循环神经网络(RNN)
- 循环神经网络(RecurrentNeuralNetwork,RNN)又称递归神经网络,它是常规前馈神经网络(FeedforwardNeuralNetwork,FNN)的扩展,本节介绍几种常见的循环神经网络。
简单的循环神经网络
- 循环神经网络(RNN)会遍历所有序列的元素,每个当前层的输出都与前面层的输出有关,会将前面层的状态信息保留下来。理论上,RNN应该可以处理任意长度的序列数据,但为了降低一定的复杂度,实践中通常只会选取与前面的几个状态有关的信息。
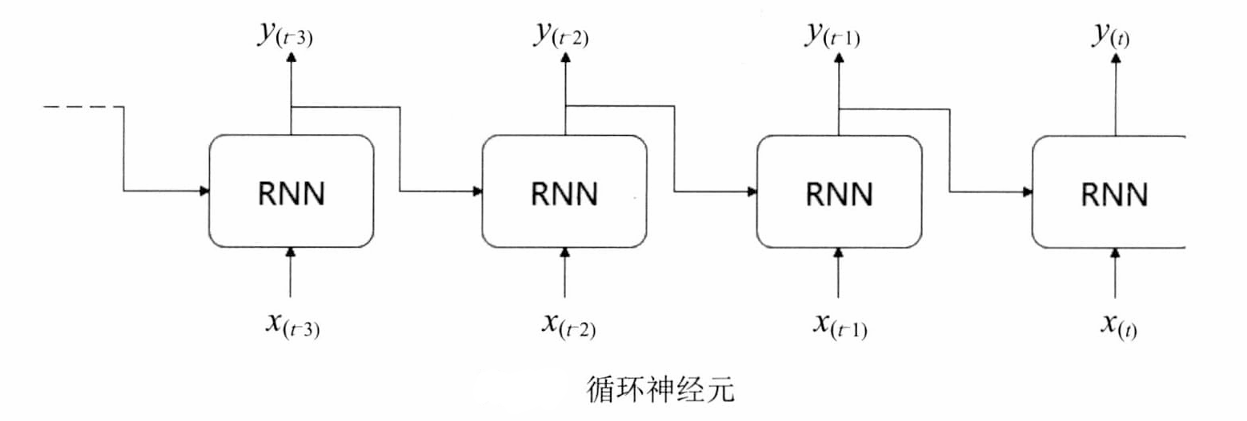
- 简单的循环神经网络如图:

- x是输入,y是输出,中间由一个箭头表示数据循环更新的是隐藏层,主要由中间部分实现时间记忆功能。
- 神经网络输入x并产生输出y,最后将输出的结果反馈回去。假设在一个时间t内,神经网络的输入除来自输入层的 x ( t ) x(t) x(t)外,还有上一时刻的输出 y ( t − 1 ) y(t-1) y(t−1),两者共同输入产生当前层的输出 y ( t ) y(t) y(t)。
- 将这个神经网络按照时间序列形式展开:
- 每个神经元的输出都是根据当前的输入 x ( t ) x(t) x(t)和上一时刻的 y ( t − 1 ) y(t-1) y(t−1)共同决定。它们对应的权重分别是 W x W_x Wx和 W y W_y Wy,单个神经元的输出计算如下:
y t = O ( x t T ⋅ W x + y t − 1 T ⋅ W y + b ) \boldsymbol { y } _ { t } = \mathcal { O } ( \boldsymbol { x } _ { t } ^ { \mathrm { T } } \cdot \boldsymbol { W } _ { x } + \boldsymbol { y } _ { t - 1 } ^ { \mathrm { T } } \cdot \boldsymbol { W } _ { y } + b ) yt=O(xtT⋅Wx+yt−1T⋅Wy+b) - 将隐藏层的层级展开,结果如下图:
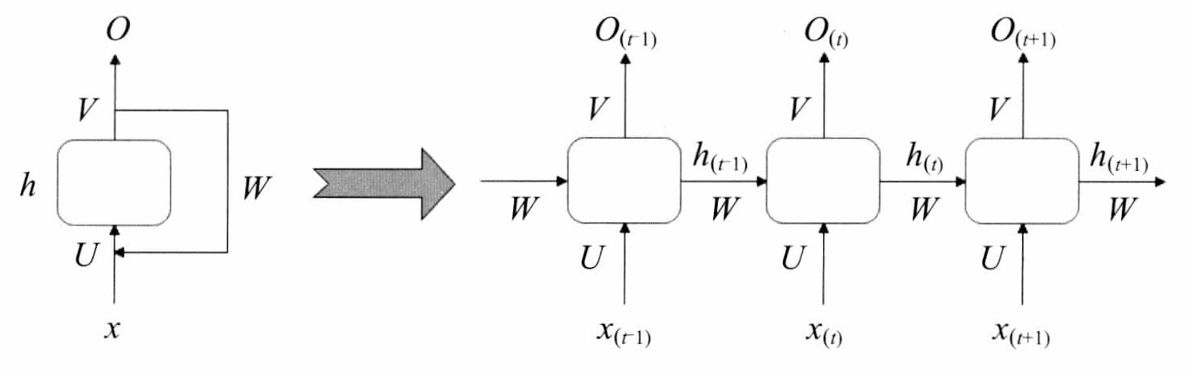
- RNN单元在时间 t t t的状态记作 h t h_t ht, U U U表示此刻输入的权重, W W W表示前一次输出的权重, V V V表示此刻输出的权重。
- 在 t = 1 t=1 t=1时刻,一般 h 0 h_0 h0表示初始状态为0,随机初始化 U 、 W 、 V U、W、V U、W、V,公式如下:
h 1 = f ( U x 1 + W h 0 + b h ) O 1 = g ( V h 1 + b o ) \begin {array} { l } { h _ { 1 } = f ( U x _ { 1 } + W h _ { 0 } + b _ { h } ) } \\ { O _ { 1 } = g ( V h _ { 1 } + b _ { o } ) } \\ \end{array} h1=f(Ux1+Wh0+bh)O1=g(Vh1+bo) - f 和 g 均为激活函数(光滑的曲线函数), f f f可以是Sigmoid、ReLU、Tanh等激活函数, g g g通常是Softmax损失函数。 b h b_h bh是隐藏层的偏置项, b 0 b_0 b0是输出层的偏置项。
- 前向传播算法,按照时间 t t t向前推进,而此时隐藏状态 h 1 h_1 h1是参与下一个时间的预测过程。
h 2 = f ( U x 2 + W h 1 + b h ) O 2 = g ( V h 2 + b o ) \begin {array} { l } { h _ { 2 } = f ( U x _ { 2 } + W h _ { 1 } + b _ { h } ) } \\ { O _ { 2 } = g ( V h _ { 2 } + b _ { o } ) } \\ \end{array} h2=f(Ux2+Wh1+bh)O2=g(Vh2+bo) - 以此类推,最终可得到输出公式为:
h t = f ( U x t + W h t − 1 + b h ) O t = g ( V h t + b o ) \begin {array} { l } { h _ { t } = f ( U x _ { t } + W h _ { t-1 } + b _ { h } ) } \\ { O _ { t } = g ( V h _ { t } + b _ { o } ) } \\ \end{array} ht=f(Uxt+Wht−1+bh)Ot=g(Vht+bo) - 权重共享机制通过统一网络参数(W、U、V及偏置项)实现了三方面优势:一是降低计算复杂度,二是增强模型泛化能力,三是实现对可变长度连续序列数据的特征提取。该机制不仅能捕捉序列特征的时空连续性,还通过位置无关的特性避免了逐位置规则学习,但保留了序列位置的识别能力。
- 尽管RNN网络在时序数据处理上表现优异,其基础结构仍存在显著缺陷。理论上RNN应具备长期记忆能力和任意长度序列处理能力,但实际应用中会出现梯度消失现象。该问题源于两方面:一是BP算法的固有缺陷(前馈神经网络中随深度增加出现训练失效),二是RNN特有的长程依赖问题(时间跨度导致记忆衰减)。从数学视角看,当激活函数导数小于1时,多层网络梯度呈指数衰减;反之若导数大于1则引发指数级梯度膨胀,造成网络失稳(即梯度爆炸问题)。
- 针对这些局限性,学界提出了两种主流改进架构:长短期记忆网络(LSTM)和门控循环单元(GRU)。
长短期记忆网络(LSTM)
- 长短期记忆网络(Long Short-Term Memory,LSTM)主要为了解决标准RNN在处理长序列数据时面临的梯度消失等问题。
- 基本的LSTM结构单元如图:
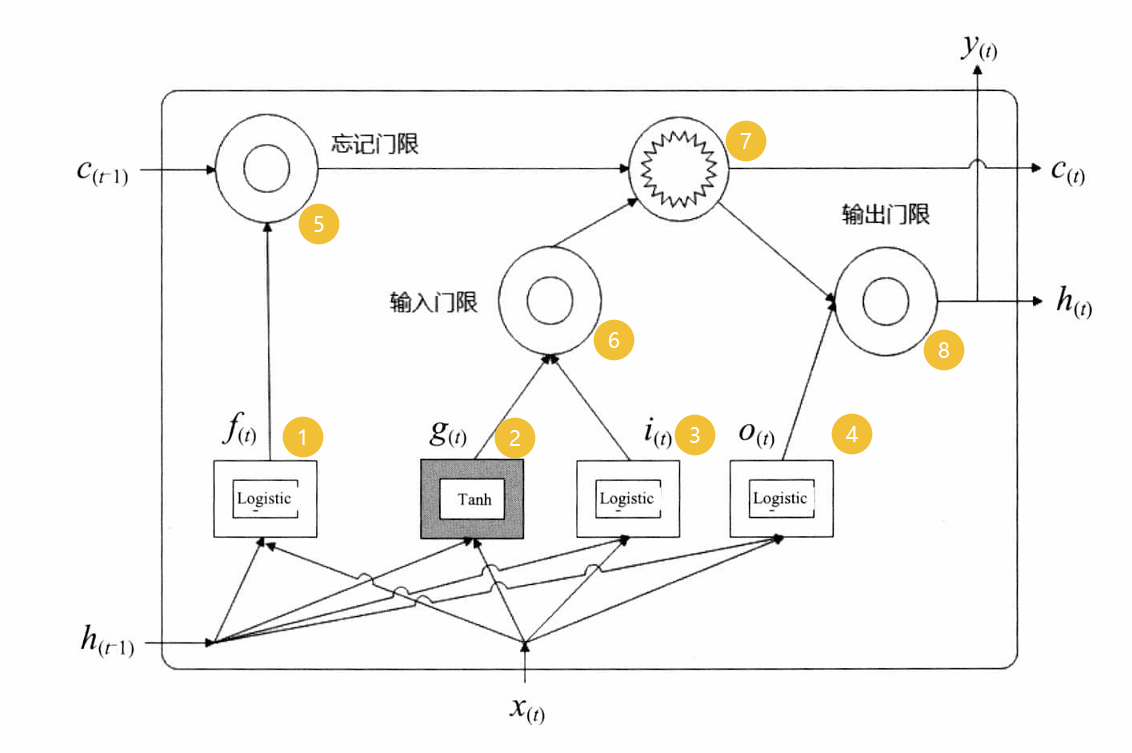
- 图中四个矩形即图标1,2,3,4是普通神经网络的隐藏层结构。其中 f ( t ) , i t , o ( t ) f_{(t),i_{{t}},o_(t)} f(t),it,o(t)都是Logistic函数, g ( t ) g_{(t)} g(t)是Tanh函数。
- LSTM单元状态分为长时记忆和短时记忆,其中短时记忆i用向量 h ( t ) h_{(t)} h(t)表示,长时记忆用 c ( t ) c_{(t)} c(t)表示。
- LSTM单元结构中还有三个门限控制器:忘记门限,输入门限和输出门限。三个门限都使用Logistic函数,如果输出值为1,表示门限打开;如果输出值为0,表示门限关闭。
- 忘记门限:主要用 f ( t ) f_{(t)} f(t)控制着长时记忆是否被遗忘。
- 输入门限:主要由 i ( t ) i_{(t)} i(t)和 g t g_{{t}} gt, i ( t ) i_{(t)} i(t)用于控制 g t g_{{t}} gt用于增强记忆的部分。
- 输出门限:主要由 o ( t ) o_{(t)} o(t)控制应该在该时刻被读取和输出的部分。
- LSTM单元的基本流程如下:随着短时记忆 c ( t ) c_{(t)} c(t)从左到右横穿整个网络,它首先经过一个遗忘门,丢弃一些记忆,然后通过输入门限来选择增加一些新记忆,最后直接输出 c ( t ) c_{(t)} c(t)。此外,增加记忆这部分操作中,长时记忆先经过Tanh函数,然后被输出门限过滤,产生了短时记忆ht)。
- 综上所述,LSTM可以识别重要的输入(输入门限的作用),并将这些信息在长时记忆中存储下来,通过遗忘门保留需要的部分,以及在需要的时候能够提取它。
- LSTM单元结构中的三个门限控制器、两种状态以及输出:
i ( t ) = σ ( w × i ⊤ ⋅ x ( t ) + w h i ⊤ ⋅ h ( t − 1 ) + b i ) f ( t ) = σ ( w × j ⊤ ⋅ x ( t ) + w h j ⊤ ⋅ h ( t − 1 ) + b f ) o ( t ) = σ ( w x o ⊤ ⋅ x ( t ) + w h o ⊤ ⋅ h ( t − 1 ) + b o ) g ( t ) = T a n h ( w x g ⊤ ⋅ x ( t ) + w h g ⊤ ⋅ h ( t − 1 ) + b g ) c ( t ) = f ( t ) ⊗ c ( t − 1 ) + i ( t ) ⊗ g ( t ) y ( t ) = h ( t ) = o ( t ) ⊗ T a n h ( c ( t ) ) \begin{array} { r l } & { i _ { ( t ) } = \sigma ( w _ { \times i } ^ { \top } \cdot x _ { ( t ) } + w _ { h i } ^ { \top } \cdot h _ { ( t - 1 ) } + b _ { i } ) } \\ & { f _ { ( t ) } = \sigma ( w _ { \times j } ^ { \top } \cdot x _ { ( t ) } + w _ { h j } ^ { \top } \cdot h _ { ( t - 1 ) } + b _ { f } ) } \\ & { o _ { ( t ) } = \sigma ( w _ { x o } ^ { \top } \cdot x _ { ( t ) } + w _ { h o } ^ { \top } \cdot h _ { ( t - 1 ) } + b _ { o } ) } \\ & { g _ { ( t ) } = \mathrm { T a n h } ( w _ { x g } ^ { \top } \cdot x _ { ( t ) } + w _ { h g } ^ { \top } \cdot h _ { ( t - 1 ) } + b _ { g } ) } \\ & { c _ { ( t ) } = f _ { ( t ) } \otimes c _ { ( t - 1 ) } + i _ { ( t ) } \otimes g _ { ( t ) } } \\ & { y _ { ( t ) } = h _ { ( t ) } = o _ { ( t ) } \otimes \mathrm { T a n h } ( c _ { ( t ) } ) } \end{array} i(t)=σ(w×i⊤⋅x(t)+whi⊤⋅h(t−1)+bi)f(t)=σ(w×j⊤⋅x(t)+whj⊤⋅h(t−1)+bf)o(t)=σ(wxo⊤⋅x(t)+who⊤⋅h(t−1)+bo)g(t)=Tanh(wxg⊤⋅x(t)+whg⊤⋅h(t−1)+bg)c(t)=f(t)⊗c(t−1)+i(t)⊗g(t)y(t)=h(t)=o(t)⊗Tanh(c(t)) - w x i 、 w x f 、 w x o 、 w x g w_{xi}、w_{xf}、w_{xo}、w_{xg} wxi、wxf、wxo、wxg是每一层连接到 x ( t ) x_{(t)} x(t)的权重, w h i 、 w h f 、 w h o 、 w h g w_{hi}、w_{hf}、w_{ho}、w_{hg} whi、whf、who、whg是每层连接到前一个短时记忆 h ( t − 1 ) h_{(t-1)} h(t−1)的权重, b i 、 b f 、 b o 、 b g b_i、b_f、b_o、b_g bi、bf、bo、bg是每一层的偏置项。
门控循环单元(GRU)
门控循环单元(GateRecurrentUnit,GRU)是循环神经网络(RNN)的一个变种,它旨在解决标准RNN中梯度消失的问题。GRU结构更简单,效果更好。
GRU的设计初衷是解决长期依赖问题,即标准RNN难以捕捉长序列中较早时间步的信息。通过引入更新门和重置门,GRU能够学习到何时更新或忽略某些信息,从而更好地处理序列数据。
相较于LSTM,GRU有更少的参数和计算复杂度,特别是在资源受限的情况下训练更快,同时也能取得不错的性能表现,。GRU已被广泛应用于各种序列建模任务,如语言模型、机器翻译、语音识别等领域。
GRU如图所示:
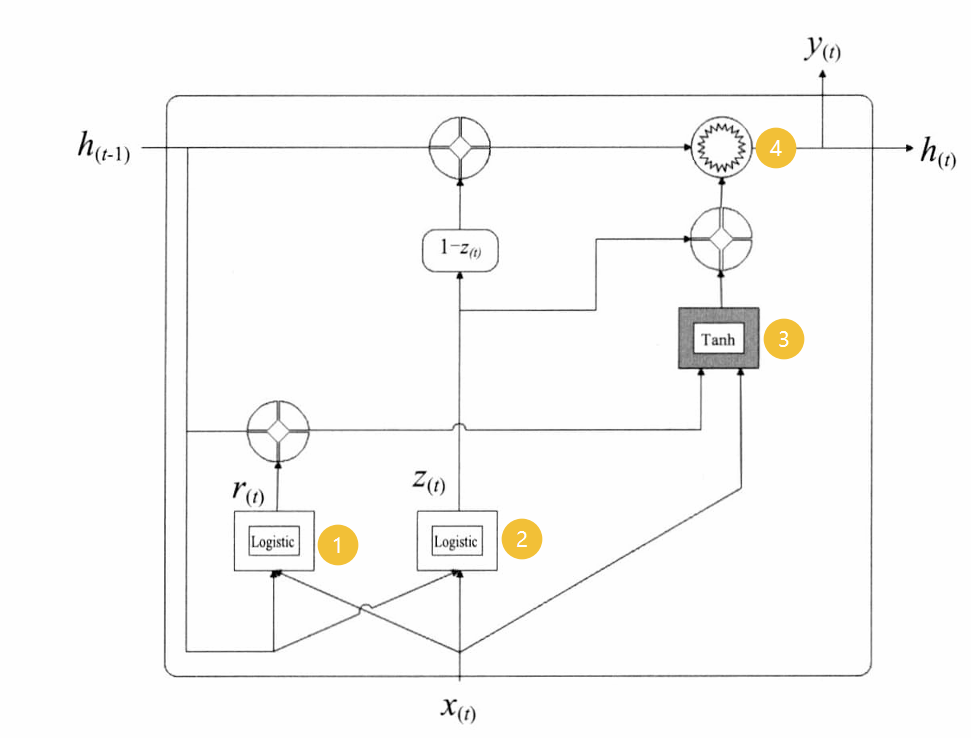
GRU中包含三个激活函数,分别为Logistic、Logistic、Tanh函数。
如图所示,GRU通过精简门控机制提升了计算效率,其核心特征如下:
门控结构简化:
- 采用**重置门(r)和更新门(z)**双门架构,激活函数缩减至3个(使用Sigmoid或Logistic函数,输出0~1的门控信号)。
- 合并状态向量为单一隐藏状态 h t h_t ht,简化信息流动路径。
门控功能详解:
- 重置门(r):控制前一时刻隐藏状态 h t − 1 h_{t-1} ht−1对当前候选状态的影响程度。门值越接近0,丢弃的历史信息越多,主层(如Tanh激活单元)将更多依赖当前输入 x t x_t xt 重新计算候选状态。
- 更新门(z):调节 h t − 1 h_{t-1} ht−1 传递至当前状态 h t h_t ht 的比例。门值越接近1,保留的历史信息比例越高,新生成的信息比例越低。
工作流程:
- 步骤1:根据 h t − 1 h_{t-1} ht−1 和 x t x_t xt 计算重置门 r t r_t rt 和更新门 z t z_t zt。
- 步骤2:利用 r t r_t rt 重置 h t − 1 h_{t-1} ht−1,生成候选状态 h ~ t \tilde{h}_t h~t(通常通过Tanh激活)。
- 步骤3:通过 z t z_t zt 加权融合 h t − 1 h_{t-1} ht−1 与 h ~ t \tilde{h}_t h~t,输出最终状态 h t h_t ht。
- GRU单元结构的计算过程:
z ( t ) = σ ( w x z T ⋅ x ( t ) + w h z T ⋅ h ( t − 1 ) ) r ( t ) = σ ( w x r T ⋅ x ( t ) + w h r T ⋅ h ( t − 1 ) ) g ( t ) = T a n h ( w x g T ⋅ x ( t ) + w h g T ⋅ ( r ( t ) ⊗ h ( t − 1 ) ) ) h ( t ) = ( 1 − z ( t ) ) ⊗ T a n h ( w x g T ⋅ h ( t − 1 ) + z ( t ) ⊗ g ( t ) ) \begin{array} { r l } & { z _ { ( t ) } = \sigma ( w _ { x z } ^ { \mathrm { T } } \cdot x _ { ( t ) } + w _ { h z } ^ { \mathrm { T } } \cdot h _ { ( t - 1 ) } ) } \\ & { r _ { ( t ) } = \sigma ( w _ { x r } ^ { \mathrm { T } } \cdot x _ { ( t ) } + w _ { h r } ^ { \mathrm { T } } \cdot h _ { ( t - 1 ) } ) } \\ & { g _ { ( t ) } = \mathrm { T a n h } ( w _ { x g } ^ { \mathrm { T } } \cdot x _ { ( t ) } + w _ { h g } ^ { \mathrm { T } } \cdot ( r _ { ( t ) } \otimes h _ { ( t - 1 ) } ) ) } \\ & { h _ { ( t ) } = ( 1 - z _ { ( t ) } ) \otimes \mathrm { T a n h } ( w _ { x g } ^ { \mathrm { T } } \cdot h _ { ( t - 1 ) } + z _ { ( t ) } \otimes g _ { ( t ) } ) } \end{array} z(t)=σ(wxzT⋅x(t)+whzT⋅h(t−1))r(t)=σ(wxrT⋅x(t)+whrT⋅h(t−1))g(t)=Tanh(wxgT⋅x(t)+whgT⋅(r(t)⊗h(t−1)))h(t)=(1−z(t))⊗Tanh(wxgT⋅h(t−1)+z(t)⊗g(t)) - w x z 、 w x r w_{xz}、w_{xr} wxz、wxr 和 w x g w_{xg} wxg是每一层连接到输入 x ( t ) x(t) x(t)的权重, W h z 、 W h r , W_{hz}、W_{hr}, Whz、Whr,和 W h g W_{hg} Whg 是每一层连接到前一个短时记忆 h ( t − 1 ) h_{(t-1)} h(t−1)的权重。