目录
本项目可以在华为云modelart上租一个实例进行,也可以在配置至少为单卡3060的设备上进行
https://console.huaweicloud.com/modelarts/
Ascend环境也适用,但是注意修改device_target参数
需要本地编译器的一些代码传输、修改等可以勾上ssh远程开发
说明:项目使用的数据集来自华为云的数据资源。项目以深度学习任务构建的一般流程展开(数据导入、处理 > 模型选择、构建 > 模型训练 > 模型评估 > 模型优化)。
主线为‘一般流程’,同时代码中会标注出一些要点(# 要点1-1-1:设置使用的设备
)作为支线,帮助学习mindspore框架在进行深度学习任务时一些与pytorch的差异。
可以只看目录中带数字标签的部分来快速查阅代码。
本系列
MindSpore框架学习项目-ResNet药物分类-数据增强-CSDN博客
MindSpore框架学习项目-ResNet药物分类-构建模型-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型训练-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型评估-CSDN博客
MindSpore框架学习项目-ResNet药物分类-模型优化-CSDN博客
4.模型评估
4.1模型预测
要求:
补充如下代码的空白处
主要完成:
1. 实例化resnet50 预测模型
2. 加载模型参数
3. 加载测试集的数据进行评估
4. 预测图像类别
4.1.1加载模型
首先加载训练好了的最佳模型权重。
num_class = 12 #
# 题目4-1-1:实例化resnet50 预测模型
net = resnet50(num_classes=num_class)
作用:创建 ResNet50 模型实例,输出维度适配新任务的 12 类分类需求。
关键:resnet50函数返回的模型结构已包含 ResNet50 的主干网络和替换后的 12 类全连接层(见前文代码)。
best_ckpt_path = 'BestCheckpoint/resnet50-best.ckpt'
# 题目4-1-2:加载模型参数
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(net,param_dict)
作用:将训练过程中保存的最佳模型权重(如验证集准确率最高的版本)加载到模型中,使模型具备 “记忆” 训练数据的能力。
关键 API:ms.load_checkpoint:读取.ckpt文件,返回参数字典(键为参数名,值为参数值)。
ms.load_param_into_net:将参数字典中的参数值赋值给模型net的对应参数,完成权重加载。
model = ms.Model(net)
image_size = 224
workers = 1
实例化模型,定义模型为推理功能的参数,单张224*224的图像推理
# 题目4-1-3:加载测试集的数据进行评估(补充代码块)
# 要求:在测试集上输出acc指标
test_acc, _ = test_loop(net, dataset_test, loss_fn)
print(f'Test Accuracy:{test_acc*100:.2f}%')
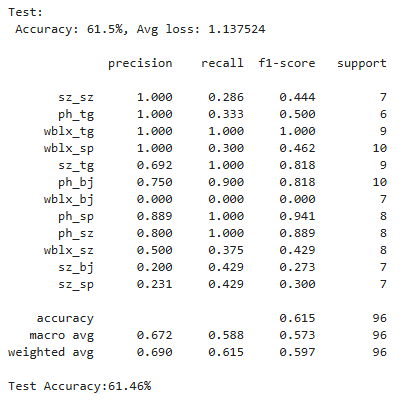
可以看到由于模型训练轮次较少,在测试集上的表现还有待提高
4.1.2通过传入图片路径进行推理
给定单张图片的路径推理预测分类结果
def predict_one(input_img):
dataset_one = create_dataset_zhongyao(dataset_dir=input_img,
usage="test",
resize=image_size,
batch_size=1,
workers=workers)
data = next(dataset_one.create_tuple_iterator())
images = data[0].asnumpy()
labels = data[1].asnumpy()
# 题目4-1-4:利用predict接口预测图像类别
output = model.predict(ms.Tensor(images)) # model = ms.Model(net)
pred = output.argmax(axis=1).asnumpy()
return index_label_dict[pred[0]]
input_img = "dataset1/zhongyiyao/train/wblx_tg/IMG_3978.JPG"
print(predict_one(input_img))
输出:wblx_tg
从文件路径也可以看出,模型推理结果正确,注意路径只是我们人类能看出结果,模型之会分析路径对应下的数据:也就是单张图片!
单张图片推理代码解释
单张图像分类预测函数
1. 加载单张图像并创建数据集(dataset_one)
dataset_one = create_dataset_zhongyao(dataset_dir=input_img,
usage="test",
resize=image_size,
batch_size=1,
workers=workers)
作用:调用自定义数据集创建函数create_dataset_zhongyao,将输入的单张图像(input_img)转换为模型可处理的数据集。
关键参数:usage="test":指定为测试模式(不进行数据增强,仅做基础预处理)。
resize=image_size(224):将图像缩放到模型输入尺寸(224×224)。
batch_size=1:单张图像作为一个批次(batch_size=1)。
2. 提取图像与标签数据
data = next(dataset_one.create_tuple_iterator()) # 获取数据迭代器的第一个批次
images = data[0].asnumpy() # 提取图像数据(转换为numpy数组)
labels = data[1].asnumpy() # 提取真实标签(转换为numpy数组,可选)
create_tuple_iterator():MindSpore 中数据集的迭代器,返回(图像, 标签)的元组。
next():获取迭代器的第一个(仅一个)批次数据(因batch_size=1,仅包含单张图像)。
3. 模型预测与类别推理(题目 4-1-4 核心)
output = model.predict(ms.Tensor(images)) # 模型推理,输入为MindSpore Tensor
pred = output.argmax(axis=1).asnumpy() # 取输出中概率最大的类别索引(axis=1为类别维度)
model.predict:MindSpore 模型的推理接口,输入预处理后的图像 Tensor,输出各分类的预测值(如概率分布)。
argmax(axis=1):在类别维度(通常为第 1 维)取最大值的索引,得到预测的类别编号(如[5]表示第 5 类)。
4. 索引转标签名称
return index_label_dict[pred[0]] # 通过预定义的索引-标签字典,将编号转换为类别名称(如"ph_sp")
index_label_dict:预定义的字典(如{0: "ph_sp", 1: "hz_sp", ...}),将模型输出的类别索引映射为具体的标签名称(如中药材名称)。
4.2图片推理
要求:
补充如下代码的空白处
主要完成:
1. 加载测试集的数据进行评估
2. 推理图像类别
3.显示图像及图像的预测值
4.2.1构造可视化推理结果函数
对测试集进行推理,可视化函数中包括了对模型的调用和对推理结果的输出
def visualize_model(dataset_test):
# 要点4-2-1:加载测试集的数据进行评估:获取图片数据和label。
data = next(dataset_test.create_tuple_iterator())
images = data[0].asnumpy()
labels = data[1].asnumpy()
# 要点4-2-2:推理图像类别
output = model.predict(ms.Tensor(images))
pred = output.argmax(axis=1).asnumpy()
plt.figure(figsize=(10, 6))
for i in range(6):
plt.subplot(2, 3, i+1)
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title('predict:{} actual:{}'.format(index_label_dict[pred[i]],index_label_dict[labels[i]]), color=color)
picture_show = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.4914, 0.4822, 0.4465])
std = np.array([0.2023, 0.1994, 0.2010])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
可视化推理结果函数代码解释
模型预测结果可视化函数
1. 功能概述
visualize_model函数用于可视化测试集的预测结果,随机选取 6 张测试图像,展示模型的预测标签与真实标签,并通过颜色区分预测正确 / 错误,直观评估模型性能。
2. 核心步骤解析
(1) 加载测试集数据(要点 4-2-1)
data = next(dataset_test.create_tuple_iterator()) # 获取测试集的一个批次数据
images = data[0].asnumpy() # 提取图像数据(shape: [batch, C, H, W])
labels = data[1].asnumpy() # 提取真实标签(shape: [batch])
作用:从测试数据集dataset_test中获取一个批次的图像和标签。
关键:create_tuple_iterator()返回数据迭代器,next()取第一个批次(假设批次大小≥6,否则需调整循环次数)。
(2) 模型推理获取预测标签(要点 4-2-2)
output = model.predict(ms.Tensor(images)) # 模型推理,输出各分类的预测值(logits或概率)
pred = output.argmax(axis=1).asnumpy() # 取概率最大的类别索引(shape: [batch])
model.predict:MindSpore 模型推理接口,输入图像 Tensor,输出预测值(如 12 类的概率分布)。
argmax(axis=1):在类别维度(第 1 维)取最大值索引,得到预测的类别编号(如[0, 5, 2, ...])。
(3) 可视化预测结果
plt.figure(figsize=(10, 6)) # 创建10x6英寸的画布
for i in range(6): # 遍历前6张图像
plt.subplot(2, 3, i+1) # 子图布局:2行3列,第i+1个位置
# 判断预测是否正确,设置标题颜色(蓝色=正确,红色=错误)
color = 'blue' if pred[i] == labels[i] else 'red'
# 标题显示预测标签和真实标签(通过index_label_dict转换索引→名称)
plt.title(f'predict:{index_label_dict[pred[i]]}\nactual:{index_label_dict[labels[i]]}', color=color)
# 反归一化并调整通道顺序(CHW→HWC,适应Matplotlib)
picture_show = np.transpose(images[i], (1, 2, 0)) # 通道维度从[C,H,W]→[H,W,C]
mean = np.array([0.4914, 0.4822, 0.4465]) # 训练时的归一化均值
std = np.array([0.2023, 0.1994, 0.2010]) # 训练时的归一化标准差
picture_show = std * picture_show + mean # 反归一化:x = x*std + mean
picture_show = np.clip(picture_show, 0, 1) # 限制像素值在[0,1]范围内(避免溢出)
plt.imshow(picture_show) # 显示图像
plt.axis('off') # 关闭坐标轴
plt.show() # 显示画布
反归一化:训练时图像经过(x - mean)/std归一化,可视化需还原为原始像素范围(x = x*std + mean)。
通道调整:MindSpore 默认图像格式为[C, H, W](通道优先),Matplotlib 需要[H, W, C](通道最后),通过np.transpose调整。
颜色标记:预测正确时标题为蓝色,错误时为红色,直观展示模型的分类效果。
4.2.2进行单张推理
# 题目4-2-3:显示图像及图像的预测值:调用visualize_model函数,利用推理数据进行可视化展示
visualize_model(dataset_test)

可以看到预测结果一般吧,因为训练轮次还是较少。为什么这么说呢,因为对于工业场景,进行药物检测还是得有>95%的精确率,才可以有效降低人工成本,此处5/6的精确率还是低了。