HunyuanCustom 速读
一、引言
HunyuanCustom 是由腾讯团队提出的一款多模态定制化视频生成框架。该框架旨在解决现有视频生成方法在身份一致性(identity consistency)和输入模态有限性方面的不足。通过支持图像、音频、视频和文本等多种条件输入,HunyuanCustom 能够生成具有特定主题且符合用户定义条件的视频。
二、整体架构
HunyuanCustom 基于 HunyuanVideo 构建,通过引入多模态理解模块和条件注入机制,实现了对不同输入模态的有效处理。其架构主要包括以下几个核心部分:
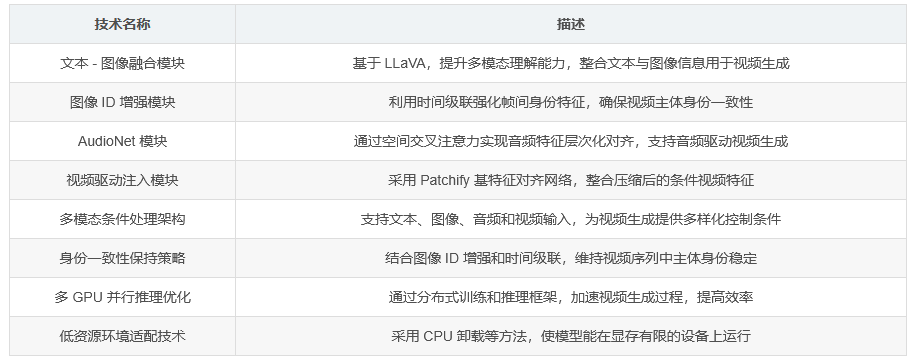
文本 - 图像融合模块 :基于 LLaVA 开发,增强模型对多模态信息的理解能力。
图像 ID 增强模块 :利用时间级联(temporal concatenation)强化帧间身份特征,确保视频中主体身份的一致性。
AudioNet 模块 :通过空间交叉注意力机制实现音频特征的层次化对齐,使视频生成能够受音频驱动。
视频驱动注入模块 :采用基于 Patchify 的特征对齐网络,将压缩后的条件视频特征整合到生成过程中,支持以视频为条件进行视频生成。
三、关键特性
多模态视频定制 :支持单主体和多主体场景,可处理单一或多个图像输入,生成定制化视频。此外,还能结合音频输入驱动主体动作,或依据视频输入替换指定物体。
身份一致性保持 :通过图像 ID 增强模块和时间级联策略,在视频帧序列中维持主体身份特征的稳定,避免生成视频中出现主体身份混淆或变化的问题。
灵活的条件输入 :兼容文本、图像、音频和视频等多种输入模态组合,为视频生成提供了丰富的控制条件,满足不同应用场景的需求。
四、应用场景
HunyuanCustom 的多模态能力使其能够广泛应用于多个领域,包括但不限于:
虚拟人广告 :输入多个相关图像,生成虚拟人物代言广告视频。
虚拟试穿 :依据图像输入创建虚拟试穿场景视频,助力在线购物体验提升。
唱歌头像生成 :结合图像和音频输入,创造出随着音乐歌唱的虚拟头像视频。
视频编辑 :利用图像和视频输入,实现视频中特定主体的替换,简化视频后期制作流程。
五、性能比较
论文中将 HunyuanCustom 与其他多款视频定制方法进行了对比,包括 VACE、Skyreels、Pika、Vidu、Keling 和 Hailuo。对比指标涵盖人脸 / 主体相似度(Face-Sim)、CLIP-B-T 分数、DINO-Sim 分数、时间一致性(Temp-Consis)以及多样性(DD)。结果显示,HunyuanCustom 在各项指标上均取得了优异成绩,例如在人脸相似度方面达到 0.627,时间一致性达到 0.958,显著优于其他方法,证明了其在身份一致性、真实感和文本 - 视频对齐等方面的优势。
六、运行要求
HunyuanCustom 模型对硬件有一定要求,以生成特定设置的视频为例:
对于分辨率为 720px×1280px、129 帧的视频,GPU 峰值内存需求为 80GB;对于 512px×896px、129 帧的视频,需求为 60GB。
推荐使用具有 80GB 内存的 NVIDIA GPU 以获得较好的生成质量,最低需 24GB 显存的 GPU,但速度会较慢。
测试操作系统为 Linux,同时提供了基于 Conda 的环境配置和 Docker 镜像部署方案,以方便用户在不同环境下安装和运行模型。
七、安装与部署
克隆仓库 :通过 Git 命令克隆 HunyuanCustom 的 GitHub 仓库到本地。
创建 Conda 环境 :推荐使用 Python 3.10.9 版本,执行 Conda 命令创建隔离的运行环境。
安装 PyTorch 及依赖 :根据不同 CUDA 版本(11.8 或 12.4),安装对应的 PyTorch、torchvision 和 torchaudio 等库。
安装其他依赖 :利用 pip 安装 requirements.txt 文件中列出的其他依赖包,如 tensorrt 相关库和 flash attention v2(用于加速)。
下载预训练模型 :按照指引下载模型权重文件,并放置在指定目录以便推理时加载。
八、推理方法
多 GPU 并行推理 :在配备 8 个 GPU 的机器上,通过 torchrun 命令启动并行推理任务,指定输入图像、正负提示词、检查点路径、视频尺寸、帧数等参数,生成高质量定制视频。
单 GPU 推理 :对于单 GPU 环境,调整命令参数,利用 CPU 卸载等策略,在有限的资源下运行模型,生成相应分辨率的视频。
低显存运行 :当显存不足时,启用 CPU 卸载选项,牺牲部分速度以实现模型的运行,确保在低配置设备上也能进行视频生成任务。
Gradio 服务器运行 :通过执行脚本启动 Gradio 服务器,提供用户友好的界面,方便用户提交输入并获取生成的视频结果,便于模型的演示和共享。
九、核心技术汇总