基于LSTM与SHAP可解释性分析的神经网络回归预测模型【MATLAB】
一、引言
在数据驱动的智能时代,时间序列预测已成为许多领域(如金融、气象、工业监测等)中的关键任务。长短期记忆网络(LSTM)因其在捕捉时间序列长期依赖关系方面的优势,广泛应用于复杂时序建模任务中。
与此同时,随着模型复杂度的提升,其“黑箱”特性也愈发明显,限制了其在一些对透明性要求较高的场景中的应用。为了解决这一问题,引入**SHAP(SHapley Additive exPlanations)**方法进行可解释性分析,有助于揭示模型的决策逻辑。
本文将以MATLAB为平台,围绕一个基于LSTM与SHAP结合的回归预测模型,从原理角度出发,介绍其构建思路与解释方法,避免涉及具体公式与代码细节。
二、LSTM在回归预测中的作用
2.1 LSTM的基本结构与思想
LSTM是一种特殊的循环神经网络(RNN),专门设计用于解决传统RNN在处理长序列时出现的梯度消失或梯度爆炸问题。它通过引入记忆单元和三个门控机制(输入门、遗忘门、输出门),实现了对信息的选择性保留与更新。
这种结构使得LSTM能够有效捕捉时间序列中的长期依赖关系,从而更准确地进行趋势预测。
2.2 LSTM在回归任务中的角色
在回归预测任务中,LSTM主要承担以下功能:
- 自动提取时间序列中的动态模式:无需人工构造滞后特征,模型能自动学习不同时间点之间的依赖关系。
- 处理非线性、非平稳数据:适用于具有复杂波动特性的实际数据,如股价、气温变化等。
- 多变量建模能力:支持多维输入,可以同时考虑多个影响因素(如温度、湿度、风速等)对目标变量的影响。
因此,LSTM在诸如电力负荷预测、空气质量预报、设备健康状态评估等领域表现出色。
三、模型的可解释性需求与SHAP的作用
尽管LSTM在预测精度上表现优异,但其内部机制较为复杂,导致用户难以理解其预测依据。这种“黑箱”特性在某些高风险应用场景中会引发信任问题。
3.1 SHAP的核心理念
SHAP是一种基于博弈论的统一解释框架,其核心思想是:
每个输入特征对模型输出的贡献值等于该特征在所有可能特征组合下的平均边际贡献。
SHAP值不仅可以反映各特征的重要性排序,还能指出其对预测结果的具体影响方向(正向或负向),从而提供直观、一致的解释。
3.2 SHAP在LSTM模型中的应用
虽然SHAP最初多用于树模型(如XGBoost、LightGBM),但近年来也被成功应用于神经网络模型的解释中。在LSTM模型中使用SHAP,可以实现:
- 对每个时间步的输入特征进行重要性评分;
- 分析哪些变量在特定时间段内对预测结果影响最大;
- 提供可视化工具帮助用户理解模型行为,增强模型可信度。
四、LSTM+SHAP联合建模流程概述
下面是一个典型的基于LSTM与SHAP的回归预测模型的工作流程:
4.1 数据准备阶段
- 收集具有时间依赖性的原始数据(如传感器采集的时间序列);
- 进行缺失值填充、标准化、归一化等预处理操作;
- 构造历史窗口作为输入样本,设定目标输出标签,划分训练集与测试集。
4.2 LSTM建模阶段
- 构建包含LSTM层与全连接层的神经网络结构;
- 使用训练数据训练模型,使其学会从历史序列中提取关键信息并输出预测值;
- 在验证集上评估模型性能,并根据需要调整网络结构或训练参数。
4.3 SHAP解释阶段
- 利用训练好的LSTM模型生成SHAP值;
- 分析不同时间点、不同输入变量对预测结果的影响;
- 结合折线图、热力图等形式展示特征重要性及其变化趋势;
- 根据解释结果优化模型结构或指导数据采集策略。
五、总结与展望
将LSTM与SHAP相结合,构建具有可解释性的神经网络回归预测模型,是当前人工智能发展的一个重要方向。这种方法既保留了深度学习强大的时序建模能力,又增强了模型的透明度与可信度,有助于推动AI技术在医疗、金融、能源等敏感领域的落地应用。
未来,我们可以进一步探索如何提高SHAP计算效率,或将该框架拓展至其他时序模型(如GRU、Transformer)中,构建更加智能、高效的可解释系统。
六、部分代码
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
rng('default');
tic
%% 导入数据
res = xlsread('data.xlsx');
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
% res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
lstmnumber = 50;
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
L = size(P_train, 1);
%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test1 = mapminmax('apply', P_test, ps_input);
[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test1 = mapminmax('apply', T_test, ps_output);
%% 数据平铺
% 将数据平铺成1维数据只是一种处理方式
% 也可以平铺成2维数据,以及3维数据,需要修改对应模型结构
% 但是应该始终和输入层数据结构保持一致
p_train = reshape(p_train, L, 1, 1, M);
p_test = reshape(p_test1 , L, 1, 1, N);
t_train = double(t_train)';
t_test = double(t_test1 )';
%% 数据格式转换
for i = 1 : M
Lp_train{i, 1} = p_train(:, :, 1, i);
end
for i = 1 : N
Lp_test{i, 1} = p_test( :, :, 1, i);
end
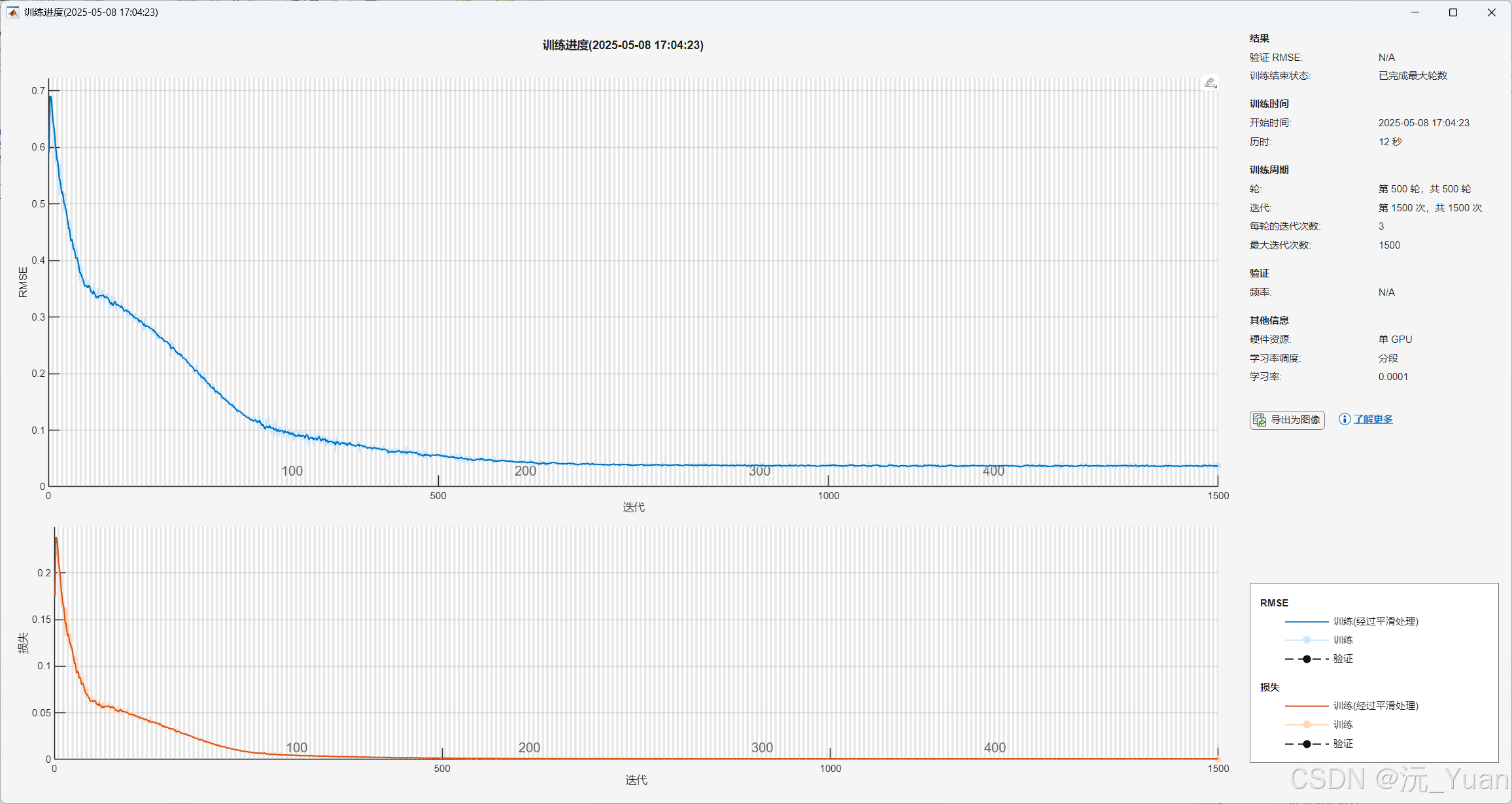
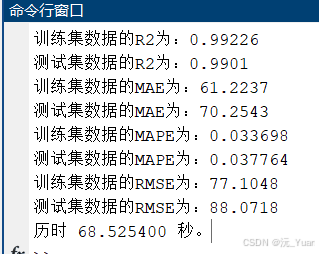
七、运行结果