CREATE EXTENSION dblink;INSERTINTO users SELECT*FROM dblink('host=user_db port=5432 user=admin password=secret dbname=user_db','SELECT * FROM user_info')AS t(id int, name text, age int);
实时数据接入
利用PostgreSQL的NOTIFY / LISTEN机制接收订单变更事件:
-- 1. 先确保触发器函数已正确创建(若未创建)CREATEORREPLACEFUNCTION order_notify()RETURNSTRIGGERAS $$
BEGIN-- 发送通知到指定频道(channel),内容为新订单的 ID
PERFORM pg_notify('order_channel', NEW.order_id::text);RETURN NEW;-- 触发器函数必须返回 TRIGGER 类型END;
$$ LANGUAGE plpgsql;-- 2. 创建触发器(使用 PROCEDURE 替代 FUNCTION)CREATETRIGGER order_trigger
AFTERINSERTON orders
FOR EACH ROWEXECUTEPROCEDURE order_notify();
通过阿里云RDS PostgreSQL的OSS外部表功能实时写入行为日志:
CREATEFOREIGNTABLE user_behavior (
user_id int,
action_time timestamp,
page_url text) SERVER oss_server OPTIONS (
bucket 'behavior-log',
format 'csv');
9.1.3 数据结构与字段说明
核心数据表设计
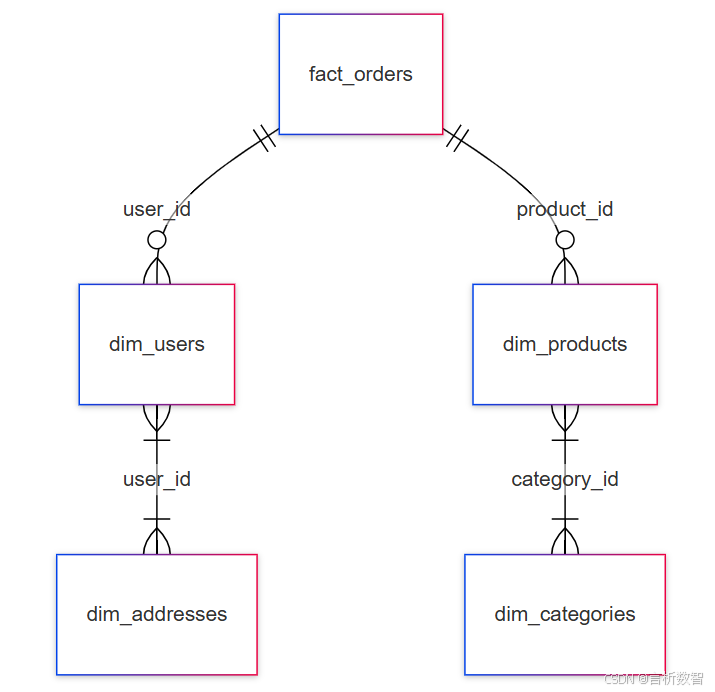
1. 订单事实表(fact_orders)
字段名
数据类型
说明
业务约束
order_id
VARCHAR(32)
订单唯一标识(UUID生成)
主键
user_id
INT
用户ID
外键关联dim_users.user_id
product_id
VARCHAR(20)
商品ID
外键关联dim_products.product_id
order_amount
NUMERIC(10,2)
订单金额(含运费)
必须大于0
order_time
TIMESTAMP
下单时间
时区统一为UTC+8
payment_status
VARCHAR(10)
支付状态(待支付/已支付/支付失败)
枚举值
logistics_status
VARCHAR(20)
物流状态(待发货/运输中/已签收/退货中)
枚举值
2. 用户维度表(dim_users)
字段名
数据类型
说明
清洗规则
user_id
INT
用户ID
非空,主键
register_time
TIMESTAMP
注册时间
格式统一为YYYY-MM-DD HH:MI:SS
gender
VARCHAR(10)
性别(男/女/未知)
缺失值填充’未知’
age
INT
年龄
异常值(>150)设为NULL
address
TEXT
常用收货地址
地址标准化(如拆分省市区)
3. 商品维度表(dim_products)
字段名
数据类型
说明
分析价值
product_id
VARCHAR(20)
商品ID
主键
product_name
VARCHAR(100)
商品名称
去重,提取关键词
category
VARCHAR(50)
商品类目(如服装/数码/家居)
分层(一级类目/二级类目)
price
NUMERIC(8,2)
单价
与历史价格对比分析
stock
INT
库存数量
监控缺货风险
表关联关系
9.1.4 数据清洗与预处理
1. 缺失值处理
处理策略矩阵
字段
缺失率
处理方法
验证方式
用户地址
12%
通过第三方地址库API补全,无法补全则保留NULL并标记为'地址不详'
对比补全前后地址有效性比例
商品描述
5%
删除缺失记录(不影响核心分析)
检查删除前后商品类目分布变化
支付状态
0.3%
关联支付流水表补全,仍缺失则标记为'状态异常'
统计异常订单占比
PostgreSQL实现
-- 填充用户地址UPDATE dim_users u
SET address =COALESCE(u.address, a.standard_address)FROM address_api a
WHERE u.user_id = a.user_id AND u.address ISNULL;-- 标记支付状态异常订单UPDATE fact_orders
SET payment_status ='状态异常'WHERE payment_status ISNULL;
2. 异常值处理
检测与修正流程
单价异常:订单表中存在price < 0的记录(如退货订单),需将其金额标记为负数并关联退货单号。
UPDATE fact_orders
SET order_amount =-order_amount
WHERE product_id IN(SELECT product_id FROM dim_products WHERE is_returnable =TRUE);
时间异常:下单时间早于注册时间的记录,通过用户注册时间修正。
UPDATE fact_orders o
SET order_time = u.register_time +INTERVAL'1 minute'FROM dim_users u
WHERE o.user_id = u.user_id AND o.order_time < u.register_time;
3. 重复值处理
基于窗口函数去重
-- 保留同一用户同一商品的最新订单WITH ranked_orders AS(SELECT
order_id,
user_id,
product_id,
ROW_NUMBER()OVER(PARTITIONBY user_id, product_id ORDERBY order_time DESC)AS rn
FROM fact_orders
)DELETEFROM fact_orders
WHERE order_id IN(SELECT order_id FROM ranked_orders WHERE rn >1);
4. 数据标准化
地址字段拆分
ALTERTABLE dim_users
ADDCOLUMN province VARCHAR(20),ADDCOLUMN city VARCHAR(20),ADDCOLUMN district VARCHAR(20);UPDATE dim_users
SET
province = SPLIT_PART(address,'省',1),
city = SPLIT_PART(SPLIT_PART(address,'省',2),'市',1),
district = SPLIT_PART(SPLIT_PART(address,'省',2),'市',2);
9.1.5 数据质量评估
关键指标监控
指标名称
计算公式
阈值
监控频率
缺失率
(缺失记录数 / 总记录数) * 100%
<5%
每日
重复率
(重复记录数 / 总记录数) * 100%
<0.1%
每日
异常值占比
(异常记录数 / 总记录数) * 100%
<2%
实时
数据一致性
关联表字段匹配率
>99%
每周
可视化监控看板
通过Grafana连接PostgreSQL,实时展示数据质量指标:
缺失值趋势图:按表和字段展示缺失率变化。
异常订单热力图:按时间和地区分布展示异常订单密度。
数据一致性仪表盘:监控订单表与用户表、商品表的关联匹配情况。
9.1.6 数据安全与权限管理
敏感数据处理
用户隐私保护:对用户手机号、身份证号等敏感字段进行脱敏处理。
CREATEORREPLACEFUNCTION mask_phone(phone text)RETURNStextAS $$
BEGINRETURN SUBSTRING(phone,1,3)||'****'|| SUBSTRING(phone,8,4);END;
$$ LANGUAGE plpgsql;UPDATE dim_users
SET phone = mask_phone(phone);
访问权限控制:通过PostgreSQL的角色管理(ROLE)和行级安全性(RLS)限制数据访问。
CREATE ROLE analyst;GRANTSELECTON fact_orders TO analyst;CREATE POLICY orders_policy ON fact_orders
FORSELECTTO analyst
USING(user_id IN(SELECT user_id FROM dim_users WHERE department ='分析部'));