该论文提出了一种结合物理模型与扩散模型的低光图像增强方法 Diff-Retinex,是首个将Retinex分解与生成式扩散模型结合的低光图像增强工作。
核心思想
Diff-Retinex 重新思考了低光图像增强(LLIE)任务,将其建模为:
Retinex 分解:将图像分为反射率图(Reflectance)和照明图(Illumination);
扩散式图像生成:利用扩散模型分别调整上述两个分量,实现颜色校正、去噪和内容补全。
其目标是通过扩散模型“生成”缺失信息,而非仅仅“增强”已有信息。
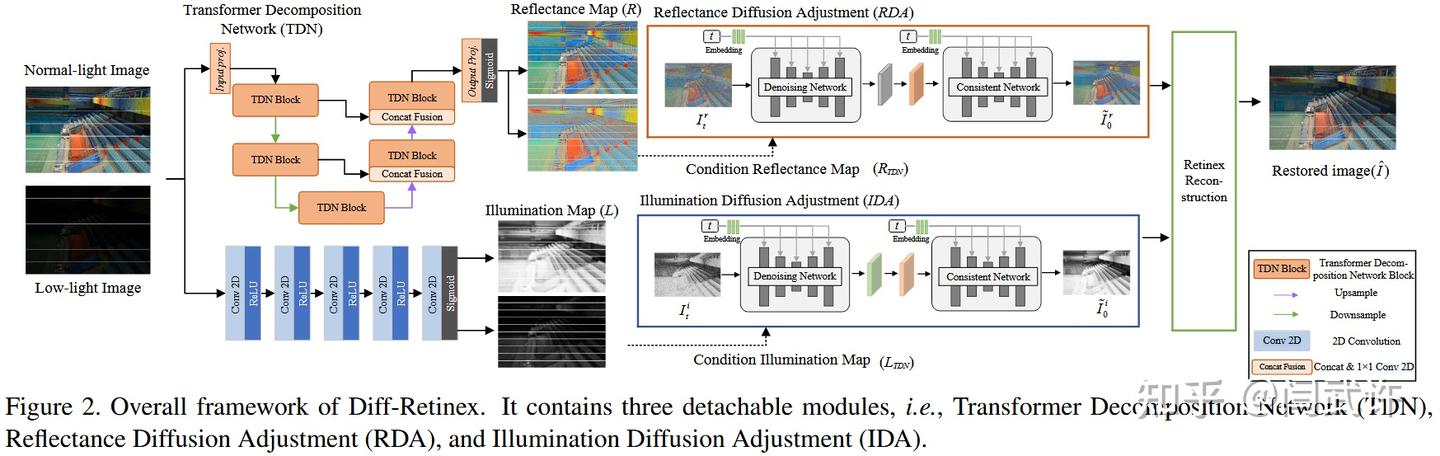
Diff-Retinex 包括三个模块:
1.Transformer Decomposition Network(TDN):
- 利用改进的 Transformer 对图像进行 Retinex 分解;
- 得到 Reflectance 和 Illumination 两张图。
2.Reflectance Diffusion Adjustment(RDA)
- 利用条件扩散模型调整反射率图,修复颜色与纹理。
3.Illumination Diffusion Adjustment(IDA)
- 同样采用扩散模型调整照明图,提升亮度一致性与自然性。
最终增强图像由:
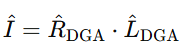
计算得出。
模块详解:
1. Transformer Decomposition Network (TDN)
经典 Retinex 理论假设图像 ![]()
该部分利用 Transformer(注意力机制)设计 TDN,克服CNN在分解时局部视野的限制,提升全局建模能力:
损失函数组成:
重建损失(保持图像重建一致性)
反射率一致性损失(低光与正常光下应一致)
照明平滑损失(局部光照应平滑变化)
核心模块 MDLA:引入多尺度卷积替代标准注意力机制,实现高分辨率图像上的高效计算。
2. Diffusion Generation Adjustment
基于 DDPM(Denoising Diffusion Probabilistic Models),用于恢复正常光照分布。
前向过程:逐步加入高斯噪声;
反向过程:利用条件图像(Retinex分解图)指导噪声图像还原成正常光图像;
Diffusion 过程训练目标
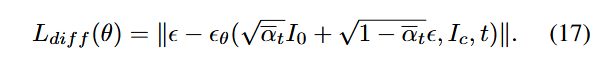
2. 现在的方法有哪些缺陷
2.1. 问题A
基于物理理论的传统图像增强方法,如:灰度变换、直方图均衡、Retinex理论,它们有着扎实的理论和可解释性,但是受限于人工设计,效率、泛化能力、鲁棒性都较差;
深度学习方法构建了低光图像和正常光图像之间复杂的映射关系,但是缺乏理论支撑、不具备可解释性。另外,由于人类缺乏对图像缺陷的具体定义,再加上深度学习模型训练的不确定性,导致基于深度学习的方法鲁棒性较差,(也就是说,在A数据集上训练的模型不能很好地迁移到B数据集上)。
以上两种方法是将低光图像增强任务作为亮度分布的拟合,但是作者认为该任务也是一个有条件生成任务。
传统低光图像增强方法(如直方图均衡化、Retinex 理论、基于深度学习的光照估计模型等)通常假设:
- 低光图像的主要问题是全局或局部亮度分布不均匀(如整体偏暗、局部过曝)。
- 解决方法是通过数学变换或模型学习,拟合或修正图像的亮度分布,
与传统方法的本质区别
传统亮度拟合 有条件生成任务 目标 修正亮度分布,逼近参考光度特性 生成视觉上真实、语义合理的图像 映射关系 一对一(输入→唯一输出) 一对多(输入→多种合理输出) 关键技术 数学变换、光照估计、像素级回归 生成模型(GAN、Transformer 等) 关注重点 光度学指标(PSNR、SSIM) 感知质量(视觉真实性、语义一致性)
假设输入是一张低光下拍摄的人像照片(面部昏暗、背景模糊):
- 传统方法:通过亮度拟合提升整体亮度,可能导致面部过曝、背景噪声放大,但 PSNR/SSIM 指标可能较高;
- 有条件生成方法:以低光图像为条件,生成一张面部清晰、色彩自然、背景合理(如补全模糊的环境细节)的人像,即使像素值与 “真实” 图像有差异,但视觉效果更优。
3. 模型概述
模型的训练分为两个阶段:Retinex分解阶段和扩散模型阶段。首先训练Retinex分解阶段,从原图中提取反射率图和入射量图;在扩散模型阶段,构建两个分支分别对反射率图和入射量图进行扩散生成的操作,将正常光图像的对应部分作为目标,低光图像的对应部分作为条件,从高斯噪声中生成正常光部分的对应部分;
提取反射率图和入射量图的本质是从观测图像中解耦物理世界的固有属性(反射率)与观测条件(光照)
4. 问题A及其对应创新点
4.1. 多种类的损失函数
4.1.1. Retinex分解阶段
这一阶段的训练为自监督训练,对正常光图像和低光图像使用同一套权重进行分解;
- In/Il 表示正常光图像/低光图像
- Rn/Rl 表示正常光图像的反射率图/低光图像的反射率图
- Ln/Ll 表示正常光图像的入射量图/低光图像的入射量图
重建损失
为了确保反射率和入射量相乘仍能得到原图像而设置的重建损失。考虑到模型较难从低光图像中提取到正确特征,使用超参 αrec 调整其所占的比例。另外,还可使用交叉重建损失,即使用正常光图像的反射率图和低光图像的入射量图得到的图像与原始的低光图像进行对比得到损失,反之亦可;
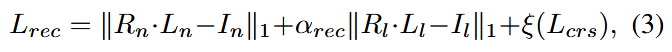
反射率一致损失
由于反射率往往根据物品材质、纹理决定,并不会随着亮度因素改变,因此应该保证从正常光图像和低光图像分别提取出的反射率图一致;
![]()
亮度平滑性损失
真实世界中亮度的变化是均匀的,但是考虑到物品与光源的相对位置、形状等因素导致的亮度突变,因此需要在亮度均匀变化的基础上保留物体的结构信息,作者提出了一种基于原图梯度的方法,使得在结构平滑的区域限制亮度剧烈变化,而在结构不平整的区域则放松这种约束;
![]()
![]()
4.1.2. 扩散模型阶段
论文采取经典的扩散损失加上内容损失的形式;
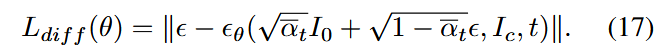
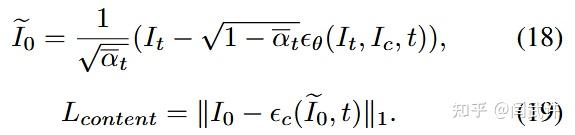
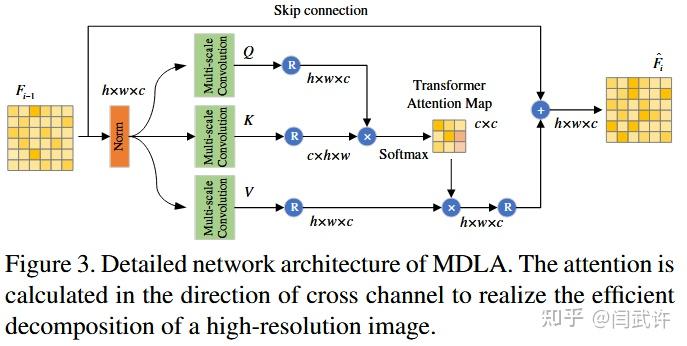
4.2. TDN Transformer Decomposition Network
论文提出了一个基于Transformer的反射率解耦模块,但论文中并没有详细介绍这个模块,仅仅表示该模块通过多尺度深度可分离卷积提取QKV,并计算通道维度的注意力以减少计算复杂度;
5. 实验
5.1. 实验设置
- γrc=0.1,γsm=0.1,αrec=0.3
- γct=1
- 迭代次数800K
- lr=0.0001
- batch size=16
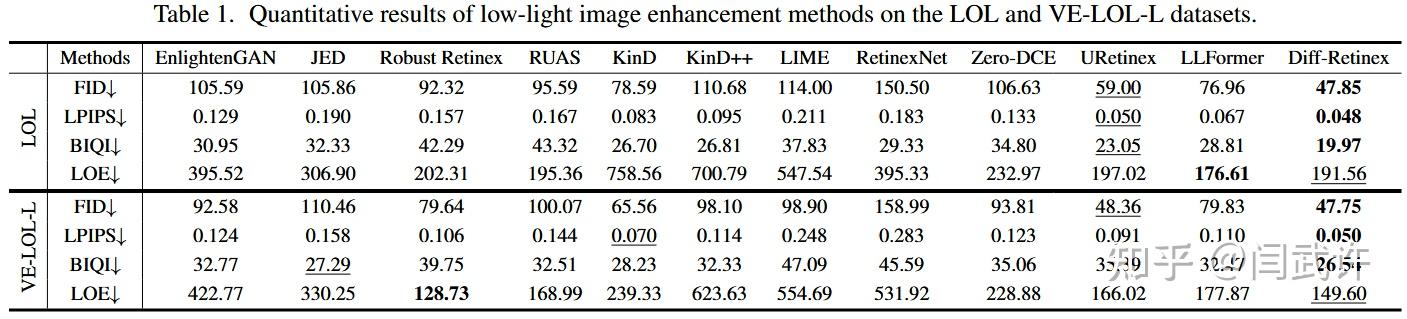
5.2. 对比实验
LOL

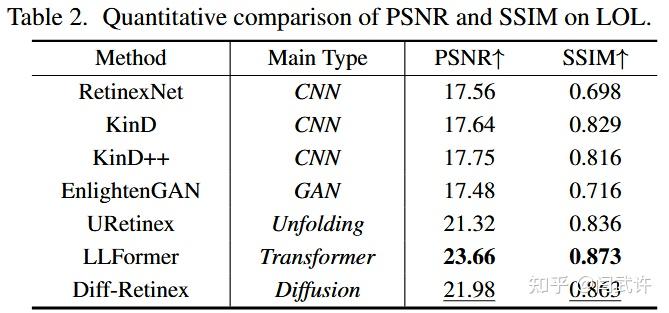
VE-LOL-L

图5和图6视觉效果:
可重建缺失纹理(如地面砖块、扶手等);
色彩更自然、无偏色;
噪声抑制显著。
LOL & VE-LOL-L
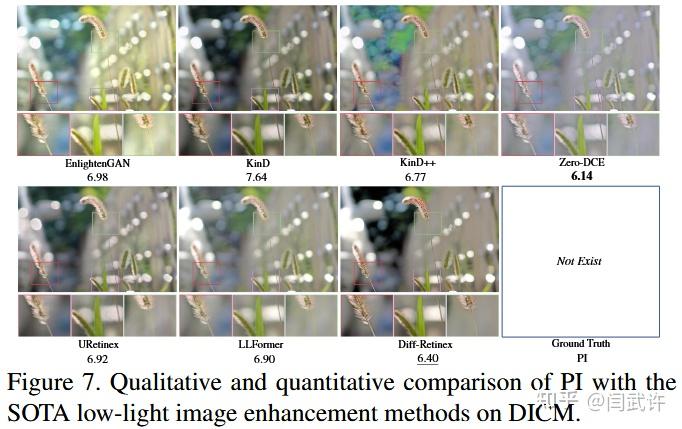
DICM
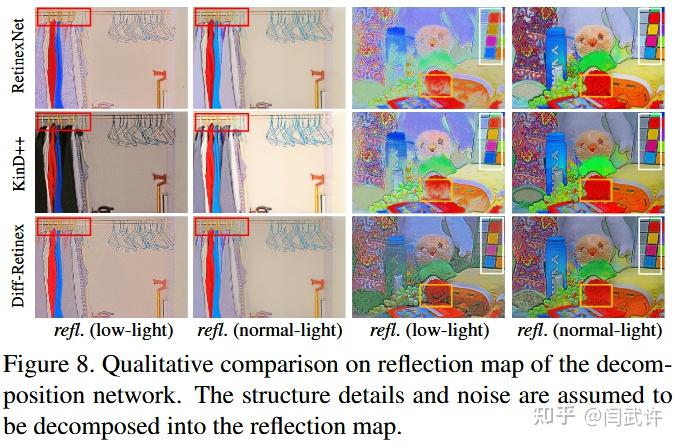
反射率图对比

5.3. 消融实验
无模块之间消融实验的结果;
6. 总结
本文提出了一种将Retinex理论和Diffusion Model结合起来的框架。
补充:
综述
概念介绍
Retinex是一种常用于图像增强的算法,其核心思想是在保留图像细节信息的前提下,调整图像的对比度和亮度。Retinex算法主要有三种不同的实现方式:单尺度Retinex(SSR)、多尺度Retinex(MSR)和多尺度自适应增益Retinex(MSRCR)。单尺度Retinex算法假设图像中的光照变化主要集中在低频分量上,因此只需对图像进行一次滤波处理即可去除低频分量,然后对得到的中高频分量进行增强。
多尺度Retinex算法将图像分解成不同尺度的图像,对每个尺度的图像进行增强,以保留不同尺度的细节信息。
多尺度自适应增益Retinex算法综合了前两种算法,先分解成不同尺度的图像,然后使用自适应增益函数对每个尺度的图像进行增强,最后重建图像以达到增强效果。
理论
Retinex的理论基础是三色理论和颜色恒常性。
这意味着物体的颜色是由它对红、绿、蓝三种光线的反射能力来决定的,而不是由反射光强度的绝对值来决定的。同时,物体的颜色也不会受到光照不均匀性的影响,具有一致性。
Retinex模型利用这种颜色恒常性,可以在动态范围压缩、边缘增强和颜色恒常三个方面打到平衡,因此可以对各种不同类型的图像进行自适应的增强,不同于传统的只能增强图像某一类特征的方法。
Retinex 图像增强的基本思想:去除照射光影响,保留物体自身的反射属性。
核心思想:保留图像细节信息的前提下,调整图像的对比度和亮度。
Retinex 理论认为图像 I(x, y)是由照度图像与反射图像组成。前者指的是物体的入射分量的信息,用 L(x, y) 表示;后者指的是物体的反射部分,用 R(x, y) 表示。公式:
I(x, y) =R(x, y) * L(x, y)
同时,由于对数形式与人类在感受亮度的过程属性最相近,因此将上述过程转换到对数域进行处理,这样做也将复杂的乘法转换为加法: i(x, y) = r(x, y) + l(x, y)
照度图和反射图
照度图和反射图的区别是,照度图表示光源对某个表面的照射强度,而反射图表示物体表面对光线的反射特性。照度图和反射图都可以用于计算光照和反射效果,但是它们的输入和输出不同。
照度图的输入是光源的位置、强度和颜色,输出是表面上不同位置的照度值。
反射图的输入是物体表面的材质、颜色和法线,输出是表面上不同位置的反射率和颜色

流程
- 高斯滤波:对输入图像进行高斯模糊处理,以消除图像中的噪声和细节。
- 计算照度图像:将处理后的图像转换为对数空间,并通过高斯滤波计算出照度图像,即物体的入射分量信息。
- 计算反射图像:通过计算原始图像和照度图像的差异得到反射图像,即物体的反射部分。
- 反对数变换:将照度图像和反射图像转换回线性空间。
- 图像拉伸:对输出图像进行亮度调整,以增强图像的对比度和细节。
PSNR(峰值信噪比)和 SSIM(结构相似性指数) 用于衡量两张图像的相似性或失真程度(如压缩、噪声、增强等处理后的效果)。
PSNR 是一种基于像素值差异的简单度量方法,常用于评估图像压缩(如 JPEG、视频编码)或噪声添加后的失真程度。
原理:通过计算原始图像与失真图像的均方误差(MSE),再将其转换为分贝(dB)值,值越大表示图像质量越好。
- 仅考虑像素差异,忽略人类视觉系统(HVS)的特性(如对高频细节不敏感)。
- 无法反映图像的结构信息或语义相似性,例如两张内容差异大但像素误差小的图像可能得到高 PSNR 值。
SSIM 是一种基于感知的质量评价指标,旨在模拟人类视觉系统对图像结构信息的感知,更贴近主观质量评价(如人眼观察效果)。
原理:从图像的亮度(Luminance)、 对比度(Contrast)和结构(Structure)三个维度比较图像相似性,输出范围为 ([0, 1]),值越接近 1 表示图像越相似。