视线移开屏幕,重复三次序列。通过这种方式,建立了捕捉与覆盖之间的关系:
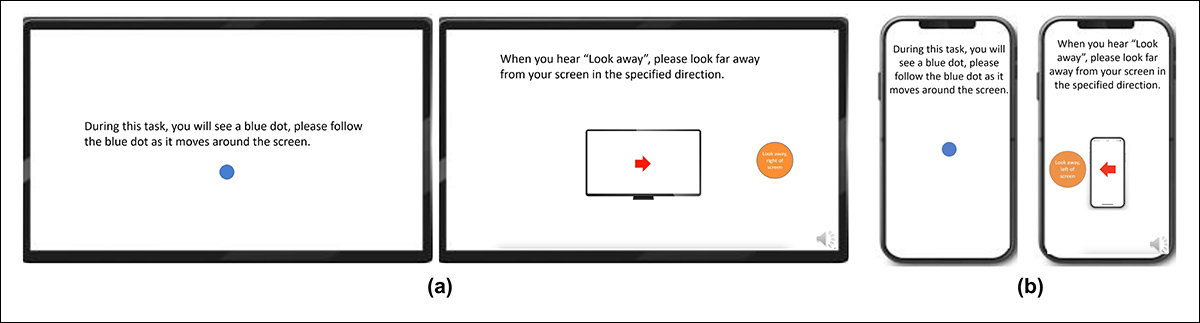
移动点的片段被标记为专注,而屏幕外的片段被标记为不专注,从而产生了一个包含正例和负例的标记数据集。
每个视频大约持续160秒,分别针对桌面和移动平台创建了不同版本,桌面和移动平台的分辨率分别为1920×1080和608×1080。
共收集了609个视频,包括322个桌面和287个移动记录。标签根据视频内容自动应用,并将数据集拆分为158个训练样本和451个测试样本。
数据集:说话
在这个上下文中,定义“不专注”的一个标准是当一个人说话时间超过一秒钟(这种情况可能是短暂的评论,甚至是咳嗽)。
由于受控环境不记录或分析音频,因此通过观察估计的面部标志的内部运动来推断说话。因此,为了在没有音频的情况下检测说话,作者基于完全来自其内部存储库的视觉输入创建了一个数据集,并将其分为两部分:第一部分包含大约5500个视频,每个视频由三名标注者手动标记为说话或不说话(其中4400个用于训练和验证,1100个用于测试)。
第二部分包含16000个会话,这些会话根据会话类型自动标记:10500个会话显示参与者静默观看广告,5500个显示参与者对品牌发表意见。
数据集:打哈欠
尽管存在一些“打哈欠”数据集,包括YawDD和Driver Fatigue,但作者认为没有一个适合广告测试场景,因为它们要么包含模拟的哈欠,要么包含可能被误认为是恐惧或其他非打哈欠行为的面部扭曲。
因此,作者从其内部收藏中选择了735个视频,选择可能包含持续时间超过一秒钟的下巴下垂的会话。每个视频由三名标注者手动标记为显示活跃或不活跃的打哈欠。只有2.6%的帧包含活跃的哈欠,突显了类别不平衡,数据集被拆分为670个训练视频和65个用于测试。
数据集:分心
分心数据集也来自作者的广告测试存储库,参与者在没有任何指定任务的情况下观看了实际广告。总共随机选择了520个会话(193个在移动设备上,327个在桌面环境中),并由三名标注者手动标记为专注或不专注。
不专注行为包括屏幕外注视、说话、困倦和无人看管的屏幕。这些会话涵盖了世界各地的不同地区,桌面记录更为常见,因为网络摄像头的放置更加灵活。
注意力模型
提出的注意力模型处理低级视觉特征,即面部表情、头部姿势和注视方向——通过上述AFFDEX 2.0和SmartEye SDK提取。
这些特征随后被转换为高级指标,每个分心因素由一个独立的二元分类器处理,每个分类器都在自己的数据集上进行训练,以便独立优化和评估。
注视模型通过归一化的注视坐标确定观众是否在看屏幕或看向别处,桌面和移动设备分别进行校准。辅助这一过程的是一个线性支持向量机(SVM),它在空间和时间特征上进行训练,并包含一个记忆窗口,以平滑快速的注视转移。
为了在没有音频的情况下检测说话,系统使用裁剪的嘴部区域和一个3D-CNN,该网络在对话和非对话视频片段上进行训练。根据会话类型分配标签,时间平滑减少了可能由短暂嘴部运动导致的假阳性。
打哈欠通过全脸图像裁剪检测,以捕捉更广泛的面部运动,使用3D-CNN在手动标记的帧上进行训练(尽管打哈欠在自然观看中的频率较低,并且与其他表情相似)。
屏幕无人看管通过面部缺失或极端头部姿势来识别,预测由决策树完成。
最终注意力状态通过固定规则确定:如果任何模块检测到不专注,则将观众标记为不专注——这种方法优先考虑敏感性,并针对桌面和移动环境分别进行调整。
测试
如前所述,测试采用消融方法,移除组件并观察对结果的影响。

注视模型通过三个关键步骤识别屏幕外行为:归一化原始注视估计、微调输出以及估算桌面设备的屏幕尺寸。
为了理解每个组件的重要性,作者分别移除了它们,并在两个数据集中的226个桌面和225个移动视频上评估性能。结果通过G-mean和F1分数衡量,如下所示:

在每种情况下,移除步骤后性能都有所下降。归一化在桌面设备上尤其有价值,因为桌面设备的相机放置变化比移动设备更大。
该研究还评估了视觉特征如何预测移动相机的方向:面部位置、头部姿势和眼睛注视的分数分别为0.75、0.74和0.60,而它们的组合达到了0.91,这突显了——作者指出——整合多个线索的优势。
说话模型在垂直唇部距离上进行训练,在手动标记的测试集上达到了0.97的ROC-AUC,在更大的自动标记数据集上达到了0.96,表明在两者之间表现一致。
打哈欠模型仅使用嘴部纵横比达到了96.6%的ROC-AUC,当与AFFDEX 2.0的动作单元预测相结合时,提高到了97.5%。
无人看管屏幕模型在AFFDEX 2.0和SmartEye未能检测到面部超过一秒钟时将时刻分类为不专注。为了评估这一模型的有效性,作者手动标注了真实分心数据集中所有此类无面部事件,并识别了每个激活的潜在原因。模糊不清的情况(例如相机遮挡或视频失真)被排除在分析之外。
如下表所示,只有27%的“无面部”激活是由于用户实际离开了屏幕。
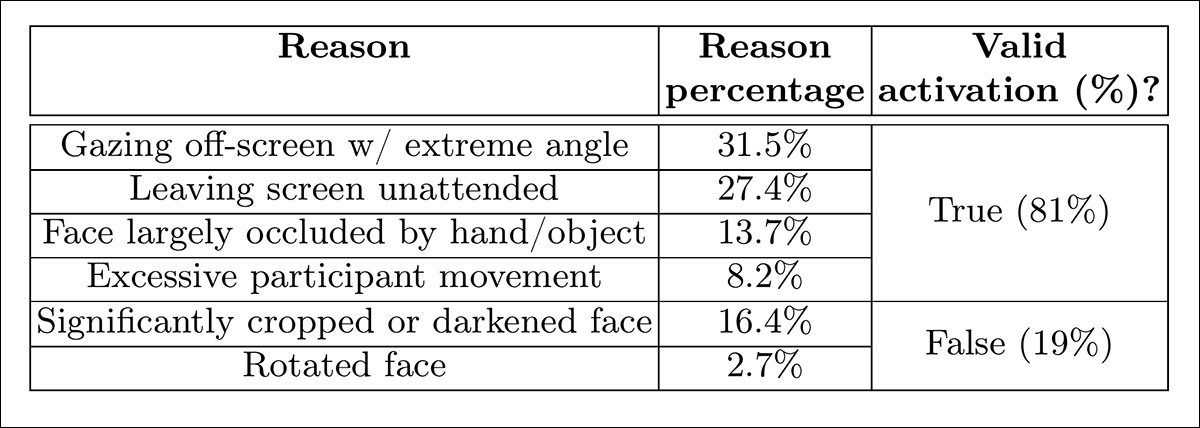
论文指出:
“尽管无人看管屏幕仅占触发无面部信号实例的27%,但该信号也可能因其他表明不专注的原因而被激活,例如参与者以极端角度看向屏幕外、进行过多运动或用物体/手显著遮挡面部。”
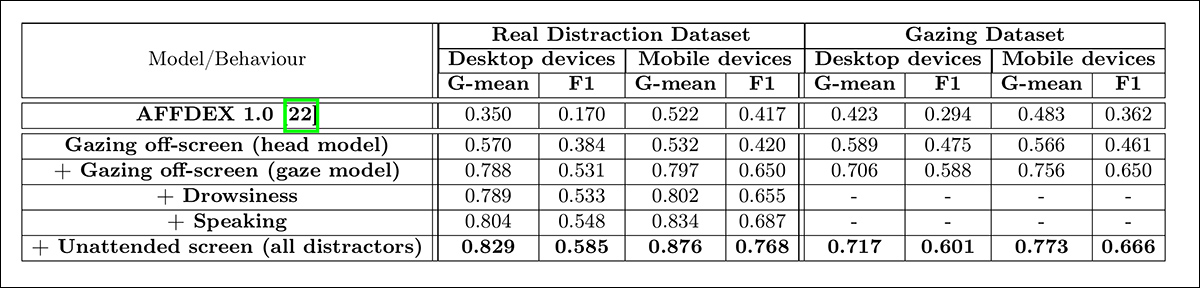
在最后的定量测试中,作者评估了逐步添加不同的分心信号——屏幕外注视(通过注视和头部姿势)、困倦、说话和无人看管屏幕——对整体注意力模型性能的影响。
测试在两个数据集上进行:真实分心数据集和注视数据集的一个测试子集。使用G-mean和F1分数衡量性能(尽管困倦和说话因在该上下文中相关性有限而被排除在注视数据集分析之外)。
如下所示,随着更多分心类型的添加,注意力检测性能持续提高,其中屏幕外注视这一最常见的分心因素提供了最强的基线。
关于这些结果,论文指出:
“首先,我们可以得出结论,整合所有分心信号有助于增强注意力检测。其次,注意力检测的改进在桌面和移动设备上都是一致的。第三,真实数据集中的移动会话在看向别处时头部运动显著,易于检测,因此移动设备的性能高于桌面设备。第四,添加困倦信号与其他信号相比,改进相对较小,因为它通常很少发生。最后,无人看管屏幕信号在移动设备上的改进相对大于桌面设备,因为移动设备更容易被留置无人看管。”
作者还将他们的模型与用于广告测试的先前系统AFFDEX 1.0进行了比较,即使当前模型的头部注视检测在两种设备类型上都优于AFFDEX 1.0:
“这一改进是由于纳入了头部在偏航和俯仰方向的运动,以及对微小变化进行头部姿势归一化。真实移动数据集中显著的头部运动导致我们的头部模型表现类似于AFFDEX 1.0。”
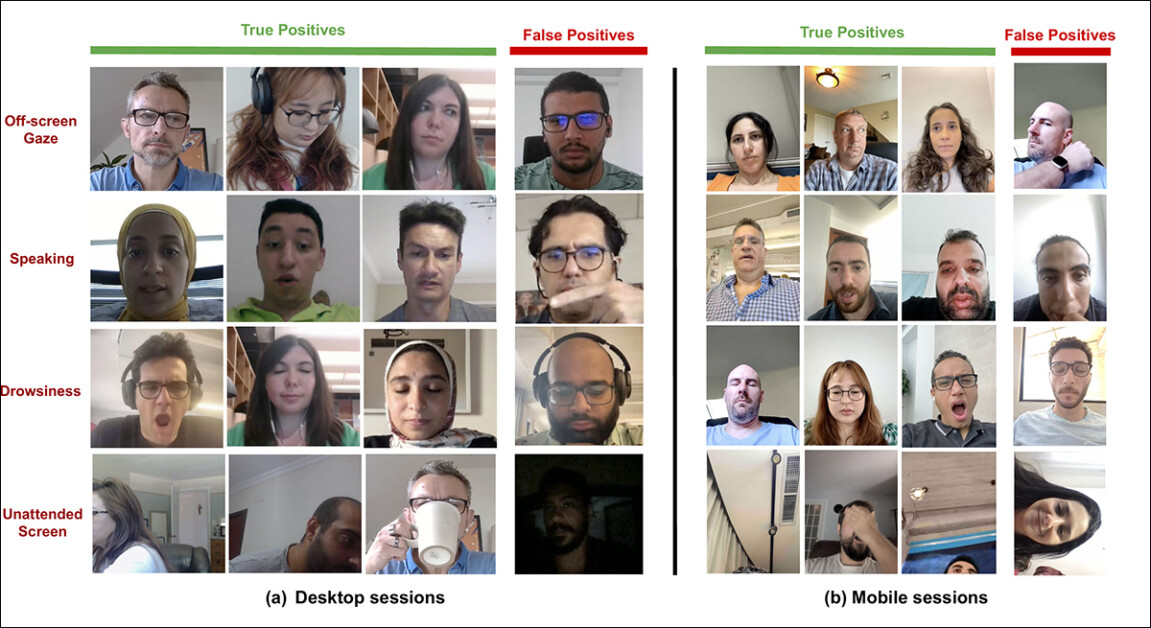
作者以一个(或许有些敷衍的)定性测试环节结束论文,如下所示。

作者指出:
“结果表明,我们的模型在不受控制的环境中能有效检测各种分心因素。然而,在某些边缘情况下,它可能会偶尔产生假阳性,例如在保持对屏幕注视的同时严重倾斜头部、嘴巴被遮挡、眼睛过于模糊或面部图像过于昏暗。”
结论
尽管结果代表了对先前工作的适度但有意义的进展,但这项研究的更深层价值在于它提供了一个窥探观众内心状态的视角。尽管数据是在获得同意的情况下收集的,但这种方法指向了未来可能超出结构化市场研究环境的框架。
这一有些偏执的结论得到了这一特定研究领域封闭、受限和保守的性质的支持。
原文地址:https://www.unite.ai/looking-for-owls-and-lizards-in-an-advertisers-audience/