
基于腾讯云MCP广场的AI自动化实践:爬取小红书热门话题
我正在参加Trae「超级体验官」创意实践征文,本文所使用的 Trae 免费下载链接:www.trae.com.cn/?utm_source…
🔎 背景
在人工智能快速发展的时代,AI技术不仅重塑了传统行业,也极大提高了开发者的工作效率。腾讯云推出的 MCP(Model Context Protocol),作为一种创新的技术协议,能够帮助开发者将云能力、AI模型与自动化流程高效整合,让开发者可以将更多精力集中在业务逻辑和创新上,而不再是重复性工作。
最近,腾讯云推出了**MCP广场,一个帮助开发者轻松创建与管理自动化应用的平台。在探索过程中,我发现了一个非常有趣的工具——超浏览器AI自动化**,它能让开发者通过浏览器模拟技术实现自动化操作。我曾经看到过一个小红书爬取的代码,但由于种种原因没有成功运行。于是,我决定尝试利用超浏览器AI自动化功能,结合腾讯云MCP的能力,进行小红书热门话题的自动化爬取与分析,最终成功实现了这一目标。
📉效果展示

通过本次实践,成功构建了一个自动化流程,它能够:
- 将提取到的数据(如标题、作者、点赞数)结构化。
- 基于抓取的数据,通过AI能力生成对当前热门趋势的分析,甚至提炼出具有吸引力的热门标题。
- 将最终结果保存为一个整洁的 Markdown 文件,便于后续查阅和使用。
👍AI编程开发流程
🧰 工具选型与架构
| 组件 | 用途 | 工具 |
|---|---|---|
| 用户输入 | 提供创作方向 | 自然语言输入 |
| MCP能力平台 | 提供发现、管理和调用各类 MCP 工具的平台。是整个自动化实践的入口。 | 腾讯云MCP |
| MCP LLM工具链 | 解析输入并生成话题 | Trae |
| 超浏览器自动化 | 模拟浏览器行为,获取平台信息 | Playwright/Selenium |
| 数据处理与输出 | 格式化生成内容,提供创作灵感 | markdown |
🧱不能运行的爬取小红书代码
如前所述,对于小红书这类大量使用JavaScript动态加载内容的网站,传统的静态HTML解析方法往往无法获取到完整的页面信息。
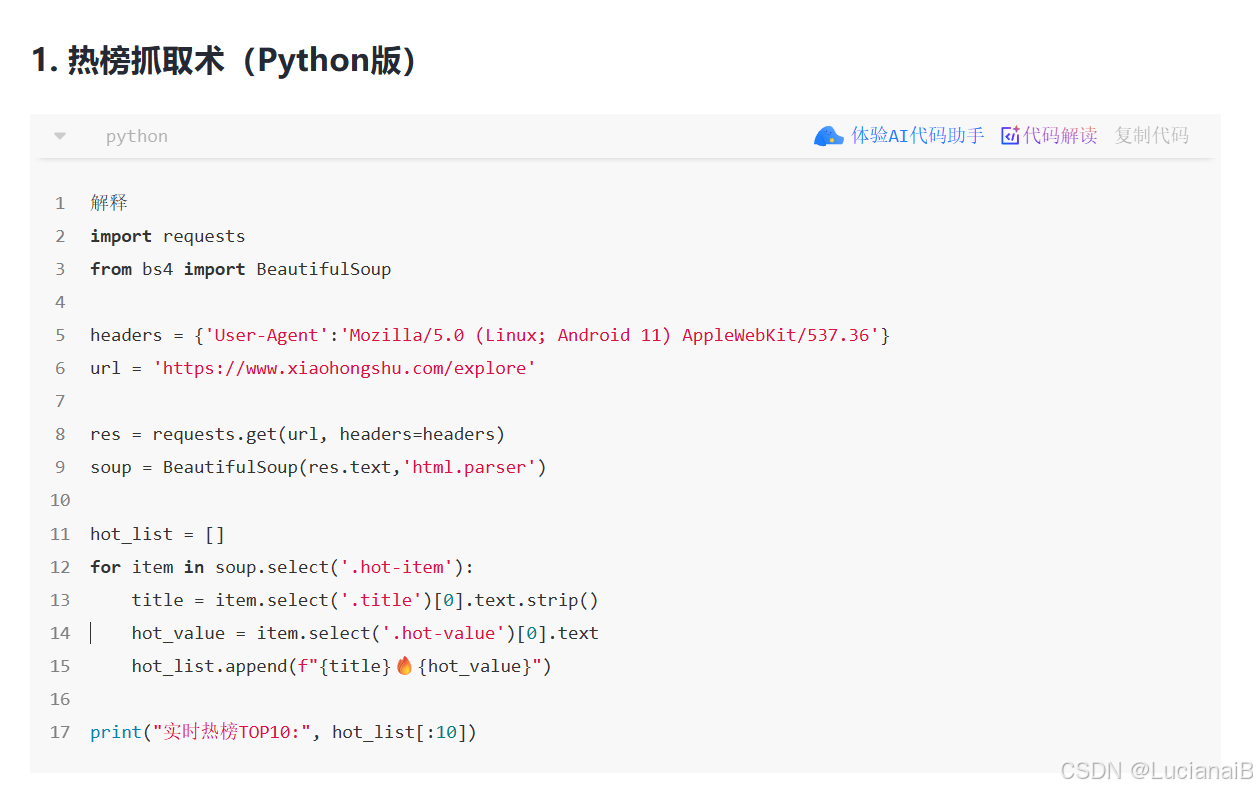
以下是我发现并运行过过的爬取小红书的代码(未能成功运行):
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent':'Mozilla/5.0 (Linux; Android 11) AppleWebKit/537.36'}
url = 'https://www.xiaohongshu.com/explore'
res = requests.get(url, headers=headers)
soup = BeautifulSoup(res.text,'html.parser')
hot_list = []
for item in soup.select('.hot-item'):
title = item.select('.title')[0].text.strip()
hot_value = item.select('.hot-value')[0].text
hot_list.append(f"{title}🔥{hot_value}")
print("实时热榜TOP10:", hot_list[:10])
之前看到的代码如下(来源):
这段代码的逻辑是发送一个HTTP请求,然后使用 BeautifulSoup 解析返回的HTML文本,尝试通过CSS选择器(.hot-item, .title, .hot-value)来定位热门话题元素。
然而,当我尝试在本地运行这段代码时,并没有得到预期的热门话题列表:
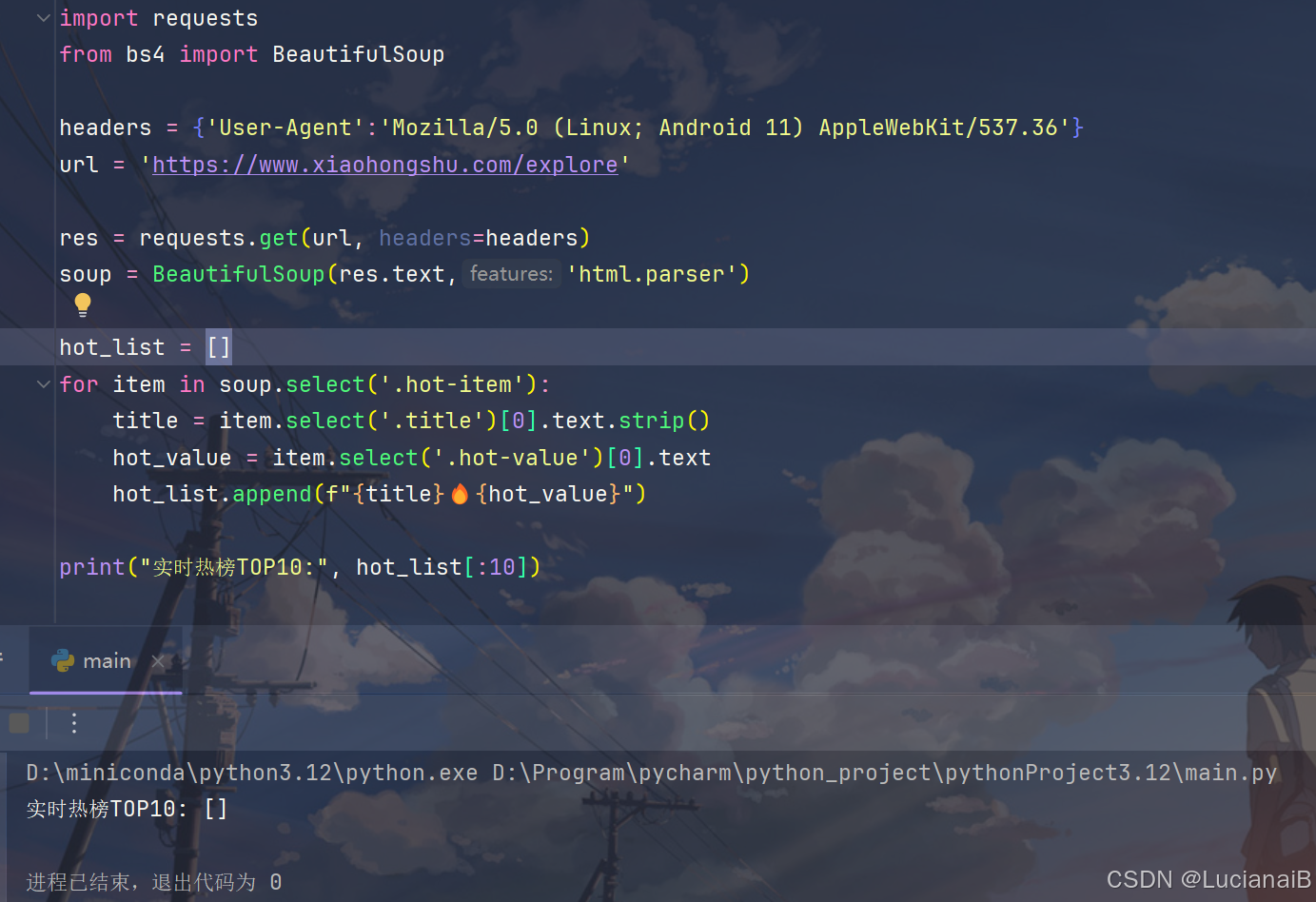
运行了个寂寞。哈哈哈哈。

😊腾讯云发现的AI自动化实践爬取小红书:超浏览器出击!
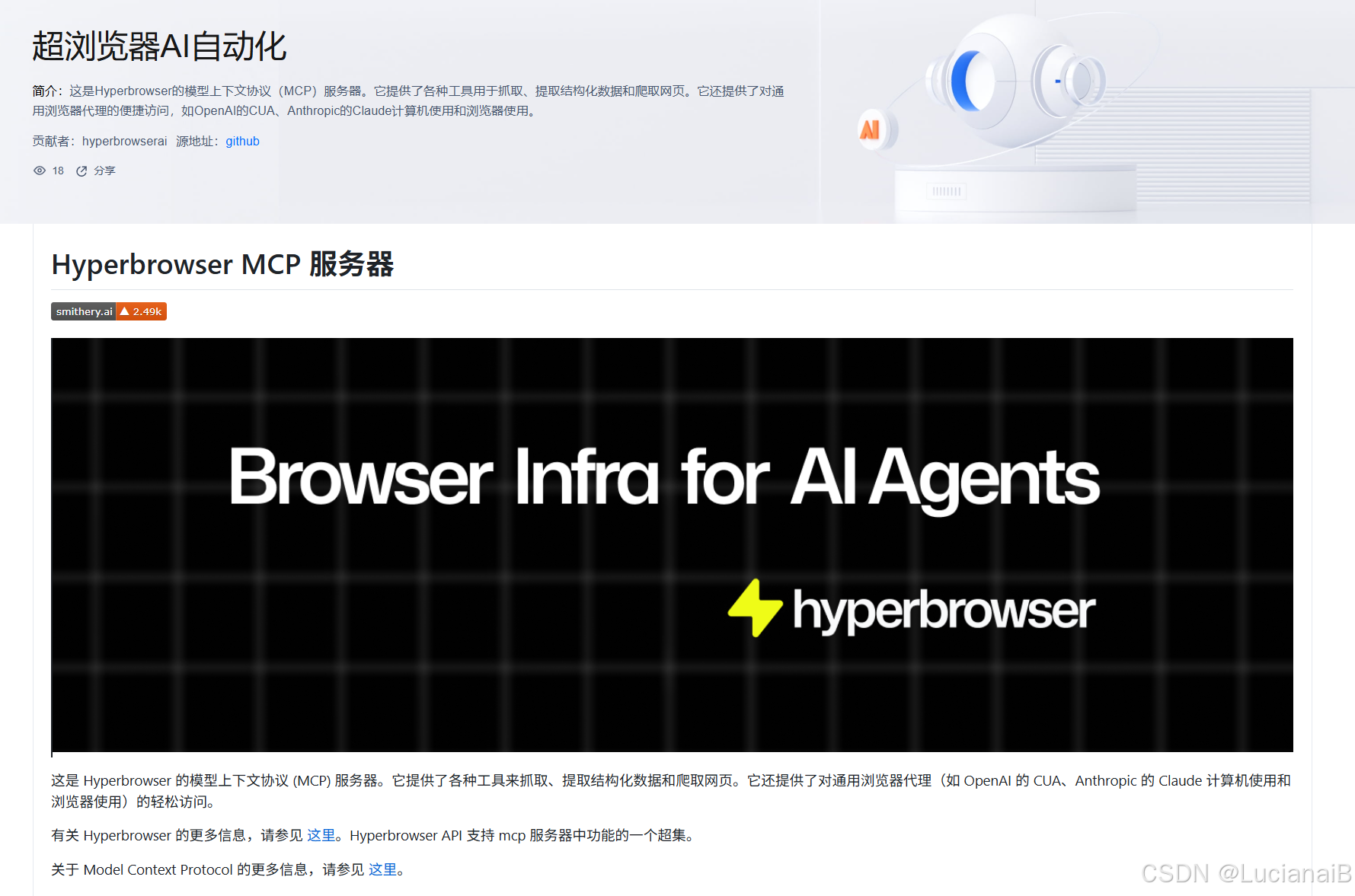
1.打开腾讯云MCP广场(点击前往了解详情),点击浏览器自动化,找到超浏览器AI自动化。
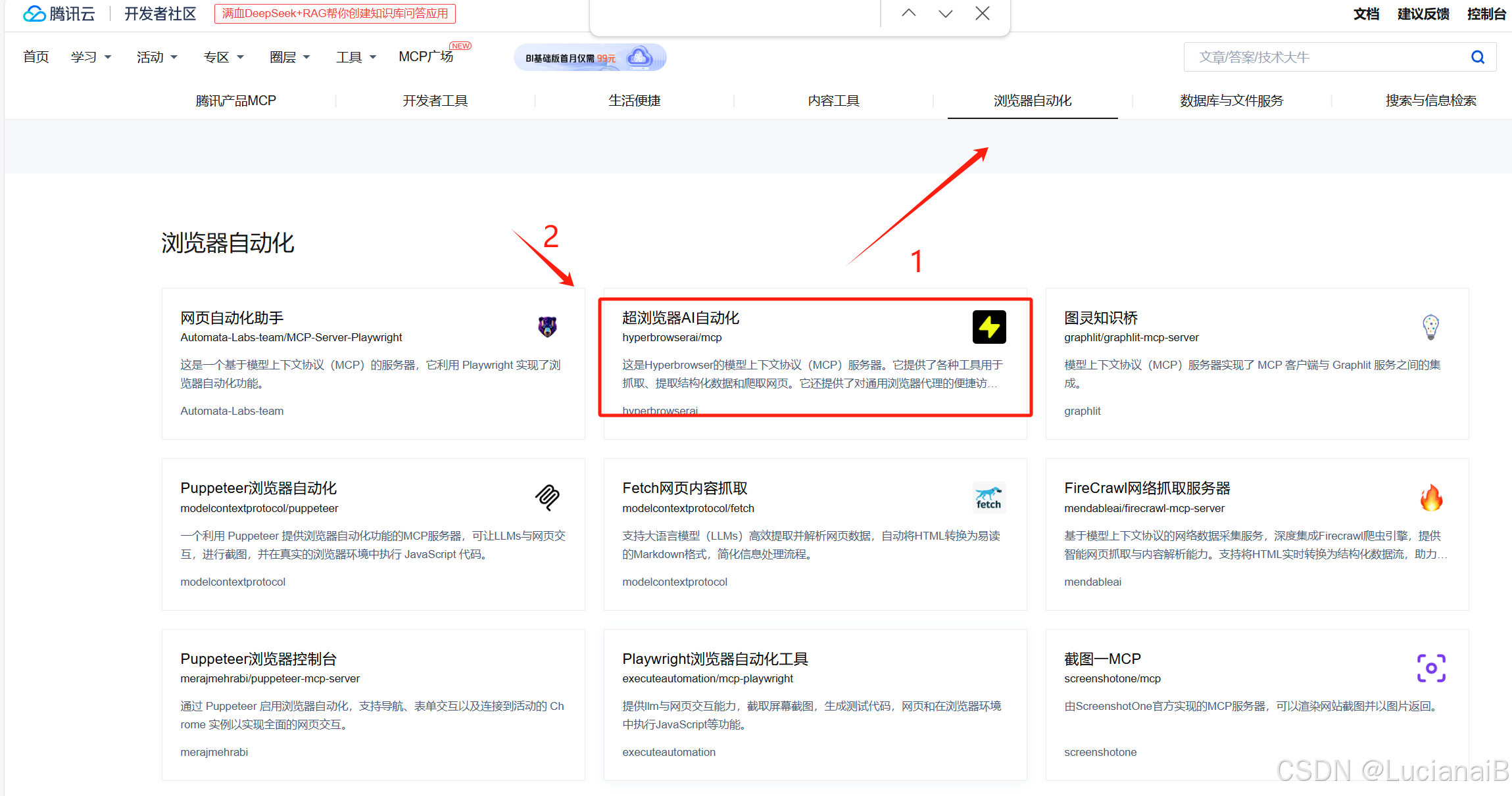
2.在超浏览器AI自动化页面可以看到安装,使用,工具,配置以及许可证。
3.根据说明,进入Hyperbrowser官网,找到API配置页面。按照官方文档的指导,创建并配置 API_KEY,再到Trae CN中进行配置,就可以开始使用了。
代码如下(修改API_KEY):
{
"mcpServers": {
"hyperbrowser": {
"command": "npx",
"args": ["-y", "hyperbrowser-mcp"],
"env": {
"HYPERBROWSER_API_KEY": "API_KEY"
}
}
}
}
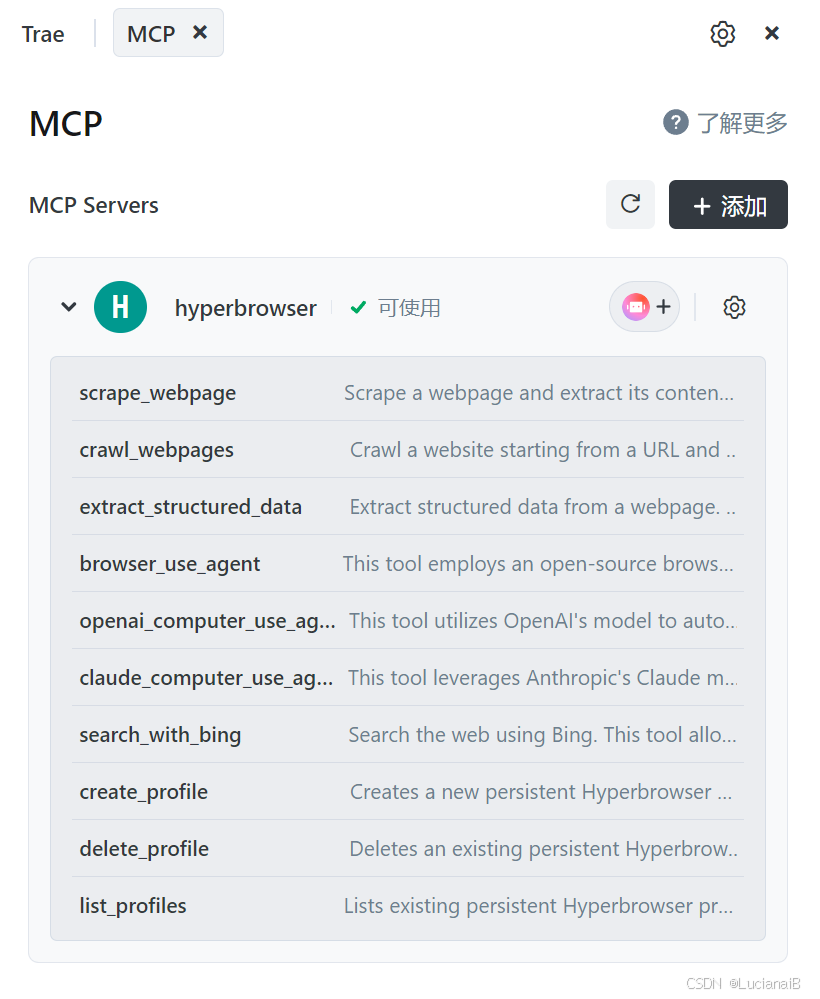
配置成功的截图如下:
🚀 使用 Trae CN 进行编程与自动化编排
Trae CN 是一个强大的开发工具,它集成了 AI 能力和 MCP 调用能力,允许我们通过自然语言或代码来 orchestrate 自动化流程。
新建一个文件夹,命名为:浏览器自动化,使用Trae CN打开这个文件夹
使用Ctrl+U唤醒对话,在对话中选择Builder with MCP,使用下面的提示词。
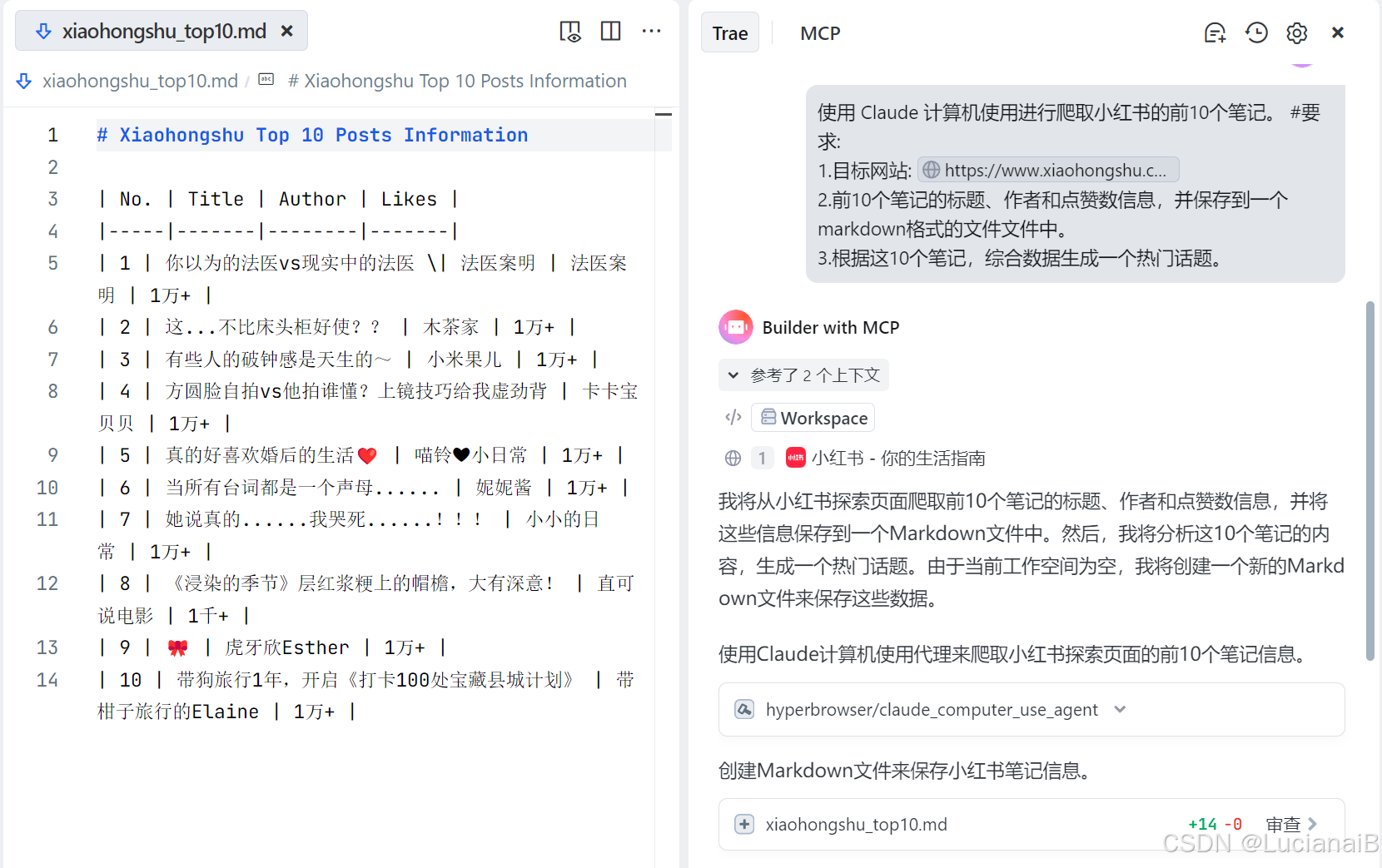
使用 Claude 计算机使用进行爬取小红书的前10个笔记。 #要求:
1.目标网站:https://www.xiaohongshu.com/explore
2.前10个笔记的标题、作者和点赞数信息,并保存到一个markdown格式的文件文件中。
3.根据这10个笔记,综合数据生成一个热门话题。
AI 代理(Claude)接收到这个指令后,会理解我们的意图,并智能地将任务分解:
- 识别出需要进行网页数据抓取,这需要调用超浏览器AI自动化 MCP。
- 构造调用超浏览器 MCP 的具体指令,包括导航到目标 URL,以及执行哪些操作来查找和提取前10个笔记的数据(例如,通过 CSS 选择器、XPath,甚至结合视觉识别能力,这取决于超浏览器工具的实现细节)。
- 指示超浏览器执行这些操作,并等待结果返回。
- 接收超浏览器返回的原始数据(例如,一个包含10个笔记信息的结构化列表)。
- 利用 Claude 自身的语言理解和生成能力,处理这些数据。首先,将数据格式化,准备写入 Markdown 文件。其次,对这10个笔记的标题和内容(如果能抓取到更多信息)进行分析,识别其中的共同主题或趋势,提炼出一个热门话题。
- 将格式化后的数据和生成的热门话题组合,按照 Markdown 格式进行排版。
- 将最终生成的 Markdown 内容输出,并指示保存到指定的文件(
xiaohongshu_top10.md)。
在 Trae CN 中,我们可以看到 AI 代理逐步执行这些任务的过程以及它的思考链条。它可能会显示正在调用 MCP 工具、正在处理数据、正在生成内容等提示信息。
成功完成小红书前10个笔记的爬取和保存任务,并分析了这些笔记内容。以下是总结:
- 在小红书探索页面爬取了前10个笔记的标题、作者和点赞数信息
- 将这些信息保存到了
xiaohongshu_top10.md文件中 - 分析这些笔记内容后,发现当前热门话题集中在:
- 生活方式分享(如旅行、宠物、婚后生活)
- 实用技巧(如拍照技巧、家居改造)
- 娱乐内容(如影视解说、搞笑视频)
优化总结输出:
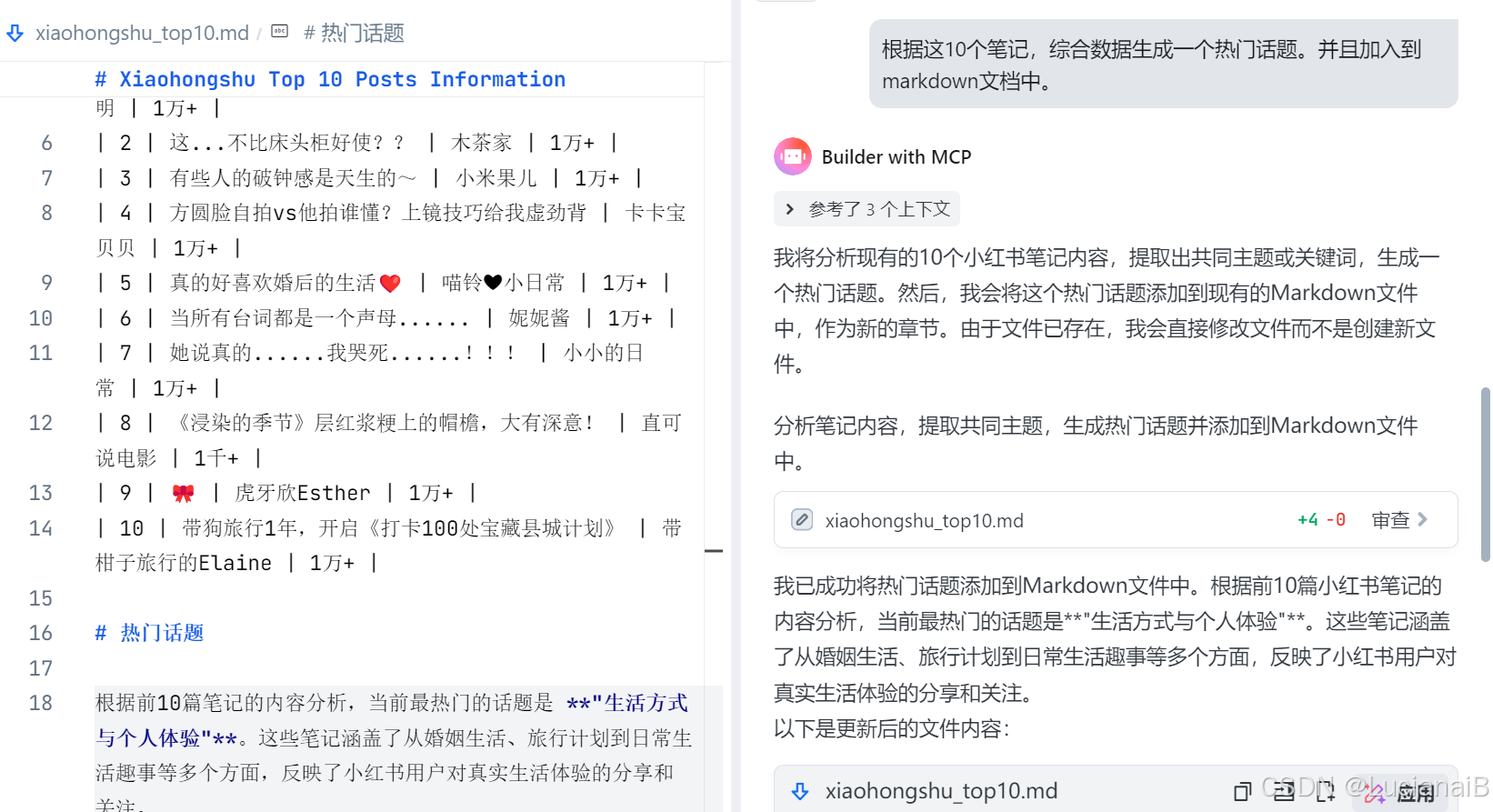
根据这10个笔记,综合数据生成一个热门话题。并且加入到markdown文档中。
结果:
# 热门话题
根据前10篇笔记的内容分析,当前最热门的话题是 **"生活方式与个人体验"**。这些笔记涵盖了从婚姻生活、旅行计划到日常生活趣事等多个方面,反映了小红书用户对真实生活体验的分享和关注。
进一步优化输出:生成具体的热门标题
AI 代理基于数据分析生成了热门话题方向(“生活方式与个人体验”),但如果我们希望得到一个更具体、更具吸引力的笔记标题,可以进一步细化指令。
继续在 Trae CN 的对话窗口中,针对刚刚完成的任务,输入新的提示词:
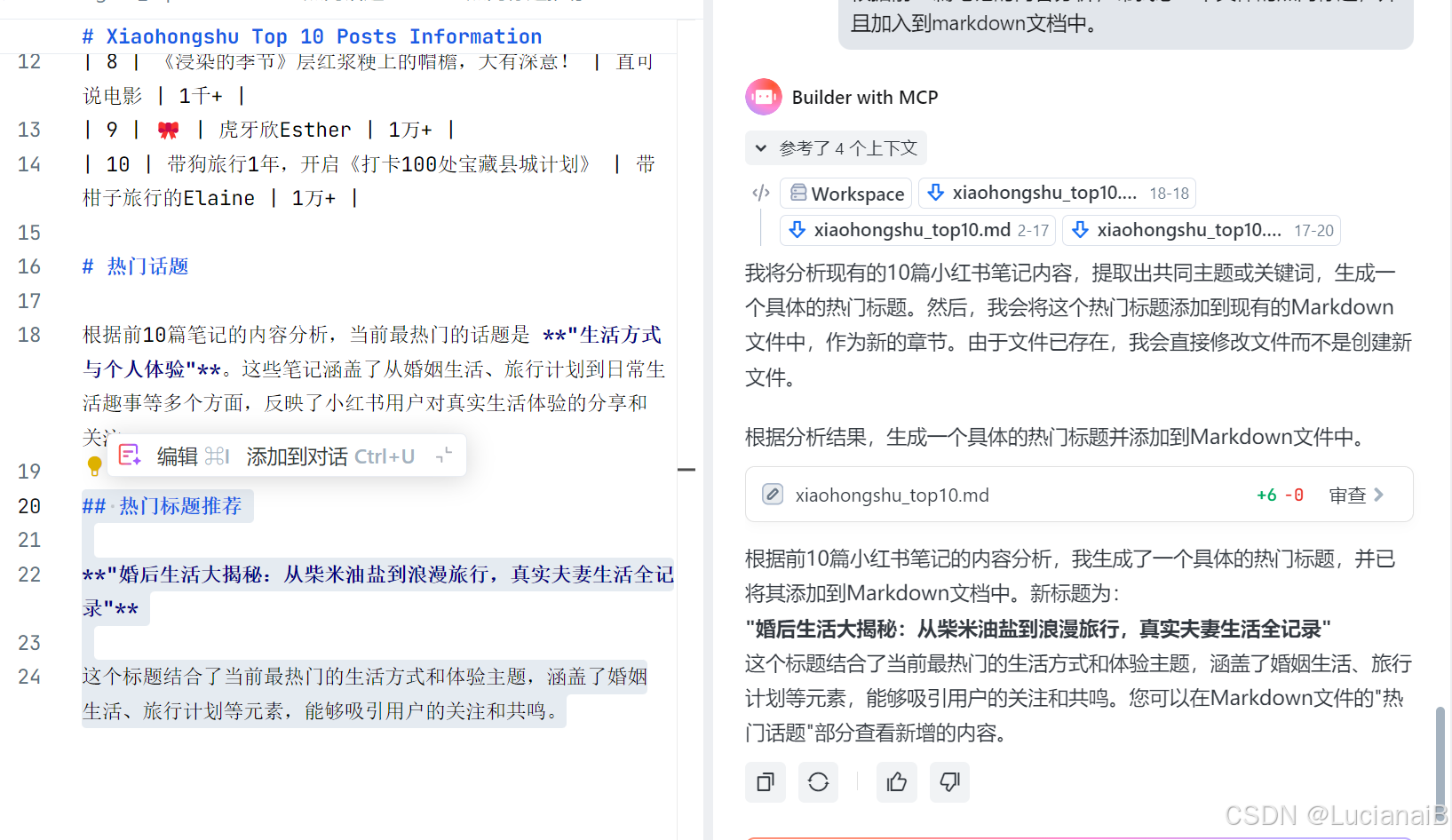
根据前10篇笔记的内容分析,帮我想一个具体的热门标题,并且加入到markdown文档中。
结果:
## 热门标题推荐
**"婚后生活大揭秘:从柴米油盐到浪漫旅行,真实夫妻生活全记录"**
这个标题结合了当前最热门的生活方式和体验主题,涵盖了婚姻生活、旅行计划等元素,能够吸引用户的关注和共鸣。
至此,我们成功地利用腾讯云 MCP 广场、超浏览器AI自动化以及 Trae,实现了小红书热门话题和笔记数据的自动化爬取、分析与内容生成。
全文总结
腾讯云MCP广场
腾讯云MCP广场堪称当前AI自动化领域的集大成者,它不仅提供了高度模块化的能力调用平台,还极大地简化了从“想法”到“落地”的整个开发流程。通过统一的接口与多种预置组件,开发者无需掌握复杂的工程细节,也能像搭积木一样构建强大且可扩展的自动化系统。尤其值得一提的是其“超浏览器AI自动化”工具,真正做到了低代码、甚至零代码完成复杂网页的动态数据抓取,这一突破对于以往困于JS渲染与反爬机制的开发者来说,无疑是生产力的质变飞跃。MCP广场不仅是工具集合,更是AI能力与开发者之间的高效桥梁,是每一个希望拥抱AI未来的技术人员不可或缺的平台。
Trae的MCP使用
Trae不仅是一个开发工具,它更像是一个真正懂你意图的“AI编程助手”。通过自然语言指令,开发者无需编写冗长代码,就能完成复杂的任务编排与AI能力调用。在本次项目中,Trae展现出卓越的任务理解能力——从输入一句“爬取小红书热门笔记”,到自动识别目标、调用MCP超浏览器工具、抓取数据、格式化输出、分析趋势,甚至推荐热门标题,全流程几乎无需人工干预。Trae就像一位经验丰富的AI工程师,能听懂你的话、明白你的目标,并迅速将其转化为可执行的方案。它大幅度提升了开发体验,也重新定义了“AI助力开发”的边界,是MCP生态中不可多得的“智慧中枢”。