效果一览
基本介绍
基本介绍
基于SHAP分析的特征选择和贡献度计算,Matlab2023b代码实现;基于MATLAB的SHAP可解释Transformer编码器回归模型,敏感性分析方法。
详细介绍
引言
在正向渗透(Forward Osmosis, FO)过程中,水通量的精准预测对于优化膜分离工艺和提升系统效率具有重要工程意义。然而,传统机理模型常受限于复杂的传质动力学方程,难以兼顾预测精度与可解释性。本研究提出一种融合Transformer编码器与SHapley加性解释(SHAP)的混合建模框架,旨在构建高精度且可解释的回归模型,以解析操作参数对水通量的非线性影响机制。该模型以膜面积、进料/汲取液流速及浓度等关键操作参数为输入特征,通过SHAP方法量化特征贡献,为工艺优化提供透明化决策支持。方法论
2.1 数据准备与预处理
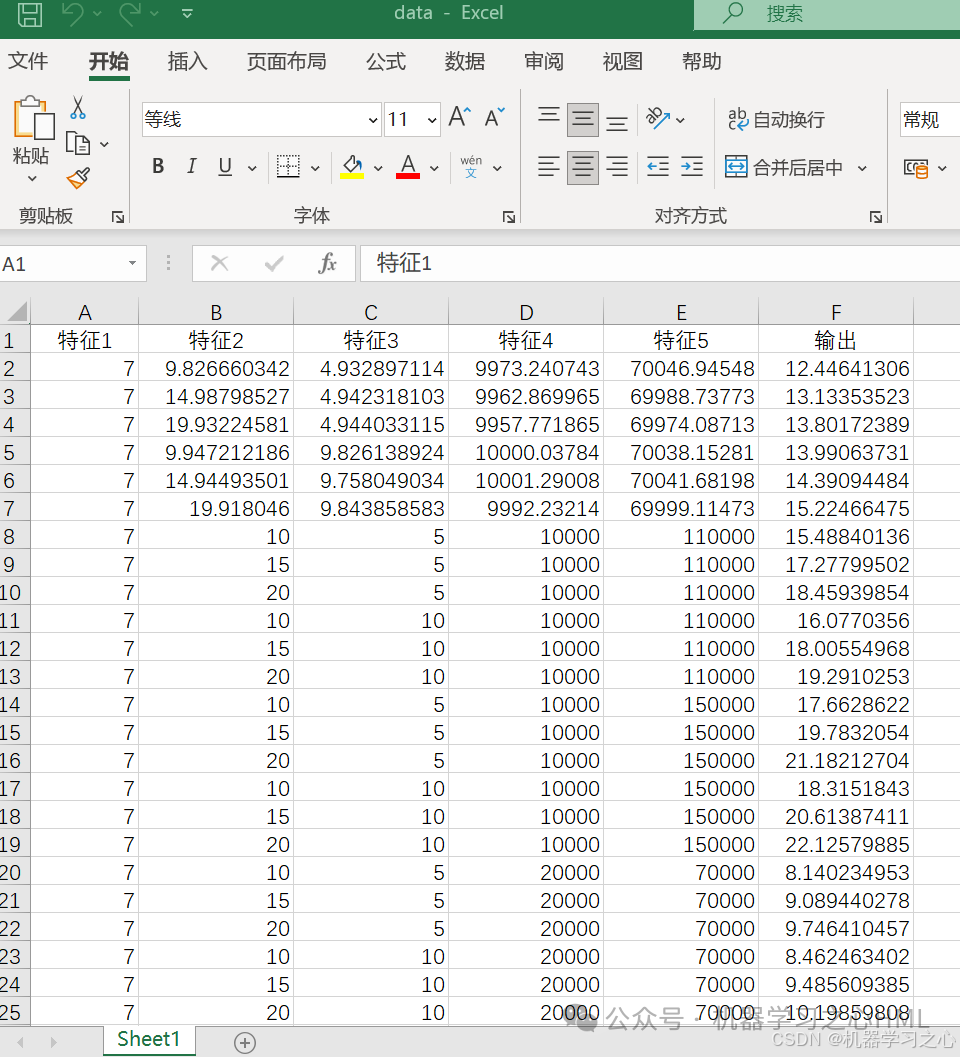
实验数据采集自FO工艺数据库,包含六维参数(5输入特征,1输出目标)。输入特征涵盖膜面积、进料流速、汲取液流速、进料浓度及汲取液浓度。数据经归一化处理,以消除量纲差异。
2.2 Transformer编码器构建与训练
Transformer架构:
位置编码(Position Embedding):为序列数据添加位置信息,弥补自注意力机制对位置不敏感的缺陷。
自注意力层(Self-Attention):捕捉输入序列中不同位置间的全局依赖关系,通过多头注意力机制(4个头)增强模型表达能力。
全连接层(Fully Connected Layer):将高维特征映射到目标输出维度(回归任务)。
采用MATLAB R2023b实现Transformer编码器架构。使用Adam优化器,结合学习率衰减(初始学习率1e-3,450轮后衰减为初始值的10%)和L2正则化(系数1e-4)防止过拟合。
2.3 SHAP可解释性分析
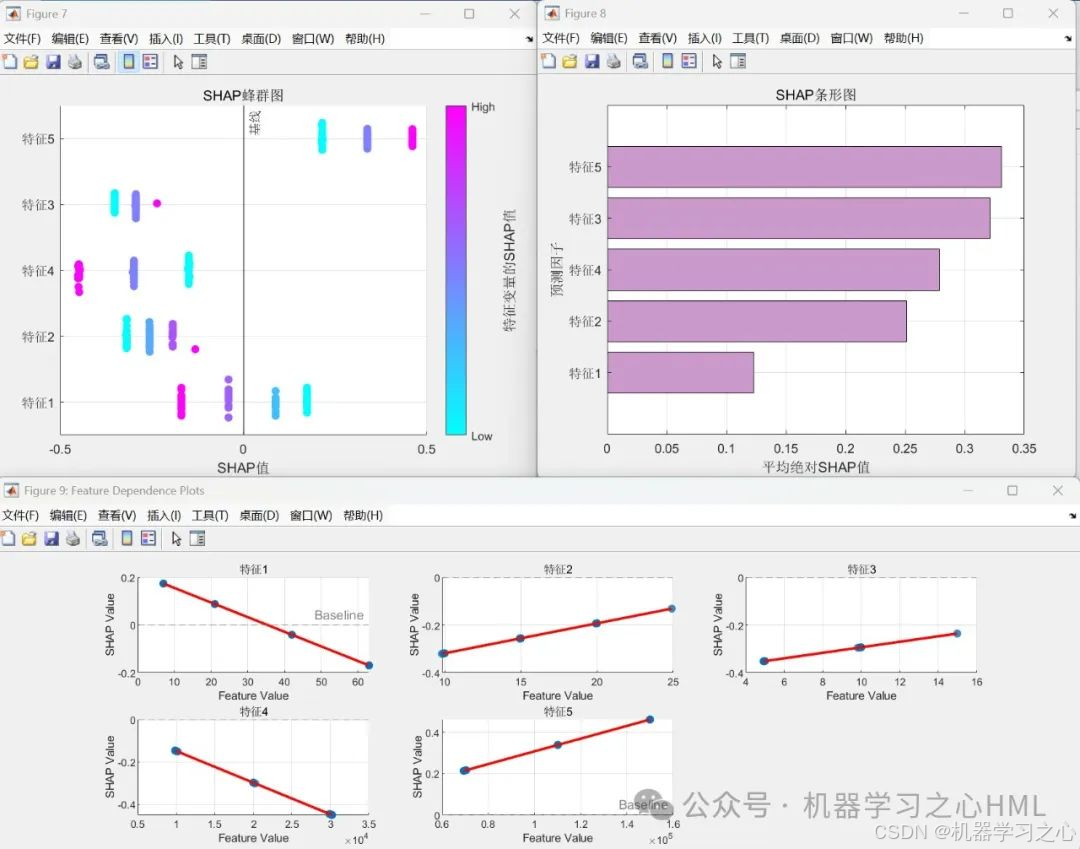
SHAP值基于合作博弈论中的Shapley值理论,量化特征对模型预测的边际贡献。通过Shapley值量化每个特征对预测结果的贡献,提供模型可解释性。

- 结论
本研究成功构建了基于Transformer编码器与SHAP的可解释回归模型,实现了FO水通量的高精度预测与特征贡献解析。方法学创新体现于:引入SHAP方法打破黑箱限制,提供全局及局部双重解释视角。
实现步骤
数据准备:
导入数据并随机打乱。
划分训练集和测试集,归一化至[0, 1]区间。
调整数据格式为序列输入(reshape和cell格式)。
模型构建:
定义输入层、位置编码层、自注意力层和全连接层。
通过加法层将输入与位置编码相加。
训练与预测:
使用trainNetwork进行模型训练。
预测结果反归一化后计算误差指标。
可视化与解释:
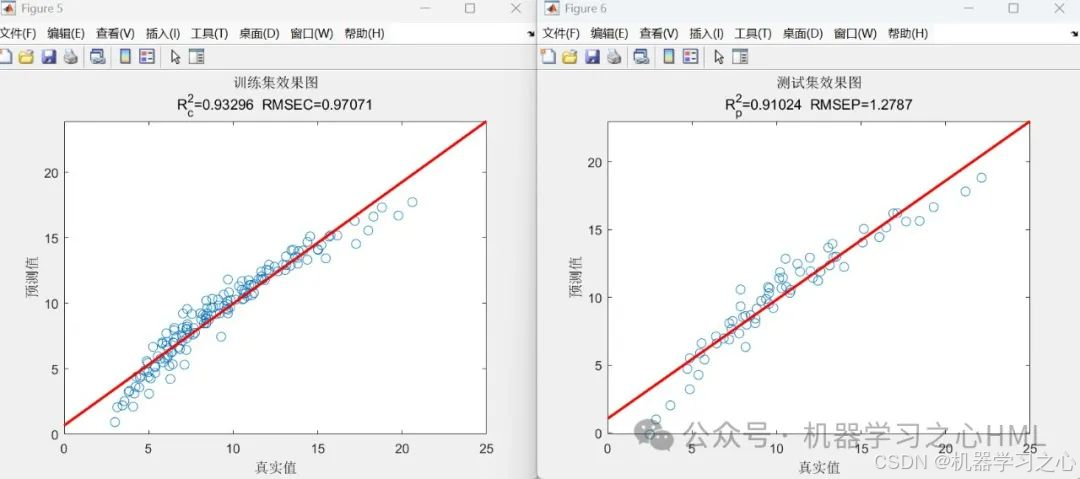
绘制预测结果对比图、误差分布图及线性拟合图。
计算SHAP值并生成特征重要性图和依赖图。
应用场景
回归预测任务:适用于需要预测连续值的场景,如:
时序预测(股票价格、能源需求、气象数据)。
工业预测(设备寿命、产量预测)。
商业分析(销售额、用户行为预测)。
需解释性的场景:SHAP分析可帮助理解特征影响,适用于:
金融风控(解释贷款违约风险的关键因素)。
医疗诊断(分析生理指标对疾病预测的贡献)。
科学研究(识别实验数据中的关键变量)。
数据集
程序设计
- 完整程序和数据下载私信博主回复Matlab也能实现可解释编码器了!Transformer编码器+SHAP分析,模型可解释创新表达!。
源码结构
数据预处理与划分:导入数据并划分为训练集(70%)和测试集(30%),进行归一化处理以适应模型输入。
模型构建:搭建基于Transformer的神经网络结构,包含位置编码、自注意力机制和全连接层。
模型训练与预测:使用Adam优化器训练模型,并在训练集和测试集上进行预测。
性能评估:计算R²、MAE、MAPE、MSE、RMSE等回归指标,并通过图表展示预测结果与真实值的对比。
模型解释:通过SHAP(Shapley值)分析特征重要性,生成摘要图和依赖图,增强模型可解释性。
.rtcContent { padding: 30px; } .lineNode {font-size: 10pt; font-family: Menlo, Monaco, Consolas, "Courier New", monospace; font-style: normal; font-weight: normal; }
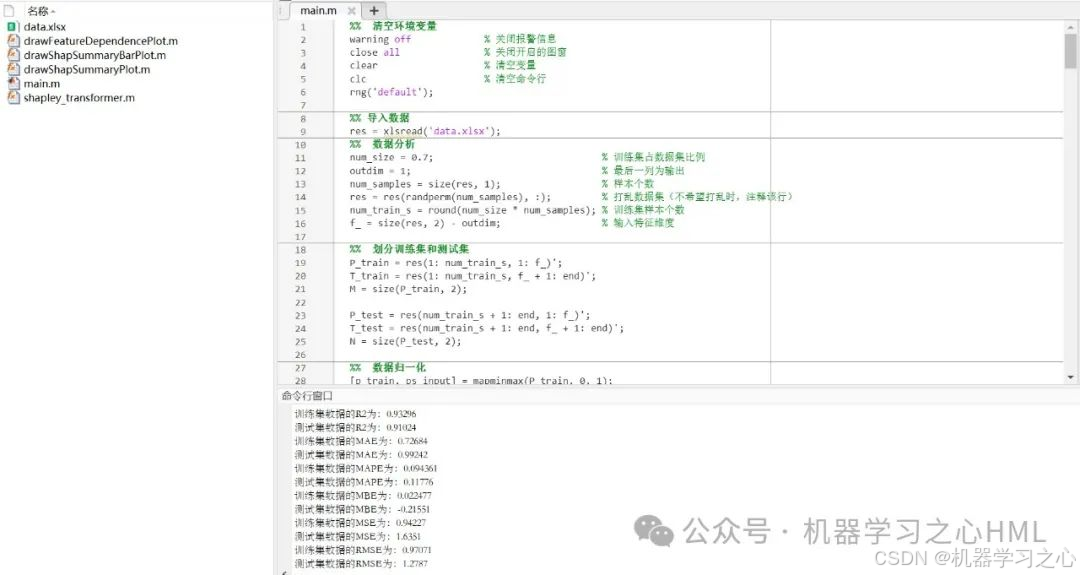
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行
rng('default');
%% 导入数据
res = xlsread('data.xlsx');
%% 数据分析
num_size = 0.7; % 训练集占数据集比例
outdim = 1; % 最后一列为输出
num_samples = size(res, 1); % 样本个数
res = res(randperm(num_samples), :); % 打乱数据集(不希望打乱时,注释该行)
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
% ------------------ SHAP值计算 ------------------
x_norm_shap = mapminmax('apply', data_shap', x_settings)'; % 直接应用已有归一化参数
% 初始化SHAP值矩阵
shapValues = zeros(size(x_norm_shap));
refValue = mean(x_norm_shap, 1); % 参考值为特征均值
% 计算每个样本的SHAP值
rtcContent { padding: 30px; } .lineNode {font-size: 10pt; font-family: Menlo, Monaco, Consolas, "Courier New", monospace; font-style: normal; font-weight: normal; }
for i = 1:numSamples
x = shap_x_norm(i, :); % 当前样本(归一化后的值)
shapValues(i, :) = shapley_transformer(net, x, refValue_norm); % 调用SHAP函数
end
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/128163536?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/kjm13182345320/article/details/128151206?spm=1001.2014.3001.5502