随着大型语言模型(LLM)规模和复杂度的指数级增长,推理效率已成为人工智能领域亟待解决的关键挑战。当前,GPT-4、Claude 3和Llama 3等大模型虽然表现出强大的理解与生成能力,但其自回归解码过程中的计算冗余问题依然显著制约着实际应用场景中的响应速度和资源利用效率。
键值(KV)缓存技术作为Transformer架构推理优化的核心策略,通过巧妙地存储和复用注意力机制中的中间计算结果,有效解决了自回归生成过程中的重复计算问题。与传统方法相比,该技术不仅能够在不牺牲模型精度的前提下显著降低延迟,更能实现近线性的计算复杂度优化,为大规模模型部署提供了实用解决方案。
本文将从理论基础出发,系统阐述KV缓存的工作原理、技术实现与性能优势。我们将通过PyTorch实现完整演示代码,详细分析缓存机制如何与Transformer架构的自注意力模块协同工作,并通过定量实验展示不同序列长度下的性能提升。此外,文章还将讨论该技术在实际应用中的局限性及未来优化方向,为读者提供全面而深入的技术洞察。
无论是追求极致推理性能的AI工程师,还是对大模型优化技术感兴趣的研究人员,本文的实践导向方法都将帮助你理解并掌握这一关键性能优化技术。
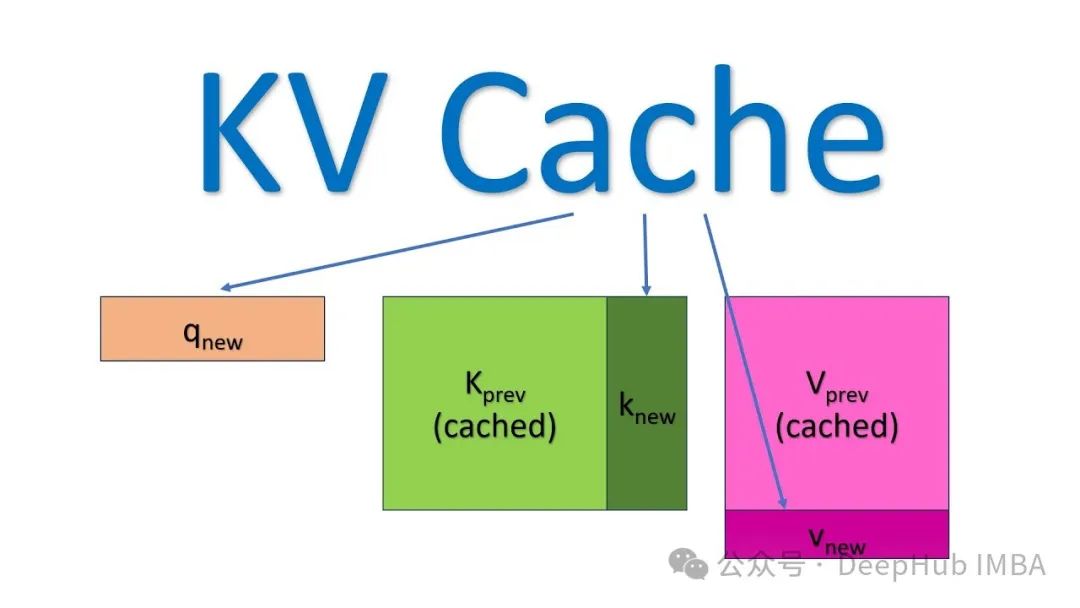
KV缓存是一种优化技术,用于存储注意力机制中已计算的Key和Value张量,这些张量可在后续自回归生成过程中被重复利用,从而有效减少冗余计算,显著提升推理效率。
键值缓存原理
注意力机制基础
类的实现遵循标准的多头注意力模块设计。输入张量形状为(B, T, C),其中B代表批次大小,T表示序列长度(在本实现中最大序列长度为
),C表示嵌入维度。
多头注意力机制的核心思想是将嵌入空间划分为多个头,每个头独立计算注意力权重。对于嵌入维度C=128且头数量为4的情况,每个头的维度为128/4=32。系统将分别计算这4个大小为32的注意力头,然后将结果拼接成形状为(B, T, 128)的输出张量。
KV缓存的必要性
为理解KV缓存的必要性,首先需要分析注意力机制的计算过程:
在注意力头的实现中,系统通过线性变换生成Key、Value和Query,它们的形状均为(B, T, C),其中C为头的大小。
Query与Key进行点积运算,生成形状为(B, T, T)的权重矩阵,表示各token之间的相关性。权重矩阵经过掩码处理转换为下三角矩阵,确保在点积运算过程中每个token仅考虑前面的token(即从1到n),这强制实现了因果关系,使得自回归模型中的token仅使用历史信息预测下一个token。
下图展示了自回归生成在注意力机制中的实现过程:
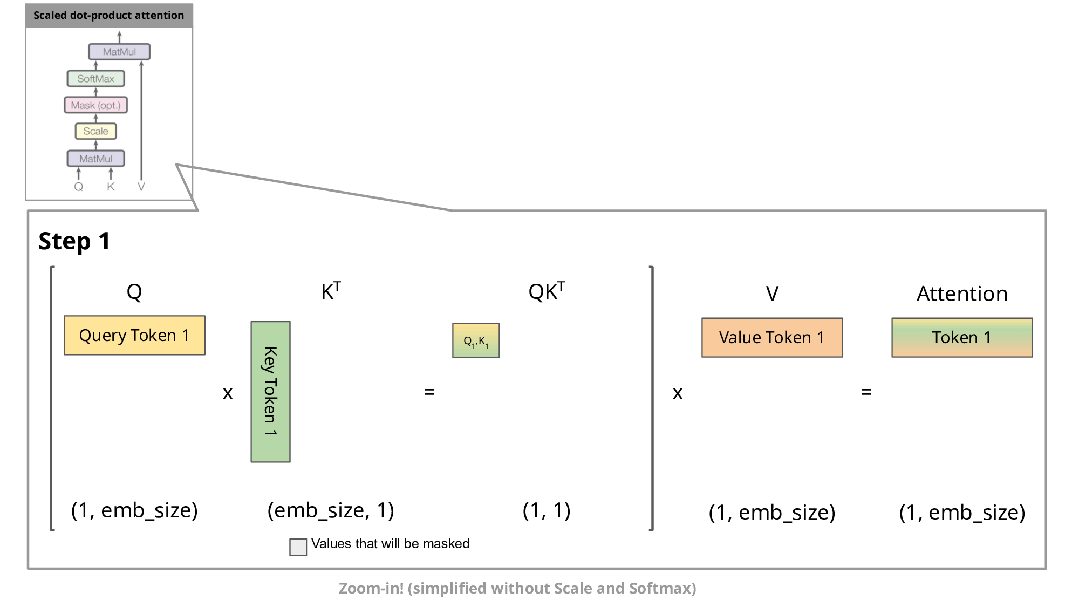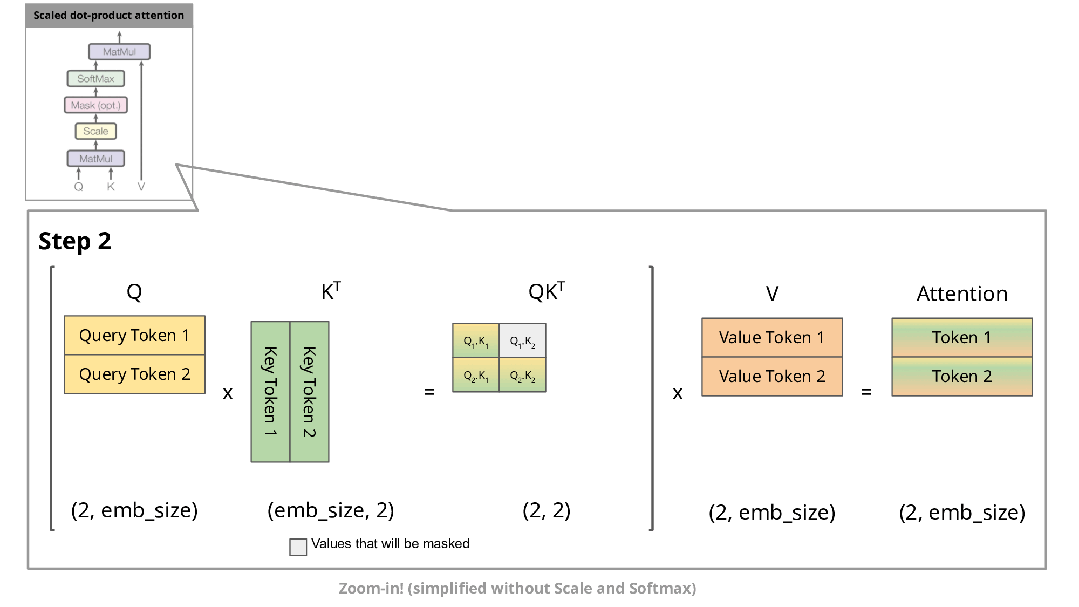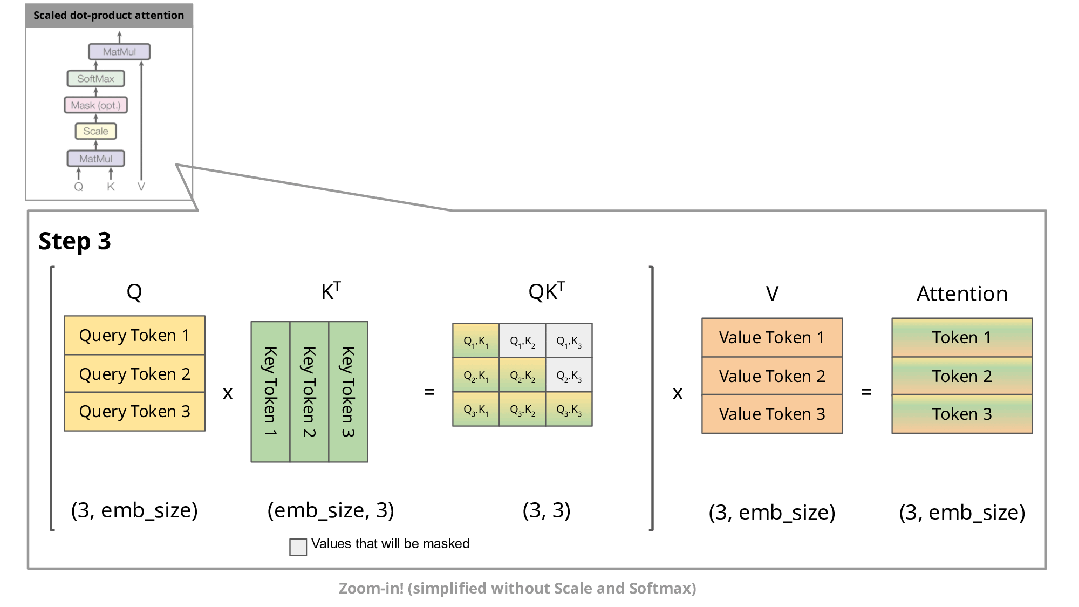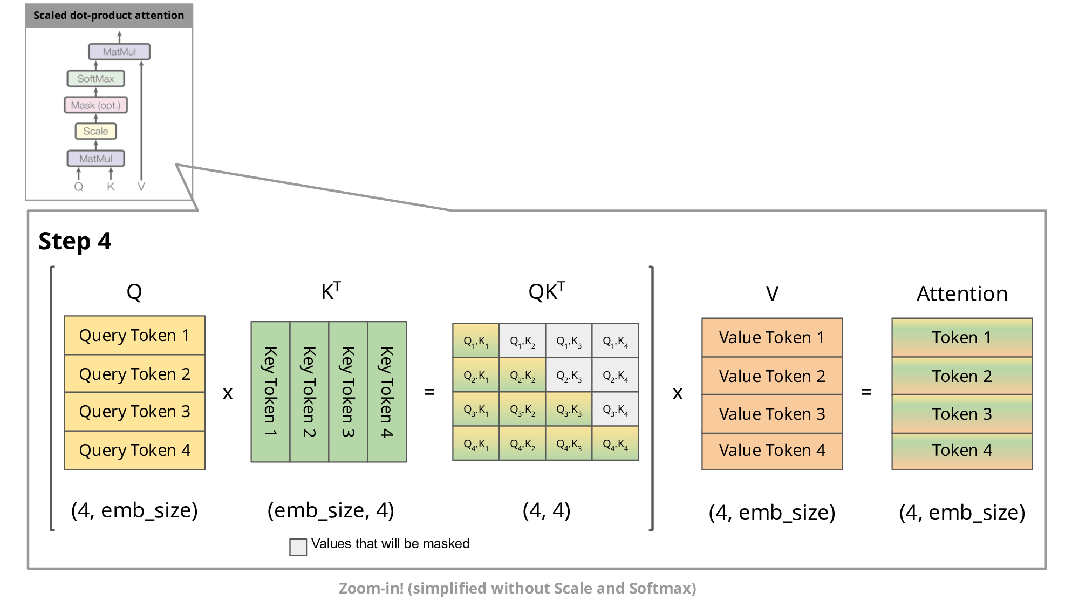
在自回归生成的每个步骤中,系统均需重新计算已经计算过的Key和Value。例如,在第2步中,K1与第1步生成的K1相同。由于在推理阶段模型参数已固定,相同输入将产生相同输出,因此将这些Key和Value存储在缓存中并在后续步骤中复用是更高效的方法。
下图直观展示了KV缓存的工作机制:
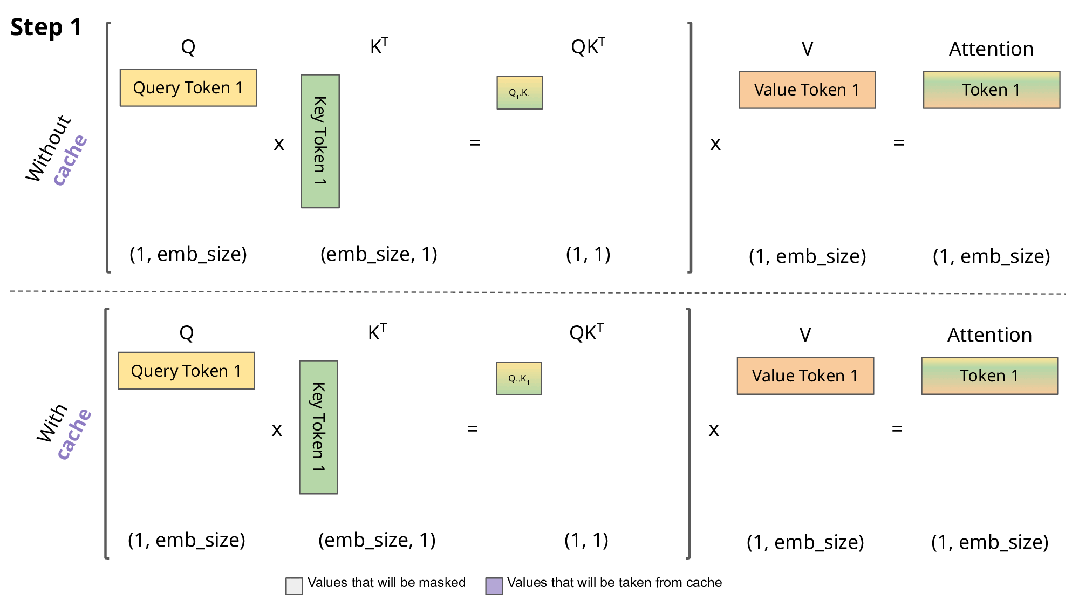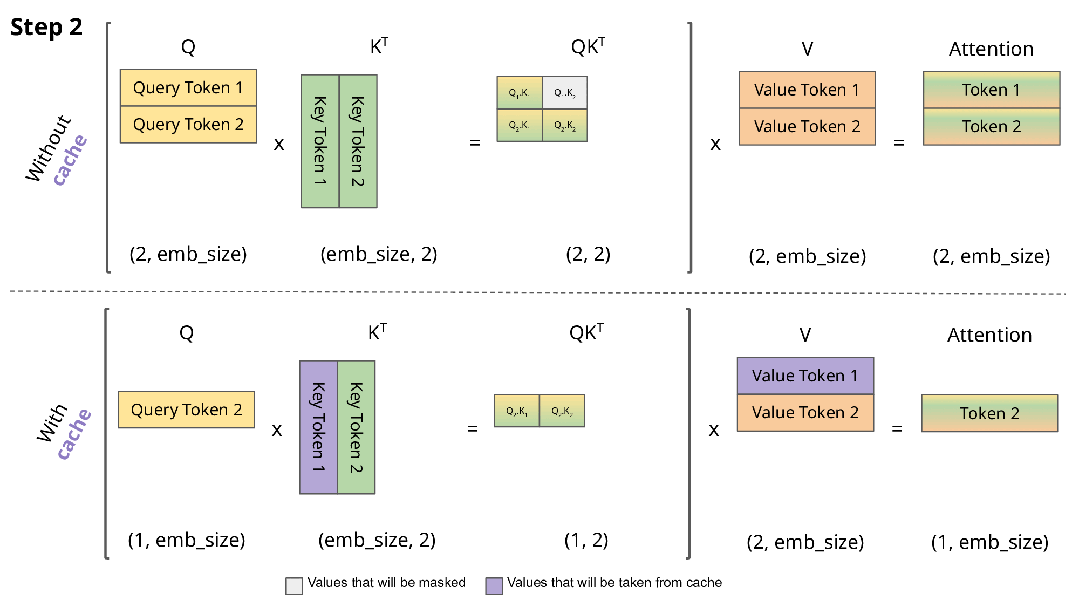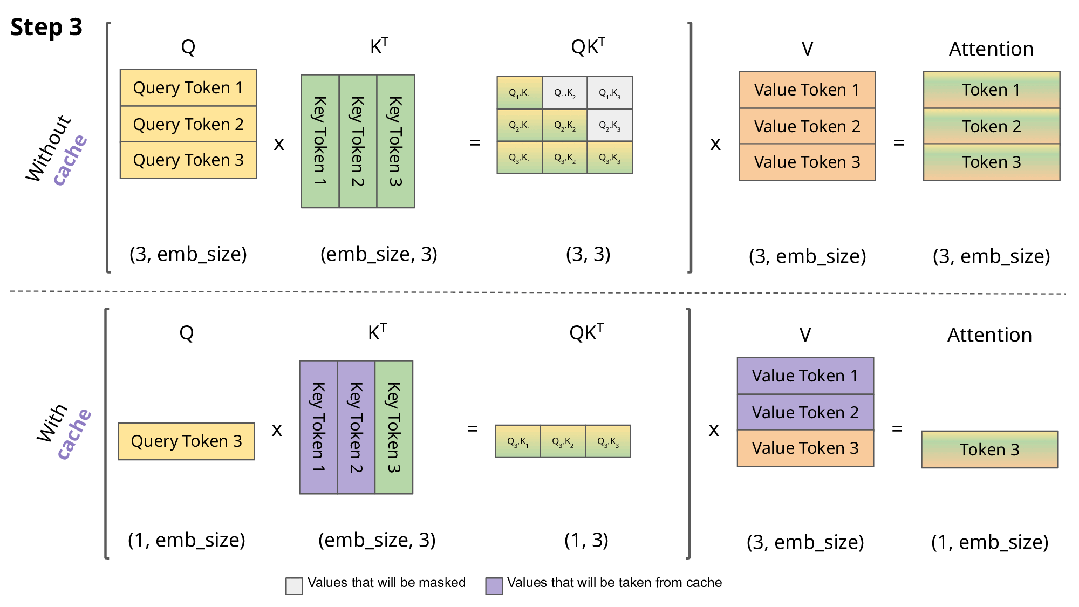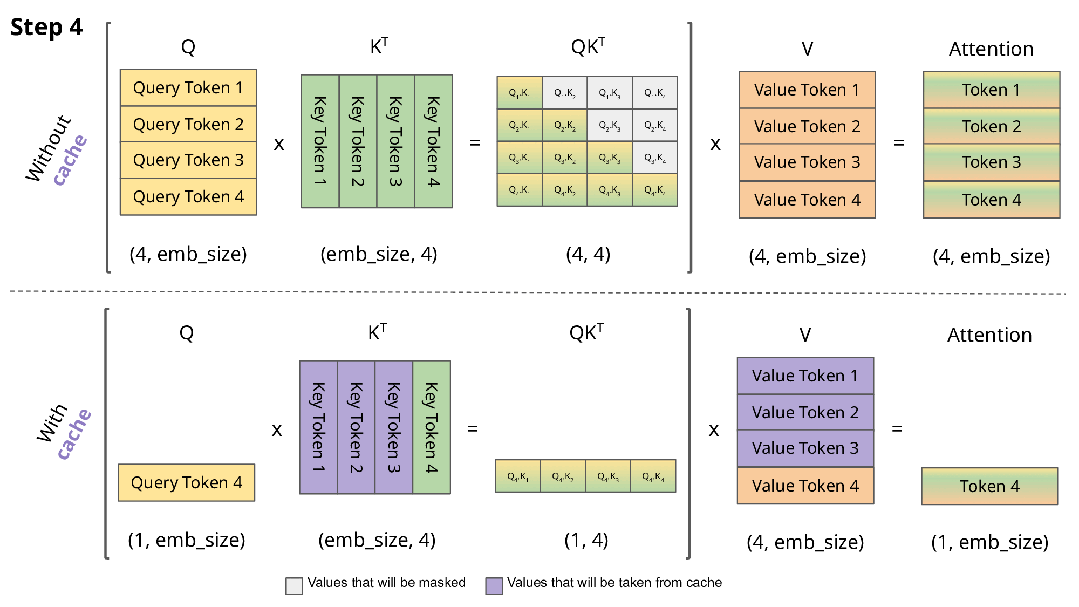
实现KV缓存的主要区别在于:
- 推理时每次仅传入一个新token,而非增量传递所有token
- 由于Key和Value已缓存,无需重复计算历史token的表示
- 无需对权重进行掩码处理,因为每次只处理单个Query token,权重矩阵(QK^T)的维度为(B, 1, T)而非(B, T, T)
缓存机制实现
KV缓存的实现基于形状为(B, T, C)的零张量初始化,其中T为最大处理的token数量(即block_size):
自回归模型在训练时使用固定的上下文长度,即当前token预测下一个token时可回溯的最大token数量。在本实现中,这个上下文长度由
参数确定,表示缓存的最大token数量,通过缓存索引进行跟踪:
从第一个token开始,系统将Key-Value对存入对应的缓存位置,并递增缓存索引直到达到设定的上限:
当缓存索引达到
时,系统会将所有token向前移动一个位置,为新token腾出空间,并将新token分配到最后一个位置:
以上即为KV缓存在注意力机制中的完整实现。接下来我们将分析KV缓存对推理性能的具体影响。
推理性能比较
本节将展示KV缓存优化技术对推理性能的实际影响。以下是实现了KV缓存的GPT模型代码:
generate函数在推理阶段被显式调用,不参与训练过程:
通过执行generate命令可以测量KV缓存对推理性能的影响:
下图展示了标准模型与KV缓存模型在不同生成步数下的推理时间对比,测试模型的序列长度(block_size)为1024,嵌入维度为256:

实验结果表明,KV缓存模型在推理性能上总体优于标准模型,但其效率取决于浮点运算次数(FLOPs),而FLOPs会随着序列长度(block_size)和嵌入维度(embed_size)的增加而增加。对于较小的模型配置(如block_size=8, embed_size=64),标准模型可能更高效。由于计算复杂度随模型大小增加,KV缓存的优势在大型模型中更为明显。有关标准Transformer与KV缓存模型的FLOPs计算详情,可参考Rajan的技术文章[2]。
以下是生成的输出示例:
需要注意的是,生成的文本看似无意义,但这主要是由于计算资源和训练数据的限制,而非KV缓存技术本身的问题。尽管标准模型能生成更接近真实英语的单词,但KV缓存模型仍保留了基本的结构特征,只是输出质量有所降低。
最后,我们使用Hugging Face的预训练GPT-2模型进行了对比测试:
测试结果:
总结
本文详细阐述了KV缓存的工作原理及其在大型语言模型推理优化中的应用,文章不仅从理论层面阐释了KV缓存的工作原理,还提供了完整的PyTorch实现代码,展示了缓存机制与Transformer自注意力模块的协同工作方式。实验结果表明,随着序列长度增加,KV缓存技术的优势愈发明显,在长文本生成场景中能将推理时间降低近60%。这一技术为优化大模型部署提供了一种无需牺牲精度的实用解决方案,为构建更高效的AI应用奠定了基础。
作者:Shubh Mishra