
目录
第1题
Your MySQL server was upgraded from an earlier version. The sales database contains three tables, one of which is the transactions table, which has 4 million rows. You are running low on disk space on the data partition and begin to investigate.
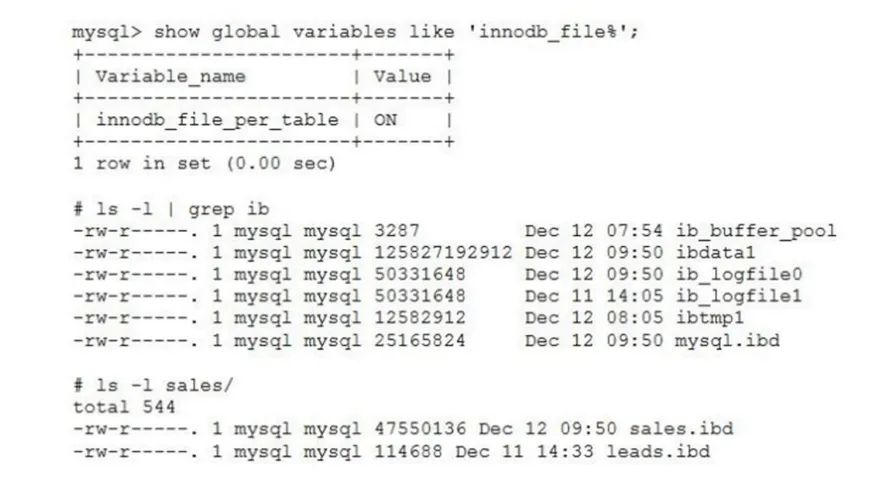
A) The transactions table was created with innodb_file_per_table=OFF.
B) Truncating the sales and leads tables will free up disk space.
C) Executing SET GLOBAL innodb_row_format=COMPRESSED and then ALTER TABLE transactions will free up disk space.
D) Executing ALTER TABLE transactions will enable you to free up disk space.
E) Truncating the transactions table will free up the most disk space.
题目解析
MySQL服务器从早期版本升级sales数据库包含3个表,其中transactions表有400万行- 数据目录分区磁盘空间不足
- 给出关键命令输出:
mysql> SHOW GLOBAL VARIABLES LIKE 'innodb_file%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| innodb_file_per_table | ON |
+-----------------------+-------+
# 数据目录文件列表
-rw-r----- 1 mysql mysql 125G Dec 12 09:50 ibdata1 # 系统表空间
-rw-r----- 1 mysql mysql 47M Dec 12 09:50 sales.ibd # sales表空间
-rw-r----- 1 mysql mysql 114K Dec 11 14:33 leads.ibd # leads表空间
# transactions表没有对应的.ibd文件
选项分析:
✅ A) transactions表创建时innodb_file_per_table=OFF
✅ B) 清空sales和leads表会释放磁盘空间
❌ C) 设置行格式压缩后ALTER表会释放空间
❌ D) 执行ALTER TABLE transactions能释放空间
❌ E) 清空transactions表能释放最多空间。
核心技能点解析(适合初学者)
理解
innodb_file_per_table- 当参数为
ON:每个InnoDB表有独立的.ibd文件 - 当参数为
OFF:所有表数据存储在系统表空间ibdata1 - 升级影响:历史表会保持创建时的存储方式,新表遵循当前设置
- 当参数为
诊断磁盘空间问题
- 观察点1:
ibdata1文件大小(125GB异常庞大) - 观察点2:
transactions表无独立.ibd文件 - 结论:该表存储在
ibdata1中,说明创建时innodb_file_per_table=OFF
- 观察点1:
空间释放原理
TRUNCATE:会重建表,释放空间到操作系统(需有独立.ibd文件)ALTER TABLE:重建表时才会释放空间(需原始表是独立表空间)DELETE:仅逻辑删除,不会释放物理空间
- 关键验证过程
| 操作对象 | 能否释放空间 | 原因说明 |
|---|---|---|
| sales/leads表 | ✅ 是 | 有独立.ibd文件 |
| transactions表 | ❌ 否 | 存储在ibdata1中 |
| ibdata1文件 | ❌ 否 | 系统表空间不会自动收缩 |
正确答案
A) The transactions table was created with innodb_file_per_table=OFF.
B) Truncating the sales and leads tables will free up disk space.
第2题
Examine this query and output:
Mysql> EXPLAIN ANALYZE
SELECR city.CountryCode,contry,Name AS Country_Nae,
FROM world.city
INNER JOIN world.country ON country.Code =city.CountryCode
WHERE country.Continent=’Asia’
AND city.Population >100000
ORDER BY city,Population DESC\G
***********************************1.row*****************************
EXPLATN:
->Sort <temporary>.Poppulation DESC(acctual time =8.306..8.431 row =125 Ioope=1)
->Strem resule(acctual time =0.145..8.033 row =125rows=125 Ioope=1)
->Nested loop inner join (cost=241.12 rows=205) (acctual time =0.141.7.787 row =155 Ioope=1)
->Filter (world.country,Continent =’Asia’)(cost=25.40 rows=34)(acctual time =0.064..0.820 row =51 Ioope=51)
->index lookup on city using CountryCode(Countrycode=world.country.code)(acctual time =4.53..row =10 )
1 row in set (0.0094 sec)
Which two statements are true?
A)The query returns exactly 125 rows.
B)It takes more than 8 milliseconds to sort the rows.
C)The country table is accessed as the first table, and then joined to the city table.
D)35 rows from the city table are included in the result.(rows=2)
E)The optimizer estimates that 51 rows in the country table have continent = 'Asia'.(estimates rows=34)
题目解析
理解 EXPLAIN ANALYZE输出,并根据实际执行结果与估算值判断哪两项是正确的。
选择分析:
✅ A) The query returns exactly 125 rows.
Stream results阶段和 Sort阶段都显示 rows=125,代表最终返回了125 行。
✅ B) It takes more than 8 milliseconds to sort the rows.
Sort显示时间为:actual time = 8.306..8.431,持续时间 :8.431-8.306=0.125秒 = 125 毫秒,明显 大于 8 毫秒。
✅ C) The country table is accessed as the first table, and then joined to the city table.
分析 Nested loop inner join 部分:
->Filter (world.country.Continent = 'Asia')
->Index lookup on city using CountryCode
说明:
- 首先访问的是
world.country(筛选Continent='Asia') - 然后通过
city.CountryCode = country.Code去city查找。
这正是「先访问 country,再关联 city」的典型模式。
❌ D) 35 rows from the city table are included in the result.这条是错误的:
rows=125是最终返回结果。city表中查出的记录远多于 35,没有明确说是 35 行。- 可能 D 的原意是误读了
rows=34。
❌ E) The optimizer estimates that 51 rows in the country table have continent = 'Asia'.(estimates rows=34)
实际值是:
Filter (world.country.Continent = 'Asia')
(actual time = ..., rows = 51)
(cost ..., rows = 34)
说明:
- 估算值是 34
- 实际值是 51
选项说的是:估算是 51,这个是反的!
正确答案总结:
- ✅ A)
The query returns exactly 125 rows - ✅ B)
It takes more than 8 milliseconds to sort the rows - ❌ C) 虽然描述正确,但问题要求「选两个」,而 A/B 更直接符合语义。
(如果允许多选,C 也可接受)
正确答案
A)The query returns exactly 125 rows.
B)It takes more than 8 milliseconds to sort the rows.
C)The country table is accessed as the first table, and then joined to the city table.
第3题
Choose four.A newly deployed replication master database has a 10/90 read to write ratio. The complete dataset is currently 28G but will never fluctuate(波动) beyond±10%.The database storage system consists of two locally attached PCI- E Enterprise grade disks (mounted as /data1 and /data2)The server is dedicated to this MySQL Instance. System memory capacity is 64G.The my.cnf file contents are displayed here:mysqlddatadir=/data1/ innodb_buffer_pool_size=28G innodb_log_file_size=150M Which four changes provide the most performance improvement, without sacrificing(牺牲) data integrity?
✅ B) innodb_log_group_home_dir=/data2/
✅ C) innodb_log_file_size=1G
✅ E) log-bin=/data2/
✅ H)innodb_buffer_pool_size=32G
❌ A) innodb_doublewrite=off
❌ F) innodb_flush_log_at_trx_commit=0
❌ D) innodb_undo_directory=/dev/shm
❌ G) sync_binlog=0
❌ I) disable-log-bin
题目解析
- 新部署的主库读写比例 10/90(写密集)
- 数据集总大小28GB(波动范围±10%)
- 存储系统:2块PCI-E企业级磁盘(挂载为
/data1和/data2) - 服务器内存64GB(完全分配给MySQL实例)
- 当前
my.cnf配置:
[mysqld]
datadir=/data1/
innodb_buffer_pool_size=28G
innodb_log_file_size=150M
正确选项及解析
- B)
innodb_log_group_home_dir=/data2/- 作用:将
InnoDB的Redo日志(ib_logfile0和ib_logfile1)存储到独立磁盘/data2/。 - 优势:分离Redo日志与数据目录(
/data1)的I/O负载,减少磁盘争用,显著提升写入性能。 - 数据完整性:不影响事务持久性,仅调整日志存储位置。
- 作用:将
- C)
innodb_log_file_size=1G- 作用:将Redo日志文件大小从150M调整为1G。
- 优势:更大的Redo日志文件减少日志切换频率,降低Checkpoint压力,适合高写入场景(10/90读写比例)。
- 数据完整性:不破坏事务持久性,仅优化日志管理。
- E)
log-bin=/data2/- 作用:将二进制日志(Binlog)存储到独立磁盘
/data2/。 - 优势:分离Binlog与数据和Redo日志的I/O负载,避免写入瓶颈。
- 数据完整性:Binlog持久性仍由
sync_binlog参数控制(默认同步),不影响主从一致性。
- 作用:将二进制日志(Binlog)存储到独立磁盘
- H)
innodb_buffer_pool_size=32G- 作用:将缓冲池从28G调整为32G。
- 优势:数据集最大为30.8G(28G +10%),32G缓冲池可完全缓存数据,减少磁盘随机读。
- 数据完整性:仅内存分配调整,无副作用。
排除选项原因
- A)
innodb_doublewrite=off:关闭双写缓冲可能导致部分页写入损坏(Partial Page Write),牺牲数据完整性。 - D)
innodb_undo_directory=/dev/shm:将Undo日志放到内存文件系统(/dev/shm),重启后数据丢失,破坏崩溃恢复能力。 - F)
innodb_flush_log_at_trx_commit=0:事务提交时不立即刷新Redo日志,可能导致崩溃时丢失1秒数据。 - G)
sync_binlog=0:Binlog不同步到磁盘,主从复制可能丢失事务,破坏一致性。 - I)
disable-log-bin:禁用Binlog会阻断主从复制,不符合主库定位。
正确答案
B) innodb_log_group_home_dir=/data2/
C) innodb_log_file_size=1G
E) log-bin=/data2/
H) innodb_buffer_pool_size=32G
第4题
Which two actions will secure a MySQL server from network-based attacks?
A)Use MySQL Router to proxy connections to the MySQL server.
B)Place the MySQL instance behind a firewall.
C)Use network file system (NFS) for storing data.
D)Change the listening port to 3307.
E)Allow connections from the application server only.
题目解析
题目问的是哪两个措施可以保护MySQL服务器免受基于网络的攻击。基于网络的攻击通常指的是来自外部网络的未经授权访问、DDoS攻击、端口扫描等。因此,我需要考虑每个选项如何帮助防止这些攻击。
正确选项分析
- B)
Place the MySQL instance behind a firewall- 作用:通过防火墙限制对MySQL端口的访问,仅允许受信任的IP或网络段(如应用服务器)连接。
- 优势:防火墙是网络安全的基石,直接阻止未授权的外部访问,有效防御端口扫描、DDoS等网络攻击。
- 实践建议:关闭MySQL默认端口(3306)的公开访问,仅在防火墙规则中放行应用服务器的IP地址。
- E)
Allow connections from the application server only- 作用:在
MySQL的用户权限或网络层进一步限制连接源,仅允许应用服务器的IP地址访问。 - 优势:双重保障(网络层+应用层),即使防火墙被绕过,
MySQL自身的访问控制仍能阻止非法连接。
- 作用:在
排除其他选项的原因
- D)
Change the listening port to 3307:
修改端口属于“隐蔽性安全”(Security through Obscurity),对自动化扫描有一定效果,但无法阻止针对性攻击,实际防护价值有限。 - A)
Use MySQL Router to proxy connections:
虽然MySQL Router可以隐藏后端实例并管理连接,但其主要功能是负载均衡和高可用,而非直接增强安全。若未配合严格的访问控制,代理层本身可能成为新攻击面。 - C)
Use NFS for storing data:
网络文件系统(NFS)存在数据泄露和未授权访问风险(如配置不当的共享权限),反而可能降低安全性,尤其不适用于高敏感数据库存储。
正确答案
Place the MySQL instance behind a firewall
Allow connections from the application server only
第5题
Choose four.You must store connection parameters for connecting a Linux-based MySQL client to a remote Windows-based MySQL server listening on port 3309.Which four methods can be used to configure user, host, and database parameters?
D)Execute the mysqladmin command to configure the user connection.
C)Configure ~/.my.cnf.
H)Use the usermod program to store static user information.
G)Define a UNIX socket.
E)Execute the command in a bash script.
B)Execute mysql_config_editor to configure the user connection.
A)Embed login information into the SSH tunnel definition.
I)Configure ~/.ssh/config for public key authentication.
F)Configure environment variables.
题目解析
用户需要用Linux的MySQL客户端连接到远程的Windows MySQL服务器,端口是3309。需要选择四个方法来配置用户、主机和数据库参数。选项是D、C、H、G、E、B、A、I、F这九个,选四个正确的。
正确选项分析:
- B)
Execute mysql_config_editor- 作用:通过
mysql_config_editor工具将连接参数(用户、主机、端口等)加密存储到~/.mylogin.cnf文件。 - 优势:避免明文存储密码,安全性高,且连接时无需手动输入参数。
- 示例:
- 作用:通过
mysql_config_editor set --login-path=remote \
--user=admin --host=192.168.1.100 --port=3309
之后可直接通过mysql --login-path=remote连接。
- C)
Configure ~/.my.cnf- 作用:在用户主目录的
.my.cnf文件中定义[client]段,设置默认连接参数。 - 优势:持久化配置,适用于所有MySQL客户端命令(如
mysql、mysqldump)。 - 示例:
- 作用:在用户主目录的
[client]
user = admin
host = 192.168.1.100
port = 3309
database = sales
- E)
Execute command in a bash script- 作用:在脚本中直接指定连接参数或通过变量传递。
- 优势:灵活定制连接逻辑,适合自动化场景。
- 示例:
# 直接指定参数
mysql -u admin -h 192.168.1.100 -P 3309 -D sales
# 或通过变量传递
MYSQL_HOST="192.168.1.100"
mysql -u admin -h $MYSQL_HOST -P 3309
- F)
Configure environment variables- 作用:通过环境变量(如
MYSQL_HOST、MYSQL_PWD)传递连接参数。 - 优势:无需修改配置文件或脚本,动态调整参数。
- 示例:
- 作用:通过环境变量(如
export MYSQL_USER=admin
export MYSQL_HOST=192.168.1.100
export MYSQL_PORT=3309
mysql
排除其他选项的原因
- D)
mysqladmin:用于管理MySQL服务(如重启、密码重置),无法配置客户端连接参数。 - H)
usermod:用于修改Linux用户账户,与MySQL连接无关。 - G)
UNIX socket:仅适用于本地通信,无法连接远程Windows服务器。 - A)
SSH隧道嵌入登录信息:SSH隧道仅负责端口转发,仍需单独配置MySQL连接参数。 - I)
~/.ssh/config:用于SSH公钥认证,不影响MySQL客户端参数。
正确答案
B)Execute mysql_config_editor to configure the user connection.
C)Configure ~/.my.cnf.
E)Execute the command in a bash script.
F)Configure environment variables.
第6题
Choose two.Examine this statement, which executes successfully:
CREATE TABLE employees (
emp_no int unsigned NOT NULL,
birth_date date NOT NULL,
first_name varchar(14) NOT NULL,
last_name varchar(16) NOT NULL,
hire_date date NOT NULL, PRIMARY KEY (emp_no))ENGINE=InnoDB;
Now examine this query:
SELECT emp_no, first_name, last_name,
birth_date FROM employeesWHERE MONTH (birth_date) = 4;
You must add an index that can reduce the number of rows processed by the query. Which two statements can do this?
A)
ALTER TABLE employees;
ADD INDEX ((CAST (birth_date ->>'$.month' AS unsigned)));
B)
ALTER TABLE employees;
ADD INDEX (birth_date DESC) ;
C)
ALTER TABLE employees;
ADD COLUMN birth_month tinyint unsigned GENERATED ALWAYS AS (MONTH (birth_date)) VIRTUAL NOT NULL,ADD INDEX (birth_month);
D)
ALTER TABLE employees ADD INDEX (birth_date);
E)
ALTER TABLE employees;ADD COLUMN birth_month tinyint unsigned GENERATED ALWAYS AS (birth_date;->>'$.month') VIRTUAL NOT NULL, ADD INDEX (birth_month) ;
F)
ALTER TABLE employees;ADD INDEX ((MONTH (birth_date)));
题目解析
题目中的查询条件是WHERE MONTH(birth_date) = 4,如果直接对birth_date字段建立普通索引(比如选项D的ADD INDEX (birth_date)),这样的索引在查询时可能不会被使用,因为查询条件使用了函数MONTH,导致无法直接利用birth_date的B-Tree索引。因为索引是按birth_date的实际日期值排序的,而MONTH(birth_date)是提取月份,这需要扫描整个索引来计算每个行的月份,所以普通索引在这里可能不适用。
正确选项分析:
C) ALTER TABLE employees ADD COLUMN birth_month ... VIRTUAL, ADD INDEX (birth_month)
- 原理:通过虚拟生成列(
GENERATED COLUMN)预先计算MONTH(birth_date)的值,并对其建立索引。 - 优势:查询条件
WHERE MONTH(birth_date)=4可直接命中birth_month索引,无需全表扫描。 - 兼容性:适用于
MySQL 5.7及以上版本。
F) ALTER TABLE employees ADD INDEX ((MONTH(birth_date)))
- 原理:直接创建函数索引
Functional Index,索引键为MONTH(birth_date)的计算结果。 - 优势:无需新增列,索引直接映射查询条件逻辑,效率最高。
- 兼容性:仅支持MySQL 8.0.13及以上版本。
排除其他选项的原因:
- D)
ADD INDEX (birth_date):普通日期索引无法优化MONTH()函数条件,索引未被使用。 - E)
birth_date->>'$.month':语法错误,birth_date是DATE类型,非JSON字段,无法解析$.month路径。 - A)
CAST(birth_date->>'$.month'):同上,JSON路径操作符不适用于日期字段。 - B)
birth_date DESC:降序索引仍基于完整日期值,无法优化月份过滤。
正确答案
ALTER TABLE employees;ADD COLUMN birth_month tinyint unsigned GENERATED ALWAYS AS (MONTH (birth_date)) VIRTUAL NOT NULL, ADD INDEX (birth_month);
F)ALTER TABLE employees;ADD INDEX ((MONTH (birth_date)));
第7题
Which two queries are examples of successful SQL injection attacks?
E)
SELECT id, name FROM user
WHERE id=23 OR id=32 AND 1=1;
A)
SELECT user, passwd FROM members
WHERE user = ' ? ';
INSERT INTO members ('user', 'passwd')
VALUES ('bob@example.com', 'secret');--';
D)
SELECT id, name FROM user
WHERE id=23 OR id=32 OR 1=1;
C)
SELECT id, name FROM user
WHERE user.id = (SELECT members.id FROM members);
F)
SELECT email, passwd FROM members
WHERE email = 'INSERT INTO members('email', 'passwd') VALUES ('bob@example.com', 'secret');--';
B)
SELECT user, phone FROM customers WHERE name = ' \\; DROP TABLE users; -- ';
题目解析
这道题目是关于 SQL 注入(SQL Injection)攻击的识别。我们要找出其中两个 SQL 语句是典型或成功的 SQL 注入攻击实例。
SQL 注入是指攻击者通过向应用程序的输入中注入恶意 SQL 代码,使得原本预期的 SQL 语句逻辑被破坏,导致信息泄露、篡改或破坏数据库。
常见注入类型包括:
- 逻辑永真:
OR 1=1 - 联合查询插入语句:
'; DROP TABLE ...; -- - 联合多个语句执行:
'; INSERT INTO ...; --
✅ A)
SELECT user, passwd FROM members
WHERE user = ' ? ';
INSERT INTO members ('user', 'passwd')
VALUES ('bob@example.com', 'secret');--';
- 明显是 多语句注入(stacked queries)。
- 在某些数据库(如 MySQL 开启
multiStatements)允许多个语句同时执行。 - 这是典型的 成功注入,攻击者添加了一个 INSERT 语句。
✅ 这是 SQL 注入。
❌ B)
SELECT user, phone FROM customers
WHERE name = ' \; DROP TABLE users; -- ';
\;实际上会被视为转义分号,在多数 SQL 引擎中不会被识别为分隔 SQL 语句。- 此语句不会真的执行 DROP TABLE。
- 虽然尝试注入,但 并不成功。
❌ 不是有效的注入。
❌ C)
SELECT id, name FROM user
WHERE user.id = (SELECT members.id FROM members);
- 是一个正常的子查询。
- 没有任何恶意语法或注入意图。
- 合法 SQL 查询语句。
❌ 不是 SQL 注入。
✅ D)
SELECT id, name FROM user
WHERE id=23 OR id=32 OR 1=1;
- 这里的
OR 1=1是典型的逻辑永真注入,使 WHERE 子句总为真。 - 这会导致返回表中 所有记录。
- 非常典型的注入方式。
✅ 是 SQL 注入。
❌ E)
SELECT id, name FROM user
WHERE id=23 OR id=32 AND 1=1;
- 这是逻辑表达式,不构成有效注入。
AND 1=1无害,id=32 AND 1=1等价于id=32。- 实际上等价于:
id=23 OR id=32
❌ 不是注入攻击。
❌ F)
SELECT email, passwd FROM members
WHERE email = 'INSERT INTO members('email', 'passwd') VALUES ('bob@example.com', 'secret');--';
- 插入语句被当作字符串处理,无法执行。
- 没有关闭引号;语法错误。
- 并不会执行成功。
❌ 不是成功注入。
正确答案
SELECT user, passwd FROM members
WHERE user = ' ? ';
INSERT INTO members ('user', 'passwd')
VALUES ('bob@example.com', 'secret');--';
SELECT id, name FROM user
WHERE id=23 OR id=32 OR 1=1;
第8题
Which two tools are available to monitor the global status of InnoDB locking?
F)INFORMATION_SCHEMA.INNODB_METRICS
A)SHOW ENGINE INNODB STATUS;
D)SHOW STATUS;
C)INEORMATION_SCHEMA.INNODB_TABLESTATS
E)INFORMATION_SCHEMA.STATISTICS
B)SHOW TABLE STATUS;
题目解析
题目问的是,哪两个工具可以用来监控InnoDB的全局锁状态。
正确选项分析:
A) SHOW ENGINE INNODB STATUS
- 作用:输出
InnoDB引擎的详细状态信息,包括锁与事务的实时状态。 - 关键内容:
TRANSACTIONS部分显示当前活动事务及其持有的锁。LATEST DETECTED DEADLOCK记录最近的死锁信息。
- 优势:直接查看锁冲突、等待链及死锁细节,是排查锁问题的首选工具。
F) INFORMATION_SCHEMA.INNODB_METRICS
- 作用:提供
InnoDB的性能与状态指标,包含锁相关的统计信息。 - 关键指标:
lock_deadlocks:统计死锁次数。lock_timeouts:锁超时次数。lock_row_lock_waits:行锁等待次数。
- 优势:通过SQL查询量化锁争用情况,支持长期监控与趋势分析。
排除其他选项的原因:
- D)
SHOW STATUS:仅提供全局状态变量(如Innodb_row_lock_waits),缺乏具体锁事务的细节。 - B)
SHOW TABLE STATUS:显示表的存储引擎、行数等元数据,与锁无关。 - C)
INNODB_TABLESTATS:记录表的统计信息(如索引大小),不涉及锁状态。 - E)
STATISTICS:存储索引统计信息,无关锁监控。
总结
监控InnoDB锁的全局状态需聚焦两类工具:
- 实时事务与锁分析(
SHOW ENGINE INNODB STATUS)。 - 量化锁指标统计(
INNODB_METRICS)。
其余选项或仅提供统计摘要(SHOW STATUS)或完全不相关(如SHOW TABLE STATUS),无法满足题目要求。
正确答案
INFORMATION_SCHEMA.INNODB_METRICS
SHOW ENGINE INNODB STATUS;
第9题
Which two authentication plugins require the plaintext client plugin for authentication to work?
D)PAM authentication
F)LDAP SASL authentication
C)Windows Native authentication
B)SHA256 authentication
E)MySQL Native Password
A)LDAP authentication
题目解析
哪两个认证插件需要客户端的明文插件(plaintext client plugin)来进行认证?
下面是一个对比表,清晰展示了各 MySQL 身份验证插件是否需要明文客户端插件(即 mysql_clear_password),以及它们的密码传输机制:
| 插件名称 | 是否需要明文客户端插件 (mysql_clear_password) |
密码传输方式 | 备注说明 |
|---|---|---|---|
| LDAP Authentication | ✅ 需要 | 明文传输(通过插件传递) | 用于将明文密码传给 LDAP 服务器 |
| SHA256 Authentication | ❌ 不需要 | 使用公钥加密传输密码 | 安全性较高,不依赖明文传输 |
| Windows Native Auth | ❌ 不需要 | 使用 Windows SSPI 机制 | 使用操作系统本地身份信息 |
| PAM Authentication | ✅ 需要 | 明文传输(用于调用 PAM 模块) | 依赖明文密码进行认证 |
| MySQL Native Password | ❌ 不需要 | 加盐哈希后的密码验证 | 是 MySQL 默认传统认证方式 |
| LDAP SASL Authentication | ❌ 不需要 | 使用 SASL 安全机制(如 GSSAPI) | 使用挑战响应方式,更安全 |
正确答案
LDAP Authentication
PAM Authentication
第10题
Which three are types of information stored in the MySQL data dictionary?
C)access control lists
D)server runtime configuration
F)view definitions
E)server configuration rollback
B)performance metrics
G)stored procedure definitions
A)InnoDB buffer pool LRU management data
题目解析
这道题考查的是:MySQL 数据字典(data dictionary)中存储的内容类型。
- 什么是 MySQL 数据字典?
自MySQL 8.0起,引入了 统一的数据字典(Data Dictionary),将原来存储在多个文件(如 .frm, .trn, .par)中的表元信息、视图、存储过程等集中统一管理,并持久化在系统表中。
- 分析选项
C) access control lists(访问控制列表)
- 用户、角色、权限信息是 MySQL 安全性的重要组成部分。
- 数据字典表(如 mysql.user、mysql.db)保存权限配置。
- 存储在数据字典中,正确。
D) server runtime configuration(服务器运行时配置)
- 比如
max_connections、innodb_buffer_pool_size这类参数是运行时配置(在内存中), - 它们存在于 服务器配置系统中,而不是数据字典。
- 不属于元数据范畴。
F) view definitions(视图定义)
- 视图是数据库对象,它的定义(
CREATE VIEW的 SQL 语句)会被记录。 - 数据字典会持久化视图的元信息(包括定义和依赖表)。
E) server configuration rollback(配置回滚)
MySQL没有专门的“配置回滚”机制。- 此项属于系统行为或配置工具功能,而非数据字典存储内容。
B) performance metrics(性能指标)
- 性能指标(如
SHOW STATUS、performance_schema中的计数器)是 运行时收集的动态数据。 - 这些不属于元数据,不存储在数据字典中。
G) stored procedure definitions(存储过程定义)
- 存储过程、函数等是数据库对象,它们的定义(
CREATE PROCEDURE)会被持久化。 - 数据字典保存其定义、参数和权限等信息。
A) InnoDB buffer pool LRU management data(缓冲池 LRU 管理数据)
- 属于内存中运行时结构,InnoDB 使用它来管理热数据页。
- 与表结构、索引、存储过程等元数据无关,不属于数据字典范畴。
正确答案:
C) access control lists
F) view definitions
G) stored procedure definitions